深度学习入门篇1
1. 目前流行的深度学习框架简介
深度学习框架(点击跳转)
2.神经网络工具箱torch.autograd与torch.nn
torch.autograd库虽然实现了自动求导与梯度反向传播,但如果我们要完成一个模型的训练,仍需要手写参数的自动更新、训练过程的控制等,还是不够便利。为此,PyTorch进一步提供了集成度更高的模块化接口torch.nn,该接口构建于Autograd之上,提供了网络模组、优化器和初始化策略等一系列功能。
3. 代码学习
epoch:训练次数
batch :批次,一次训练要多少个样本一起求误差
torch.autograd包的主要功能就是完成神经网络后向传播中的链式求导,手动去写这些求导程序会导致重复造轮子的现象。
搭建简易神经网络(不使用torch.autograd或torch.nn工具箱,自己求梯度)
下面我们用torch搭一个简易神经网络:不借助工具箱,自己求梯度
1、我们设置输入节点为1000,隐藏层的节点为100,输出层的节点为10
2、输入100个具有1000个特征的数据,经过隐藏层后变成100个具有10个分类结果的特征,然后将得到的结果后向传播
import torch
batch_n = 100#一个批次输入数据的数量
hidden_layer = 100
input_data = 1000#每个数据的特征为1000
output_data = 10
x = torch.randn(batch_n,input_data)
y = torch.randn(batch_n,output_data)
w1 = torch.randn(input_data,hidden_layer)
w2 = torch.randn(hidden_layer,output_data)
epoch_n = 20
lr = 1e-6
for epoch in range(epoch_n):
h1=x.mm(w1)#(100,1000)*(1000,100)-->100*100
print(h1.shape)
h1=h1.clamp(min=0)
y_pred = h1.mm(w2)
loss = (y_pred-y).pow(2).sum()
print("epoch:{},loss:{:.4f}".format(epoch,loss))
grad_y_pred = 2*(y_pred-y)
grad_w2 = h1.t().mm(grad_y_pred)
grad_h = grad_y_pred.clone()
grad_h = grad_h.mm(w2.t())
grad_h.clamp_(min=0)#将小于0的值全部赋值为0,相当于sigmoid
grad_w1 = x.t().mm(grad_h)
w1 = w1 -lr*grad_w1
w2 = w2 -lr*grad_w2
torch.autograd实现一个完整的神经网络(不需要自己求梯度)
torch.autograd包的主要功能就是完成神经网络后向传播中的链式求导,手动去写这些求导程序会导致重复造轮子的现象。
自动梯度的功能过程大致为:先通过输入的Tensor数据类型的变量在神经网络的前向传播过程中生成一张计算图,然后根据这个计算图和输出结果精确计算出每一个参数需要更新的梯度,并通过完成后向传播完成对参数的梯度更新。
完成自动梯度需要用到的torch.autograd包中的Variable类对我们定义的Tensor数据类型变量进行封装,在封装后,计算图中的各个节点就是一个Variable对象,这样才能应用自动梯度的功能。
下面我们使用autograd实现一个二层结构的神经网络模型
import torch
from torch.autograd import Variable
batch_n = 100#一个批次输入数据的数量
hidden_layer = 100
input_data = 1000#每个数据的特征为1000
output_data = 10
x = Variable(torch.randn(batch_n,input_data),requires_grad=False)
y = Variable(torch.randn(batch_n,output_data),requires_grad=False)
#用Variable对Tensor数据类型变量进行封装的操作。requires_grad如果是False,表示该变量在进行自动梯度计算的过程中不会保留梯度值。
w1 = Variable(torch.randn(input_data,hidden_layer),requires_grad=True)
w2 = Variable(torch.randn(hidden_layer,output_data),requires_grad=True)
#学习率和迭代次数
epoch_n=50
lr=1e-6
for epoch in range(epoch_n):
h1=x.mm(w1)#(100,1000)*(1000,100)-->100*100
print(h1.shape)
h1=h1.clamp(min=0)
y_pred = h1.mm(w2)
#y_pred = x.mm(w1).clamp(min=0).mm(w2)
loss = (y_pred-y).pow(2).sum()
print("epoch:{},loss:{:.4f}".format(epoch,loss.data))
loss.backward()#后向传播
w1.data -= lr*w1.grad.data
w2.data -= lr*w2.grad.data
w1.grad.data.zero_()
w2.grad.data.zero_()
自定义传播函数
其实除了可以采用自动梯度方法,我们还可以通过构建一个继承了torch.nn.Module的新类,来完成对前向传播函数和后向传播函数的重写。在这个新类中,我们使用forward作为前向传播函数的关键字,使用backward作为后向传播函数的关键字。下面我们进行自定义传播函数:
import torch
from torch.autograd import Variable
batch_n = 64#一个批次输入数据的数量
hidden_layer = 100
input_data = 1000#每个数据的特征为1000
output_data = 10
class Model(torch.nn.Module):#完成类继承的操作
def __init__(self):
super(Model,self).__init__()#类的初始化
