【Azure 架构师学习笔记】- Azure Databricks (2) -集群
本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure Databricks】系列。
接上文 【Azure 架构师学习笔记】- Azure Databricks (1) - 环境搭建
前言
在上文中提到了ADB 的其中一个核心就是集群,所以这里专门研究一下ADB 的集群。
ADB 集群
首先了解一下ADB 的集群, ADB的集群本质上就是一堆Azure VM,在创建之时已经按照特定模板,配置有Spark和可以并行操作Spark的能力的机器。用于并行执行ADB的代码。
ADB 的集群有两种:
- Interactive:通过GUI手动创建的集群,通常共享给多用户多notebook使用。
- Job:一个临时的集群,绑定到Databricks的作业,根据作业运行情况自动启停。
集群访问模式
ADB 有三种可选类型,如下图:

Access modes
- Single User:单用户使用
- Shared:多用户使用
- No isolation shared:管理员可以隐藏这个集群。
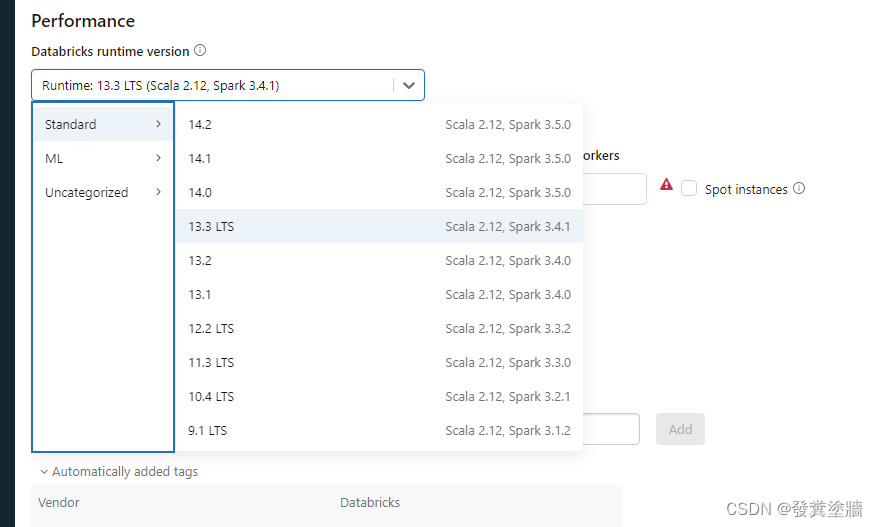
Databricks Runtime Version
Databricks runtime是预配环境,其软件,优化配置已经初始化到你的集群中,一般来说,如果不清楚这些版本的区别,那就选择最新版本。
- Standard:用于大多数常规场景。
- ML:用于专门的机器学习场景。
- Uncategorized:不属于上面两种场景的时候使用。
自动控制
ADB 的自动控制部分有两个功能:
-
Enable autoscaling:会根据上面选择的最小,最大节点进行按需升级,注意它是按需的,而不是直接一次性到大设置的最大节点数。降级也同理,并不是一次性降下来。 除非负载在短时间内降到很低。
-
Terminate after ? minutes of inactivity:没有活动多少分钟后,停止集群,从而节省不必要的费用。不过也要根据job的运行规律而定,不能一刀切。

Worker 和 Driver types
目前主流集群都以主节点(Worker)和子节点(Driver)为结构,worker node是用来控制的,而Driver 则是实际执行的。这些节点物理上就是一系列的windows VM。 可以看到下面两个图中VM 类型的选择,不同类型性能和价格都不一样。
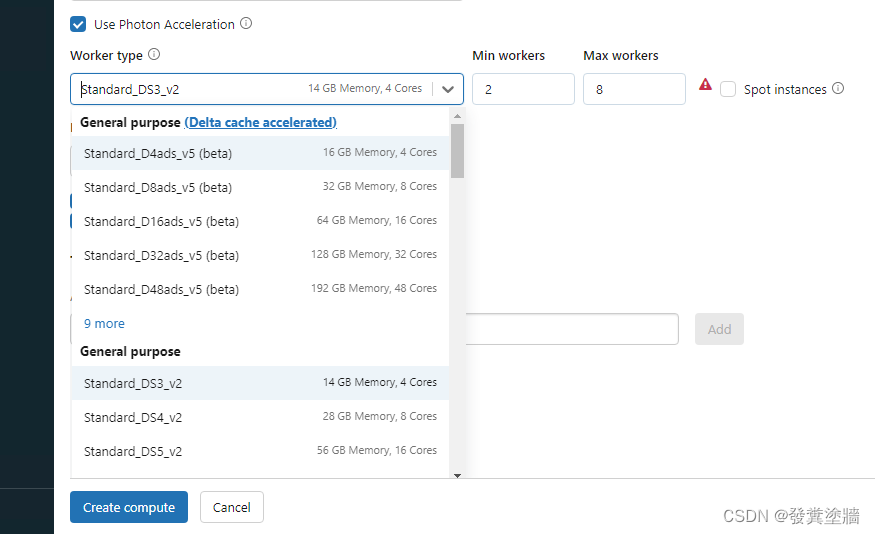
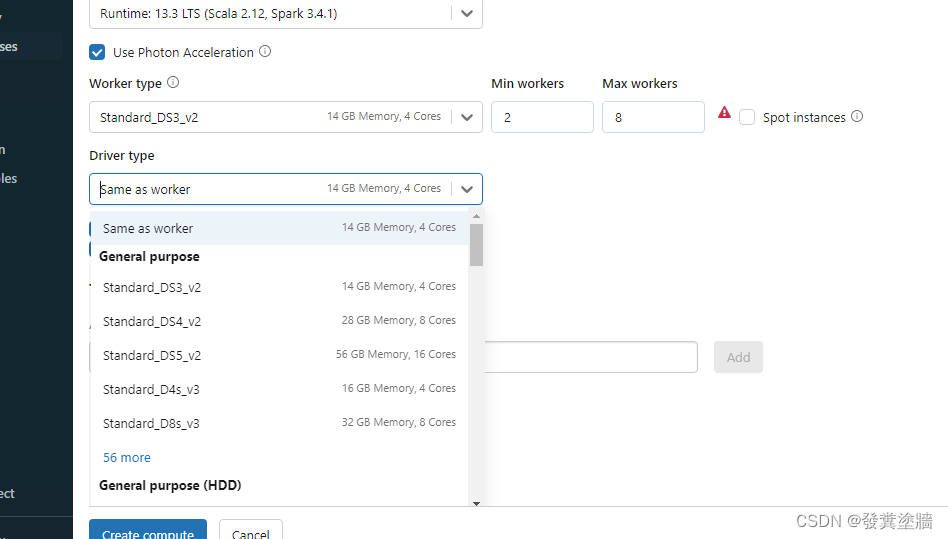
- General Purpose:适合开发,标准的job 运行。
- Memory Optimized: 适合内存密集型运算。
- Storage Optimized:ADB中有一个功能叫Delta Lake,这个后续介绍,这种类型适合Delta Lake使用。
- GPU Accelerated: 对于大规模GPU 负载, 机器学习等都更加合适。
通常来说两个类型可以相同,不过如果要频繁集中数据到driver node,那么就需要考虑增加VM 的性能。
Advanced Options
这里更多是对常规集群的增强或者定制化配置: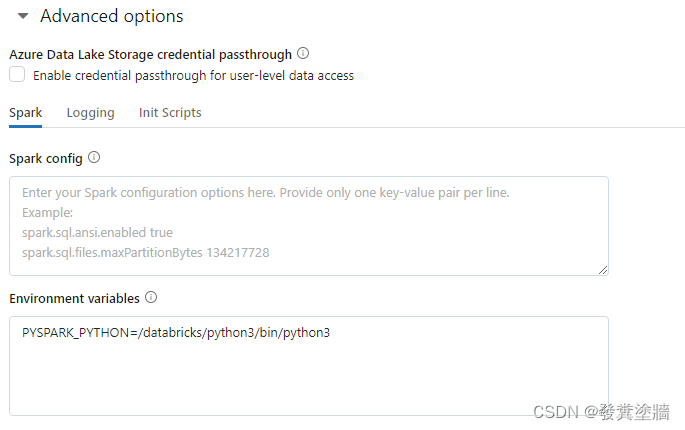
- Azure Data Lake Storage credential passthrough: 这个功能适用于增强Data Lake对于内部用户的安全性。
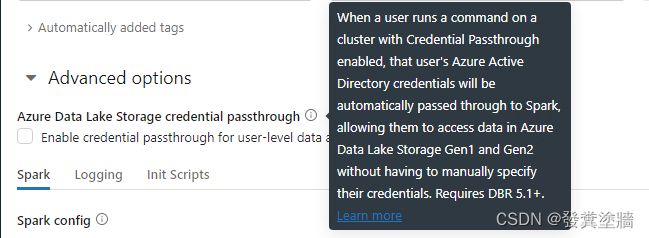
- Spark Config:这是对Spark进行深度配置的区域。可以作为性能优化,或者其他特别需求之用。
- Environment Variables:类似于Spark Config, 通过特定的内容,调整Spark的安装。
- Logging:指定集群日志的输出位置。
- Init Scripts:可以通过bash来安装额外的库和包。
虽然大部分情况下默认的配置已经足够,但是对于那些需要迁移现有Spark 负载到新的ADB 情境下,那么自定义就有必要了。