Pandoc 从入门到精通,你也可以学会这一个文本转换利器
Pandoc 简介
如果你需要在不同的文件格式之间相互转换,多半听说或使用过文档转换的瑞士军刀——Pandoc。事实上,不仅人类知道 Pandoc,最近很火的人工智能 ChatGPT 也知道「将 Markdown 转换为 docx」,首选方案是使用 Pandoc。
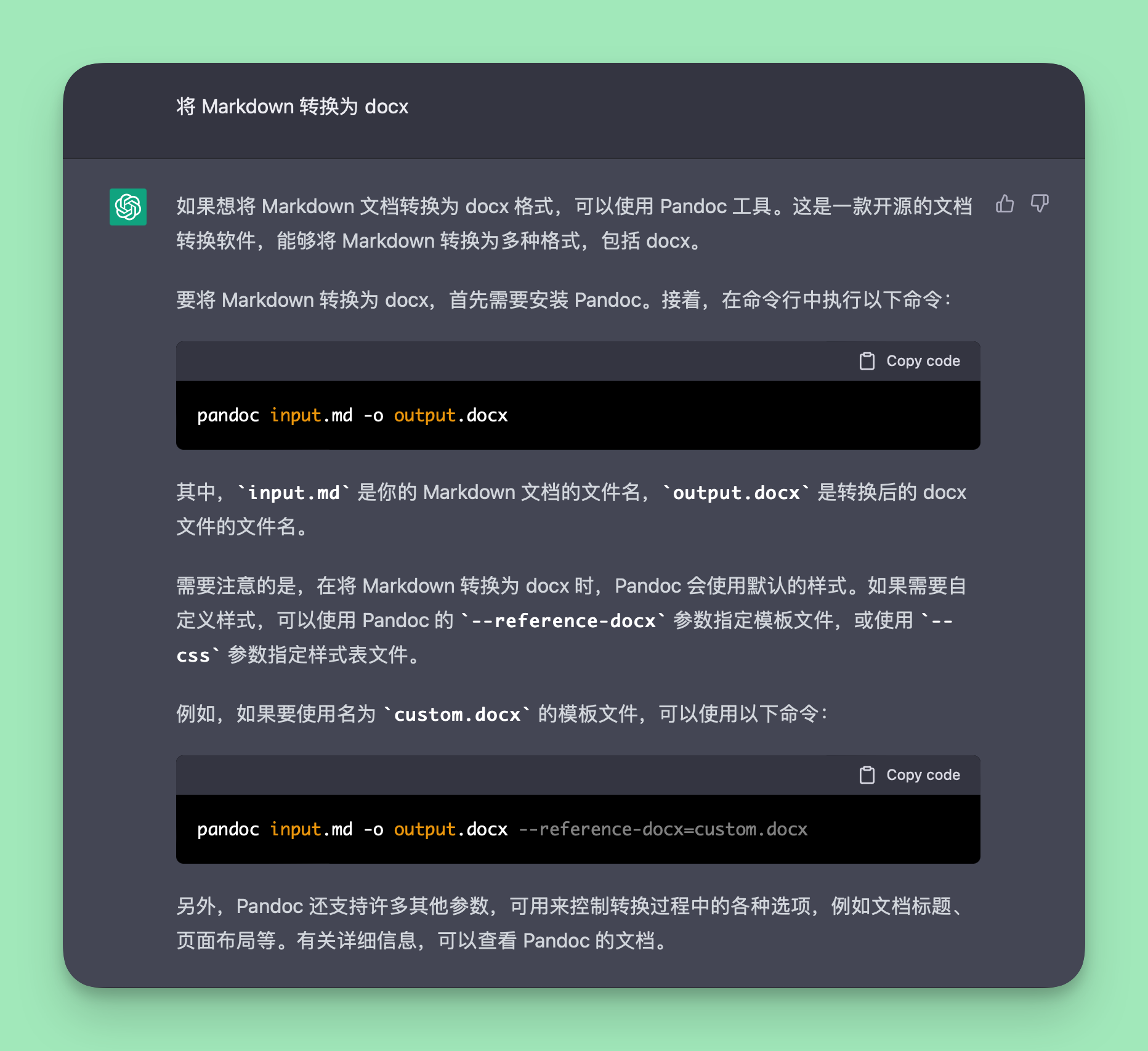
如何「将 Markdown 转换为 docx」,ChatGPT 回答使用 Pandoc,并给出了转换命令
Pandoc 是一个基于 GPL 协议开源的免费命令行软件 ,由加州大学伯克利分校哲学系教授 John MacFarlane使用 Haskell语言开发,目前另一位核心开发者是来自德国的Albert Krewinkel 。截止 2022 年 12 月 10 日,Pandoc 的 GitHub 仓库拥有超过 27,000 个 Star,3,000 次 Fork。
根据 John MacFarlane 教授的介绍 ,Pandoc 这个名称是一个组合单词: Pan是希腊神话里的牧神,指的是一切掌管树林、田地和羊群的神,doc 则是 document 的缩写,意为文档。因此从字面意思来看,可以说 Pandoc 是一个「无所不能的文档转换利器」 (universal markup converter),而它的确也拥有名副其实的功能。
作为一个始于 2006 年的个人项目,经过 16 年的发展,现在的 Pandoc 已经变得非常庞杂,拥有相当丰富的功能,可以实现 几十种 文件格式的转换,各种调整细节的选项也不计其数,除了基础的文档转换功能外,还能通过 Lua、Python 等脚本语言实现高度自定义的文档转换,甚至成为其他很多现代文档工具的依赖,例如R Markdown、Quarto。正因如此,它的功能非常复杂,仅PDF 版使用手册 就超过了 150 页。一方面,这使得 Pandoc 上手门槛比较高,容易劝退新手,但另一方面,丰富的功能也让它具有极强的可玩性和无限的可能性,甚至可以不仅限用于文档格式转换,还能实现一些「意料之外」的功能。
Pandoc 作为一个命令行工具,一个经常围绕它的问题是:为什么没有图形化界面(GUI
