Redis学习笔记01 (数据结构,线程模型,持久化)
Background
Redis(Remote Dictionary Server)是一种基于键值对的内存数据库,通常被称为数据结构服务器。它支持多种数据结构,例如字符串(String)、哈希(Hash)、列表(List)、集合(Set)、有序集合(Sorted Set)等,并提供了丰富的命令接口,使得开发者可以方便地利用这些数据结构来实现各种复杂应用。
Redis具有高性能、高可靠性和高可扩展性等特点,它将所有的数据保留在内存中,并通过异步方式将数据写入磁盘,以保证数据的持久化。同时,Redis还支持数据复制、主从架构、哨兵模式等多种高可用解决方案,可以用于构建分布式系统。
由于Redis的优秀性能和易用性,它已经成为了一个非常流行的开源项目,被广泛应用于Web应用程序、缓存、消息队列、计数器等领域。
主要为了阅读redis源码做好大局观和理论上的铺垫
数据结构
redis支持的key或者value的数据的底层数据结构如下
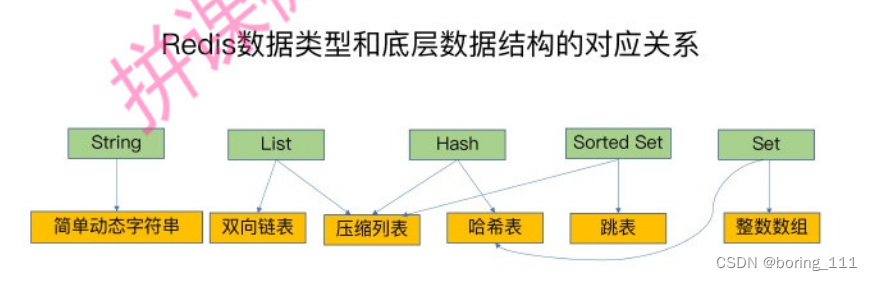
key/value的映射采用一个全局hash表
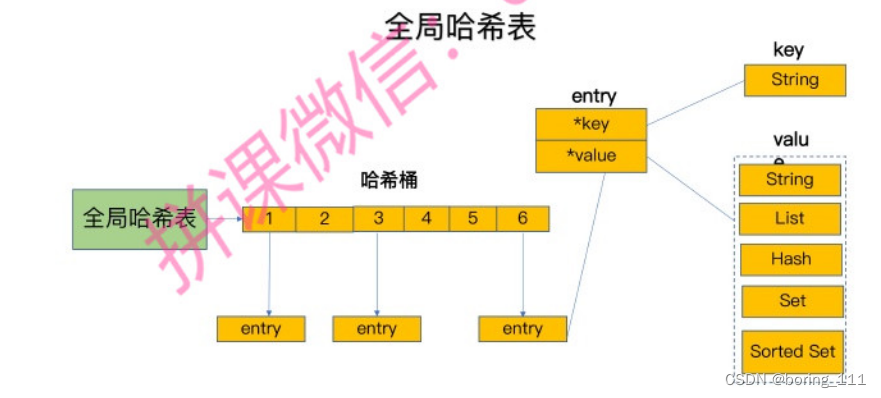
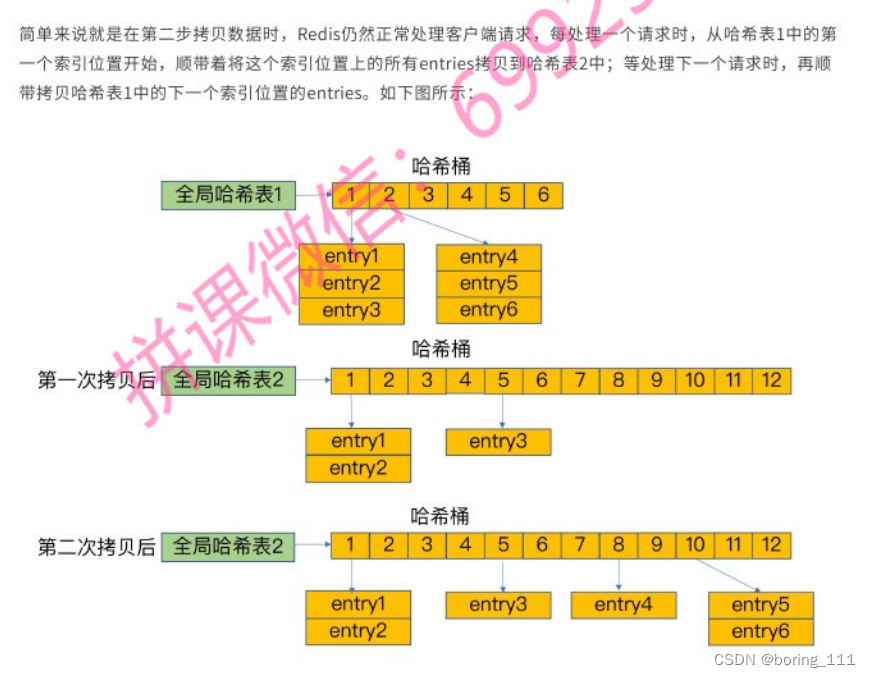
但是因为hash冲突的存在,可能退化成链,所以我们要rehash,但是为了更低的延迟,我们要可以做一个优化:之前的rehash分为3步:1)分配一个hash table大小两倍的hash table, 2)把hash table1的数据转移到hash table2 3)释放hash table1的空间
优化后,因为主要是2)太耗时了,一个请求把延时都承担了,所以我们可以把这个转移分担到每一个请求操作上:
不同操作的复杂度

