目标检测——R-CNN算法解读
论文:Rich feature hierarchies for accurate object detection and semantic segmentation
作者:Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik
链接:https://arxiv.org/abs/1311.2524
代码:http://www.cs.berkeley.edu/˜rbg/rcnn
文章目录
- 1、算法概述
- 2、R-CNN细节
- 2.1 模型设计
- 2.2 推理阶段
- 2.3 训练过程
- 2.4 Bounding-box回归
- 3、实验结果
- 4、创新点和不足
1、算法概述
R-CNN的过程论文中给了如下框图
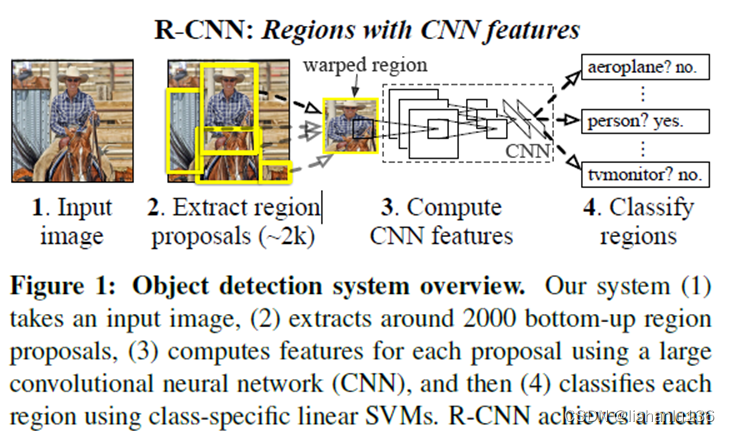
R-CNN的思路很直观,可以分为三步:首先从图片中得到若干个目标候选框,然后对每个候选框利用CNN取特征,最后利用每个候选框的特征对候选框进行分类和边框预测。
在R-CNN论文出来之前,目标检测的流行思路是对图像进行多尺度滑窗得到多个图像块,然后对这些图像块分别提取手工设计特征,比如Haar,HOG等,然后利用这些特征对这些图像块进行分类和调整预测框。对应的经典算法就是Haar+adboost人脸检测,HOG+SVM行人检测。可以想象到的是,这种方法滑窗得到的图像块越多,目标被召回的可能性就越大,当然代价就是检测的速度会变慢,误检也有可能增多;传统思路中的手工设计特征也不一定适合其他任务,比如检测车辆、检测动物等。

所以R-CNN相对于之前的方法创新点可总结为:
1、用Selective Search的候选区域选择方式替换了经典的滑窗方式,使得候选框“少而精”(论文取了2000个候选框);
2、用深度学习神经网络自动学习图像块特征替换了传统方式的手工设计特征。
2、R-CNN细节
2.1 模型设计
区域候选框采用selective search;特征提取采用AlexNet,输入图片固定在227x227大小,提取的特征维度为4096维;图像resize,文中提了几种方式,但是实验下来最佳的方式是先对候选区进行padding,其中padding=16,然后忽略长宽比,直接缩放到网络的输入尺寸。并且提到在所有的方法中,如果扩展的过程中超过了图像,就用图像的平均值填充(在输入CNN前会先减去自身的平均值)。
2.2 推理阶段
在推理阶段,区域候选框被限制在2000个,利用训练好的CNN网络对每个候选框提取4096维特征。对于某个类别,将特征送入对应类别的svm分类器进行预测得分。这样,对于C个类别的任务,每个候选框就有C个分数,最后对这些预测分数后的候选框进行类别独立的非极大值抑制(nms)坐标框合并。
时间分析:区域候选框选择加上特征提取(在GPU上13s/image,在CPU上53s/image)
2.3 训练过程
有监督的预训练,采用AlexNet,用数据集ILSVRC2012进行训练得到
特定领域数据进行微调
1、网络调整:调整AlexNet最后输出的类别数量为N+1类,其中1位背景类别;对于VOC数据集,N=20,对于ILSVRC2013,N=200。
2、样本选择:将用selective search提出的区域候选框(全部使用)与ground-truth(标注框)求iou,iou大于等于0.5的视为该gt标注框所对应类别的正样本。否则为负样本。
3、参数设置:采用SGD优化算法,初始学习率设置为0.001,mini-batch size设置为128,其中32个正样本(涵盖所有类),96个负样本。
训练一组SVM分类器
有多少个类别,就需要训练多少个SVM分类器,每个分类器用于判断输入是否是该类别,并通过预测分数得到该类别的概率。
1、样本选择:正样本为CNN提取的ground truth的特征向量;负样本为CNN提取的iou<0.3的region proposals的特征向量,可见训练SVM用的正负样本要比训练CNN网络的样本定义要严格许多。
2、因为负样本远远大于正样本,造成了正负样本不平衡,所以负样本不能全用,采用了hard negative mining
为什么微调CNN和训练SVM定义正负样本的方式不同,以及为什么要用多个SVM而不是直接在CNN后面用softmax直接预测类别 ?
