python数据分析
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
使用pandas进行数据预处理
- 实训1 合并年龄、平均血糖和中风患者信息数据
- 1. 训练要点
- 2. 需求说明
- 3. 实现思路及步骤
- 实训2 删除年龄异常的数据
- 1. 训练要点
- 2. 需求说明
- 3. 实现思路及步骤
- 实训3 离散化年龄特征
- 1.训练要点
- 2. 需求说明
- 3. 实现思路及步骤
实训1 合并年龄、平均血糖和中风患者信息数据
1. 训练要点
(1)掌握判断主键的方法
(2)掌握主键合并的方法
2. 需求说明
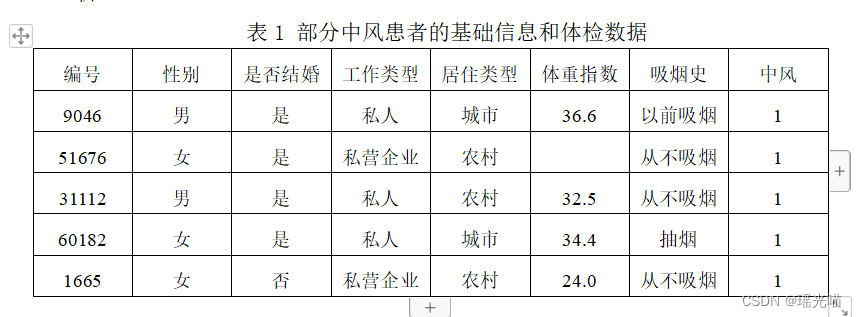
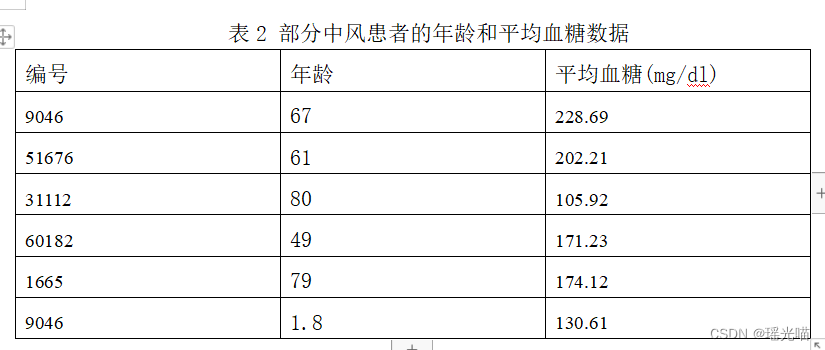
我国始终把保障人民健康放在优先发展的战略位置。“上医治未病”,建立疾病预防控制体系有利于从源头上预防和控制重大疾病。某医院为了早期监测预警患者的中风风险,对现有中风患者的基础信息和体检数据 (healthcare-dataset-stroke.xlsx)进行分析,其部分数据如表 1所示。经观察发现患者基础信息和体检数据中缺少中风患者的年龄和平均血糖的信息,然而在年龄和平均血糖数据(healthcare-dataset-age-abs.xlsx)中存放了分析所需的中风患者的年龄和平均血糖信息,其部分数据如表2所示。现需要对患者的年龄平均血糖数据与患者基础信息和体检数据进行合并,以便下一步分析。
3. 实现思路及步骤
# 实训1 合并年龄、平均血糖和中风患者信息数据
import pandas as pd
import numpy as np
# (1)利用read_excel 函数读取 healthcare-dataset-age_abs.xlsx表
ageabs=pd.read_excel("healthcare-dataset-age_abs.xlsx")
ageabs.head()
# (2)利用read_excel 函数读取 healthcare-dataset-age_abs.xlsx表
stroke=pd.read_excel("healthcare-dataset-stroke.xlsx")
stroke.head()
# (3)查看两表的数据量。
ageabs.count()
stroke.count()
# (4)以编号作为主键进行外连接
stroke1=pd.merge(stroke,ageabs,on="编号")
# (5)查看数据是否合并成功
stroke1.head()
实训2 删除年龄异常的数据
1. 训练要点
掌握异常值数据处理的方法。
2. 需求说明
基于实训1的数据,经观察发现在年龄特征中存在异常值( 年龄数值为小数如 1.8),为了避免异常值数据对分析结果造成不良影响,需要对异常值进行处理。
3. 实现思路及步骤
# 实训2 删除年龄异常的数据
# (1)获取年龄特征
age = pd.DataFrame(stroke1['年龄'])
age.head()
# (2)利用for 循环获取年龄特征中的数值,并用 if-else 语句判断年龄数值是否为异常值。
n = 0
for i in age.values:
if i[0] <0:
age.drop(level=i[0])
else:
n=n+1
print(n)
age.head()
实训3 离散化年龄特征
1.训练要点
(1)掌握函数的创建与使用方法。
(2)掌握离散化连续型数据 的方法。
2. 需求说明
用分类算法预测患者是否中风时,算法模型要求数据是离散的。在题目 2中已对年龄特征异常值进行了处理,现需要将连续型数据变换为离散型数据,使用等宽法对年龄特征进行离散化。
3. 实现思路及步骤
代码如下(示例):
# 3. 离散化年龄特征
# (1)获取年龄特征。
# (2)使用等宽法离散化对年龄特征进行离散化。
data = stroke1['年龄']
list(data)
# 可视化
def cluster_plot(d, k):
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(12, 4))
for j in range(0, k):
plt.plot(data[d == j], [j for i in d[d == j]], 'o')
plt.ylim(-0.5, k - 0.5)
return plt
# data = np.random.randint(1, 100, 200)
k = 10 # 分为5个等宽区间
# 等宽离散
d1 = pd.cut(data, k, labels=range(k))
cluster_plot(d1, k).show()
#吸烟状态与中风发病率的关系
ax = sns.countplot("stroke",hue="smoking_status",data=data)
plt.ylabel("中风发病率")
annot_plot(ax)
plt.show()
#bmi箱线图
sns.boxplot(x="stroke",y="bmi",data=data)
plt.ylabel("中风与不中风人群的bmi分布情况")
plt.show()