1.单点操作一般很快,通过hash找到value,然后对其底层数据结构操作即可
2.range sort对于hash table来说很慢,O(N), O(NlogN)。但是对于leveldb这种sorted key就比较友好了。
3.统计操作就是操作元数据
4.最后就是查询末尾啥的。。。
线程模型
都说redis是单线程模型,但这个单线程是指处理get, put,这些操作是单线程,还有很多别的线程IO,background线程。
为啥单线程还是快
1)因为多线程对同一资源的竞争的协调是有代价的,比如cpu cache失效啥的,多线程实际上是这样的
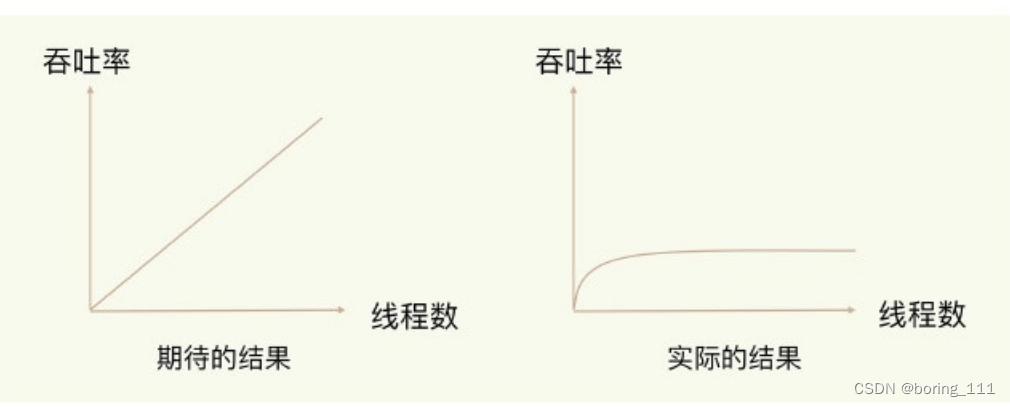
2)IO处理上用了多路复用和非阻塞操作

但是还是存在性能瓶颈

持久化
AOF日志
注意redis是先内存,后日志,不是WAL,因为redis主要是做缓存用的,不是真的数据库,如果丧失真的数据库的话,这样做可能会导致数据丢失。好处是当前操作不阻塞,但是可能会稍微导致下一个操作阻塞
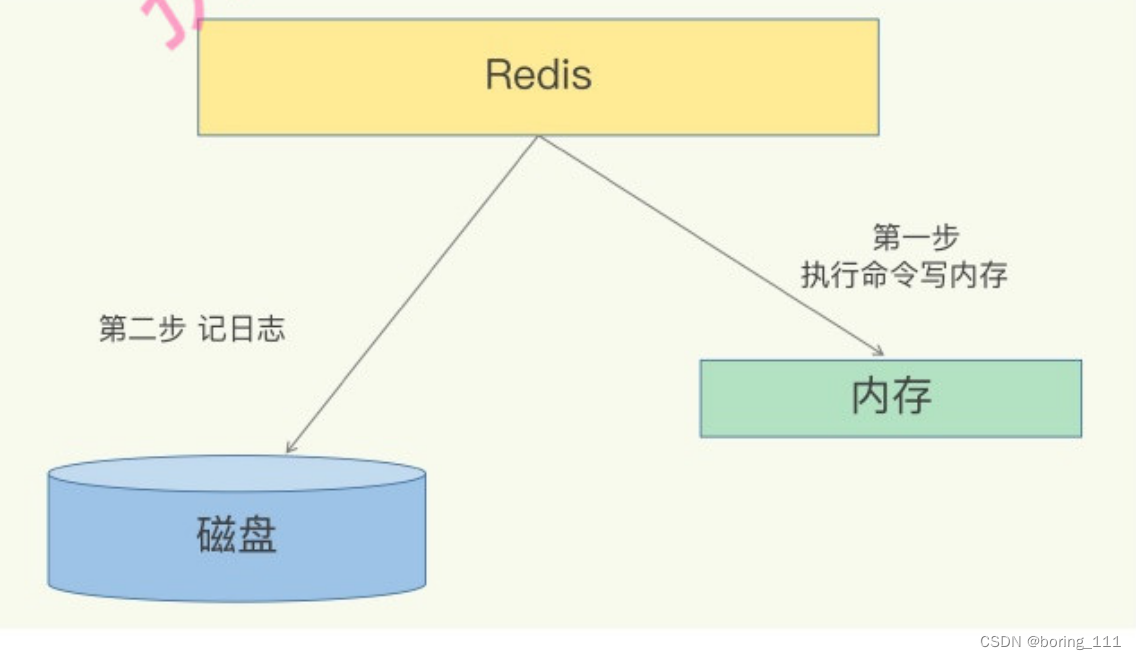
append only file

关于持久化到磁盘的时机有三个可选择的
1)always,修改就写入
2)everysecond,每秒批处理
3)NO 防止内存中,有操作系统决定
但是日志不能无限增加,所以我们要重写,重写就是根据当前内存中有的元素做一个put操作记录,这样就大大减少了日志的大小
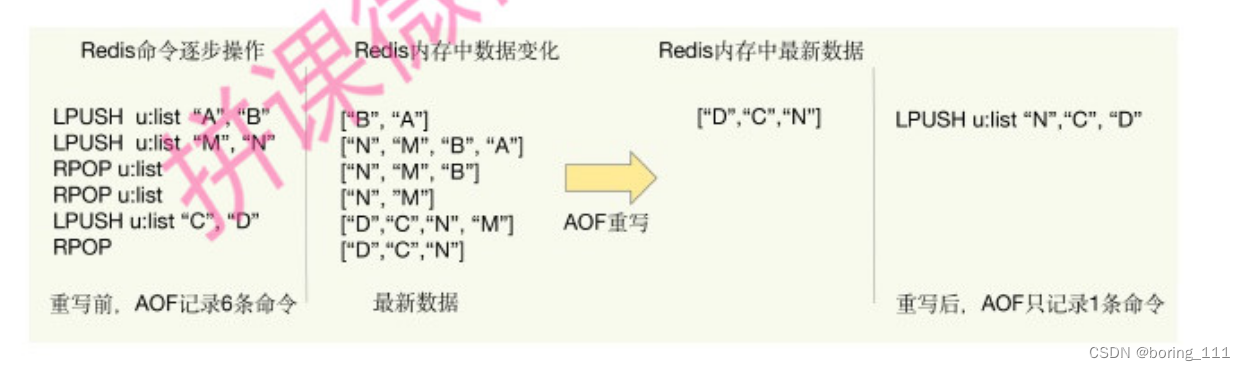
AOF重写过程--------------一个拷贝,两处日志
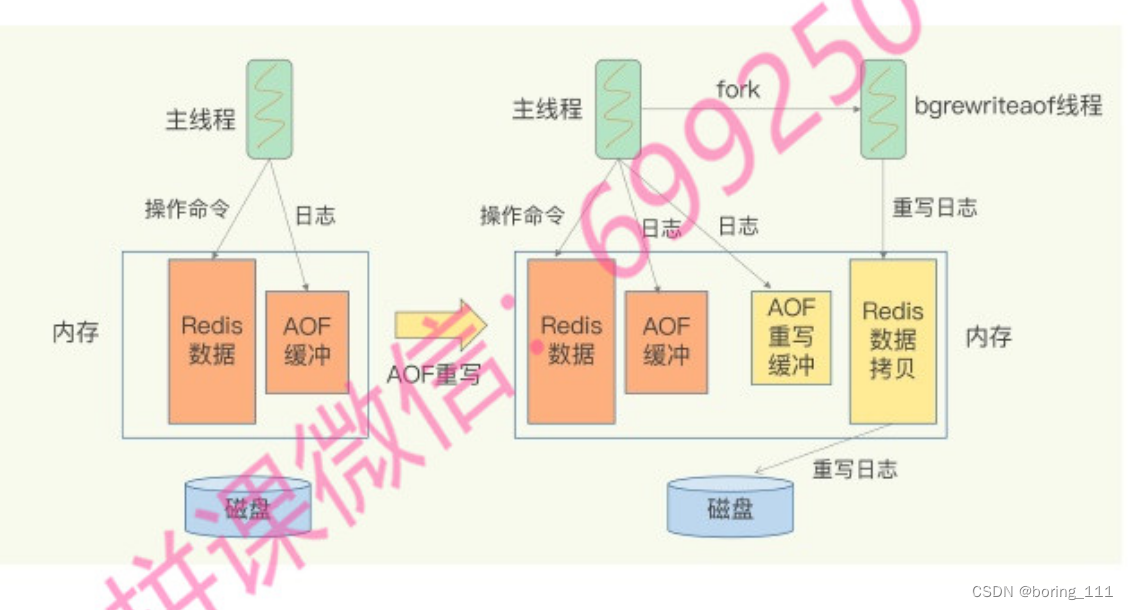
AOF还是有阻塞风险的

AOF重写用两个日志是因为防止污染主日志和减少并发竞争。
