1 NLP分类之:FastText
0 数据
https://download.csdn.net/download/qq_28611929/88580520?spm=1001.2014.3001.5503
数据集合:0 NLP: 数据获取与EDA-CSDN博客
词嵌入向量文件: embedding_SougouNews.npz
词典文件:vocab.pkl
1 模型
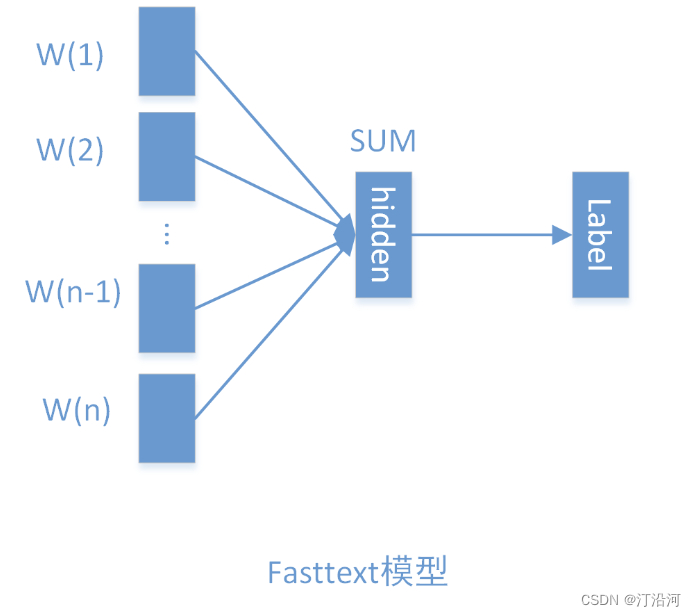
基于fastText做词向量嵌入然后引入2-gram, 3-gram扩充,最后接入一个MLP即可;
fastText 是一个由 Facebook AI Research 实现的开源库,用于进行文本分类和词向量学习。它结合了传统的词袋模型和神经网络的优点,能够快速训练大规模的文本数据。
fastText 的主要特点包括:
1. 快速训练:fastText 使用了层次化 Softmax 和负采样等技术,大大加快了训练速度。
2. 子词嵌入:fastText 将单词表示为字符级别的 n-gram,并将其视为单词的子词。这样可以更好地处理未登录词和稀有词。
3. 文本分类:fastText 提供了一个简单而高效的文本分类接口,可以用于训练和预测多类别文本分类任务。
4. 多语言支持:fastText 支持多种语言,并且可以通过学习共享词向量来提高跨语言任务的性能。
需要注意的是,fastText 主要适用于文本分类任务,对于其他类型的自然语言处理任务(如命名实体识别、机器翻译等),可能需要使用其他模型或方法。
2 代码
nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
`nn.Embedding.from_pretrained` 是 PyTorch 中的一个函数,用于从预训练的词向量加载 Embedding 层的权重。
在使用 `nn.Embedding.from_pretrained` 时,你需要提供一个预训练的词向量矩阵作为参数,
freeze 参数: 指定是否冻结该层的权重。预训练的词向量可以是从其他模型(如 Word2Vec 或 GloVe)中得到的。
y = nn.Embedding.from_pretrained(x)x输入:词的索引
y返回: 词向量
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import pickle as pkl
from tqdm import tqdm
import time
from torch.utils.data import Dataset
from datetime import timedelta
from sklearn.model_selection import train_test_split
from torch.utils.data import Dataset, DataLoader
from collections import defaultdict
from torch.optim import AdamW
UNK, PAD = '<UNK>', '<PAD>' # 未知字,padding符号
RANDOM_SEED = 2023
file_path = "./data/online_shopping_10_cats.csv"
vocab_file = "./data/vocab.pkl"
emdedding_file = "./data/embedding_SougouNews.npz"
vocab = pkl.load(open(vocab_file, 'rb'))
class MyDataSet(Dataset):
def __init__(self, df, vocab,pad_size=None):
self.data_info = df
self.data_info['review'] = self.data_info['review'].apply(lambda x:str(x).strip())
self.data_info = self.data_info[['review','label']].values
self.vocab = vocab
self.pad_size = pad_size
self.buckets = 250499
def biGramHash(self,sequence, t):
t1 = sequence[t - 1] if t - 1 >= 0 else 0
return (t1 * 14918087) % self.buckets
def triGramHash(self,sequence, t):
t1 = sequence[t - 1] if t - 1 >= 0 else 0
t2 = sequence[t - 2] if t - 2 >= 0 else 0
return (t2 * 14918087 * 18408749 + t1 * 14918087) % self.buckets
def __getitem__(self, item):
result = {}
view, label = self.data_info[item]
result['view'] = view.strip()
result['label'] = torch.tensor(label,dtype=torch.long)
token = [i for i in view.strip()]
seq_len = len(token)
# 填充
if self.pad_size:
if len(token) < self.pad_size:
token.extend([PAD] * (self.pad_size - len(token)))
else:
token = token[:self.pad_size]
seq_len = self.pad_size
result['seq_len'] = seq_len
# 词表的转换
words_line = []
for word in token:
words_line.append(self.vocab.get(word, self.vocab.get(UNK)))
result['input_ids'] = torch.tensor(words_line, dtype=torch.long)
#
bigram = []
trigram = []
for i in range(self.pad_size):
bigram.append(self.biGramHash(words_line, i))
trigram.append(self.triGramHash(words_line, i))
result['bigram'] = torch.tensor(bigram, dtype=torch.long)
result['trigram'] = torch.tensor(trigram, dtype=torch.long)
return result
def __len__(self):
return len(self.data_info)
df = pd.read_csv("./data/online_shopping_10_cats.csv")
#myDataset[0]
df_train, df_test = train_test_split(df, test_size=0.1, random_state=RANDOM_SEED)
df_val, df_test = train_test_split(df_test, test_size=0.5, random_state=RANDOM_SEED)
df_train.shape, df_val.shape, df_test.shape
def create_data_loader(df,vocab,pad_size,batch_size=4):
ds = MyDataSet(df,
vocab,
pad_size=pad_size
)
return DataLoader(ds,batch_size=batch_size)
MAX_LEN = 256
BATCH_SIZE = 4
train_data_loader = create_data_loader(df_train,vocab,pad_size=MAX_LEN, batch_size=BATCH_SIZE)
val_data_loader = create_data_loader(df_val,vocab,pad_size=MAX_LEN, batch_size=BATCH_SIZE)
test_data_loader = create_data_loader(df_test,vocab,pad_size=MAX_LEN, batch_size=BATCH_SIZE)
class Config(object):
"""配置参数"""
def __init__(self):
self.model_name = 'FastText'
self.embedding_pretrained = torch.tensor(
np.load("./data/embedding_SougouNews.npz")["embeddings"].astype('float32')) # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 0.5 # 随机失活
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = 2 # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 20 # epoch数
self.batch_size = 128 # mini-batch大小
self.learning_rate = 1e-4 # 学习率
self.embed = self.embedding_pretrained.size(1)\
if self.embedding_pretrained is not None else 300 # 字向量维度
self.hidden_size = 256 # 隐藏层大小
self.n_gram_vocab = 250499 # ngram 词表大小
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.embedding_ngram2 = nn.Embedding(config.n_gram_vocab, config.embed)
self.embedding_ngram3 = nn.Embedding(config.n_gram_vocab, config.embed)
self.dropout = nn.Dropout(config.dropout)
self.fc1 = nn.Linear(config.embed * 3, config.hidden_size)
# self.dropout2 = nn.Dropout(config.dropout)
self.fc2 = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
out_word = self.embedding(x['input_ids'])
out_bigram = self.embedding_ngram2(x['bigram'])
out_trigram = self.embedding_ngram3(x['trigram'])
out = torch.cat((out_word, out_bigram, out_trigram), -1)
out = out.mean(dim=1)
out = self.dropout(out)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
return out
config = Config()
model = Model(config)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
EPOCHS = 5 # 训练轮数
optimizer = AdamW(model.parameters(),lr=2e-4)
total_steps = len(train_data_loader) * EPOCHS
# schedule = get_linear_schedule_with_warmup(optimizer,num_warmup_steps=0,
# num_training_steps=total_steps)
loss_fn = nn.CrossEntropyLoss().to(device)
def train_epoch(model,data_loader,loss_fn,device,n_exmaples,schedule=None):
model = model.train()
losses = []
correct_predictions = 0
for d in tqdm(data_loader):
# input_ids = d['input_ids'].to(device)
# attention_mask = d['attention_mask'].to(device)
targets = d['label']#.to(device)
outputs = model(d)
_,preds = torch.max(outputs, dim=1)
loss = loss_fn(outputs,targets)
losses.append(loss.item())
correct_predictions += torch.sum(preds==targets)
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
#scheduler.step()
optimizer.zero_grad()
return correct_predictions.double() / n_examples, np.mean(losses)
def eval_model(model, data_loader, loss_fn, device, n_examples):
model = model.eval() # 验证预测模式
losses = []
correct_predictions = 0
with torch.no_grad():
for d in data_loader:
targets = d['label']#.to(device)
outputs = model(d)
_, preds = torch.max(outputs, dim=1)
loss = loss_fn(outputs, targets)
correct_predictions += torch.sum(preds == targets)
losses.append(loss.item())
return correct_predictions.double() / n_examples, np.mean(losses)
# train model
EPOCHS = 5
history = defaultdict(list) # 记录10轮loss和acc
best_accuracy = 0
for epoch in range(EPOCHS):
print(f'Epoch {epoch + 1}/{EPOCHS}')
print('-' * 10)
train_acc, train_loss = train_epoch(
model,
train_data_loader,
loss_fn,
optimizer,
device,
len(df_train)
)
print(f'Train loss {train_loss} accuracy {train_acc}')
val_acc, val_loss = eval_model(
model,
val_data_loader,
loss_fn,
device,
len(df_val)
)
print(f'Val loss {val_loss} accuracy {val_acc}')
print()
history['train_acc'].append(train_acc)
history['train_loss'].append(train_loss)
history['val_acc'].append(val_acc)
history['val_loss'].append(val_loss)
if val_acc > best_accuracy:
torch.save(model.state_dict(), 'best_model_state.bin')
best_accuracy = val_acc
备注: CPU训练模型很慢啊!!!有GPU的用GPU吧。大家有想了解的可以私聊。
平均 1epoch / h;
Epoch 1/10 ----------
100%|██████████████████████████████████| 14124/14124 [10:25:00<00:00, 2.66s/it]
Train loss 0.30206009501767567 accuracy 0.9164365618804872 Val loss 0.335533762476819 accuracy 0.9111181905065308 Epoch 2/10 ----------
100%|███████████████████████████████████| 14124/14124 [1:40:00<00:00, 2.35it/s]
Train loss 0.2812397742334814 accuracy 0.924667233078448 Val loss 0.33604823821747 accuracy 0.9114367633004141 Epoch 3/10 ----------
100%|███████████████████████████████████| 14124/14124 [1:26:10<00:00, 2.73it/s]
Train loss 0.26351333512826924 accuracy 0.9319420843953554 Val loss 0.3722937448388443 accuracy 0.9082510353615801