多级缓存建设方案
项目背景
xx系统中对容量和耗时有较高要求,以支付优惠立减为例,每个用户咨询可用立减时,都会过一遍全量生效活动。目前日常活动数3000+,目标2w+;日常秒级咨询量1w+,大促22w+。所以如何支撑日常和大促的业务非常具有挑战性。
对此我们做了很多优化,其中缓存是整个优化的基石。我们对优惠模型、优惠活动预算和优惠周期预算等数据都做了缓存,但在日常开发中存在以下问题:
- 没有标准的缓存设计方案,需要翻其他系统的代码去理解怎么做;
- 开发成本高,搭建一套缓存要创建多个类,其中较多代码可复用;
- 容易踩坑,比如数据一致性问题、缓存击穿、热点key问题等。
本次缓存设计参考自yy系统,其代码经过了长时间的验证,所以我们希望输出一套缓存标准化方法,尽量满足当前已有业务场景,经过验证后能推广至其他系统,帮助大家夯实缓存系统,为业务发展保驾护航。
多级缓存整体设计
为什么需要多级缓存?
通过建设 可选的分级缓存结构、各层级缓存数据的不同scope、各层级不同的更新策略 的多级缓存,减少网络IO,极大的提高各个应用节点获取数据的速度。
适用场景
- 针对数据变更较少。如大促期间的优惠配置、商户支付规则配置等。
- 访问量非常大的。这个概念需要case by case去看,一般是某个接口会对某批数据高频查询使用的场景,数据QPS > 10w or 接口TPS > 10w
- 接受较短时间的数据同步延迟的场景。
- 不接受 既要 非常满足CAP能力,又要 保证数据吞吐量,还要 多级缓存结构的业务通用性,这是非常不合理的述求,异常情况兼容处理的 ROI 太低,建议由提出这个想法的人来做。分布式多级缓存的 Consistency 和 Availability,只能是尽量满足,如果业务能接受一些技术层面的规则,我们的架构就能在 Consistency 和 Availability 上做的更好。
分级缓存结构
参照已有的系统,有较为常用的三级缓存结构:
- 常驻缓存:存放静态数据或热点数据,一般没有超时时间也不会被剔除。为解决变更数据的一致性问题,需要数据推送更新一定成功,定时任务只校验数据一致性问题;
- LRU缓存:存放懒加载的热点数据,使用LRU淘汰机制和打散的过期时间维护缓存数据;
- 远端缓存:存放近期的全量数据,会设置较长的过期时间,尽量不被击穿,保护数据源;
- 数据源:存放全量数据,通常是数据库或者外部查询接口。
各级缓存形成一个数据正金字塔,流量访问倒金字塔,越上层存放着越经常访问的数据,承担着更多的流量。

说明:
- 为什么要常驻缓存和LRU缓存?
a. 如果只有一个LRU缓存,那么在预热时存在预读失效的问题,导致真正需要缓存的数据不在LRU中。
b. 如果只有一个常驻缓存,那么其数据容量是有限的,需要选择性的缓存数据,会导致该模块业务通用性不够强。
c. 常驻缓存和LRU缓存设计参考的是InnoDB中的LRU实现思路。 - 常驻缓存、LRU缓存的数据有什么差异?
a. 长期来看,常驻缓存和LRU缓存中的数据会呈现互补的关系。
缓存更新机制(Consistency保障)
多级缓存更新设计时,应考虑的问题
先抛出业务问题,再看解决的方案。
- DB 数据变更后,如何尽快的让业务使用到最新的数据?
- 需要主动更新的方式,尽快变更缓存中的数据
- 在1更新数据时,由于一些未知因素导致缓存数据更新失败,该如何处理?
- 为避免部分数据更新成功,部分数据更新失败,需要保证更新操作的原子性,既有更新的操作,有更新失败的回滚操作即可。(不建议对小概率的异常场景,进行过多的设计)
- 如何及时发现各级缓存的数据不一致问题和使用情况
- 主动增量变更数据时,保证操作的原子性
- 定时任务定时扫描
- 为什么不要延时双删?怎么解决在更新数据的同时,把历史数据加载到了缓存中,导致脏数据长时间在Cache中。延时双删方案
- 本业务方案中,不使用删除的方式,在完成DB的数据变更后,使用更新DB的数据更新到各级缓存,可以解决延时双删方案中,读取并使用老的数据更新缓存的问题。
- 同步更新DB和Cache 或 延时双删的策略,需按业务场景自行决策。
- 如何解决热点key的大批量请求影响系统的运行问题?
- 热点key一般都会被放在一级常驻缓存中,正常来讲,不影响单台node的运行
- 若疏忽上面的步骤,且一级LRU缓存中,没有对应的数据,那么将请求到远端缓存中,此时应当可以得到数据,也可以解决热点key问题对应用的影响
- 若上面两级缓存中都不存在,我们在远端缓存查询DB时,使用分布式排他锁,避免大量请求到DB端,也可以解决绝大部分场景下的热点key问题对应用的影响。
Consistency 由推拉结合的方式来保障,但不同层级的缓存操作流程不一样,整体架构图如下:

通过业务平台被动的数据变更流程

备注:
- 蓝色为业务管理系统,绿色为应用服务
多级缓存主动增量更新机制
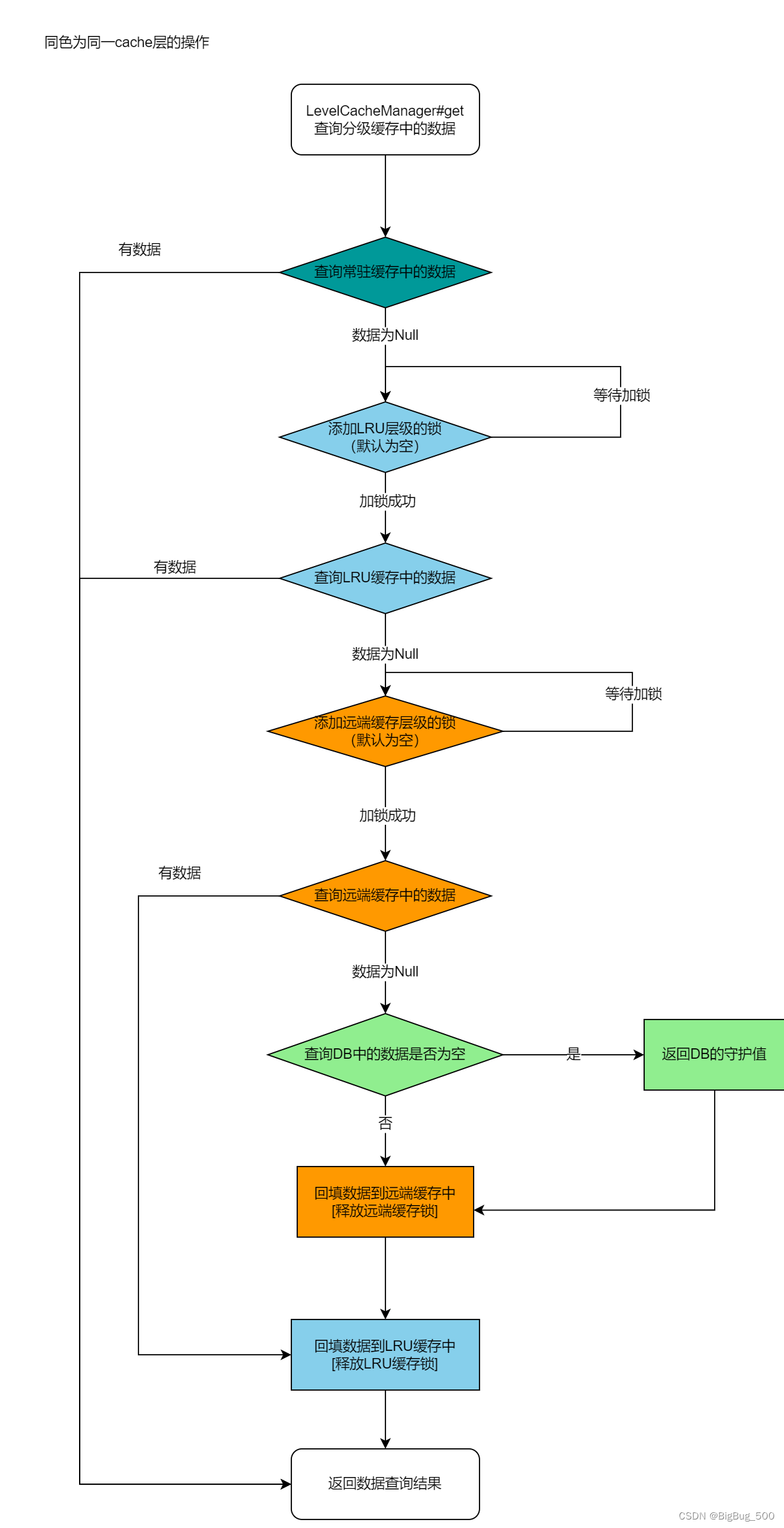
备注:
- 缓存穿透问题的解决:
- 查询前校验key的合法性
- 设置守护值,设置一个较短的过期时间
- 在查询DB的前一级缓存中添加锁(分布式或单机锁),控制缓存击穿。只解决DB层的缓存击穿,其他缓存层级间不处理该问题
- 缓存雪崩问题的解决:
- 设置过期时间时,添加了随机值
定时器缓存核对任务
- 通过指定的策略(loop:30min),扫描缓存中的所有Key,并和DB的数据源进行对比;若数据有差异,则抛出告警,不更新缓存;
- 记录各个缓存层级基础信息,如命中率、内存使用情况、key情况等
缓存预热加载机制
… …