numpy实现神经网络
numpy实现神经网络
首先讲述的是神经网络的参数初始化与训练步骤
随机初始化
任何优化算法都需要一些初始的参数。到目前为止我们都是初始所有参数为0,这样的初始方法对于逻辑回归来说是可行的,但是对于神经网络来说是不可行的。如果我们令所有的初始参数都为0,这将意味着我们第二层的所有激活单元都会有相同的值。同理,如果我们初始所有的参数都为一个非0的数,结果也是一样的。
我们通常初始参数为正负ε之间的随机值
训练神经网络一般步骤
- 参数的随机初始化
- 利用正向传播方法计算所有的 h θ ( x ) h_{\theta}(x) hθ(x)
- 编写计算代价函数 J J J 的代码
- 利用反向传播方法计算所有偏导数
- 利用数值检验方法检验这些偏导数
- 使用优化算法来最小化代价函数
激活函数和参数初始化
sigmoid函数
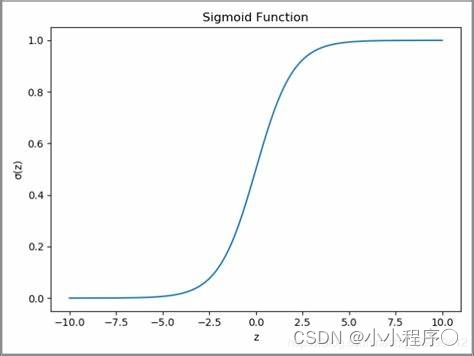
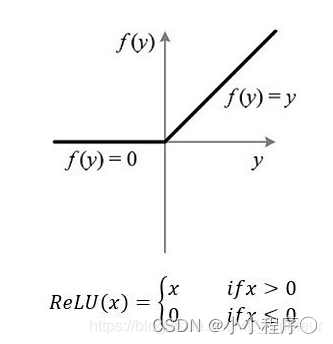
relu函数:
import numpy as np
# sigmoid激活函数
def sigmoid(x):
return 1/(1+np.exp(-x))
# relu激活函数
def relu(x):
return np.maximum(0, x)
# sigmoid反向传播函数
def sigmoid_back(x):
return x*(1-x)
# relu反向传播函数
def relu_back(x):
return np.where(x > 0, 1, 0)
#初始化参数
def initialize(input_size,hidden_size,output_size):
'''
input_size 输入层列数
hidden_size 隐藏层列数
output_size 输出层列数
'''
np.random.seed(42)
input_hidden_weights=np.random.randn(input_size,hidden_size)
input_hidden_bias=np.zeros((1,hidden_size))
hidden_out_weights=np.random.randn(hidden_size,output_size)
hidden_out_bias=np.zeros((1,output_size))
return input_hidden_weights,input_hidden_bias,hidden_out_weights,hidden_out_bias
前向传播和反向传播函数
# 前向传播
def forward(inputs,input_hidden_weights,input_hidden_bias,hidden_out_weights,hidden_out_bias):
hidden_input=np.dot(inputs,input_hidden_weights)+input_hidden_bias
hidden_output=relu(hidden_input)
final_input=np.dot(hidden_output,hidden_out_weights)+hidden_out_bias
final_output=sigmoid(final_input)
return hidden_output,final_output
# 后向传播
def backward(inputs,hidden_output,final_output,target,hidden_out_weights):
output_error = target - final_output
output_delta = output_error * sigmoid_back(final_output)
hidden_error = output_delta.dot(hidden_out_weights.T)
hidden_delta = hidden_error * relu_back(hidden_output)
return output_delta,hidden_delta
更新参数
# 更新参数
def update(inputs, hidden_output, output_delta, hidden_delta, input_hidden_weights, input_hidden_bias,
hidden_output_weights, hidden_output_bias, learning_rate):
hidden_output_weights =hidden_output_weights+ hidden_output.T.dot(output_delta) * learning_rate
hidden_output_bias = hidden_output_bias+ np.sum(output_delta, axis=0, keepdims=True) * learning_rate
input_hidden_weights = input_hidden_weights+ inputs.T.dot(hidden_delta) * learning_rate
input_hidden_bias = input_hidden_bias+ np.sum(hidden_delta, axis=0, keepdims=True) * learning_rate
return input_hidden_weights,input_hidden_bias,hidden_output_weights,hidden_output_bias
训练及预测模型
#训练模型
def train(inputs, target, input_size, hidden_size, output_size, learning_rate, epochs):
input_hidden_weights,input_hidden_bias,hidden_output_weights,hidden_output_bias=initialize(input_size,hidden_size,output_size)
# 梯度下降优化模型
for epoch in range(epochs):
hidden_output,final_output=forward(inputs,input_hidden_weights,input_hidden_bias,hidden_output_weights,hidden_output_bias)
output_delta,hidden_delta=backward(inputs,hidden_output,final_output,target,hidden_output_weights)
input_hidden_weights,input_hidden_bias,hidden_output_weights,hidden_output_bias=update(inputs,hidden_output,output_delta,hidden_delta,
input_hidden_weights,input_hidden_bias,hidden_output_weights,hidden_output_bias,learning_rate)
# 计算损失
loss = np.mean(np.square(targets - final_output))
if epoch % 100 == 0:
print(f"Epoch {epoch}: Loss {loss}")
return input_hidden_weights,input_hidden_bias,hidden_output_weights,hidden_output_bias
# 预测模型
def predict(inputs, input_hidden_weights, input_hidden_bias, hidden_output_weights,hidden_output_bias):
_, result = forward(
inputs, input_hidden_weights, input_hidden_bias, hidden_output_weights, hidden_output_bias)
return [1 if y_hat>0.5 else 0 for y_hat in result]
检验模型
# 定义训练数据和目标
inputs = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
target = np.array([[0], [1], [1], [0]])
# 定义神经网络参数
input_size = 2
hidden_size = 4
output_size = 1
learning_rate = 0.1
epochs = 1000
# 训练神经网络
parameters = train(inputs, target, input_size, hidden_size, output_size, learning_rate, epochs)
# 预测
predictions = predict(inputs, *parameters)
print("预测结果:")
print(predictions)
最终结果
