Java数据结构之《构造哈夫曼树》(难度系数85)
一、前言:
这是怀化学院的:Java数据结构中的一道难度中等(偏难理解)的一道编程题(此方法为博主自己研究,问题基本解决,若有bug欢迎下方评论提出意见,我会第一时间改进代码,谢谢!) 后面其他编程题只要我写完,并成功实现,会陆续更新,记得三连哈哈! 所有答案供参考,不是标准答案,是博主自己研究的写法。(这一个题书上也有现成类似的代码,重要的是理解它的算法原理!)
二、题目要求如下:
(第 16 题)构造哈夫曼树(难度系数85+%5)(自己添加的%5哈哈)
构造哈夫曼树
题目描述:
根据给定的叶结点字符及其对应的权值创建哈夫曼树。
输入:
第一行为叶子结点的数目n(1<=n<=100)。第二行为一个字符串,包含n个字符,每个字符对应一个叶子结点,第三行为每个叶子结点的概率(即权值),要求根据各叶结点构造哈夫曼树。构造哈夫曼树的原则是先两个最小的,构造一个父结点,其中最小的结点为左孩子,次小的为右孩子,如果两个最小的叶结点相等,则取排在前一个位置的为左孩子。
输出:
哈夫曼树的权值,左孩子,右孩子及其对应的父亲,相邻数据之间用空格隔开;
输入样例:
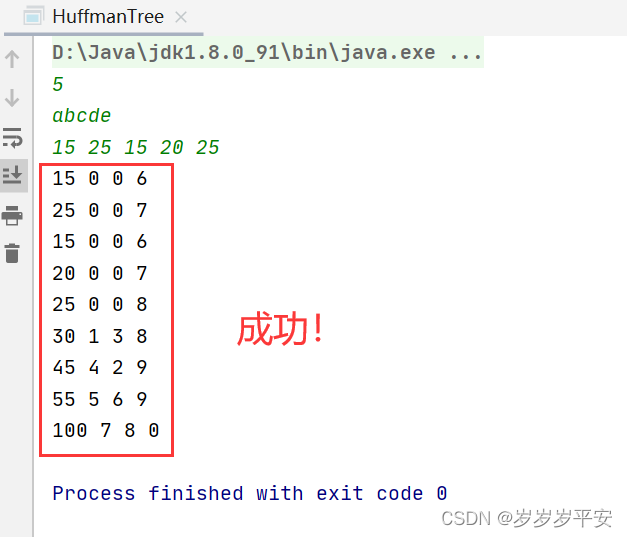
5
abcde
15 25 15 20 25
输出样例:
15 0 0 6
25 0 0 7
15 0 0 6
20 0 0 7
25 0 0 8
30 1 3 8
45 4 2 9
55 5 6 9
100 7 8 0
补充:题目意思一定要深度揣摩一下,没有提示就得自己根据它题目给的输入输出来推一下原理了,不然就是盲目下手出错很多!
三、代码实现: (代码的做题原理全部在代码注释中,若还有疑问也可以翻书关于哈夫曼树的构造原理的内容)
补充:应该当你放到考试系统里检测代码是否正确时,请把所有的代码注释去掉哦!不过是自己的编译器应该没问题的
(1)我把所有的实现细节全部放到一个类里了:(解释已经尽力详细了...)
package com.fs.demo;
import java.util.Scanner;
public class HuffmanTree {
//构建结点静态内部类
private static class Node{
private int data; //当前哈夫曼树的总值
//题目中要求输出的左孩子和右孩子结点都是用数字表示,父结点也是一样
private int lchild; //左孩子
private int rchild; //右孩子
private int parent; //父结点
//默认初始化;没有左孩子、右孩子以及父结点默认数值为0
public Node(){
this.data=0;
this.lchild=0;
this.rchild=0;
this.parent=0;
}
}
public static void main(String[] args) {
Scanner sc =new Scanner(System.in);
int n=sc.nextInt(); //代表最先给的叶子结点的个数
String node01 = sc.next(); //代表n个叶子结点组成的字符串
// 之所以把存储每个结点的数组长度设为(2*n-1),
// 是因为在非空二叉树中,拥有2个度的结点=叶子结点个数-1,则整个构造成功的哈夫曼树的结点总数=n*n-1=2*n-1
Node [] node = new Node[2*n-1];
for(int i=0;i<n;i++){
node[i]=new Node(); //在结点数组中依次给前面输入的叶子结点创建空间
node[i].data=sc.nextInt(); //给前面几个叶子结点依次赋值
}
//控制最大只能到2*n-1个结点也就是到(2*n-1)-1下标
for(int j=0;j<n-1;j++){
int low01=-1; //所有可以相加的叶子结点或者叶子结点+生成的父结点中两个权值最小的那个的下标
int low02=-1; //所有可以相加的叶子结点或者叶子结点+生成的父结点中两个权值次小的那个的下标
//注意最后只有0~(n-1)-1的下标中还没选完的最小和次小的下标作为根节点,因为最后生成的根结点是最终的哈夫曼树的最大总权值
for(int k=0;k<n+j;k++){ //随着新建的"父"结点加入,下标会逐渐超过原来的(n-1)
//寻找最小下标的最终值(这里不好用文字解释,需要自己拿笔对着题目试运行去理解了)
//也就是依次判断所有的结点的权值相比较,最小的那个
//条件首先是要找没有父结点的结点(也就是根结点),再其次判断:该位置的结点的值:是否比假定最小下标的值还小,如果是把当前位置的下标就赋给设定的最小下标,再继续循环,直到找完所有符合条件的
if(node[k].parent==0 && (low01==-1 || (node[k].data<node[low01].data) )){ //"||"如果前面满足后面不会执行
low02=low01;
low01=k; //每找到一次就覆盖一次下标值
}else if(node[k].parent==0&&(low02==-1|| (node[k].data<node[low02].data) )){ //寻找次小下标的最终值(这里不好用文字解释,需要自己拿笔对着题目试运行去理解了)
low02=k;
}
}
//当我们找到第一组符合权值最小和次小的结点时:如下操作
//每次相加成功的某2个叶子结点或者某1个叶子结点+生成的父结点生成的结点存放在结点数组的新位置
node[n+j]=new Node(); //且位置下标最大不超出(2*n-1)-1下标
node[n+j].data=node[low01].data+node[low02].data; //新生成的这个结点的权值为:没加过的结点中的最小小标和次小下标结点的值的和
node[n+j].lchild=low01+1; //可以去想最开始的叶子结点是不是最小下标和次小下标都是默认-1,加1就代表0:表示没有孩子结点
node[n+j].rchild=low02+1; //而后面的左孩子和右孩子表示都是之前在原来最初的结点数组(也就是输入后的)所处的位置,例如(low01=0)+1=1 表示:a是它的左孩子.(low02=1)+1=2,表示:b是它的右孩子
//例如30是第6个结点(5+0+1)
node[low01].parent=node[low02].parent=n+j+1;
}
for(int i=0;i<2*n-1;i++){
//依次输出当前状态两个结点构造的哈夫曼树的总权值、左子树、右子树与父结点的
System.out.print(node[i].data+" "+node[i].lchild+" "+node[i].rchild+" "+node[i].parent);
System.out.println();
}
}
}四、代码测试运行结果:
<1>题目的输入样例测试情况: