Spark大数据集群日常开发过程遇到的异常及解决思路汇总

原创/朱季谦
在开发Spark任务过程中,遇到过不少新人经常可能会遇到的坑,故而将这些坑都总结了下来,方便日后遇到时,可以快速定位解决,壁面耗费过多时间在查找问题之上。
一、出现java.lang.IllegalAccessError: tried to access method com.google.common.base.Stopwatch.()V from class org.apache.hadoop.hbase.zookeeper.MetaTableLocator
在新项目上创建以下Scala代码去连接Hbase集群,用来判断Hbase是否存在某张表。
//离线Hbase
val conf: Configuration = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum","192.168.1.200")
conf.set("hbase.zookeeper.property.clientPort","2181")
// 创建HBase连接
val connection = ConnectionFactory.createConnection(conf)
val hbaseAdmin = connection.getAdmin
val tables = Set("SYSTEM_LOG")
val synTable = TableName.valueOf(tableName)
val tableExist = hbaseAdmin.tableExists(synTable)
在测试运行时,出现了以下异常:
Exception in thread "main" org.apache.hadoop.hbase.DoNotRetryIOException: java.lang.IllegalAccessError: tried to access method com.google.common.base.Stopwatch.()V from class org.apache.hadoop.hbase.zookeeper.MetaTableLocator
检查发现是因为maven里引入的hbase-client、spark-core等众多依赖包里都含有com.google.guava包,这就会出现各个guava包冲突问题,进而导致出现 tried to access method com.google.common.base.Stopwatch.异常问题。
我们可以通过maven的maven-help插件来检查com.google.guava包冲突问题,maven-help插件的引入与使用,我在另一篇博客里有介绍过——Maven Helper插件——实现一键Maven依赖冲突问题
在maven里切换至【Dependency Analyzer】栏,在搜索框输入冲突包guava,即会出现,guava都被哪些包依赖了,当多个组件包都依赖了同一个包但又不同版本时,很容易久出现各种冲突。红色部分就是表示有冲突的依赖包版本——
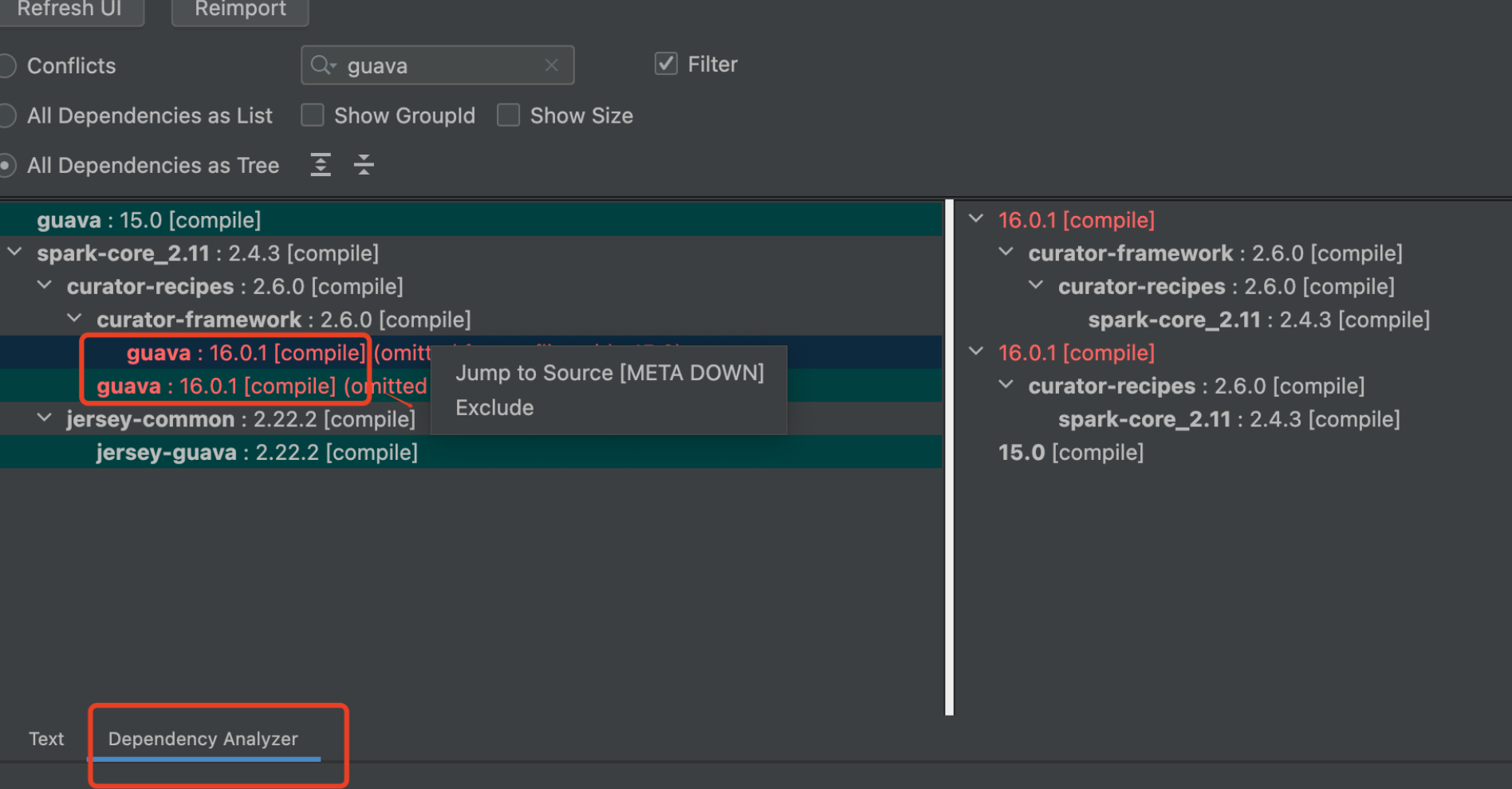