)?这是因为图形化应用虽然更加容易上手,但缺点也很明显——难以排列下数量庞大的参数。事实上,对于拥有大量参数的软件,命令行界面的易用性其实要优于图形化界面,这一点可以在网友设计的 OpenSSL GUI
中看出来。

如果命令行工具 OpenSSL 拥有图形化界面,将会是如此复杂的样子
当然,如果你非常偏爱图形化应用,可以使用 PanWriter
——一个基于 Pandoc 的 Markdown 编辑器,能够通过 GUI 的方式实现 Pandoc 的部分文档转换功能。
需要指出的是,Pandoc 不仅仅是一个文档转换工具,还包括了它定义的一系列标准,而 Pandoc’s Markdown
就是这样的标准之一。众所周知,诞生于 2004 年的 标准 Markdown
有不少局限性,这导致后来的 Markdown 方言
层出不穷,而在这些 Markdown 方言中,Pandoc’s Markdown 作为少有的「业界良心」,可以说是最为规范、功能最全面的,它主要包括了以下扩展语法:
- 表格:简单表格、多行表格、网格表、管道表格
- 列表:多种多样的有序列表和无序列表
- 行块:以
|开头,可用于诗歌等特殊文体的排版 - 脚注:包括常规脚注和行内脚注
- 文献引用:在 Markdown 中引用文献,支持 BibTeX 等多种引文格式
- 数学公式:用
$或$$包裹数学公式 - 支持混合使用 LaTeX 和 HTML 语法
在强大的 Pandoc’s Markdown 加持下,我们几乎可以在 Markdown 中完成任何类型的写作,并使用 Pandoc 将其转换为其他文件格式。在写作时,我们只需要思考下一句该写什么,而不用考虑写作本身之外的其他因素,正如 Pandoc 邮件讨论组中的网友 Michael Thompson
所说:
In Markdown – not to put too fine a point on it – the writer is only ever faced with one question, and it is the right one: what the next sentence should be.
在 Markdown 中——直言不讳地说——作者只会面对一个问题,而且是正确的问题:下一句应该写什么。
安装 Pandoc 与使用方法
Pandoc 的官网详细介绍了在各个操作系统上的 安装方法
,你可以根据自己使用的操作系统下载安装包进行安装,或者下载源代码 自行编译
。当然,也可以使用包管理器进行安装。例如,在 Windows 上使用 Chocolatey
安装:
choco install pandoc在 macOS 上使用 Homebrew
安装:
brew install pandoc在 Linux 上使用 APT
安装:
sudo apt-get install pandoc安装完成之后,在终端中输入 pandoc --version,如果输出以下或类似的信息,则意味着安装成功:
pandoc 2.19.2
Compiled with pandoc-types 1.22.2.1, texmath 0.12.5.2, skylighting 0.13,
citeproc 0.8.0.1, ipynb 0.2, hslua 2.2.1
Scripting engine: Lua 5.4
User data directory: /Users/username/.local/share/pandoc
Copyright (C) 2006-2022 John MacFarlane. Web: https://pandoc.org
This is free software; see the source for copying conditions. There is no
warranty, not even for merchantability or fitness for a particular purpose.Pandoc 的基本使用方式如下:
pandoc [options] [input-file]…例如,将一个 TXT 文件转换为 HTML 文件:
pandoc -f markdown input.txt -t html -o output.html上面这行命令中,-f markdown 表示
输入文件的格式为 Markdown,也可以写作 --from=markdown、-r markdown 或 --read=markdown。-t html 表示
输出文件格式为 HTML,也可以写作 --to=html、-w html 或 --write=html。输入文件为 input.txt,-o output.html 也可以写作 --output=output.html,表示
将输出写入到一个 HTML 文件中,命名为 output.html。
需要注意的是,在命令行中明确指出输入或输出的文件格式不是必须的,因为 Pandoc 可以根据文件扩展名 推测出
文件格式,例如,它会将 .txt、.md、.markdown 等扩展名视为 Markdown,将 .html 视为 HTML。而如果输入文件没有扩展名,则会被当作 Markdown,如果输出文件没有扩展名,则会被当作 HTML。因此,上面这行命令可以简写为:
pandoc input.txt -o output.html不只能处理文件
很多教程都会强调 Pandoc 的「输入文件」和「输出文件」,尽管这本身没有问题,但却在一定程度上限制了 Pandoc 的功能,让新手觉得它只能处理文件。然而事实上并非如此,与大部分命令行工具一样,Pandoc 的输入和输出也可以是 stdin
(标准输入)或 stdout
(标准输出),而不只是文件。
Pandoc 用户手册
指出,如果没有指定输入文件,Pandoc 会从 stdin 读入,如果没有指定输出文件,则输出为 stdout,也就是直接显示在终端中,例如执行下面这行简单的命令:
echo 'hello world' | pandoc通过 管道操作
| 将 echo 命令的输出结果传递给 pandoc。由于这里没有指定输入和输出文件,Pandoc 默认会将输入当作 Markdown,将输出当作 HTML,因此输出如下结果,并显示在终端中:
<p>hello world</p>标准输入和标准输出意味着可以使用 Pandoc 结合其他命令行工具一起使用。假设你得到一个文本文件 input.txt,它的文件编码不是 UTF-8,但 Pandoc 默认使用 UTF-8,那么可以结合 iconv 进行转换:
iconv -t utf-8 input.txt | pandoc | iconv -f utf-8再举个例子,少数派创作手册 指出:汉字与英文字母、数字间应手动追加一个空格。实际上,这基本上是 中文文案排版 的通用习惯,尽管手动在中英文、数字之间加一个空格是一个好习惯,然而由于这 只是习惯,不是规范,很多情况下,我打开别人发来的文档,中文、英文和数字「坐排排」挤在一起,实在是 让人坐立难安。如何在不修改源文件的情况下,在转换为其他格式时自动在汉字与英文字母、数字之间加上一个空格?我们可以结合 AutoCorrect 和 Pandoc,实现这一需求:
