java8新特性——StreamAPI
1.集合处理数据的弊端
当我们在需要对集合中的元素进行操作的时候,除了必需的添加,删除,获取外,最典型的操作就是集合遍历。
package com.wxj.streamapi;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class StreamTest01 {
public static void main(String[] args) {
//定义一个集合
List<String> list = Arrays.asList("张三","周星驰","张三丰","星");
List<String> list1 = new ArrayList<>();
//1.获取所有 姓张的信息
for (String s:list) {
if(s.startsWith("张"))
{
list1.add(s);
}
}
//2.获取名称长度为3的用户
List<String> list2 = new ArrayList<>();
for (String s : list1) {
if(s.length() == 3){
list2.add(s);
}
}
//3.输出所有的用户信息
for (String s : list2) {
System.out.println(s);
}
}
}
上面代码针对于我们不同的需求,总是一次次的循环循环循环,这时我们希望有更加高效的处理方式,这时我们可以通过JDK8中提供的Stream API来解决这个问题了。
Stream更加优雅的解决方案:
package com.wxj.streamapi;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class StreamTest02 {
public static void main(String[] args) {
//定义一个集合
List<String> list = Arrays.asList("张三","周星驰","张三丰","星");
List<String> list1 = new ArrayList<>();
//1.获取所有 姓张的信息
//2.获取名称长度为3的用户
//3.输出所有的用户信息
list.stream()
.filter(s -> s.startsWith("张"))
.filter(s -> s.length() == 3)
.forEach(s -> System.out.println(s));
}
}
上面的StreamAPI代码的含义:获取流,过滤张,过滤长度,逐一打印。代码相比上面的更简洁。
2.Stream流式思想概述

Stream API能让我们快速完成许多复杂的操作,如筛选,切片,映射,查找,去除重复,统计,匹配和归约。
3.Stream流的获取方式.
3.1根据Collection获取
首先,java.util.Collection 接口中加入了default方法stream,也就是说Collection接口下的所有的实现都可以通过stream方法来获取Stream流。
package com.wxj.streamapi;
import java.util.*;
public class StreamTest03 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.stream();
Set<String> set = new HashSet<>();
set.stream();
Vector vector = new Vector();
vector.stream();
}
}
但是Map接口没有实现Collection接口,那这时怎么办呢?这时我们可以根据Map获取对应的key value集合。.

3.2通过Stream的of方法
在实际开发中我们不可避免的会操作到数组中的数据,由于数组对象不可能添加默认方法,所以Stream接口中提供了静态方法of。
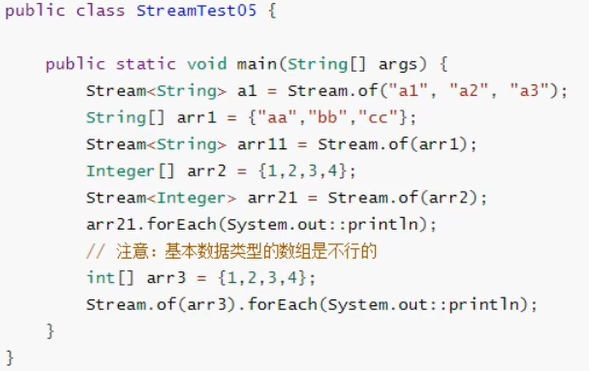
上面中的基本数据类型,int类型,把它当成了一个整体,输出的是地址,而Integer是一个包装类,将数组换成了集合去处理。
4.Stream常用方法

Stream注意事项(重要)
1.Stream只能操作一次
2.Stream方法返回的是新的流
3.Stream不调用终结方法,中间操作不会执行
4.match也是一个终结方法
4.1 forEach方法
forEach用来遍历流中的数据

该方法接受一个Consumer接口,会将每一个流元素交给函数处理

4.2 count方法
Stream流中的count方法用来统计流中元素个数的

该方法返回一个long值,代表元素的个数。无参。

4.3 filter方法
filter方法的作用是用来过滤数据的。返回复合条件的数据

可以通过filter方法将一个流转换成另一个子集流

该接口接受一个Predicate函数式接口参数作为筛选条件

输出的内容是包含a的
4.4 limit方法
limit方法可以对流进行截取处理,只取前n个数据


参数是一个long类型的数值,如果集合当前长度大于参数就进行截取,否则不操作,参数为负数报错。

输出

4.5 skip方法

如果希望跳过前面几个元素,可以使用skip方法获取一个截取以后的新流:

操作:

输出:

4.6 map方法
如果我们需要将流中的元素映射到另一个流中,可以使用map方法


该接口需要一个Function函数式接口参数,可以将当前流中的T类型数据转换成另一种R类型的数据

map方法通过方法引用将字符串转换成整型,Integer::parseInt
4.7 sorted方法
如果需要将数据排序,可以使用sorted方法:

在使用的时候可以根据自然排序,也可以通过比较强来指定对应的排序规则

4.8 distinct方法
如果要去掉重复数据,可以使用distinct方法


操作:

Stream流中的distinct方法对于基本数据类型是可以直接去重的,但是对于自定义类型,我们是需要hashCode和equals方法来移除重复元素。
4.9 match方法
如果需要判断数据是否匹配指定的条件,可以使用match相关的方法

使用:

注意match是一个终结方法
4.10 find方法
如果我们需要找到某些数据,可以使用find来实现


使用:

4.11 max和min方法

如果我们想要获取最大值和最小值,那么可以使用max和min

使用:

4.12 reduce方法

如果需要将所有数据归纳得到一个数据,可以使用reduce方法。
使用:

4.13 map和reduce的组合
在实际开发中我们经常会将map和reduce一块来使用

输出结果:

4.14 mapToInt方法
如果需要将Stream中的Integer类型转换成int类型,可以使用mapToInt方法

使用:

4.15 concat方法
如果有两个流希望合并成为一个流,那么可以使用Stream接口的静态方法concat
使用:

4.16 综合案例
定义两个集合,然后再集合中存储多个用户名称。然后完成如下的操作:
1.第一个队伍只保留姓名长度为3的成员
2.第一个队伍筛选之后只要前3个人
3.第二个队伍只要姓张的成员
4.第二个队伍筛选之后不要前两个人
5.将两个队伍合并成一个队伍
6.根据姓名创建Person对象
7.打印整个队伍的Person信息
实现:
package com.wxj.streamapi;
import com.wxj.jdk.lambda.domain.Person;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Stream;
public class StreamDemo {
public static void main(String[] args) {
List<String> list1 = Arrays.asList("炎柱","音柱","霞柱","恋柱","水柱","风柱","蛇柱","岩柱","虫柱","继国缘一");
List<String> list2 = Arrays.asList("上弦一","上弦二","上弦三","上弦四","上弦五","上弦六","黑死牟","童磨","半天狗");
//1.第一个队伍只保留姓名长度为3的成员
//2.第一个队伍筛选之后只要前3个人
Stream<String> stringStream1 = list1.stream().filter(s -> s.length() == 3).limit(3);
//3.第二个队伍只要姓张的成员
//4.第二个队伍筛选之后不要前两个人
Stream<String> stringStream2 = list2.stream().filter(s -> s.startsWith("上")).skip(2);
//5.将两个队伍合并成一个队伍
//6.根据姓名创建Person对象
//7.打印整个队伍的Person信息
Stream.concat(stringStream1,stringStream2).map(n -> new Person(n)).forEach(System.out::println);
}
}
输出结果:

5.Stream结果收集
5.1结果收集到集合中
实现:

输出:

5.2结果收集到数组中
Stream中提供了toArray方法来将结果放到一个数组中,返回值类型是Object[],如果我们要指定返回的类型,那么可以使用另一个重载的toArray(IntFunction)方法

5.3对流中的数据做聚合计算
当我们使用Stream流处理数据后,可以像数据库的聚合函数一样对某个字段进行操作,比如获得最大值,最小值,求和,平均值,统计数量


5.4对流中的数据做分组操作
当我们使用Stream流处理数据后,可以根据某个属性将数据分组

输出结果:

多级分组:
先根据name分组然后再根据成年未成年分组,


5.5对流中的数据做分区操作
Collectors,partitoningBy会根据值是否为true,把集合中的数据分割成两个列表,一个true列表,一个false列表。
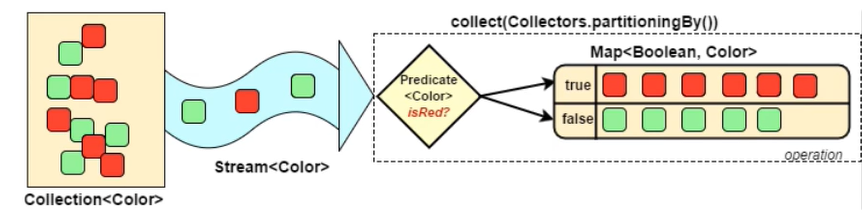

输出结果:

5.5对流中的数据做拼接操作
Collectors,joining会根据指定的连接符,将所有的元素连接成一个字符串

6.并行的Stream流
6.1串行的Stream流
我们前面使用的Stream流都是串行,也就是一个线程上面执行。

输出:

6.2并行流
parallelStream其实就是一个并行执行的流,它通过默认的FprkJoinPool,可以提高多线程的效率。
6.2.1获取并行流
我们可以通过两种方式来获取并行流
1.通过List接口中的parallelStream方法来获取
2.通过已有的串行流转换为并行流(parallel方法)
实现:

6.2.2并行流操作

结果:

6.3并行流和串行流对比
我们通过for循环,串行Stream流,并行Stream流来对5亿个数字求和。来消耗时间。


通过案例我们可以看到parallelStream的效率是最高的。
Stream并行处理的过程会分而治之,也就是将一个大的任务切分成了多个小任务,这表示每个任务都是一个线程操作。
6.线程安全问题
在多线程的处理下,肯定会出现数据安全问题。

运行结果:
直接抛异常,或者执行结果不对。
针对这个问题,我们的解决方案有哪些呢?
1.加同步锁

2.使用线程安全的容器

3.将线程不安全的容器包装为线程安全的容器

4.通过Stream中的toArray方法或者Collect方法来操作