def forward(self,input,w1,w2):
x = torch.mm(input,w1)
x = torch.clamp(x,min = 0)
x = torch.mm(x,w2)
return x
def backward(self):
pass
model = Model()
x = Variable(torch.randn(batch_n,input_data),requires_grad=False)
y = Variable(torch.randn(batch_n,output_data),requires_grad=False)
#用Variable对Tensor数据类型变量进行封装的操作。requires_grad如果是F,表示该变量在进行自动梯度计算的过程中不会保留梯度值。
w1 = Variable(torch.randn(input_data,hidden_layer),requires_grad=True)
w2 = Variable(torch.randn(hidden_layer,output_data),requires_grad=True)
epoch_n=30
for epoch in range(epoch_n):
y_pred = model(x,w1,w2)
loss = (y_pred-y).pow(2).sum()
print("epoch:{},loss:{:.4f}".format(epoch,loss.data))
loss.backward()
w1.data -= lr*w1.grad.data
w2.data -= lr*w2.grad.data
w1.grad.data.zero_()
w2.grad.data.zero_()
使用torch.nn.Sequential、torch.optim、torch.nn.损失函数搭建完成的神经网络
import torch
from torch.autograd import Variable
batch_n = 100#一个批次输入数据的数量
hidden_layer = 100
input_data = 1000#每个数据的特征为1000
output_data = 10
x = Variable(torch.randn(batch_n,input_data),requires_grad=False)
y = Variable(torch.randn(batch_n,output_data),requires_grad=False)
#用Variable对Tensor数据类型变量进行封装的操作。requires_grad如果是F,表示该变量在进行自动梯度计算的过程中不会保留梯度值。
models = torch.nn.Sequential(
torch.nn.Linear(input_data,hidden_layer),
torch.nn.ReLU(),
torch.nn.Linear(hidden_layer,output_data)
)
#torch.nn.Sequential括号内就是我们搭建的神经网络模型的具体结构,Linear完成从隐藏层到输出层的线性变换,再用ReLU激活函数激活
#torch.nn.Sequential类是torch.nn中的一种序列容器,通过在容器中嵌套各种实现神经网络模型的搭建,
#最主要的是,参数会按照我们定义好的序列自动传递下去。
# loss_fn = torch.nn.MSELoss()
# x = Variable(torch.randn(100,100))
# y = Variable(torch.randn(100,100))
# loss = loss_fn(x,y)
epoch_n=10000
lr=1e-4
loss_fn = torch.nn.MSELoss()
optimzer = torch.optim.Adam(models.parameters(),lr=lr)
#使用torch.optim.Adam类作为我们模型参数的优化函数,这里输入的是:被优化的参数和学习率的初始值。
#因为我们需要优化的是模型中的全部参数,所以传递的参数是models.parameters()
#进行,模型训练的代码如下:
for epoch in range(epoch_n):
y_pred = models(x)
loss = loss_fn(y_pred,y)
print("Epoch:{},Loss:{:.4f}".format(epoch,loss.data))
optimzer.zero_grad()#将模型参数的梯度归0
loss.backward()
optimzer.step()#使用计算得到的梯度值对各个节点的参数进行梯度更新。
torch.nn.Sequential
自定义搭建各种神经网络模型:
models = torch.nn.Sequential(
torch.nn.Linear(input_data,hidden_layer),
torch.nn.ReLU(),
torch.nn.Linear(hidden_layer,output_data)
)
全连接(或称线性模型)torch.nn.Linear(input_data,hidden_layer)
H=X*W,其中H是隐藏层或输出层,X是输入层,W是权重。
torch.nn.Linear(输入神经元个数(特征数),隐藏层(或输出层)神经元个数)
非线性激活函数 torch.nn.ReLU()
Y=激活函数ReLU( H ),其中H是隐藏层或输入,Y是输出。
torch.nn.ReLU()
防止过拟合torch.nn.Dropout
用于防止卷积神经网络(或全连接神经网络)在训练过程中发生过拟合,原理是以一定的随机概率将卷积神经网络模型的部分参数归零,以达到减少相邻两层神经连接的目的。
nn.Dropout(p=0.5)
4.从手写数字识别例子中认识torchvision包
torchvision 是PyTorch中专门用来处理图像的库。这个包中有四个大类。
(1)torchvision.datasets
(2)torchvision.models
(3)torchvision.transforms
(4)torchvision.utils
完整代码
import torch
import torchvision
from torchvision import datasets,transforms
from torch.autograd import Variable
import numpy as np
import matplotlib.pyplot as plt
#torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;
# transform=transforms.Compose(
# [transforms.ToTensor(),#将PILImage转换为张量
# transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))#将[0, 1]归一化到[-1, 1]
# #前面的(0.5,0.5,0.5) 是 R G B 三个通道上的均值, 后面(0.5, 0.5, 0.5)是三个通道的标准差
# ])
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: x.repeat(3,1,1)),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
]) # 修改的位置
data_train = datasets.MNIST(root="./data/",
transform=transform,
train = True,
download = True)
data_test = datasets.MNIST(root="./data/",
transform = transform,
train = False)
data_loader_train=torch.utils.data.DataLoader(dataset=data_train,
batch_size=64,#每个batch载入的图片数量,默认为1,这里设置为64
shuffle=True,
#num_workers=2#载入训练数据所需的子任务数
)
data_loader_test=torch.utils.data.DataLoader(dataset=data_test,
batch_size=64,
shuffle=True)
#num_workers=2)
#预览
#在尝试过多次之后,发现错误并不是这一句引发的,而是因为图片格式是灰度图只有一个channel,需要变成RGB图才可以,所以将其中一行做了修改:
images,labels = next(iter(data_loader_train))
# dataiter = iter(data_loader_train) #随机从训练数据中取一些数据
# images, labels = dataiter.next()
img = torchvision.utils.make_grid(images)
img = img.numpy().transpose(1,2,0)
std = [0.5,0.5,0.5]
mean = [0.5,0.5,0.5]
img = img*std+mean
print([labels[i] for i in range(64)])
plt.imshow(img)
import math
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
#构建卷积层之后的全连接层以及分类器
self.conv1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.Conv2d(64,128,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.MaxPool2d(stride=2,kernel_size=2)
)
self.dense = torch.nn.Sequential(
nn.Linear(14*14*128,1024),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(1024,10)
)
def forward(self,x):
x=self.conv1(x)
x=x.view(-1,14*14*128)
x=self.dense(x)
return x
model = Model()
cost = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
print(model)
n_epochs = 5
for epoch in range(n_epochs):
running_loss = 0.0
running_correct = 0
print("Epoch {}/{}".format(epoch,n_epochs))
print("-"*10)
for data in data_loader_train:
X_train,y_train = data
X_train,y_train = Variable(X_train),Variable(y_train)
outputs = model(X_train)
_,pred=torch.max(outputs.data,1)
optimizer.zero_grad()
loss = cost(outputs,y_train)
loss.backward()
optimizer.step()
running_loss += loss.data
running_correct += torch.sum(pred == y_train.data)
testing_correct = 0
for data in data_loader_test:
X_test,y_test = data
X_test,y_test = Variable(X_test),Variable(y_test)
outputs = model(X_test)
_,pred=torch.max(outputs.data,1)
testing_correct += torch.sum(pred == y_test.data)
print("Loss is:{:4f},Train Accuracy is:{:.4f}%,Test Accuracy is:{:.4f}".format(running_loss/len(data_train),100*running_correct/len(data_train)
,100*testing_correct/len(data_test)))
data_loader_test = torch.utils.data.DataLoader(dataset=data_test,
batch_size = 4,
shuffle = True)
X_test,y_test = next(iter(data_loader_test))
