【人脸检测】——YOLO5Face: Why Reinventing a Face Detector论文浅读
人脸检测, yolov5
主要讨论的问题:
用通用的目标检测模型做人脸检测,而不一定需要一些专业设计的结构
摘要
最近几年在使用卷积神经网络进行人脸检测方面取得了巨大的进展。尽管许多人脸检测器使用专门用于检测人脸的设计,但我们将人脸检测视为一般目标检测任务。我们基于YOLOv5目标检测器实现了一个人脸检测器,并称之为YOLO5Face。我们在其中添加了一个五点地标回归头并使用Wing损失函数。我们设计了不同模型大小的探测器,从大型模型以实现最佳性能,到超小型模型以在嵌入式或移动设备上实时检测。 WiderFace数据集上的实验结果表明,我们的人脸检测器在几乎所有简单、中等和困难子集中都可以实现最先进的性能,超过了更复杂的指定人脸检测器。
1. 简介
我们将人脸检测视为一般目标检测任务。我们与TinaFace 有相同的直觉。直观地说,脸就是一个物体。正如TinaFace中所讨论的那样,从数据的角度来看,脸部具有的属性,如姿势、尺度、遮挡、照明、模糊等,以上的属性也存在于其他物体中。脸部独特的属性,如表情和化妆,也可以对应于物体中的变形和颜色。关键点对于脸部来说是特殊的,但它们也不是唯一的。它们只是物体的关键点。例如,在车牌检测中,也使用了关键点。并且在对象预测头中添加关键点回归是很简单的。人脸检测遇到的挑战,如多尺度、小脸和密集场景,都存在于通用目标检测中。因此,人脸检测只是一般目标检测的一个子任务。
我们遵循这种直觉,基于YOLOv5目标检测器设计了一个人脸检测器。我们修改了人脸检测的设计,考虑到大脸、小脸、地标监督,用于不同的复杂性和应用
我们将YOLOV5目标检测器重新设计为人脸检测器,并称之为YOLO5Face。我们对网络进行了关键修改,以提高平均精度(mAP)和速度方面的性能。
2. 网络结构
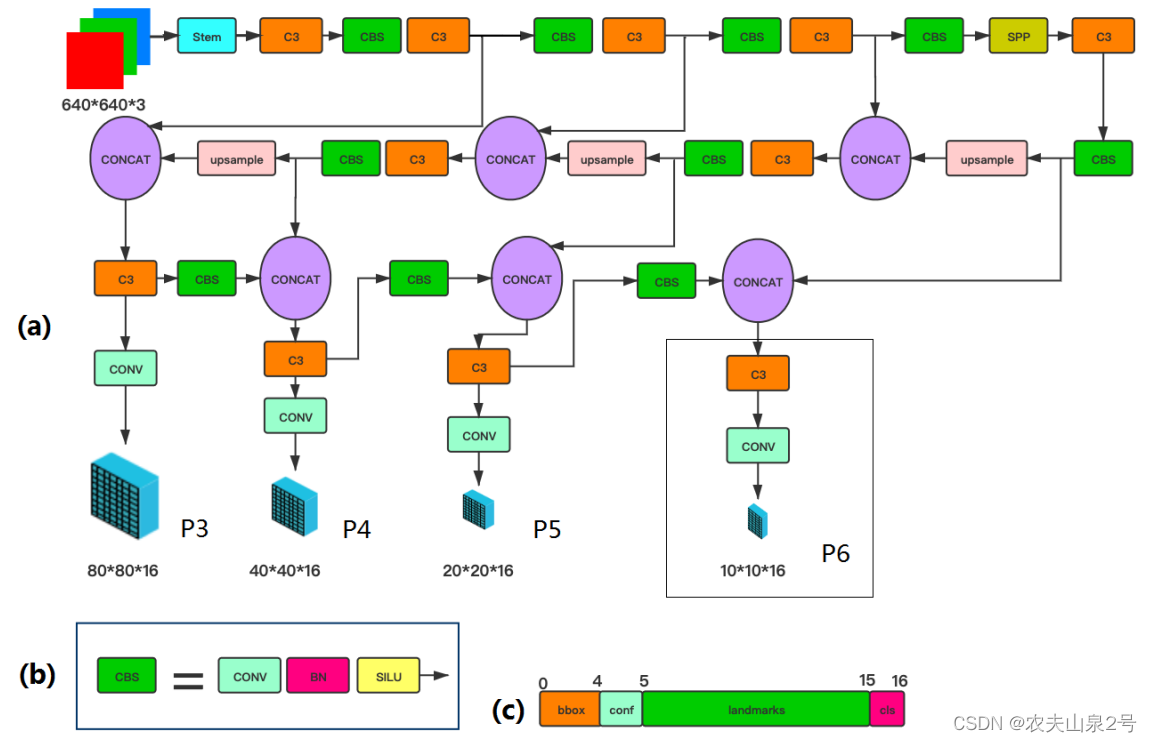
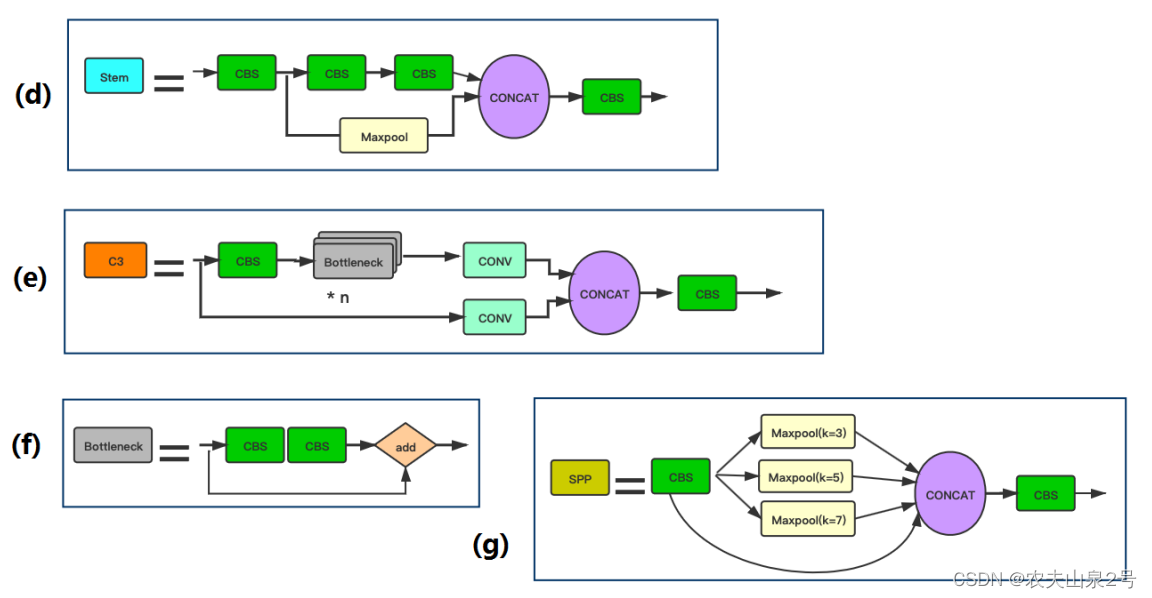
a. 网络结构
以原始的yolov5结构为baseline在进行后续的优化
- 以d图的stem 模块替换了FOCUS 模块
- 提了一个新的csp 模块,参考了 densenet
- 将SPP模块中 max pooling 的大小改为了 3,5,7
- 可选的 1/64 scale 输出
- 更贴近于实际部署场景的分辨率VGA 640x640
- 随机裁剪有助于提高性能,上下翻转,马赛克增强并不适用
- 基于shufflenetv2 设计了两个轻量级的网络
- 人脸关键点部分采用 Wing 损失函数
3. 实验结果
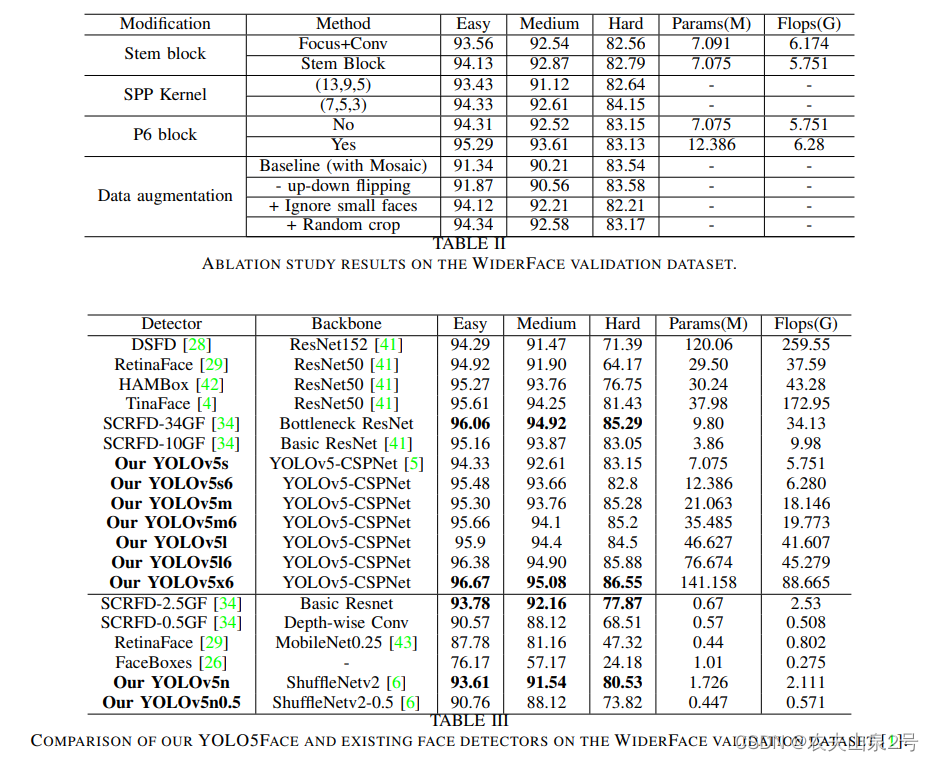
损失函数:
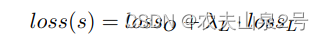
lamda=0.5,检测和关键点回归各一半
- 训练了240epoch, 64的batch size,其他。。。
人脸识别
就不说了
总结
- 将人脸检测直接用通用的目标检测模型是ok的
- 可以借鉴一些实用的图像增强策略:小目标忽略,随机裁剪