ELK(五)—集群搭建
写目录
- ip规划
- ElasticSearch集群
- 集群节点
- 搭建集群
- es切片和副本
- 切片(Shard):
- 副本(Replica):
- 故障转移
- postman创建索引的情况
- 直接在面板中创建索引
- 总结
ip规划
| ip | 名称 | 服务 |
|---|---|---|
| 192.168.150.190 | elk_master | elasticsearch |
| 192.168.150.189 | elk_node1 | |
| 192.168.150.188 | elk_node2 |
ElasticSearch集群
集群节点
ELasticsearch的集群是由多个节点组成的,通过cluster.name设置集群名称,并且用于区分其它的集群,每个节点通过node.name指定节点的名称。
在Elasticsearch中,节点的类型主要有4种:
master节点
- 配置文件中node.master属性为true(默认为true),就有资格被选为master节点。master节点用于控制整个集群的操作。比如创建或删除索引,管理其它非master节点等。
data节点
- 配置文件中node.data属性为true(默认为true),就有资格被设置成data节点。data节点主要用于执行数据相关的操作。比如文档的CRUD(创建(Create),读取(Retrieve),更新(Update) 、删除(Delete))。
客户端节点
- 配置文件中node.master属性和node.data属性均为false。
- 该节点不能作为master节点,也不能作为data节点。
- 可以作为客户端节点,用于响应用户的请求,把请求转发到其他节点
部落节点
- 当一个节点配置tribe.*的时候,它是一个特殊的客户端,它可以连接多个集群,在所有连接
搭建集群
elk-master节点的信息
#################################
# master节点的 elasticsearch.yml 内容
#################################
# 集群节点名称
node.name: "elk_node1"
# 设置集群名称为elasticsearch
cluster.name: "cluster_es"
# 网络访问限制
network.host: 0.0.0.0
#社会绑定的IP地址,可以是IPV4或者IPV6
network.bind_host: 0.0.0.0
#设置其他节点与该节点交互的IP地址
network.publish_host: 192.168.150.189
#是否开启http服务对外提供服务
http.port: 9200
#设置节点之间交互的端口号
transport.port: 9300
# 是否支持跨域
http.cors.enabled: true
# 表示支持所有域名
http.cors.allow-origin: "*"
# 内存交换的选项,官网建议为true
bootstrap.memory_lock: true
# 集群中的其它节点
discovery.seed_hosts: ["192.168.150.190","192.168.150.189","192.168.150.188"]
#集群中的角色
node.roles: [master,data]
# 集群中初始化的节点
cluster.initial_master_nodes: ["elk_master", "elk_node1", "elk_node2"]
# 取消安全验证
xpack.security.enabled: false
xpack.security.http.ssl.enabled: false
xpack.security.transport.ssl.enabled: false
elk_node1的节点相关信息
#################################
# master节点的 elasticsearch.yml 内容
#################################
# 集群节点名称
node.name: "elk_node1"
# 设置集群名称为elasticsearch
cluster.name: "cluster_es"
# 网络访问限制
network.host: 0.0.0.0
#社会绑定的IP地址,可以是IPV4或者IPV6
network.bind_host: 0.0.0.0
#设置其他节点与该节点交互的IP地址
network.publish_host: 192.168.150.189
#是否开启http服务对外提供服务
http.port: 9200
#设置节点之间交互的端口号
transport.port: 9300
# 是否支持跨域
http.cors.enabled: true
# 表示支持所有域名
http.cors.allow-origin: "*"
# 内存交换的选项,官网建议为true
bootstrap.memory_lock: true
# 集群中的其它节点
discovery.seed_hosts: ["192.168.150.190","192.168.150.189","192.168.150.188"]
#集群中的角色
node.roles: [master,data]
# 集群中初始化的节点
cluster.initial_master_nodes: ["elk_master", "elk_node1", "elk_node2"]
# 取消安全验证
xpack.security.enabled: false
xpack.security.http.ssl.enabled: false
xpack.security.transport.ssl.enabled: false
elk_node2的节点相关信息
#################################
# master节点的 elasticsearch.yml 内容
#################################
# 集群节点名称
node.name: "elk_node2"
# 设置集群名称为elasticsearch
cluster.name: "cluster_es"
# 网络访问限制
network.host: 0.0.0.0
#社会绑定的IP地址,可以是IPV4或者IPV6
network.bind_host: 0.0.0.0
#设置其他节点与该节点交互的IP地址
network.publish_host: 192.168.150.188
#是否开启http服务对外提供服务
http.port: 9200
#设置节点之间交互的端口号
transport.port: 9300
# 是否支持跨域
http.cors.enabled: true
# 表示支持所有域名
http.cors.allow-origin: "*"
# 内存交换的选项,官网建议为true
bootstrap.memory_lock: true
# 集群中的其它节点
discovery.seed_hosts: ["192.168.150.190","192.168.150.189","192.168.150.188"]
#集群中的角色
node.roles: [master,data]
# 集群中初始化的节点
cluster.initial_master_nodes: ["elk_master", "elk_node1", "elk_node2"]
# 取消安全验证
xpack.security.enabled: false
xpack.security.http.ssl.enabled: false
xpack.security.transport.ssl.enabled: false
三个节点的“elasticsearch.yml”文件修改完成后,我们就可以启动elasticsearch服务了
./elasticsearch -d

cluster.initial_master_nodes: ["elk_master", "elk_node1", "elk_node2"]因为在集群的master节点初始化的时候,三个节点都有机会成为master节点,那个节点先启动就是对应的主节点了。
创建一个索引,其中加粗的为主分片,其余为副本分片

查询集群状态:/_cluster/health
在postman工具(或其他工具)
get http://192.168.150.189:9200/_cluster/health
get http://集群中的节点ip:端口/_cluster/health
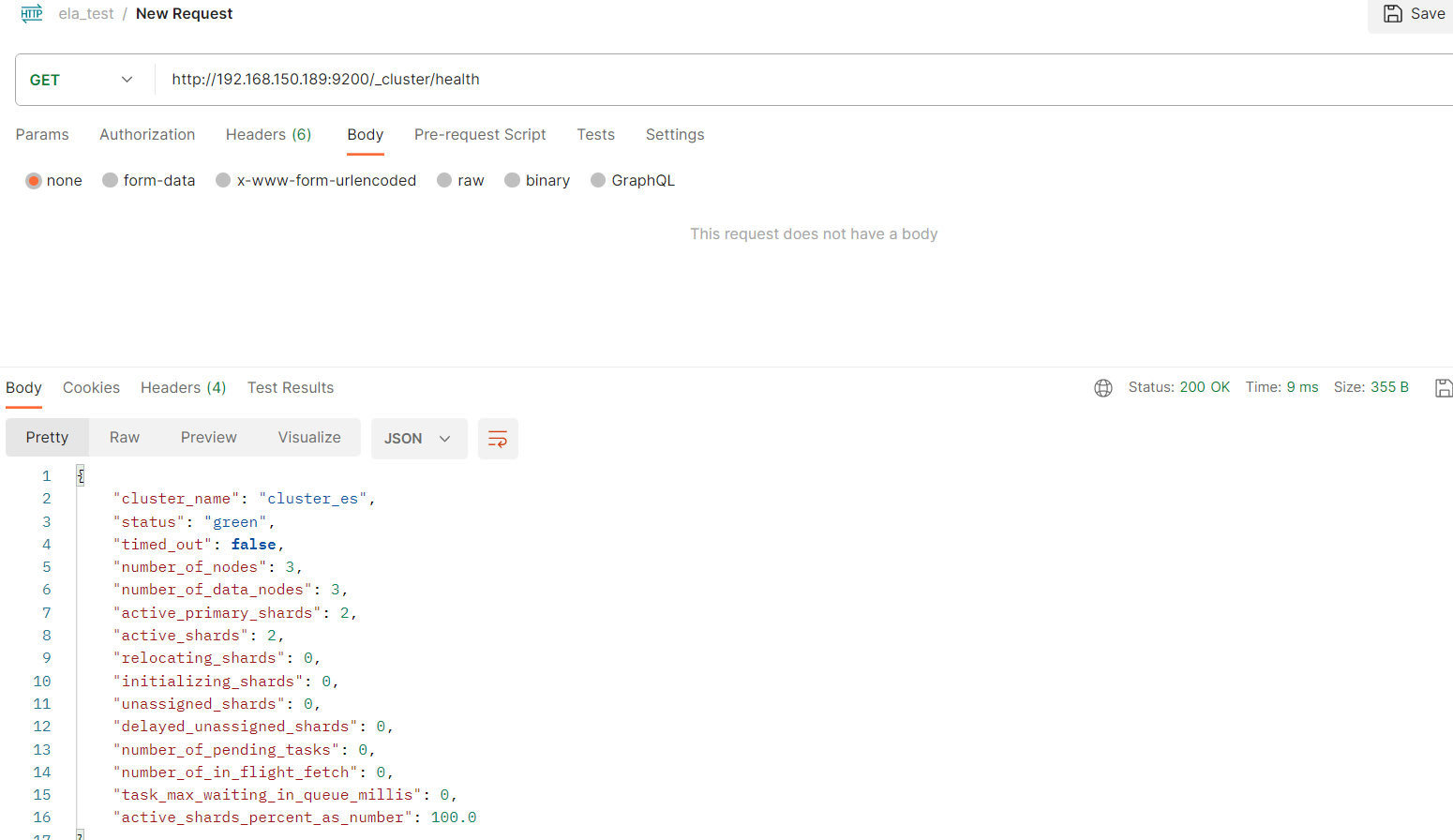
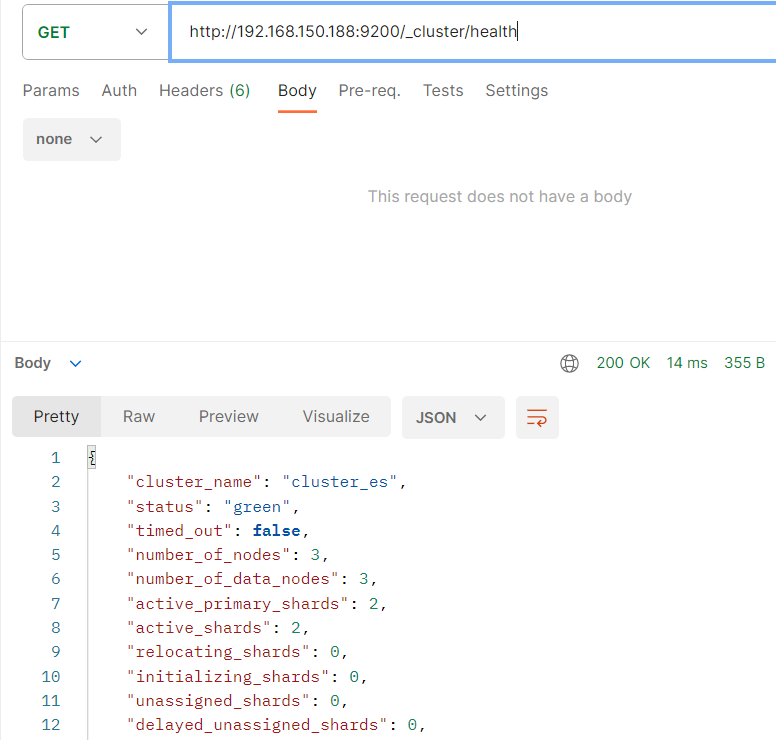
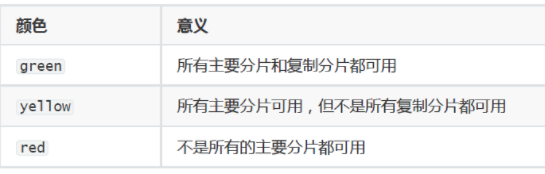
集群中有三种颜色
es切片和副本
在Elasticsearch中,切片(shard)和副本(replica)是两个重要的概念,它们对于分布式和高可用性非常关键。以下是对这两个概念的详细解释:
切片(Shard):
- 定义:
- 切片是数据在Elasticsearch集群中的基本单元。每个索引都被分成一个或多个切片,每个切片是一个独立的工作单元,包含了索引中的一部分数据。
- 目的:
- 切片的主要目的是将索引的数据分散存储在整个集群中,以实现分布式存储和搜索。这使得Elasticsearch能够处理大量数据并提供快速的检索能力。
- 类型:
- 主切片(Primary Shard):每个切片都有一个主切片,它是切片的主要工作单元,负责处理所有的读和写操作。
- 复制切片(Replica Shard):为了提高高可用性和性能,每个主切片可以有零个或多个复制切片。复制切片是主切片的拷贝,可以接收读请求。
- 分配策略:
- 切片的分配是在索引创建时确定的,通常在索引创建时指定主切片的数量。副本的数量可以在运行时进行动态调整。
- 路由:
- 文档被路由到特定的切片,Elasticsearch使用文档的ID和切片数量来确定路由。这确保了相同ID的文档总是存储在同一个切片上。
副本(Replica):
- 定义:
- 副本是主切片的拷贝,用于提供冗余和高可用性。每个主切片可以有零个或多个副本,这些副本存储在不同的节点上。
- 目的:
- 主切片和其所有副本一起形成一个分片组,该组提供了在节点故障或网络问题时的冗余和故障恢复能力。
- 高可用性:
- 当主切片不可用时,Elasticsearch可以自动将一个副本提升为新的主切片,以保持索引的可用性。
- 读操作:
- 读操作可以由主切片或任何副本处理,这取决于请求的路由和索引的健康状况。
- 写操作:
- 写操作总是由主切片处理,然后通过异步复制到所有副本。这确保了写操作的一致性和可用性。
总体而言,切片和副本是Elasticsearch实现分布式、高性能和高可用性的关键组件。通过合理设置切片和副本的数量,可以有效地利用集群资源并确保数据的安全和可用性。
故障转移
postman创建索引的情况
这里选择将elk_node2的es停止
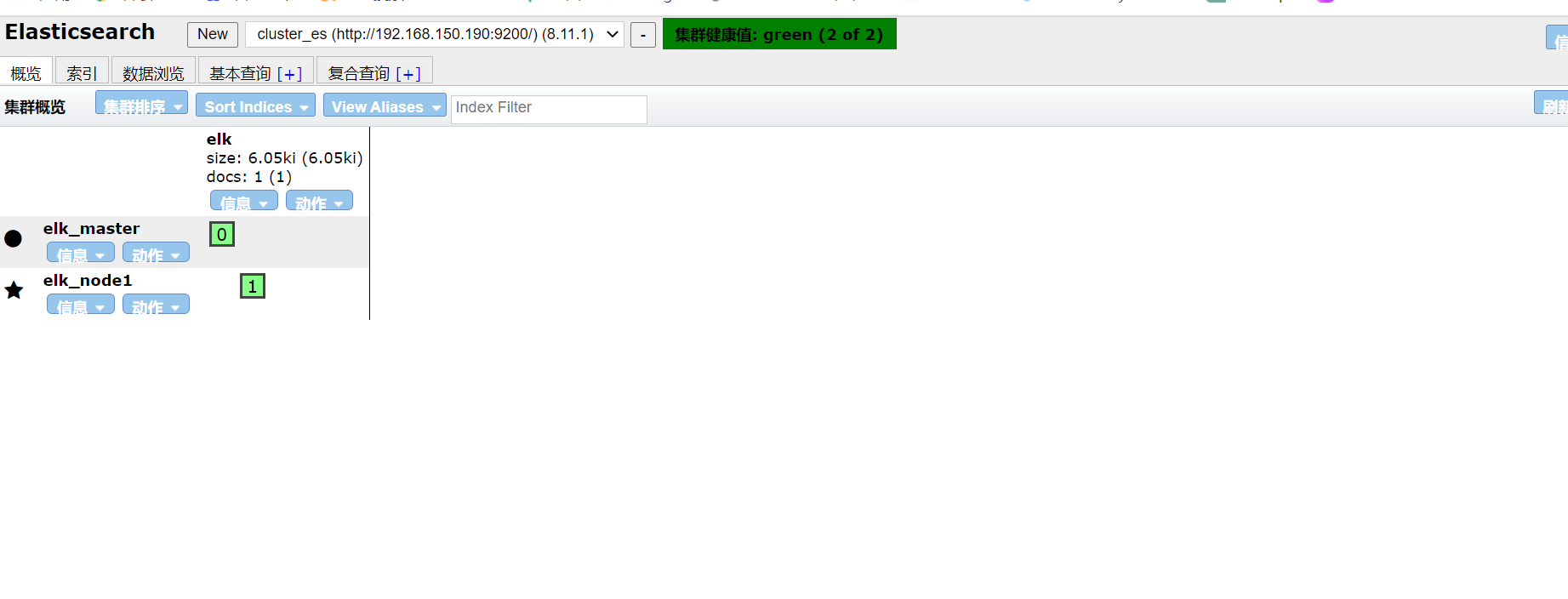
可以看到,elk_node2节点立即从看板中消失了。
重启启动elk_node2节点
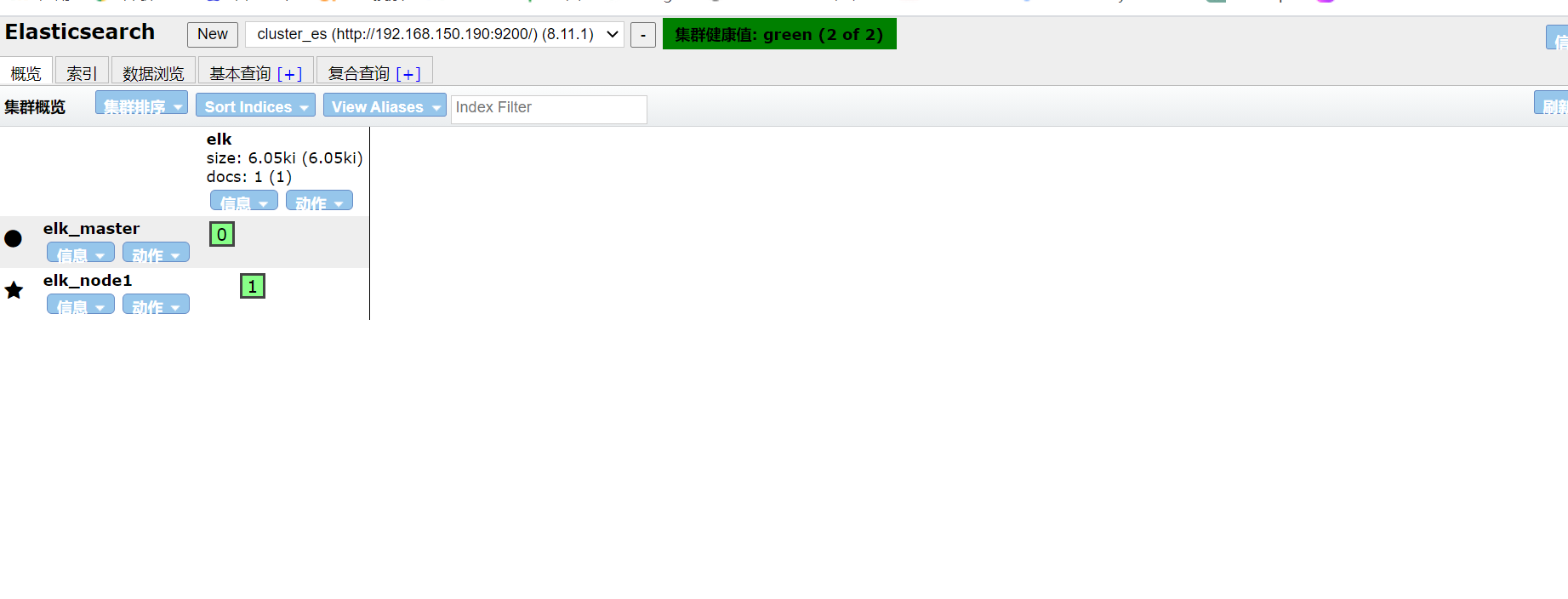
elk_node2节点立马又加入了集群中。
这次选择删除elk_node1节点,可以从看板中知道,该节点是主节点.
看看删除主节点后,会不会在其他节点中产生一个新的节点。

删除node1节点后,节点信息立马变为unassigned了,同时elknode2节点变为了新的master节点。当然了这是随机的,elk_master也可以是新的master节点。
lasticsearch具备自动分配未分配分片到可用节点的机制。当一个节点离开集群时,未分配的分片应该被自动分配到其他可用的节点上,确保集群的高可用性和数据完整性。
理论上,在这种情况下,其他可用的节点应该接管这个分片。然而,可能存在一些情况导致自动分片分配失败,例如网络问题、节点配置问题等。
进行手动分配分片。
先查看可用节点
[root@elk_node2 ~]# curl -X GET "localhost:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.150.188 39 86 0 0.00 0.00 0.00 dm * elk_node2
192.168.150.190 44 88 0 0.03 0.04 0.01 dm - elk_master
[root@elk_node2 ~]# curl -X GET "192.168.150.188:9200/_cat/indices?v"
health status index uuid pri rep docs.count docs.deleted stor
red open elk EhgU7OuaS_q3aj_wVd5e_A 2 0 0 0
[root@elk_node2 ~]# curl -X GET "192.168.150.188:9200/_cat/shards/elk?v"
index shard prirep state docs store dataset ip node
elk 0 p STARTED 0 249b 249b 192.168.150.190 elk_master
elk 1 p UNASSIGNED
- 分配主分片:
curl -X POST "192.168.150.188:9200/_cluster/reroute" -H 'Content-Type: application/json' -d '{
"commands" : [
{
"allocate_stale_primary" : {
"index" : "elk",
"shard" : 1,
"node" : "elk_node2"
}
}
]
}'
请注意,这里使用了 allocate_stale_primary 命令,这是一种尝试为失效节点分配主分片的方式。
- 等待主分片分配完成后,再分配副本:
curl -X POST "192.168.150.188:9200/_cluster/reroute" -H 'Content-Type: application/json' -d '{
"commands" : [
{
"allocate_replica" : {
"index" : "elk",
"shard" : 1,
"node" : "elk_node2"
}
}
]
}'
这两个命令组合起来,应该可以解决主分片和副本分配的问题。如果问题仍然存在,可能需要查看 Elasticsearch 的日志以获取更多详细信息。
在有分片的节点down之后,分片不会直接分配。很关键
更关键的是,这样进行手动分配分片是没因的!! 因为没有副本。。
直接在面板中创建索引
先创建索引
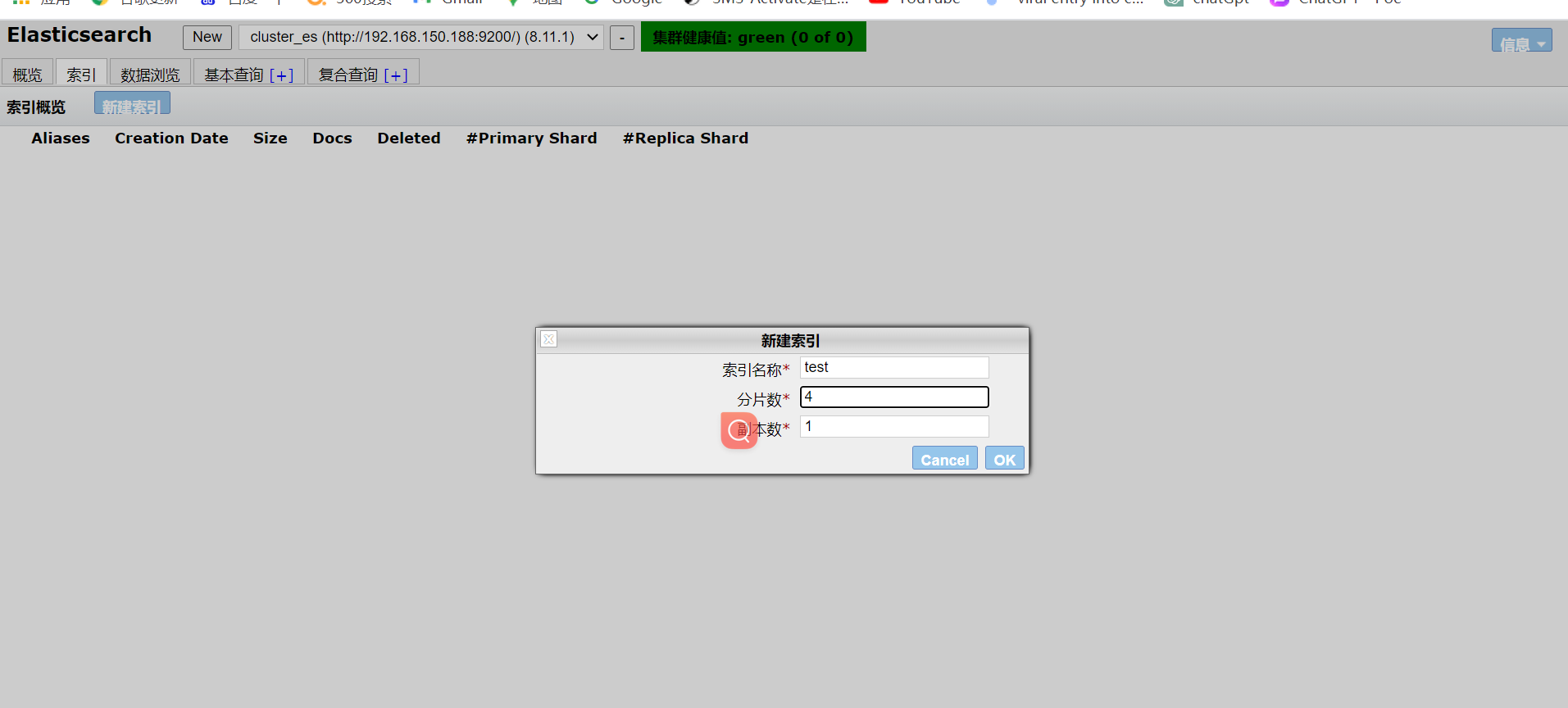
四分片、一个副本数,可以看到已经创建成功了。
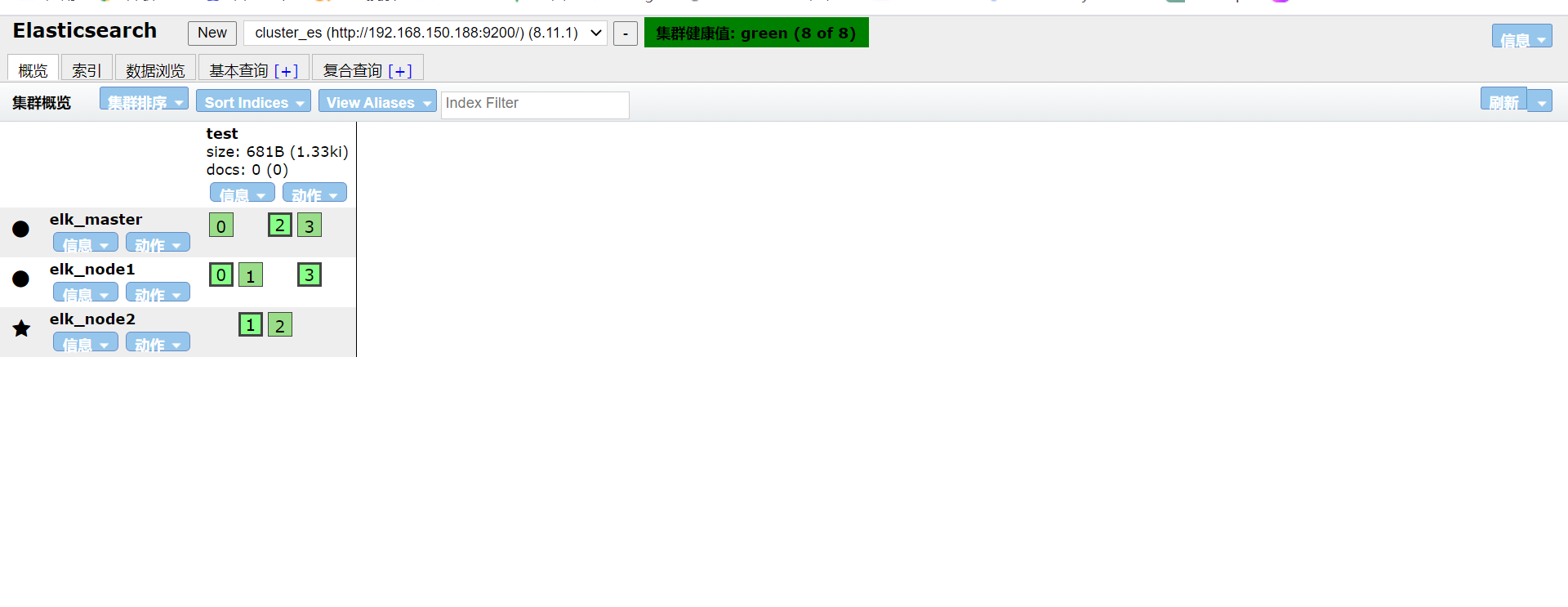
这个时候我们把elk_node1节点停掉。
