人工智能学习8(集成学习之xgboost)
编译工具:PyCharm
文章目录
- 编译工具:PyCharm
- 集成学习
- XGBoost(Extreme Gradient Boosting)极端梯度提升树
- 1.最优模型的构建方法
- XGBoost目标函数
- 案例1:泰坦尼克号
- 案例2:对奥拓集团差评进行正确分类。
- 数据准备:
- 1.第一种基础的训练方式(不全,作对比)
- 2.第二种优化后的训练方式
- 2.1数据处理部分
- 2.2模型训练及调优
集成学习
解决欠拟合问题:弱弱组合变强,boosting
解决过拟合问题:互相遏制变壮,Bagging
集成学习(Ensemble learning)通过构建并结合多个学习器来完成学习任务。
同质
同质(homogeneous)集成:集成中只包含同种类型的“个体学习器”相应的学习算法称为“基学习算法”(base learning algorithm)
个体学习器亦称“基学习器”(base learner)
异质(heterogeneous)集成:个体学习器由不同的学习算法生成不存在“基学习算法”
Bagging方法(并行)
boosting方法(串行)基本思想:基分类器层层叠加,每一层在训练的时候对前一层基分类器分错的样本给予更高的权重。
XGBoost(Extreme Gradient Boosting)极端梯度提升树
1.最优模型的构建方法
构建最优模型的一般方法:最小化训练数据的损失函数。
(1.1)经验风险最小化,训练得到的模型复杂度哈皮,但是当训练数据集较小的时候,模型容易出现问题。

为进度模型复杂度,采用(2.1)结构风险最小化,它对训练数据以及未知数据都有较好的预测。
J(f)是模型的复杂度

应用:
决策树的生成:经验风险最小化
剪枝:结构风险最小化
XGBoost的决策树生成:结构风险最小化
XGBoost目标函数
正则化损失函数:

CART树

树的复杂度

目标函数:
目标函数推导过程

分裂节点计算
分开前-分开后,结果>0,可以进行分裂,<0不进行
γ:减去一个加入新叶子节点引入的复杂度代价。

案例1:泰坦尼克号
数据集:https://hbiostat.org/data/repo/titanic.txt
# xgboost
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split # 进行数据集划分
from sklearn.feature_extraction import DictVectorizer
import matplotlib.pyplot as plt
from xgboost import XGBClassifier
# 读取数据
# titan = pd.read_csv("https://hbiostat.org/data/repo/titanic.txt")
titan = pd.read_csv("./data/titanic.csv")
# print(titan.describe())
# 获取样本和目标值
# 这里取pclass社会等级、age年龄、sex性别作为特征值
# 取survived存活为目标值
x = titan[["pclass","age","sex"]]
y = titan["survived"]
# 缺失值处理:对age为空的用平均值替换
x['age'].fillna(value=titan["age"].mean(),inplace=True)
# print(x.head())
# 数据集划分
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=22,test_size=0.2)
# 特征抽取(字典特征提取)
x_train = x_train.to_dict(orient="records")
x_test = x_test.to_dict(orient="records")
tranfer = DictVectorizer()
x_train = tranfer.fit_transform(x_train)
x_test = tranfer.fit_transform(x_test)
# xgboost 初步模型训练
# 实例化
xg = XGBClassifier()
# 训练
xg.fit(x_train,y_train)
# 初步模型评估
print("xg初步模型训练评估: ",xg.score(x_test, y_test))
# xgboost 调优模型训练
depth_range = range(5)
score = []
for i in depth_range:
xg=XGBClassifier(eta=1,gamma=0,max_depth=i)
xg.fit(x_train,y_train)
s = xg.score(x_test,y_test)
print("第",i+1,"次训练评估: ",s)
score.append(s)
# 对调优结果可视化
# plt.plot(depth_range,score)
# plt.show()

