mysql的组合查询
mysql的组合查询
1、mysql的内连接查询
在 MySQL 中,内连接(INNER JOIN)是一种根据两个或多个表之间的匹配条件,将多个表中的数据进行联接的操作。内连接只返回符合联接条件的行,而不会返回未匹配的行。
内连接的语法如下:
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column_name;
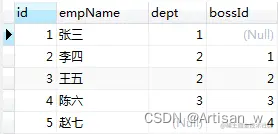
以t_employee(员工表)和t_dept(部门表)为例:
t_employee表中的记录如下:dept代表该员工所在的部门
t_dept表中记录如下:
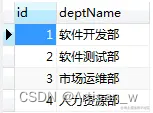
可以发现,其中人力资源部里没有员工(这里只是举例,可能与实际不符,但主要在于逻辑关系),而赵七没有对应的部门,现在想要查询出员工姓名以及其对应的部门名称:
此时,就要使用内连接查询,关键字(inner join)
在这里说一下关联查询sql编写的思路,1,先确定所连接的表,2,再确定所要查询的字段,3,确定连接条件以及连接方式
select
e.empName,d.deptName
from t_employee e
INNER JOIN t_dept d
ON e.dept = d.id;
)
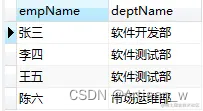
其中,没有部门的人员和部门没有员工的部门都没有被查询出来,这就是内连接的特点,只查询在连接的表中能够有对应的记录,其中e.dept = d.id是连接条件
需要注意这两个表的地位是平等的,如果其中一个表没有与另一个表相关连的数据,那么数据就不会显示出来
在内部具体的执行流程为:
1、打开第一个表,并按照 SELECT 语句中指定的列列表读取数据。
2、对于第一个表中的每一行数据,打开第二个表,并按照 SELECT 语句中指定的列列表读取数据。
4、对于第二个表中的每一行数据,比较两个表中的关联列是否匹配,如果匹配,则将两个表中的所有列组合成一行,并添加到结果集中。
5、如果两个表中存在相同列名的列,将在列名前加上表名作为前缀。
6、如果需要,按照 ORDER BY 子句中指定的顺序对结果集进行排序。
7、如果需要,应用 LIMIT 和 OFFSET 子句对结果集进行分页。
8、返回查询结果。
2、左外连接查询
是指以左边的表的数据为基准,去匹配右边的表的数据,如果匹配到就显示,匹配不到就显示为null,例如上面的实例
语法为:
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;
其中,table1 和 table2 是要进行联接的两个表,column_name 是两个表中要进行匹配的列的名称。在 ON 子句中,需要指定两个表中要进行匹配的列的名称。
此外,左外连接还有其他类型的语法,如 LEFT OUTER JOIN 等,这些语法可以更改联接方式或使用不同的联接条件。
SELECT e.empName,d.deptName
from t_employee e
LEFT OUTER JOIN t_dept d
on d.id = e.dept;
结果为:

3、右外连接查询
右外连接是同理的,只是基准表的位置变化了而已,以右边的表为基准。
在mysql的内部,右外连接也会转化为等价的左外连接。
4、mysql的union查询(全外连接的一种形式,实际不支持全外连接)
在 MySQL 中,UNION 是一种用于组合多个 SELECT 语句结果集的操作符。UNION 操作符将多个 SELECT 语句的结果集合并成一个结果集,并去除重复的行。
UNION 操作符的语法如下:
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;
其中,table1 和 table2 是两个要合并的表,它们必须具有相同数量和数据类型的列,列的顺序也必须相同。UNION 操作符会按照 SELECT 语句的顺序合并两个结果集,并去除重复的行。
注意,UNION 操作符会对结果集进行排序。如果您需要按照特定的顺序组合结果集,可以使用 ORDER BY 子句。例如:
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2
ORDER BY column_name;
如果您需要组合多个结果集,可以使用多个 UNION 操作符。例如:
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2
UNION
SELECT column_name(s) FROM table3;
这将组合三个结果集,并去除重复的行。
注意,如果要使用 UNION 操作符,必须确保每个 SELECT 语句返回相同数量和类型的列。如果不是这样,可以使用 NULL 补充缺失的列。例如:
SELECT column1, column2 FROM table1
UNION
SELECT column1, NULL FROM table2;
这样可以确保两个结果集返回相同数量和类型的列,从而可以使用 UNION 操作符组合它们。
union 与union all
1、UNION 和 UNION ALL 都是 MySQL 中用于合并两个或多个 SELECT 语句的操作符。它们的区别如下:
UNION 对结果集去重,UNION ALL 不对结果集去重。
UNION 操作符需要对结果集进行排序,而 UNION ALL 不需要排序。因此,UNION 的性能一般比 UNION ALL 差。
UNION 可以使用 ORDER BY 子句对结果集进行排序,而 UNION ALL 不支持 ORDER BY 子句。
UNION ALL 的语法比 UNION 简单,因此在一些场景下使用 UNION ALL 可以减少代码的复杂性。
总的来说,UNION 适用于需要合并两个或多个结果集,并去除重复数据的场景。而 UNION ALL 适用于需要合并两个或多个结果集,但不需要去除重复数据的场景。由于 UNION ALL 不需要进行排序和去重操作,因此它的性能通常比 UNION 更快,尤其是在处理大量数据时。
需要注意的是,在使用 UNION 或 UNION ALL 操作符时,要保证 SELECT 语句中查询的列数、数据类型和顺序都一致,否则会导致合并结果集失败。
2、UNION 和 UNION ALL 的性能差异通常是由以下两个原因造成的:
去重排序操作
UNION 运算符会对结果集进行去重排序,而 UNION ALL 不会去重排序。去重排序是一个非常耗费计算资源的操作,因为需要对结果集进行排序,并且需要对每一条记录进行比较。如果结果集非常大,去重排序的代价就会非常昂贵,导致查询性能下降。
执行计划
在执行查询时,MySQL 会根据查询语句生成一个执行计划,用于指导数据库引擎执行查询操作。对于 UNION 和 UNION ALL 操作,由于它们的语义不同,生成的执行计划也会有所不同。
在执行 UNION 操作时,MySQL 需要将所有结果集合并在一起,并对结果集进行去重排序。为了完成这个操作,MySQL 通常会使用一些额外的排序算法和临时表,这些操作会增加查询的执行时间和计算负担。
相比之下,UNION ALL 操作不需要进行去重排序,因此可以避免这些额外的操作。这使得 MySQL 可以更轻松地优化 UNION ALL 查询的执行计划,提高查询性能。
综上所述,由于需要进行去重排序等额外的操作,UNION 的性能通常比 UNION ALL 差。但是,对于需要去重操作的场景,UNION 仍然是一个非常有用的操作符。
优化器对于关联查询的处理与优化
下面是大致的内部处理过程:
解析 SQL 语句:MySQL首先需要解析查询语句并生成执行计划。在这个阶段,MySQL 将检查查询中使用的表和列是否存在,并且会根据 WHERE 子句和 JOIN 条件来确定哪些索引可以使用,以及执行联接的顺序等信息。
优化执行计划:MySQL 接下来会对执行计划进行优化,目的是生成最优的执行计划。这个阶段包括以下步骤:
a. 估算查询成本:MySQL 会估算每个可能的执行计划的成本,并选择最优的执行计划。成本估算的主要依据包括查询的数据量、磁盘 I/O 操作和 CPU 负载等。
b. 选择最优的执行计划:MySQL 会比较所有可能的执行计划的成本,并选择最优的执行计划。
c. 生成执行计划:MySQL 会根据最优的执行计划,生成用于执行查询的代码。
执行联接查询:MySQL 接下来会执行联接查询,具体步骤如下:
a. 打开第一个表:MySQL 打开查询中的第一个表,并读取其中的数据。
b. 执行联接查询:MySQL 对于第一个表中的每一行,会在第二个表中查找匹配的行,并将两个表中匹配的行组合成一行。
c. 筛选结果:MySQL 根据 WHERE 子句中指定的条件对结果进行筛选。
d. 排序结果:如果有 ORDER BY 子句,则 MySQL 会对结果进行排序。
e. 分页结果:如果有 LIMIT 和 OFFSET 子句,则 MySQL 会对结果进行分页。
f. 返回结果集:最后,MySQL 将结果集返回给客户端。
如果关联查询中涉及到了很多表,那么查询优化器会尝试生成不同的执行计划,并对每个执行计划的执行代价进行评估,然后选择代价最小的执行计划。关联查询优化器在生成执行计划时,会根据查询的具体情况和数据库的统计信息等,进行综合考虑,选择最优的执行计划。
当涉及到大量的表时,查询优化器通常会采用一些特殊的算法来生成执行计划,以减少执行代价和查询时间。其中,一种常用的算法是基于动态规划的算法,该算法可以通过多次扫描表,计算出最优的执行计划,并将其缓存起来以便重复使用。
或者表关联太多就会使用贪婪算法。
此外,查询优化器还可以利用一些特殊的技术来优化查询性能,例如将关联查询中的子查询转化为连接查询,利用索引和缓存来提高查询效率等等。总之,查询优化器在处理大量表的关联查询时,会根据具体情况进行优化,并尽可能选择最优的执行计划,以提高查询性能。