选中对应想去除的包,右击点击Exclude即可一键exclusion。
最后,单独引入一个com.google.guava包,我的hbase是1.x版本的,引入guava-15版本的可以解决。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>15.0</version>
</dependency>
二、出现org.apache.hadoop.hbase.NamespaceNotFoundException: SYSTEM
在创建带有命名空间的表时,例如创建表名为SYSTEM:SYSTEM_LOG时出现以下异常——
Caused by: org.apache.hadoop.hbase.ipc.RemoteWithExtrasException(org.apache.hadoop.hbase.NamespaceNotFoundException): org.apache.hadoop.hbase.NamespaceNotFoundException: SYSTEM
at org.apache.hadoop.hbase.master.HMaster.ensureNamespaceExists(HMaster.java:2090)
at org.apache.hadoop.hbase.master.HMaster.createTable(HMaster.java:1270)
at org.apache.hadoop.hbase.master.MasterRpcServices.createTable(MasterRpcServices.java:399)
at org.apache.hadoop.hbase.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java:42436)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2033)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:107)
at org.apache.hadoop.hbase.ipc.RpcExecutor.consumerLoop(RpcExecutor.java:130)
at org.apache.hadoop.hbase.ipc.RpcExecutor$1.run(RpcExecutor.java:107)
at java.lang.Thread.run(Thread.java:748)
此时Hbase里并没有事先创建该SYSTEM命名空间,因此需要先创建一个,直接登陆Hbase服务器,通过hbase shell执行以下指令:
create_namespace 'SYSTEM'
执行成功后,如下图所示:
![]()
这时,再重新运行下代码,这时就没有报错了,然后通过hbase shell的list查看指令,发现已经正常创建带有命名空间的表了SYSTEM:SYSTEM_LOG 。
三、在spark的bin目录里,运行spark-shell出现异常Failed to initialize Spark session.