案例2:对奥拓集团差评进行正确分类。
数据准备:
数据集:https://download.csdn.net/download/weixin_42320758/15728128?utm_source=bbsseo
使用pycharm下载包的时候,容易下载不成功,建议使用清华大学提供的网站进行下载
-i https://pypi.tuna.tsinghua.edu.cn/simple 包名称
在命令行进行下载也可以使用:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple


1.第一种基础的训练方式(不全,作对比)
数据分割使用:train_test_split
模型训练选择:RF进行模型训练
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 欠采样方法从大量数据中抽取数据
from imblearn.under_sampling import RandomUnderSampler
# 将标签转化为数字
from sklearn.preprocessing import LabelEncoder
# 数据分割
from sklearn.model_selection import train_test_split
# RF模型训练
from sklearn.ensemble import RandomForestClassifier
# log_loss模型评估
from sklearn.metrics import log_loss
# one-hot处理数据
from sklearn.preprocessing import OneHotEncoder
# 获取数据
data = pd.read_csv("./data/otto_train.csv")
# 数据标签可视化,查看数据的分布情况
sns.countplot(data.target)
plt.show()
x = data.drop(["id","target"], axis=1)
y = data["target"]
# 数据已结果脱敏处理(保护一些隐私等信息的安全)
# 截取部分数据进行训练(防止数据量过大)
# 使用欠采样的方法获取数据,注意:不能直接按照前n行的方式进行截取
rus = RandomUnderSampler(random_state=0)
x_resampled,y_resampled = rus.fit_resample(x,y)
sns.countplot(y_resampled)
plt.show()
# 将标签转数字
le = LabelEncoder()
y_resampled = le.fit_transform(y_resampled)
print(y_resampled)
# 数据分割
x_train,x_test,y_train,y_test = train_test_split(x_resampled,y_resampled,test_size=0.2)
print(x_train.shape,y_train.shape)
print(x_test.shape,y_test.shape)
# 模型训练1
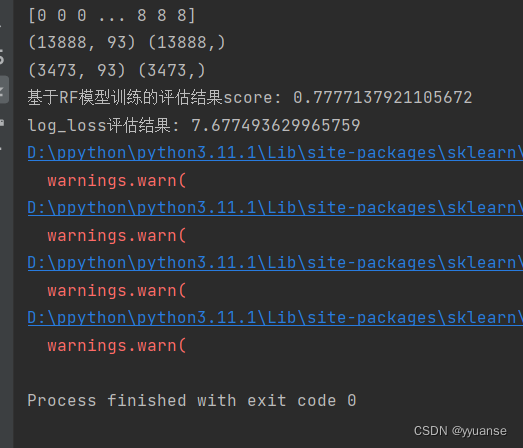
# 基于RF模型训练
rf = RandomForestClassifier(oob_score=True)
rf.fit(x_train,y_train)
y_pre = rf.predict(x_test)
print("基于RF模型训练的评估结果score:",rf.score(x_test, y_test))
# log_loss模型评估
# log_loss(y_test,y_pre,eps=1e-15,normalize=True) # 这样子写会报错,log_loss中要求输出用one-hot表示
# one-hot处理
one_hot=OneHotEncoder(sparse=False)
y_test1=one_hot.fit_transform(y_test.reshape(-1,1))
y_pre1 = one_hot.fit_transform(y_pre.reshape(-1,1))
print("log_loss评估结果:",log_loss(y_test1, y_pre1, eps=1e-15, normalize=True))
原始数据标签可视化,,查看数据的分布情况

数据量过大,用欠采样的方法抽取部分数据后,标签可视化:

输出结果:
2.第二种优化后的训练方式
数据分割处理:StratifiedShuffleSplit
2.1数据处理部分
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 欠采样方法从大量数据中抽取数据
from imblearn.under_sampling import RandomUnderSampler
# 将标签转化为数字
from sklearn.preprocessing import LabelEncoder
# 数据分割
from sklearn.model_selection import StratifiedShuffleSplit
# 数据标准化
from sklearn.preprocessing import StandardScaler
# 数据pca降维
from sklearn.decomposition import PCA
# 获取数据
data = pd.read_csv("./data/otto_train.csv")
# 数据标签可视化,查看数据的分布情况
# sns.countplot(data.target)
# plt.show()
x = data.drop(["id","target"], axis=1)
y = data["target"]
# 数据已结果脱敏处理(保护一些隐私等信息的安全)
# 截取部分数据进行训练(防止数据量过大)
# 使用欠采样的方法获取数据,注意:不能直接按照前n行的方式进行截取
rus = RandomUnderSampler(random_state=0)
x_resampled,y_resampled = rus.fit_resample(x,y)
# sns.countplot(y_resampled)
# plt.show()
# 将标签转数字
le = LabelEncoder()
y_resampled = le.fit_transform(y_resampled)
print("标签转为数值后: ",y_resampled)
# 数据分割
x_train = []
x_val = []
y_train = []
y_val=[]
sss = StratifiedShuffleSplit(n_splits=1,test_size=0.2,random_state=0)
for train_index,test_index in sss.split(x_resampled.values,y_resampled):
# print(len(train_index))
# print(len(test_index))
x_train = x_resampled.values[train_index] # 训练集的数据
x_val = x_resampled.values[test_index] # 测试集的数据
y_train = y_resampled[train_index] # 训练集的标签
y_val = y_resampled[test_index] # 测试集的标签
print("训练集和测试集的大小:",x_train.shape,x_val.shape)
# 分割后的数据可视化
# sns.countplot(y_val)
# plt.show()
# 数据标准化
scaler = StandardScaler()
scaler.fit(x_train)
x_train_scaled = scaler.transform(x_train)
x_val_scaled = scaler.transform(x_val)
# 数据pca降维
pca = PCA(n_components=0.9)
x_train_pca = pca.fit_transform(x_train_scaled)
x_val_pca = pca.transform(x_val_scaled)
print("pca降维后: ",x_train_pca.shape,x_val_pca.shape)
# 可视化数据降维信息变化程度
plt.plot(np.cumsum(pca.explained_variance_ratio_))
# plt.xlabel("元素数量")
# plt.ylabel("可表达信息的百分占比")
plt.show()


2.2模型训练及调优

这一段运行起来需要些时间
# 模型训练
# 基本模型训练
xgb = XGBClassifier()
xgb.fit(x_train_pca,y_train)
# 输出预测值(一定是输出带有百分比的预测值)
y_pre_proba = xgb.predict_proba(x_val_pca)
# log-loss评估
print("基础训练的log_loss评估值: ",log_loss(y_val, y_pre_proba, eps=1e-15, normalize=True))
# 模型调优
scores_ne = []
n_estimators = [100,200,300,400,500,550,600,700]
for nes in n_estimators:
print("n_estimators: ",nes)
xgb=XGBClassifier(max_depth=3,learning_rate=0.1,n_estimators=nes,objective="multi:softprob",
n_jobs=-1,nthread=4,min_child_weight=1,subsample=1,colsample_bytree=1,seed=42)
xgb.fit(x_train_pca,y_train)
y_pre = xgb.predict_proba(x_val_pca)
score = log_loss(y_val,y_pre)
scores_ne.append(score)
print("每次测试的log_loss评估值为:{}".format(score))
# 图形化logloss
plt.plot(n_estimators,scores_ne,"o-")
plt.xlabel("n_estimators")
plt.ylabel("log_loss")
plt.show()
print("最优的e_estimators的值是: {}".format(n_estimators[np.argmin(scores_ne)]))
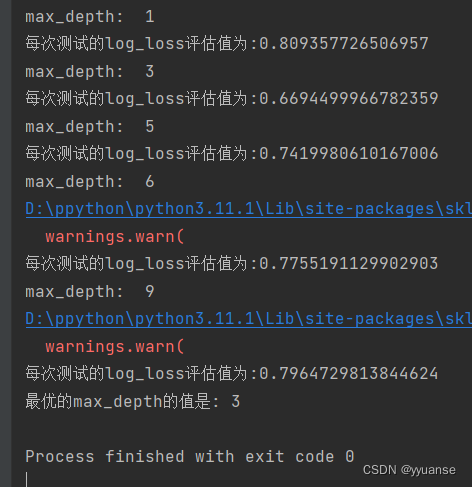
# 最优max_depth的调试
scores_md = []
max_depths = [1,3,5,6,9]
for md in max_depths:
print("max_depth: ",md)
xgb=XGBClassifier(max_depth=md,learning_rate=0.1,n_estimators=n_estimators[np.argmin(scores_ne)],objective="multi:softprob",
n_jobs=-1,nthread=4,min_child_weight=1,subsample=1,colsample_bytree=1,seed=42)
xgb.fit(x_train_pca,y_train)
y_pre = xgb.predict_proba(x_val_pca)
score = log_loss(y_val,y_pre)
scores_md.append(score)
print("每次测试的log_loss评估值为:{}".format(score))
# 图形化logloss
plt.plot(max_depths,scores_md,"o-")
plt.xlabel("max_depths")
plt.ylabel("log_loss")
plt.show()
print("最优的max_depth的值是: {}".format(max_depths[np.argmin(scores_md)]))
# (省略)调优min_child_weights,subsamples,consample_bytrees,etas
# 调优后这几个参数为min_child_weight=3,subsample=0.7,consample_bytree=0.7
# 找到最优参数后
xgb = XGBClassifier(max_depth=3,learning_rate=0.1,n_estimators=600,objective="multi:softprob",nthread=4,min_child_weight=3,subsample=0.7,colsample_bytree=0.7,seed=42)
xgb.fit(x_train_pca,y_train)
# y_pre = xgb.predict_proba(x_val_scaled)
y_pre = xgb.predict_proba(x_val_pca)
print("测试数据的log_loss值为: {}".format(log_loss(y_val,y_pre,eps=1e-15,normalize=True)))


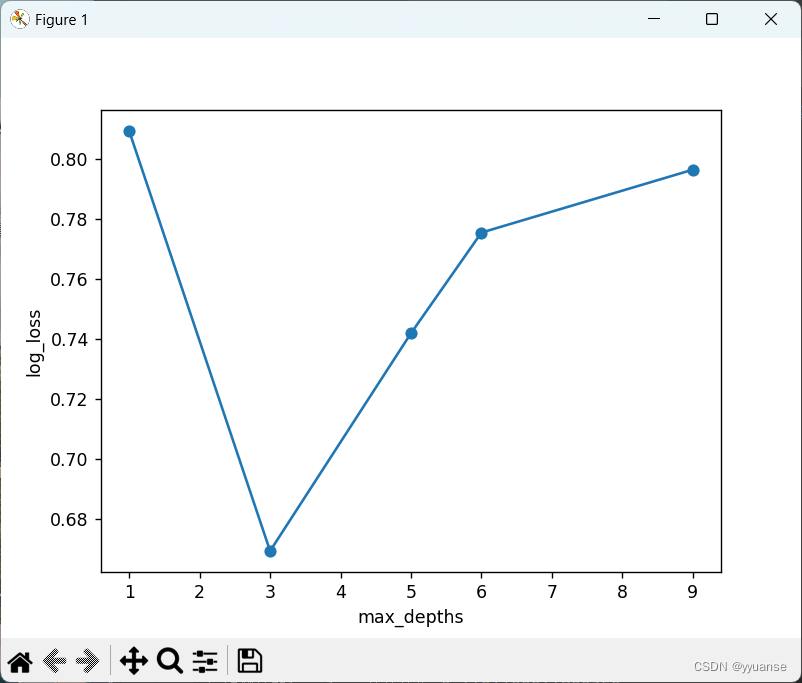
由于有好几个参数min_child_weights,subsamples,consample_bytrees没有跑,没找出最优的值,所以最后的log_loss的值还是有些大的。
