prometheus|云原生|轻型日志收集系统loki+promtail的部署说明
一,
日志聚合的概念说明
- 日志------
每一个程序,服务都应该有保留日志,日志的作用第一是记录程序运行的情况,在出错的时候能够记录错误情况,简单来说就是审计工作,例如nginx服务的日志,kubernetes集群的pod运行日志,Linux系统的系统日志。
其次是数据库的日志,记录数据库的运行细节,在需要的时候通过日志回溯数据库动作,比如MySQL数据库的binlog日志,这类日志比较特殊,基本没有聚合的意义。
- 日志聚合----
指的是将分散在各个服务器上的日志统一一个入口程序来查看其内容,并可通过关键字或者正则表达式搜索特定的管理人员感兴趣的内容,例如,efk日志系统,elastisearch负责将分散的日志收集,flueed将es收集的日志进行预处理以符合我们的审计工作需求,最终通过kibana这个web界面查看这些分散于各个服务器的日志,以提高管理服务器的效率,毕竟,日志没有聚合的时候,我们是需要每个服务器都登陆,然后找到相应的日志文件,打开日志文件,检索需要的内容这样一个复杂的流程,而聚合日志后,通过特定标签就可以查询检索到我们需要的信息了。
那么,现在的常用日志聚合系统有elk,efk,毫无疑问的,这些系统是比较重的,复杂的(架构复杂,所以维护管理也复杂,在系统出现问题的时候会比较难以判断,解决),而这些无疑是会提高我们的使用门槛的,毕竟,如果是在生产上,我们可能希望这个日志系统是稳定高效的,那么,es可能就需要以集群的架构来部署,f或者l可能也需要集群的架构,而集群的维护和管理工作这些都限制了我们使用的欲望。
OK,有没有一个相对elk这样的日志系统更为简单的,查询效率更高的日志系统呢?答案当然是 ---必须有,loki+promtail+grafana基本可以满足中小企业的日志聚合功能。
那么,本文将就loki+promtail+grafana这个日志聚合系统的部署和简单使用做一个尽量详尽的介绍。
二,
架构说明
日志收集器---promtail ,负责将需要聚合的日志发送到loki,通常每个日志节点都需要安装
日志处理器---loki,负责将promtail推送过来的日志打上特定标签,管理这些聚合到的日志,应用层的服务,带有api,通常只安装这么一个服务
日志展示部分---grafana,展示数据,也就是web端展示,日志的内容统一暴露接口,通常只安装这么一个服务
本文使用的是centos7操作系统
三,
部署方式
部署方式非常多,helm,kubernetes内集成yaml清单形式,二进制,rpm安装包形式,docker容器形式都可以,本文主要是二进制的方式安装
二进制方式安装部署的优点是部署简单,方便,形式灵活,可深度定制
四,
二进制安装包的获取
百度网盘下载地址:链接:https://pan.baidu.com/s/1XKqwdJrrYYewsAcy8foQ5Q?pwd=kkey
提取码:kkey
或者在github官网下载,地址为:
Releases · grafana/loki · GitHub
五,
loki的部署
相关介质上传到服务器上后,解压,编写配置文件,文件内容如下:
cat >loki-cfg.yaml<<EOF
auth_enabled: false
server:
http_listen_port: 13100 #http监听端口,代理服务(promtail)会向此端口发送日志流
grpc_listen_port: 9086 #grpc监听端口,简单部署不用管
ingester:
lifecycler:
address: 192.168.123.11
ring:
kvstore:
store: inmemory
replication_factor: 1
final_sleep: 0s
chunk_idle_period: 5m
chunk_retain_period: 30s
max_transfer_retries: 0
schema_config:
configs:
- from: 2023-12-02 #2023-12-02之后loki信息用下面的配置,这个主要是用来做兼容的
store: boltdb #索引使用哪种存储
object_store: filesystem #怎么存储,简单部署的话保存在本地文件系统
schema: v11
index:
prefix: index_
period: 24h #索引期限24小时
storage_config:
boltdb:
directory: /tmp/loki/index
filesystem:
directory: /tmp/loki/chunks
limits_config:
enforce_metric_name: false
reject_old_samples: true
reject_old_samples_max_age: 168h
ingestion_rate_mb: 32 #采集速率
ingestion_burst_size_mb: 64 #单次采集大小
max_entries_limit_per_query: 0 #查询返回的条目的最大行数,默认是5000,0表示无限制
retention_period: 24h #全局保留期,超过这个时间的日志会被删除,具体删除规则在compactor里配置
#retention_stream: #局部保留期
#- selector: '{level="error"}'
# priority: 1
# period: 720h
chunk_store_config:
max_look_back_period: 0s #最大日志可见时间,0表示一直可见。or 24h等等
table_manager:
retention_deletes_enabled: false
retention_period: 0s
compactor:
working_directory: /data/loki/compactor #compactor运行状态保存目录
shared_store: filesystem
retention_enabled: true #启动日志删除
compaction_interval: 10m #compactor每隔10分钟运行一次
retention_delete_delay: 2h #在compactor运行2小时后删除
retention_delete_worker_count: 150 #用150个worker删除chunks
analytics:
reporting_enabled: false #关闭向loki团队发送此配置文件
EOF配置文件说明:
ingestion_rate_mb: 32 #采集速率,如果日志量比较大的话,需要调整的
ingestion_burst_size_mb: 64 #单次采集大小,如果日志量比较大的话,需要调整的
max_entries_limit_per_query: 0 #查询返回的条目的最大行数,默认是5000,0表示无限制这三个是比较重要的,其它的其实是可以默认的,就性能比较好
在Loki中,对于客户端push到distributor中产生的每条日志流是可以对其做条目的大小限制的,这个在配置里面默认是不限制,也就是说每行的日志大小可以是无限?,当然大部分情况下我们都不会去限制这个,如果有的同学环境特殊,可以考虑开启对每行日志的大小限制。
limits_config: # 日志条目的大小限制,默认不限制 max_line_size: | default = none除此之外,对于单次查询的限制还有的chunk、stream和series的,不过大部分场景我们不会去对此做调整
limits_config: # 单个查询最多匹配的chunk个数 max_chunks_per_query: | default = 2000000 # 限制查询是匹配到的chunk大小,默认0为不限制 max_query_length: | default = 0 # 单词查询最多匹配到的日志流个数 max_streams_matchers_per_query: | default = 1000 # 限制查询时最大的日志度量个数 max_query_series: | default = 500 # 查询的并发数 max_query_parallelism | default = 14 # 允许租户缓存结果的有效时间 max_cache_freshness_per_query |default = 1m.