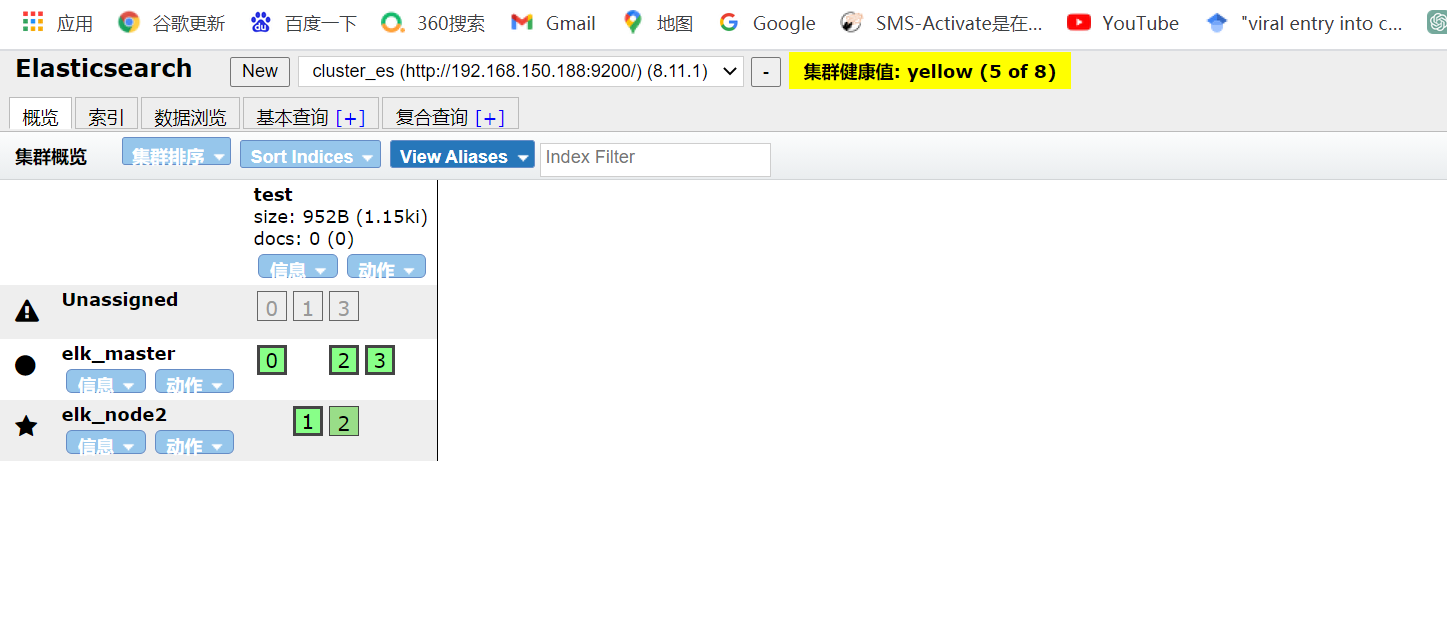
OK,这里可以看到集群颜色变为了黄色,并不是上面的红色了。
表示集群是运行的,但不是所有的主分片和副本分片都是 active(活跃) 状态。这可能是因为某些副本尚未分配,但主分片是活跃的。
经过一段时间之后,我们可以看到集群又重新变为绿色了。
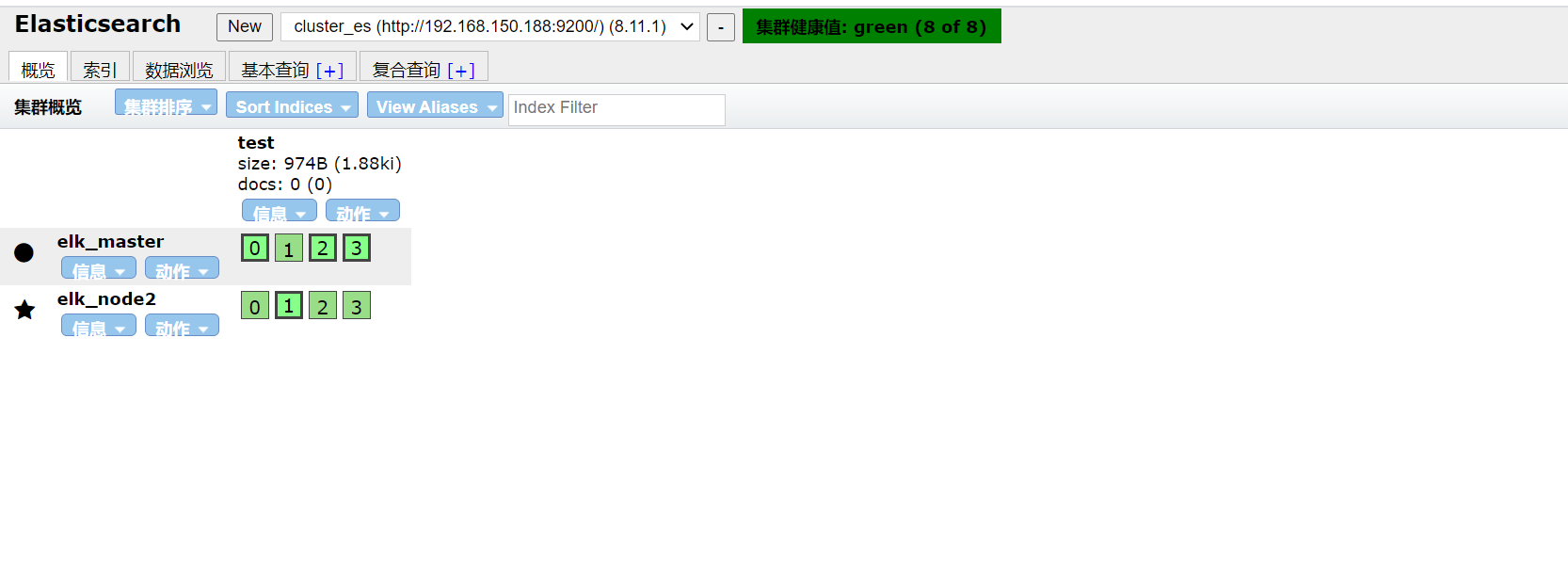
这是因为,集群将其他节点的副本调动起来了,保证正常运行了。
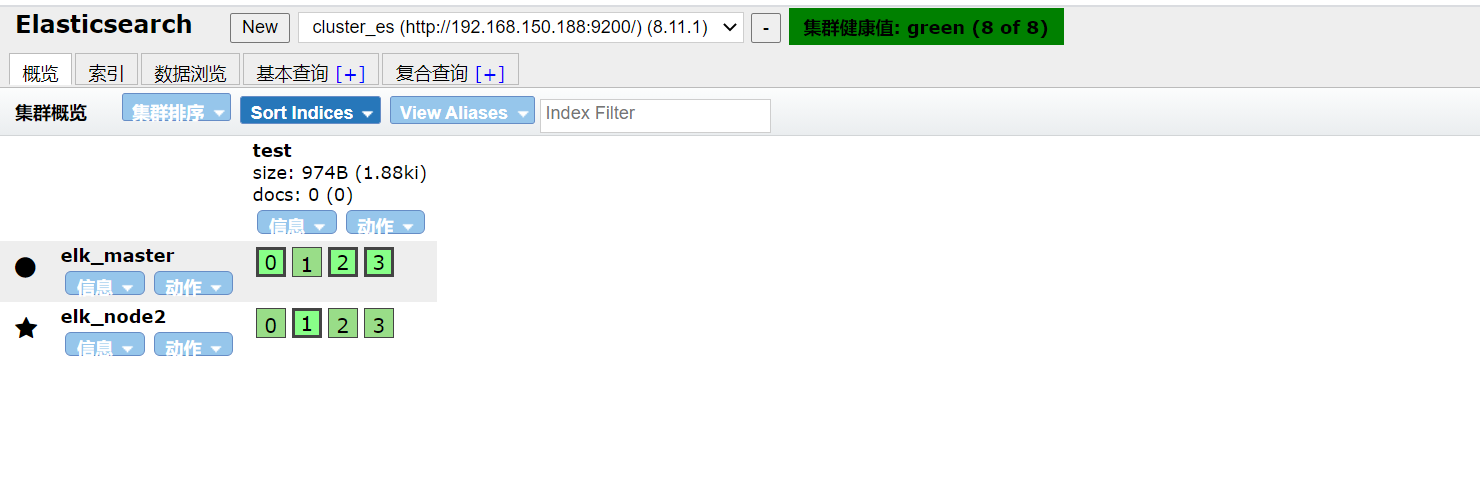
有意思的一点,我们上面创建索引的时候指定的分片是四,每个节点都有对应的四个小方块了,保证了只要还存在节点,项目就肯定可以运行。
现在继续吧elk_master节点停掉,然后又启动看分片的分布
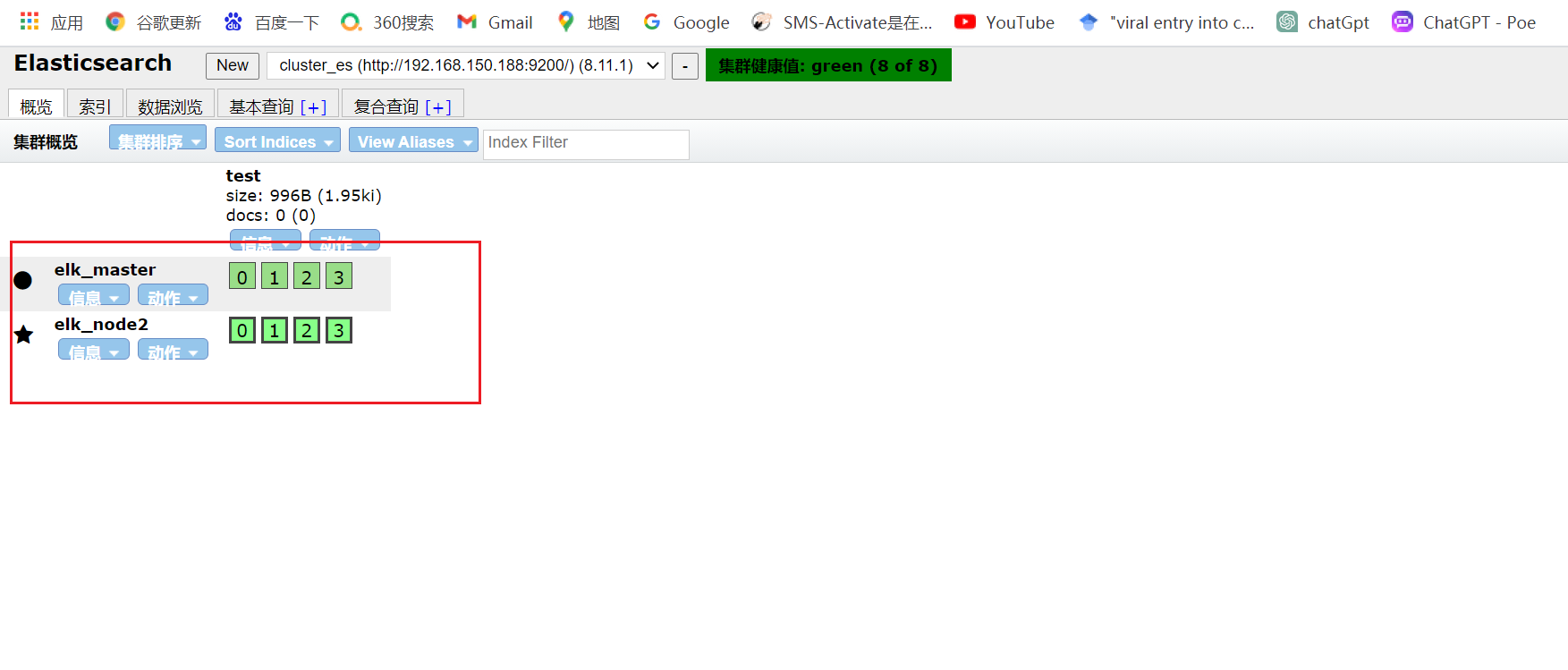
可以看到主片已经全部是elknode2节点上了,而elk_master的分片已经全部是负集了。
总结
- 设置集群的时候,各个节点的配置文件要特别注意节点的名称,主要的不一样就是在这里了。
- 想要故障转移的效果,我们创建索引的时候,需要设置副本,否则不会自动转移。