针对第一个疑问:附录B中说是由于训练SVM是用微调后的CNN提取的特征训练的,而微调CNN是直接针对图片,其实怎么定义正负样本不太重要,重要的是微调的数据量限制,不得不加入iou为0.5到1之间的”抖动”数据,这些数据相对于ground truth增加了30倍;作者也意识到加入这种“抖动”数据可能是次优的,因为CNN网络没有学习到精度定位的数据特征,所以就引出了第二个疑问,为什么作者没有直接在CNN网络接softmax直接预测类别而是接一组SVM,作者试验过在CNN最后一层直接接softmax,最终导致在VOC 2007上mAP从SVM的54.2%下降到50.9%,作者猜测原因有可能是因为由于网络未学习精确定位的正样本和随机抽取的负样本,不像SVM学习的是精确定位的ground truth和通过难度挖掘的负样本。
到这一步,R-CNN算是介绍完了,但利用svm预测到区域候选框的分数后,候选框数量众多且坐标框不一定准,这就需要nms和Bounding-box回归(参考DPM)来修正了。加入bounding-box回归后能提升3到4个mAP。
2.4 Bounding-box回归
作者使用bounding-box回归来提升预测框定位的准确性,当每个候选框通过某个类别的SVM得到预测分数后,也会通过该类别的线性回归器回归到新的坐标框。这种方法类似于DPM的bounding-box,与之不同的是,回归所用的特征这里用的是从CNN提取出来的。
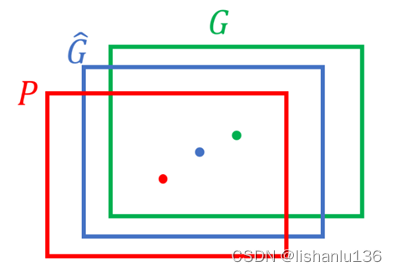
如上图所示,红色框为region proposal,绿色框为ground truth,蓝色框为最终预测的框,也就是想将红色框调整为蓝色框。转换方式如下:
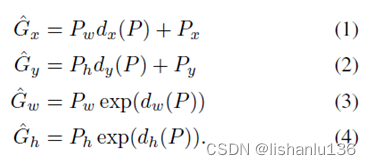
其中Px,Py,Pw,Ph代表region proposal的中心点坐标及宽高。中心点经过平移,宽高通过缩放可以将P转换到G ̂,从转换公式可以看出,就只需要学习dx( P ),dy( P ),dw( P ),dh( P )四个函数即可,每个d*( P )都是一个线性回归函数,它是通过CNN提取P这个区域候选框对应的pool5层特征学习得到的。记为 ,其中w* 就是线性回归需要学习的权重。而红框与绿框之间真正的平移和缩放为:
,其中w* 就是线性回归需要学习的权重。而红框与绿框之间真正的平移和缩放为:
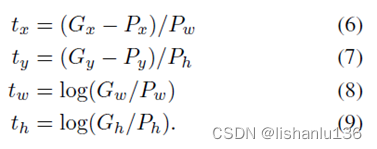
只有当d* 接近于t*的时候,G ̂才接近G,最终利用最小二乘及加上正则化的优化公式为:
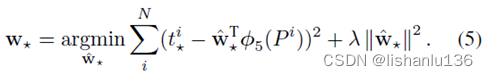
可见学习线性回归,学习的是x,y,w,h的偏移量(平移、缩放),使得P到G ̂的偏移量尽量接近P到G的偏移量。
构造用于训练回归器的样本集,(Pi,Gi),其中P是SS算法生成的region proposal,G是ground truth。只有当IOU(Pi,Gi)>0.6时才可以视为变化是线性的。所以构造数据集时需要当心这点。有了数据集,然后利用上面公式5进行优化,即可得到线性回归器的权值。于是得到了一组BBox Repression。
还需要注意的是,此线性回归器的输入并不是(x,y,w,h)四个值,而是对应的box作为CNN的输入,在pool5提取到的特征,所以训练时回归器时也要先训练好CNN。同时在测试阶段使用线性回归器时,需要得到特定box(经过了NMS)的特征,于是:要么再跑一遍CNN,要么在第一次跑CNN时,记录下所有box的特征。所以由此看出还是比较麻烦的。
3、实验结果
作者在VOC2007和VOC2010上测试结果如下:
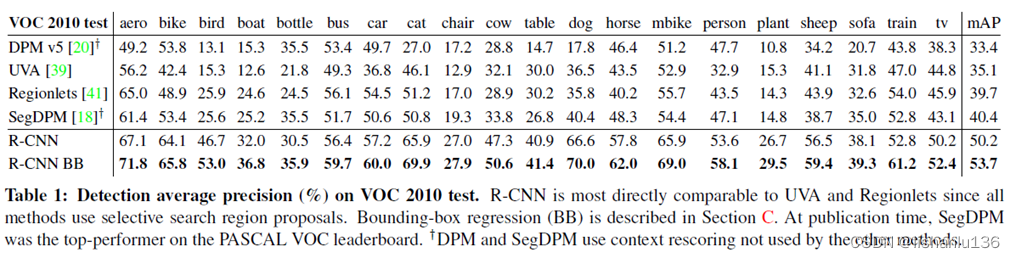
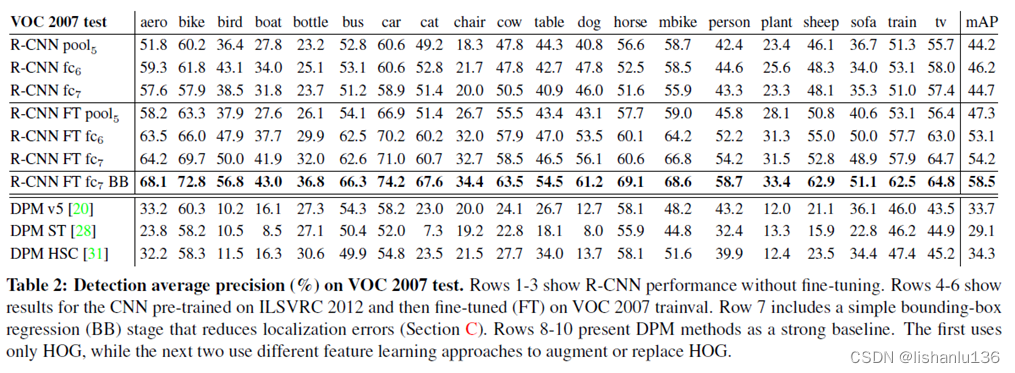
可以看出相对于之前的DPM方法,提升很多;值得注意的是当R-CNN加入了Bounding-box对预测坐标进行修正后,mAP都有3到4个点的提升。
4、创新点和不足
- 创新点:
1、用Selective Search的候选区域选择方式替换了经典的滑窗方式,使得候选框“少而精”。
2、用CNN网络提取特征用于检测 - 不足:
1、候选框区域生成耗时;
2、候选框区域特征提取重复操作;
3、特征提取、SVM分类、边框回归这三个阶段是独立的,需分别进行训练和推理,效率较低。