启动脚本:
/var/log/loki/ 目录需要提前建立,/opt/loki/loki-linux-amd64 是loki的执行程序,/opt/loki/loki-cfg.yaml是loki的配置文件绝对路径
cat >/etc/systemd/system/loki.service <<EOF
[Unit]
Description=loki
After=network.target
[Service]
ExecStart=/opt/loki/loki-linux-amd64 -config.file=/opt/loki/loki-cfg.yaml &>> /var/log/loki/loki.log
ExecReload=/bin/kill -s HUP $MAINPID
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TimeoutStartSec=0
Delegate=yes
KillMode=process
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
EOF启停和自动启动:
systemctl enable loki && systemctl start loki && systemctl status loki六,
promtail的部署
promtail的配置文件:
这个是一个非常简单的静态读取/var/log/目录下的log后缀文件信息,并上传到loki
cat promtail_config.yaml
server:
http_listen_port: 9080
grpc_listen_port: 0
# 记录读取日志的位置信息文件,Promtail重新启动时需要它
positions:
filename: /tmp/positions.ymal
# Loki的api服务的地址
clients:
- url: http://192.168.123.11:13100/loki/api/v1/push
scrape_configs:
- job_name: system
static_configs:
- targets:
- localhost
labels:
job: varlogs
__path__: /var/log/*log
promtail的启动脚本:
cat >/etc/systemd/system/promtail.service <<EOF
[Unit]
Description=promtail
After=network.target
[Service]
ExecStart=/opt/loki/promtail-linux-amd64 -config.file=/opt/loki/promtail_config.yaml &>> /var/log/promtail/promtail.log
ExecReload=/bin/kill -s HUP
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TimeoutStartSec=0
Delegate=yes
KillMode=process
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
EOF七,
grafana部署安装
这个没什么好说的,rpm安装启动服务就可以了
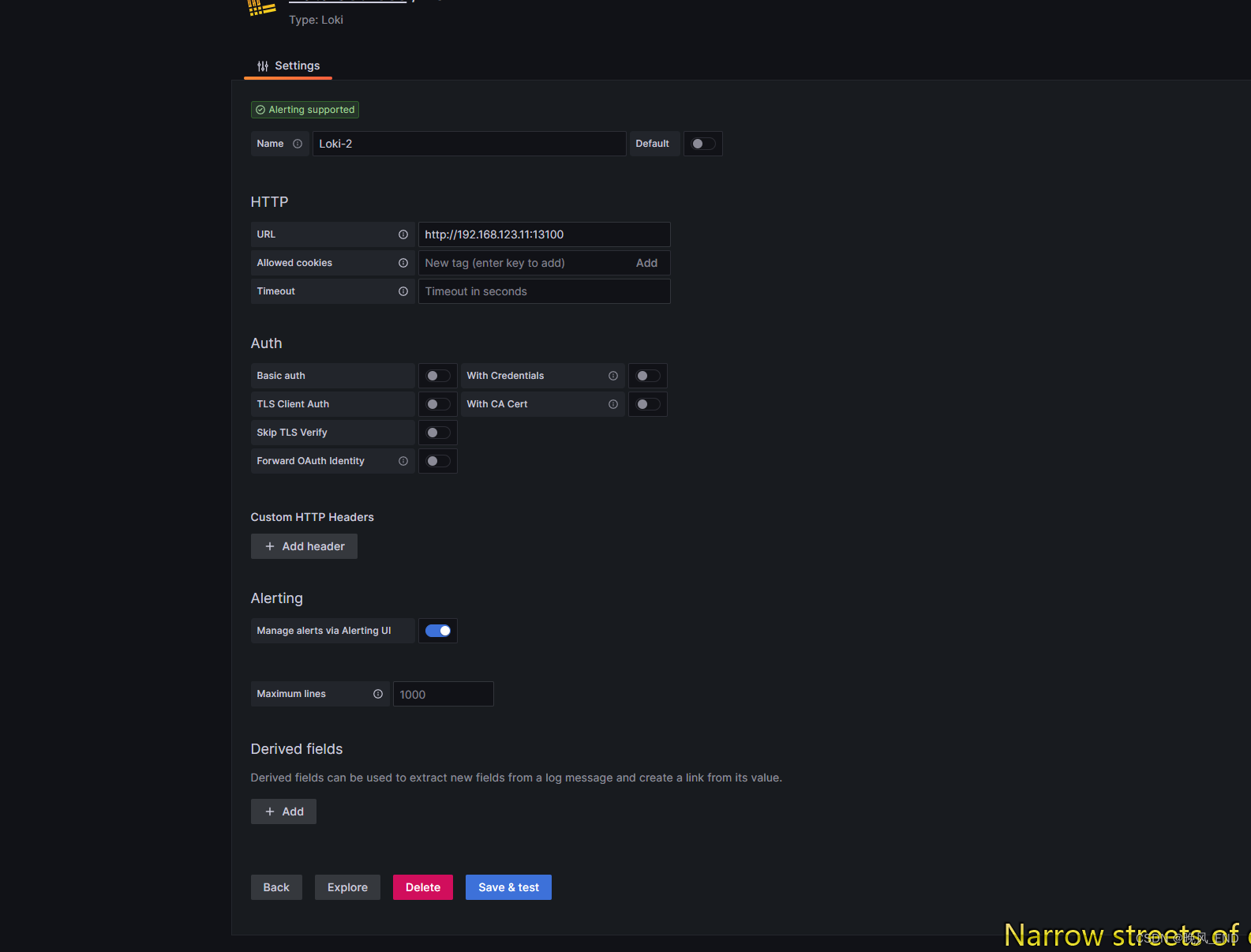
添加数据源
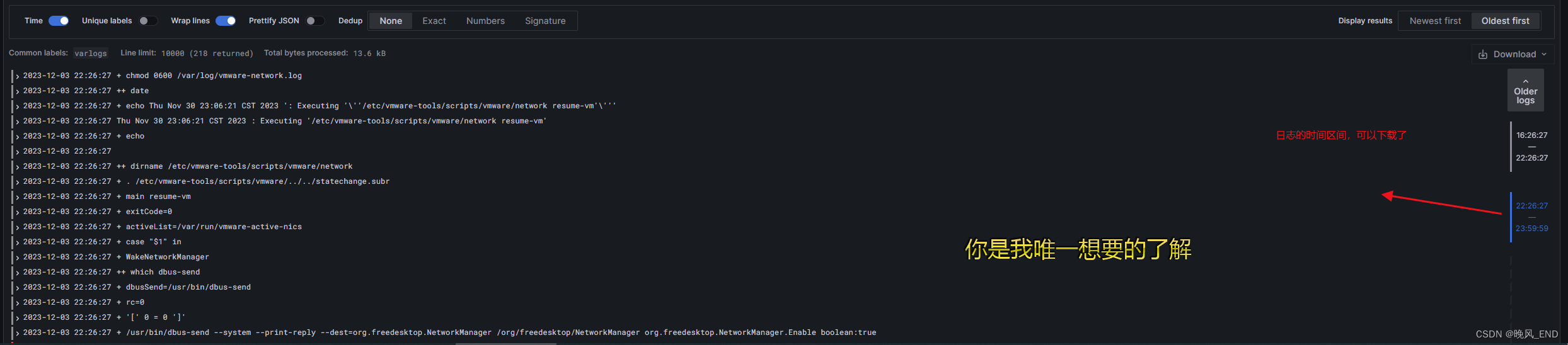
直接explore就可以看到如下了:

点击label browser 可以看到:



多说一句,内存和CPU最好还是给的高一点,一开始我只给的4G loki服务经常卡掉,很难受,给到8G后就流畅很多了。