2023.12.1 --数据仓库之 拉链表
目录
什么是拉链表
为什么要做拉链表?
没使用拉链表:
使用了拉链表:
题中订单拉链表的形成过程
实现语句
什么是拉链表
拉链表是缓慢渐变维的一种解决方案.
拉链表,记录每条信息的生命周期,一旦一条记录的生命周期结束,就重新开始一条新的记录,并把当前日期放入生效开始日期,如果当前信息至今都有效,就在结束日期中填入一个最大值(9999-12-31)
为什么要做拉链表?
拉链表适合于:数据会发生变化,但是大部分是不变的
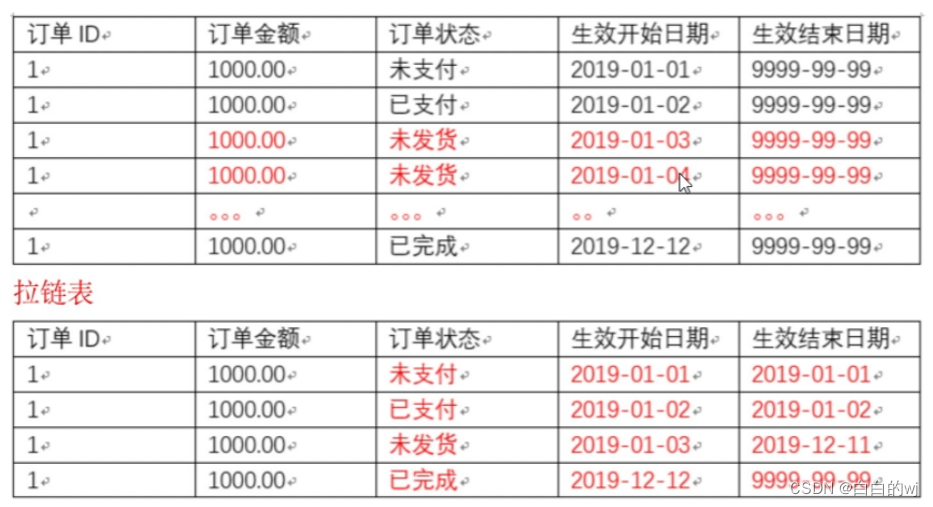
比如:订单信息从未支付、已支付、未发货、已完成等状态经历了一周,大部分时间是不变化的,如果数据量有定规模,无法按照每天全量的方式保存。
没使用拉链表:
从上图可以看到,如果按照上面那个表的记录方法,因为订单未发货的状态从1月持续到了12月,假如一直都是全量同步的方式,那么未发货这条信息,我们将需要用350多行来记录维护他,但对客户来说,或者维护人员来说,我们关心的是订单状态转换的那一刻,在这期间的信息并不重要,所以这种记录方法这会导致冗余过多
使用了拉链表:
从上图的下面那张图可以看到,原本我们需要用350多行来维护未发货这条状态的信息,使用了拉链表后,我们只需要一行,即可涵盖了1月3日到12月11日这300多天的状态.
题中订单拉链表的形成过程

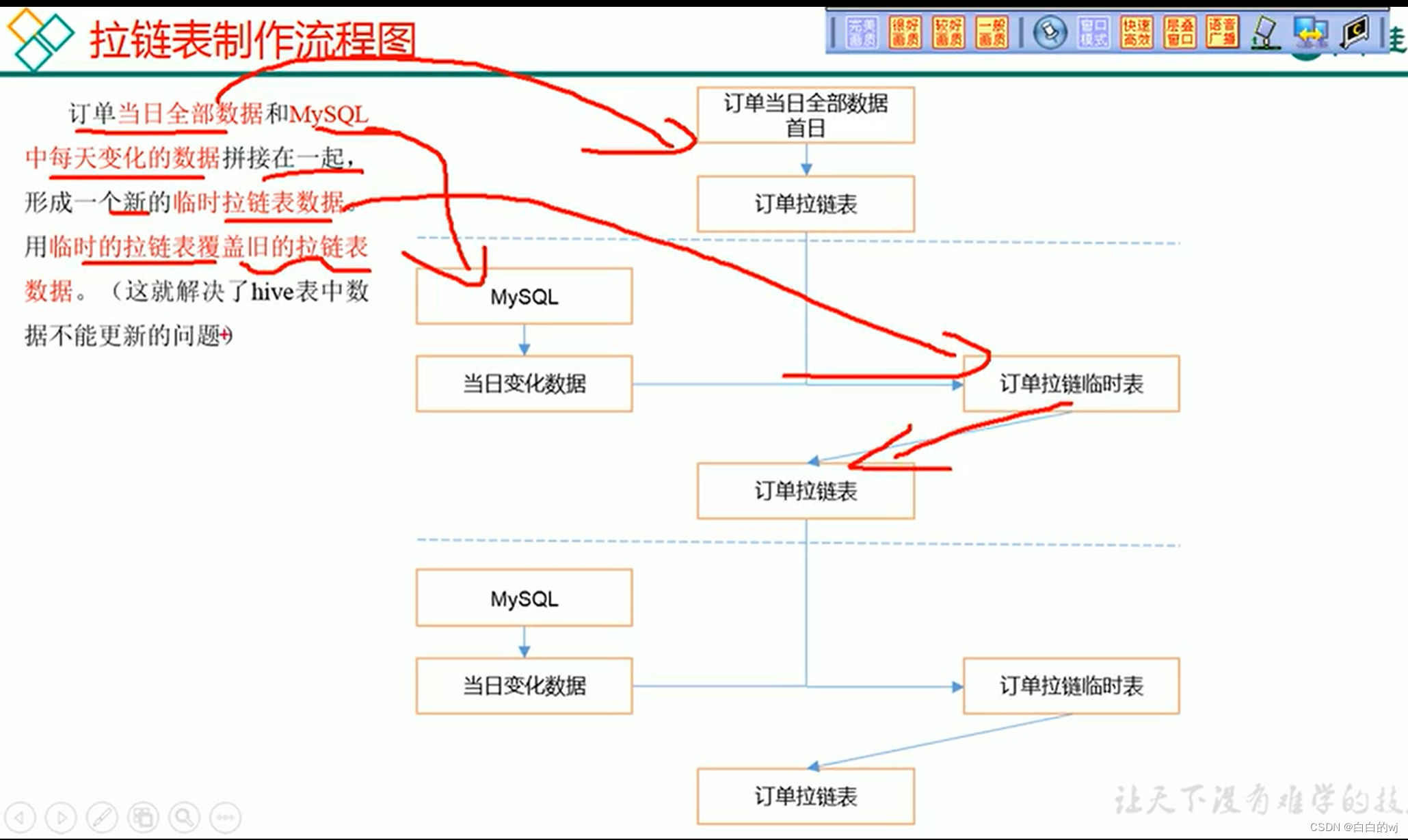
制作拉链表,简单来说就是在表原本的字段上,再加上两列字段,一个是开始时间,一个是结束时间
然后每天找出新增和变化的订单导入到拉链表中,通过合并初始的表和新增变化的表,就能得到对应的拉链表
实现语句
1.从ods层得到每天更新或者新增的数据表
2.原始拉链表 left join 增量表,如果增量表关联id为null或者原始拉链表end_time不是9999-12-31(9999说明这是最新的状态) ,保留原有数据,否则修改拉链表的end_time为增量表中的start_time 减去 1
3.拿着left join 修改后的拉链数据,直接union all 增量数据集
4.把最新拉链数据保存到临时表中
5.insert overwrite 把数据插入到原始拉链表中