echo 'hello世界你好world,这是一段中文、日本語、한국어和English以及数字123夹杂在一起的文字。' | autocorrect --stdin | pandoc --wrap=preserve输出的 HTML 中,汉字与英文字母、数字之间成功地加上了一个空格:
<p>hello 世界你好 world,这是一段中文、日本語、한국어和 English 以及数字 123 夹杂在一起的文字。</p>这行命令中,--wrap=preserve 表示 不折行,加上它是因为 Pandoc 默认设置行宽为 72,而 preserve 的作用是不折行,保持原样。
意识到 Pandoc 不只能处理文件,我们就可以让 Pandoc 不仅限用于「转换文档格式」,还可以实现一些「处理文本」的需求。除此之外,Pandoc 还可以 读取网页内容,并将其转换为其他格式:
pandoc -f html https://pandoc.org -t commonmark-raw_html -o pandoc.md这行命令将 Pandoc 官网主页从 HTML 转换为 Markdown,并关闭 raw_tml 扩展(-extenson 表示关闭扩展),避免转换后的 Markdown 中出现很多 HTML 语法。需要指出的是,CommonMark 是一套针对 标准 Markdown 语法 进行严格定义并与之高度兼容的规范,也是由 John MacFarlane 教授主导开发的。
忽略东亚文字换行符
众所周知,Markdown 文件中连续两个换行,在生成的 HTML 文件中会产生一个新的段落,而单个换行则会产生一个空格。我派对此有一篇文章专门介绍了 为什么你应该试试一句话换一行,这种写作方式可以让你像写大纲或写诗一样来写文章,好处非常明显,对我也非常受用。如果你打开 Pandoc 用户手册的 源文件,就会发现它也是这样写的,不得不说好的写作习惯是相通的。
对于英文写作来说,「一句话换一行」的写作方式是非常自然的,因为每个英文单词之间都有空格,但对于汉字之间不存在空格的中文来说则不同。尽管作者 PlatyHsu 提供了使用正则表达式来清理标点符号后多余空格的方法,但若不在标点符号处换行,而在任意位置换行,使用正则表达式就相对比较复杂,显得不那么优雅。
对此,我们可以开启 Pandoc 专门针对处理东亚文字(包括中文、日文和韩文,一般统称为 CJK)的 扩展 east_asian_line_breaks(+extension 表示使用扩展),它的作用是忽略东亚文字中一个换行所产生的空格。
例如,将 Markdown 转换为 HTML,其中的 \n 表示换行:
echo '忽略\n\n中文段落里\n单个换行符。ignore the newline\n within\n\na paragraph' | pandoc --from markdown+east_asian_line_breaks --to html输出结果为:
<p>忽略</p>
<p>中文段落里单个换行符。ignore the newline within</p>
<p>a paragraph</p>作为对比,如果不开启 east_asian_line_breaks 扩展,Pandoc 则会在输出中将单个换行符转换为空格:
echo '忽略\n\n中文段落里\n单个换行符。ignore the newline\n within\n\na paragraph' | pandoc --to html输出结果为:
<p>忽略</p>
<p>中文段落里 单个换行符。ignore the newline within</p>
<p>a paragraph</p>尽管这个扩展对于中文写作非常实用,但我在习惯「一句话换一行」的写作方式之后,发现并非任何场景都能使用 Pandoc,比如写博客。那么在这种情况下,可以先使用 Pandoc 将文档处理一下,例如,我们可以将输入与输出都设置为 Markdown,这样就可以在不转换文件格式的同时处理文档内容:
echo '忽略\n\n中文段落里\n单个换行符。ignore the newline\n within\n\na paragraph' | pandoc --wrap=preserve --from markdown+east_asian_line_breaks --to markdown输出结果为:
忽略
中文段落里单个换行符。ignore the newline within
a paragraph另外值得一提的是,Pandoc 还有一个类似的 扩展 ignore_line_breaks,其作用与 east_asian_line_breaks 几乎一致,但后者考虑了东亚文字与其他类型的文字混合使用的情形。因此,对于中英混排的场景,更加推荐使用 east_asian_line_breaks。
直引号转换为弯引号
在正式的英文写作中,引号 应该使用弯引号 “”(U+201C & U+201D)、‘’(U+2018 & U+2019)而不是直引号 "(U+0022)、'(U+0027),所有格或缩略词的撇号应是 ’(U+2019)而不是 '。但是,由于打字机时代遗留下来的 习惯,在键盘上打出直引号要方便得多,因此,在最终呈现的文档中,需要将直引号转换为弯引号,也就是使用 Smart Quotes。
关联阅读:
- 别再用「六个点」当省略号了,这些标点都有更规范的输入方式
- 如何在 macOS 上精准输入左引号和右引号 | 一日一技
很多工具都内置了 Smart Quotes 的功能,能够在打字的过程中实现自动转换,比如 Drafts、iA Writer、Microsoft Word。但如果你已经有了一个使用直引号的文档,如何将其中所有的直引号快速转换为弯引号?可能大多数同学会首先想到使用 正则表达式,然而编写一个替换 Smart Quotes 的正则表达式需要考虑单引号、双引号、撇号以及中英混排等好几种情况,相对比较复杂,而使用 Pandoc 则非常简单,只需一行命令:
echo I\'m a sentence with \'single quotes\', \"double quotes\", as well as \"mixed straight and curly quotes”. | pandoc --wrap=preserve --to markdown-smart需要注意的是,上面的例子中,\' 和 \" 是 Shell 中 转义字符 的写法,实际写作中不需要加反斜杠 \。
输出结果为:
I’m a sentence with ‘single quotes’, “double quotes”, as well as “mixed straight and curly quotes”.上面的命令中,smart 扩展 的作用是将直引号转换为弯引号,这是一个默认开启的扩展。然而,如果 Markdown 作为输出格式时,则有相反的效果——将弯引号转换为直引号,因此这里使用 --to markdown-smart 关闭它。
实际上,除了将直引号转换为弯引号外,smart 扩展还有其他几个作用:
- 将
--转换为 En-dash(短连接号) - 将
---转换为 Em-dash(长连接号) - 将
...转换为 Ellipsis(省略号) - 在某些缩写之后插入不换行空格(non-breaking space),例如
Mr.
除此之外,Pandoc 也会对一些特殊字符进行 转义处理,例如将 * 转换为 \*。尽管 smart 扩展不仅仅把直引号转换为弯引号,还有其他一些「副作用」,有点不符合 DOTADIW 的原则,但这些都是 英文文案 或 Markdown 排版领域事实上的标准。而如果是转换为其他文件类型的话,Pandoc 则会完美地处理这些细节。
转换标题层级
知名 Markdown 语法检查器 markdownlint 的 第 25 条规则 指出,一个 Markdown 文件中,一级标题 # Heading 1 应该用作文章标题,有且只有一个,因此正文中最高的标题层级只能是二级标题 ## Heading 2。然而,这并不是一条通用规则,无论是出于个人习惯还是 Markdown 解释器的原因,# 一级标题 或 ## 二级标题 都有可能成为文章的最高层级标题,甚至同一篇文章可能需要同时处理这两种情况。
关联阅读:给你的 Markdown 挑挑刺——语法检查器入门与进阶
为了解决这个问题,Pandoc 提供了一个 选项 --shift-heading-level-by=NUMBER,可以灵活地调整文章标题的层级。如果其中的 NUMBER 设置为 1,那么一级标题就会变为二级标题,如果 NUMBER 设置为 -1,那么二级标题就会变为一级标题。
例如,我们在 Markdown 中写作时使用二级标题作为文章的最高层级标题,但在导出为 HTML 时,想要二级标题成为一级标题,可以使用下面这行命令:
echo '## 二级标题变成一级标题\n\n### 三级标题变成二级标题\n\n开始正文' | pandoc --shift-heading-level-by=-1 --to html输出结果为:
<h1 id="二级标题变成一级标题">二级标题变成一级标题</h1>
<h2 id="三级标题变成二级标题">三级标题变成二级标题</h2>
<p>开始正文</p>可以看到,Markdown 中原本的二级标题 ## 变成了 HTML 中的一级标题 h1,原本的三级标题 ### 变成了二级标题 h2。而如果把输出格式改为 Markdown,也有类似的效果:
echo '## 二级标题变成一级标题\n\n### 三级标题变成二级标题\n\n开始正文' | pandoc --wrap=preserve --shift-heading-level-by=-1 --to markdown输出结果为:
# 二级标题变成一级标题
## 三级标题变成二级标题
开始正文提取媒体文件
如果需要将 Microsoft Word 或 Epub 中的所有图片提取出来,单独保存在一个文件夹中,你会怎么做?最直接的方式当然是打开文件,在其中选中图片「另存为」或拖拽出来。一些同学可能觉得这种方式过于麻烦,并且知道 .docx 和 .epub 实际上是一类压缩文件,可以通过解压缩的方式得到其中的所有图片。以 Word 文件为例,执行以下命令:
unzip test.docx -d unzipped就会得到一个解压缩后的文件夹 unzipped,而所有图片都保存在 unzipped/word/media 这个目录中。
与 unzip 命令 类似,Pandoc 也有一个 选项 extract-media=DIR,用于处理文件转换过程中的图片等媒体文件。例如执行下面这行命令,将包含图片的 Word 文件转换为 Markdown:
pandoc test.docx --extract-media=. -o test.md输出结果包括一个 Markdown 文件 test.md 以及一个文件夹 media,其中包括 Word 文件 test.docx 中的所有图片,--extract-media=. 的作用是把图片保存在 media 中,而不是其子文件夹中。到此为止,Pandoc 所做的工作与 unzip 命令差不多,不过,Pandoc 肯定不止能做到这一点,得益于它的文档转换功能,我们还可以利用 --extract-media=DIR 这个选项来将 Markdown 中的图床链接替换为本地图片链接。
此前,我分享过使用 Curl 或 Wget 下载远程图床中的图片到本地,再用 sed 结合正则表达式替换 Markdown 中的图片链接,实现图床链接替换为本地图片链接的需求。
关联阅读:批量下载、处理图片和 PDF,这些任务你可以在命令行中完成
但说实话,这个方法稍微有点复杂,还很容易出错,不具有真正意义上的普适性,而使用 Pandoc 就简单多了。例如,我们有一个 Markdown 文件 input.md,其中的内容如下,包括两个少数派图床链接:
使用 Pandoc 将 Markdown 中的图床链接替换为**本地图片链接**。


Pandoc is really *awesome*!执行下面的命令:
pandoc --wrap=preserve -f markdown input.md --extract-media=media -t markdown -o output.md这行命令中,由于开启了 --extract-media=DIR 选项,Pandoc 会新建一个文件夹 media,将图床中的远程图片下载到本地并保存在该文件夹中,然后再输出为一个新的 Markdown 文件 output.md,并自动把原本的图床链接替换为本地图片链接,而不再需要手动编写复杂的正则表达式来查找替换。
得到 output.md 的内容如下:
使用 Pandoc 将 Markdown 中的图床链接替换为**本地图片链接**。


Pandoc is really *awesome*!其中的 ab9f7f9.png 和 8q6y9r7.gif 是下载到 media 文件夹中的本地图片,图片名称是根据内容的 SHA1 哈希值构建的。值得注意的是,Pandoc 支持很多 Markdown 变种,比如 MultiMarkdown、GitHub-Flavored Markdown、PHP Markdown Extra,相互之间略有差异,如果你对输出的 output.md 不满意,可是通过修改 -t markdown,试试其他类型的 Markdown。
转换参考文献
Pandoc 使用 --citeproc (或 -C) 选项 来处理参考文献,这是它的看家本领之一,甚至可以说是无出其右,仅支持的文献类型格式就包括 BibTeX、BibLaTeX、CSL JSON、EndNote XML 和 RIS 这 5 种。在使用 Pandoc 处理参考文献之前,首先需要明确,能这样做的前提是文献数据一定要单独保存,而不能混在其他文件中,比如使用 Zotero 的 Word 插件 插入 Word 文档中的文献信息就无法被 Pandoc 处理。
与 LaTeX 相比,在 Markdown 中 引用文献 简单得多。假设你的文章存储在一个 Markdown 文件 input.md 中,参考文献数据存储在一个 BibTeX 文件 bib.bib 中,那么就可以在 input.md 中通过 [@citekey] 的方式来引用文献,其中的 citekey 是 BibTeX 文件中对应的 Citation Key。在论文写好之后,然后就可以通过 Pandoc 将其转换为其他文件格式,例如转换为 Word 文档:
pandoc --citeproc --bibliography bib.bib input.md -o output.docx我的 Zotero 数据库中有两千条多条文献条目,使用插件 Better BibTeX 将它们全部导出为 Better BibLaTeX 格式,存储在一个名为 bibliography.bib 的文件中,大概有 3.5 MB。无论我写什么论文,引文数据都来自这一个文件,假设我写的一篇论文从中引用了 100 篇文献,如何将它们保存为一个单独的 BibLaTeX 文件呢?全能的 Pandoc 自然可以做到,不过这一步需要借助 Lua filter 来实现。
首先将下面这 5 行 Lua 代码 复制,粘贴到文本编辑器中并保存为 getbib.lua,移动到工作目录中:
function Pandoc(bib)
bib.meta.references = pandoc.utils.references(bib)
bib.meta.bibliography = nil
return bib
end然后执行下面这行命令,就可以将 Markdown 文件 input.md 中引用的 100 篇文献提取出来,并保存为 citation.bib:
pandoc --bibliography bibliography.bib --lua-filter getbib.lua --to biblatex input.md --output citation.bib这行命令中,--bibliography bibliography.bib 告诉 Pandoc 从 bibliography.bib 中读取 引文数据(可能需要调整文件所在路径),--lua-filter getbib.lua 表示使用上面已保存的 Lua filter getbib.lua,--to biblatex 表示转换为 BibLaTeX 格式。
得到所有引用过的 100 篇文献之后,如果需要单独提交参考文献,就可以把这个 citation.bib 文件分享给其他人。但考虑到 BibLaTeX 格式并不通用,大多数情况下对方往往需要我们提供 Word 文档,为了解决这个问题,可以使用 Pandoc 将 BibLaTeX 文件转换为 Word 文档:
pandoc --citeproc citation.bib -o bibliography.docx转换得到的 bibliography.docx 默认使用 chicago-author-date 样式排列参考文献,当然,你也可以通过加上 --csl 参数 来设置自定义的 CSL (Citation Style Language) 文件,例如使用 APA 样式:
pandoc --citeproc citation.bib --csl=https://www.zotero.org/styles/apa -o bibliography.docx上面这行命令中,--csl 指向的是一个远程 CSL 文件,不过它也可以是本地文件。更多参考文献样式,可以前往 Zotero Style Repository 搜索或下载。
结语
本文总结了我平时使用 Pandoc 的一些技巧,希望对你有所帮助。但是对于熟练使用 Pandoc 来说,这些技巧还远远不够,如果你在使用过程中遇到了问题,一定记得首先去阅读 Pandoc 的用户手册(Pandoc User’s Guide)。一般来说,大多数人使用 Pandoc 的目的都是为了快速转换文档格式,往往看一下 Quick Start,或者直接复制互联网其他人分享的命令,不会花很多时间与精力去仔细阅读 Pandoc 用户手册,尽管这无可非议,但不阅读 Pandoc 用户手册是十分不明智的,正如 R Markdown 开发者 谢益辉 所说:
No matter how many times I have recommended R Markdown users to read the full Pandoc manual at least once, I still want to recommend it again. You won’t really appreciate how powerful Pandoc’s Markdown is until you read the full manual once.
无论我已推荐 R Markdown 用户至少完整阅读一遍 Pandoc 手册多少次,我仍然想再次推荐它。只有完整阅读一遍用户手册,你才会惊叹于 Pandoc’s Markdown 是多么强大。
对此我非常赞同,很多时候我遇到使用 Pandoc 的问题时,查阅 Pandoc 用户手册往往都会带给我惊喜。
如果查阅 Pandoc 用户手册仍然没有解决问题,你也可以在 Stack Overflow 上搜索或提问,开发者 Albert Krewinkel 在上面非常活跃,基本上 Pandoc 的相关问题下都有他的回答或评论,或者在 Pandoc 的 Google Groups 中讨论和求助。除此之外,你也可以关注 Pandoc 的 长毛象帐号,Albert Krewinkel 会在上面分享很多实用技巧。当然,如果你想偷懒,也可以问问 ChatGPT 应该怎么使用 Pandoc,不过需要小心,它也可能会犯错。
毫不夸张地说,Pandoc 是我最喜欢的一个工具,尽管它是一个免费软件,我仍然在 GitHub 上赞助了两位核心开发者,在感谢他们开发了如此优秀的软件的同时,也希望能为项目开发尽一点绵薄之力。写下这篇介绍 Pandoc 的文章,让更多人了解并使用它,我同样感到非常开心,颇有一种把「压箱底的宝贝儿」拿出来分享的兴奋感觉。尽管无法面面俱到,甚至可能遗漏了非常基础的部分,但仍希望能让你感受到 Pandoc 的魅力,如果可以使用并分享它就更好了。