hive里如何高效生成唯一ID
常见的方式:
hive里最常用的方式生成唯一id,就是直接使用 row_number() 来进行,这个对于小数据量是ok的,但是当数据量大的时候会导致,数据倾斜,因为最后生成全局唯一id的时候,这个任务是放在一个reduce里进行的,数据量过大会有很大的瓶颈。
优化的方式:
主体的思想就是先分再合,参考下一个思路:

这个思路是借鉴了一篇文章的思路:附上链接:bitmap用户分群方法在贝壳DMP的实践和应用_架构_侯学博_InfoQ精选文章
我是只想用sql来做具体的实现,如何实现最好呢?
1:将数据打散,分为N份
2:在这N份里,先分别给一个行号使用row_number()
3: 统计出来每份里有多少条数据(这个数据要在第四步里使用)
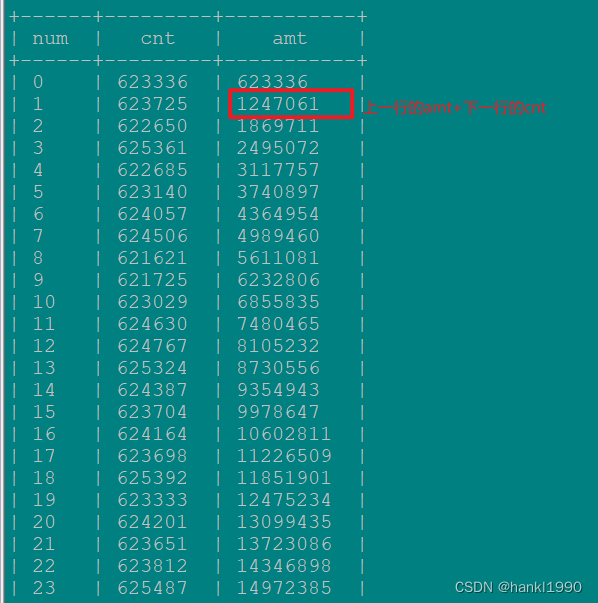
4: 计算出来到当前分片最大的行号是多少(这个就是我如下图示里的,上一个分片的最大行号+下当前分片数据的条数)sum() over() 来实现的
with temp01 as (
select
iccid,
imsi,
cast(rand() * 200 as bigint) num
from
原始表
where
date_id = '20231123';
)
select
a.iccid,
a.imsi,
a.num as a_num,
a.rn,
b.num as b_num,
b.cnt,
b.amt,
nvl(b.amt, 0) + rn as final_num
from
(
select
iccid,
imsi,
num,
ROW_NUMBER() OVER(PARTITION BY num) AS rn
from
temp01
) a
left outer JOIN (
select
num,
cnt,
// 这个sum就是生成到当前分区最大的行号是多少,这里一定要理解sum() over这个窗口函数是怎么个原理。再强调一次:是到当前分区累加起来的行号。
sum(cnt) over(
order by
num
) amt
from
(
select
num,
count(*) cnt
from
temp01
group by
num
) a
) b on a.num -1 = b.num;配上完整的sql实现逻辑: