数据库管理-第七十二期 复盘(20230505)
数据库管理 2023-05-05
- 第七十二期 复盘
- 1 再测试
- 2 对照
- 分析:
- 3 如何解决
- 总结
第七十二期 复盘
上一期的内容,我承认主要是在放假,分析过程还是水了一点,SR转回国内之后,处理效率还是提升了一大截。
1 再测试
在客户的要求下昨晚把之前建立的单列索引干掉以后,再执行相同的语句,本以为会花费比较多时间,结果很快就执行完成了,40s。这对我来说到不算是惊吓,只能说,数据量和业务量的增长不是语句跑不出结果的主要原因,需要进一步的分析。
2 对照
把新的SQL Monitor弄出来和之前的做一个对比:
- OLD - poor performance (SQL1)
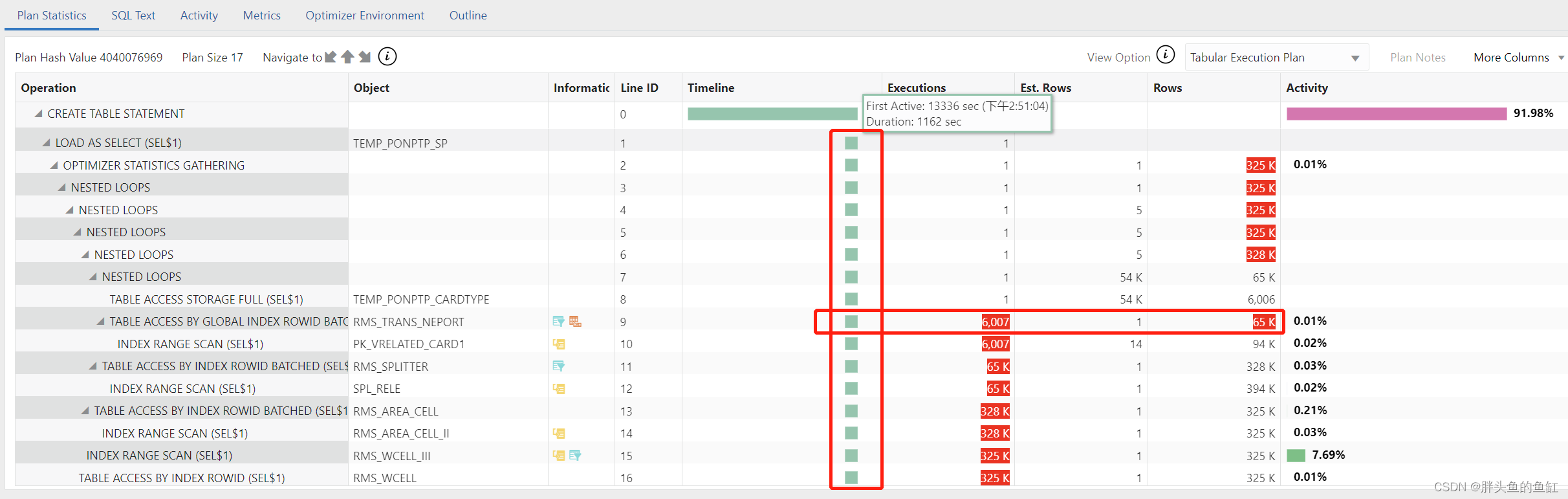

- NEW - good performance (SQL2)

分析:
- 对SQL1进行分析,由时间线入手,CTAS的实际执行加载数据是从语句执行开始的13336s开始的,根据任务开始时间为11:00-11:10之间计算,该语句被阻塞约222.3分钟,至14:40-14:50之间;后开始执行加载数据耗时1162s,约19.4分钟,和15:08处理终止语句时间时间是匹配的上的。
- 同时SQL1是因为row cache lock被阻塞达到13336s。 这个表名在当时可能有相同的或者类似的sql 也在执行同样的操作,导致这个sql 获取不到数据字典上的锁,所以有这个等待事件并且执行很慢。结合业务方反馈9点任务执行失败可能造成数据库后台仍有相关字典锁,一直持续至14:40-14:50之间。
- 以rms_trans_neport为例,SQL1执行1162s仅完成6007次操作扫描65k数据,SQL2执行40s完成54k次操作扫描数据617k并成功完成。经业务方反馈,rms_trans_neport、rms_area_cell d、rms_wcell每日都涉及数据全量刷新,同时temp_ponptp_cardtype为任务执行中创建的临时表,在涉及大规模数据操作或全表数据刷新时会导致表统计信息异常,加上这些操作经常发生在统计信息自动维护任务窗口之外,数据库优化器无法正确根据统计信息分配合理的资源用于运算。
- 语句书写使用自然连接,执行计划解析为nest loop,即5张表根据关联关系row by row筛选数据,进一步增大了分配资源不足带来的执行速度不足的影响。
不得不说当时处置的时候,由于时间紧迫,加上第二次异常紧接着发生,没有时间通过类似于gv$locked_object等视图进一步排查是否在活动SQL以外还有没有异常锁(当然我14:50后登录到服务器和EM也错过了没法直接看到之前的异常会话orSQL)。
3 如何解决
- 业务方调整任务执行机制,确保无相同任务同时执行,并添加任务失败与超时的告警机制。
- 业务方在大规模数据操作或表刷新操作后添加统计信息收集操作以避免因统计信息异常导致的性能问题。
- 业务方修改CTAS建表语句,使用join替代自然连接,增加查询效率。
- 同时Oracle后台SR反馈,PDB回收站功能开启状态也可能出现建表过程中出现"row cache lock" (dc_objects) 相关等待,将继续持续监控数据库,并与业务方沟通是否需要开启回收站功能。(Sessions Hang on “row cache lock” (dc_objects) While Creating & Dropping a Table Concurrently (Doc ID 2319957.1))。
alter system set recyclebin='off' sid='*';
总结
老规矩,知道写了些啥。