java.io.FileNotFoundException: File does not exist: hdfs://hadoop1:9000/spark-logs
出现的异常信息如下:
[main] ERROR org.apache.spark.repl.Main - Failed to initialize Spark session.
java.io.FileNotFoundException: File does not exist: hdfs://hadoop1:9000/spark-logs
at org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1309)
at org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1301)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
这说明hdfs没有spark-logs目录。
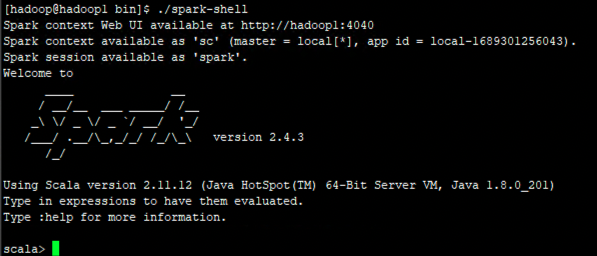
我在hadoop主机器上运行指令hdfs dfs -mkdir /spark-logs指令后,生成了一个目录/spark-logs,再执行spark-shell,就能正常进入scala命令行界面了——
四、本地scala远程spark查询hive库只显示defalt库的问题
最开始,我的代码本地Scala远程连接Spark查询hive库的代码是这样写的:
val spark = SparkSession
.builder()
.master("spark://192.168.1.99:7077")
.appName("YourAppName")
.enableHiveSupport() // 启用对Hive的支持
.getOrCreate()
spark.sql("show databases").show()
这块代码执行下来,都只能查到hive的default库,其他库都找不到。

需要在代码里增加一行 .config("hive.metastore.uris","thrift://hadoop1:9083")就可以了
val spark = SparkSession
.builder()
.master("spark://192.168.1.99:7077")
.config("hive.metastore.uris","thrift://hadoop1:9083")
.appName("YourAppName")
.enableHiveSupport() // 启用对Hive的支持
.getOrCreate()
spark.sql("show databases").show()
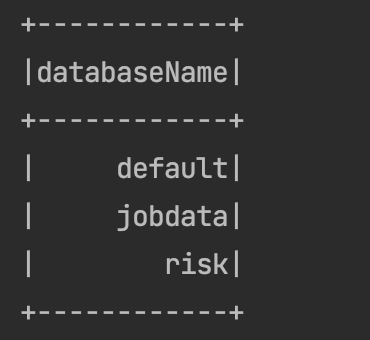
重新执行一遍,就能正常查到hive的所有库了——
四、HBase外部表映射到Hive表显示整数列为NULL
刚开始的语句是这样的——
CREATE EXTERNAL TABLE test(
ROW_KEY string,
PK string,
count1 int,
count2 int,
count3 int,
count4 int,
count5 int,
count6 int
)
STORED by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES("hbase.columns.mapping" = ":key,INFO:PK,INFO:count1,INFO:count2,INFO:count3,INFO:count4,INFO:count5,INFO:count6")
TBLPROPERTIES ("hbase.table.name" = "test");
发现HIve查询整数对应的字段都为NULL——

后来修改成这样,Hive就能正常映射到Hbase的byte整数字段值了——
CREATE EXTERNAL TABLE test(
ROW_KEY string,
PK string,
count1 int,
count2 int,
count3 int,
count4 int,
count5 int,
count6 int
)
STORED by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES("hbase.columns.mapping" = ":key,INFO:PK,INFO:count1#b,INFO:count2#b,INFO:count3#b,INFO:count4#b,INFO:count5#b,INFO:count6#b",'serialization.format'='1')
TBLPROPERTIES ("hbase.table.name" = "test");
再次查询Hive,就发现整数对应的值都有了——

五、RDD之foreach和foreachPartition方法日志查看
这两个方法内的日志,在driver端是看不到的,也就是说,即使你将driver执行日志>spark.log,在spark.log是看不到方法里面的日志的。
foreach和foreachPartition日志需要到Spark Web里查看。