内存快照
因为我们在日志里面记录的是操作,如果我们运行了一天挂了,那么我们也要跑上一天来恢复,同理一年也是
内存快照-----------1)对哪些做快照2)做快照时redis是否阻塞
1)全量快照,对每个数据都要做
2)不阻塞,通过fork的copy on write技术来处理,复制内存,然后子进程做快照,父进程进行操作,如果修改了key/value的话,子进程就读取key/value的副本
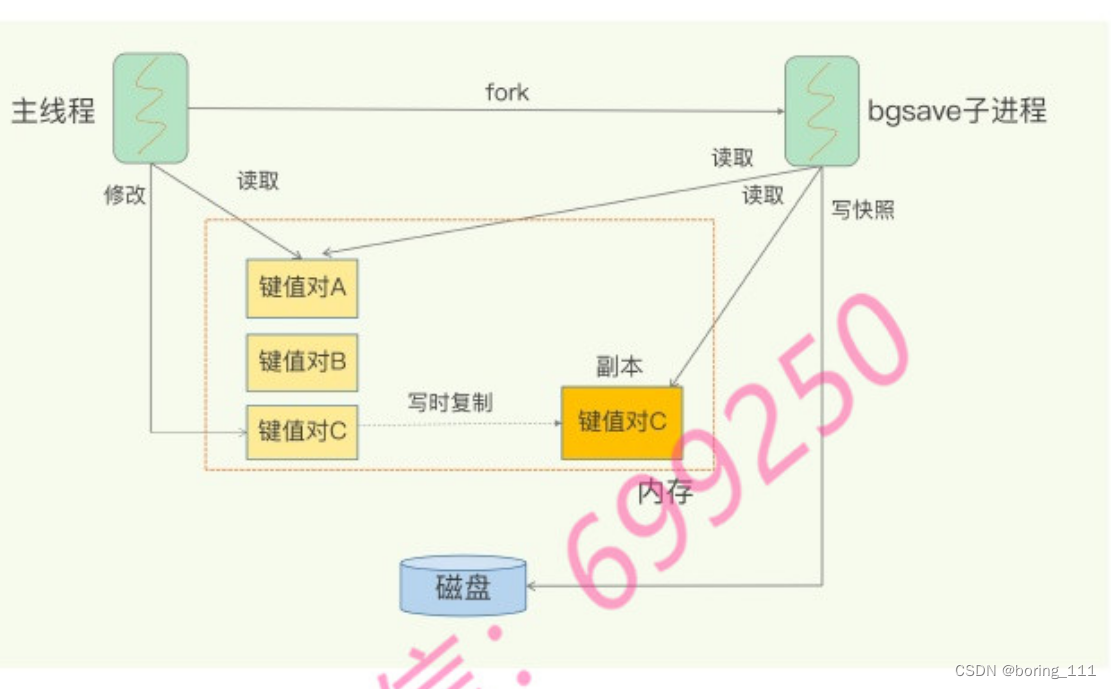
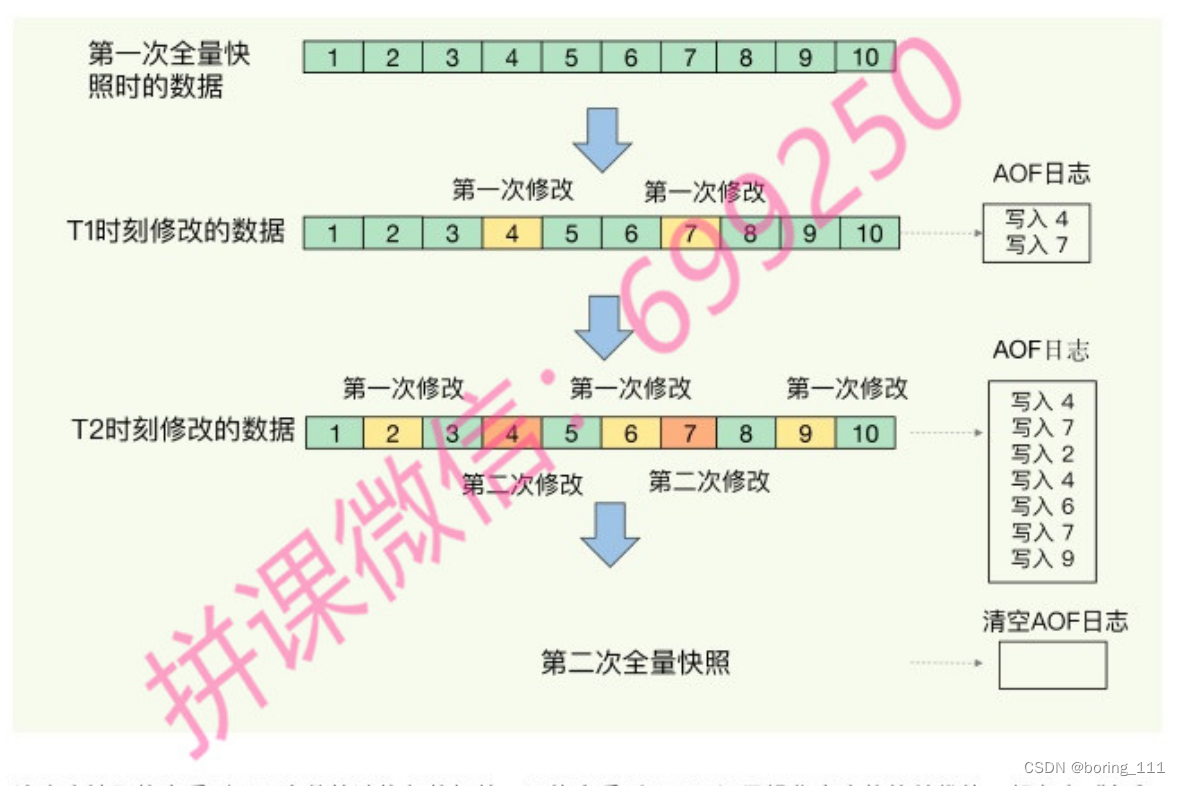
但是内存全量快照负担重,我们可以第一个做全量,后面做增量,也就是快照+AOF的这种结合。就是raft日志快照,和log record一样。


进程绑核是将一个进程或线程固定到一个或多个特定的CPU核心上,以优化系统性能和资源利用率