inputs = Variable(X_test)
pred = model(inputs)
_,pred = torch.max(pred,1)
print("Predict Label is:",[i for i in pred.data])
print("Real Label is:",[i for i in y_test])
img = torchvision.utils.make_grid(X_test)
img = img.numpy().transpose(1,2,0)
std = [0.5,0.5,0.5]
mean = [0.5,0.5,0.5]
img = img*std+mean
plt.imshow(img)
功能模块的解析
加载训练数据、下载训练数据
(1)从本地加载图片、数据;
(2)从服务器下载并加载图片、数据;
data_train = datasets.MNIST(root="./data/",
transform=transform,
train = True,
download = True)
data_test = datasets.MNIST(root="./data/",
transform = transform,
train = False)
创建待训练模型、加载已训练模型:torchvision.models
(1)创建一个权重随机初始化的网络模型用于下一步的训练,有以下成熟模型可供选择:
AlexNet、VGG、ResNet、SqueezeNet、DenseNet。这几个网络模型各有优缺点,可根据应用场景进行选择。
import torchvision.models as models
resnet18 = models.resnet18()
alexnet = models.alexnet()
squeezenet = models.squeezenet1_0()
densenet = models.densenet_161()
(2) 加载一个别人预训练好的模型:
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
数据变换类torch.transforms (缩放、裁剪、翻转、类型转换)
torchvision.transforms.Resize
torchvision.transforms.Scale
torchvision.transforms.CenterCrop
torchvision.transforms.RandomCrop
torchvision.transforms.RandomHorizontalFlip
torchvision.transforms.RandomVerticalFlip
torchvision.transforms.ToTensor
torchvision.transforms.ToPILImage
数据装载(将训练数据文件加载到变量)torch.utils.data.DataLoader
dataset参数:指定我们载入的数据集的名称;
batch_size参数:设置每个包中图片的数量;
shuffle:是否在装载的过程会将数据随机打乱顺序并进行打包。
data_loader_train=torch.utils.data.DataLoader(dataset=data_train,
batch_size=64,#每个batch载入的图片数量,默认为1,这里设置为64
shuffle=True,
#num_workers=2#载入训练数据所需的子任务数
)
将一个批次的图片构造成网格模式的图片 torchvision.utils.make_grid
#预览
#在尝试过多次之后,发现错误并不是这一句引发的,而是因为图片格式是灰度图只有一个channel,需要变成RGB图才可以,所以将其中一行做了修改:
images,labels = next(iter(data_loader_train))
# dataiter = iter(data_loader_train) #随机从训练数据中取一些数据
# images, labels = dataiter.next()
img = torchvision.utils.make_grid(images)
img = img.numpy().transpose(1,2,0)
std = [0.5,0.5,0.5]
mean = [0.5,0.5,0.5]
img = img*std+mean
print([labels[i] for i in range(64)])
plt.imshow(img)
nn.Conv2d(输入通道数,输出通道数,kernel_size=3,stride=1,padding=1),
通道:一个通道即一个2维矩阵,如rgb图像有3个通道,分别是人r、g、b通道,矩阵的值是0~255彩色值。
卷积和池化
self.conv1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.Conv2d(64,128,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.MaxPool2d(stride=2,kernel_size=2)
)
加载数据后如何使用数据进行for循环训练?
print(type(data_loader_train))
结果为: <class ‘torch.utils.data.dataloader.DataLoader’>
将本地的图像数据加载到变量data_loader_train后,发现数据的类型是一个类,所有信息都在类中,而不是加载成一个矩阵的形式,那么如何进行训练和使用呢??
根据以下代码我们可以发现这个数据是一个迭代器,因此可以利用迭代器把数据取出并保存成矩阵的形式,这样就可以用常规的方法进行训练了…
images, labels = next(iter(data_loader_train))
运行结果:

理论储备
python3 知识点
迭代器,迭代器对象,迭代器的元素
基本函数iter( ), next( ) :
list=[1,2,3,4] # 列表本身是一个迭代器
it = iter(list) # 创建迭代器对象
print (next(it)) # 输出迭代器的下一个元素
在for循环中的应用:
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
for x in it:
print (x, end=" ")
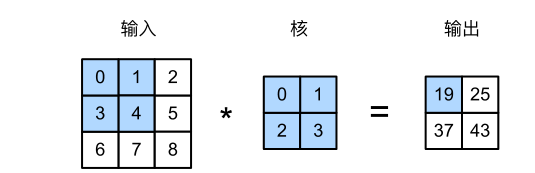
2维卷积
意义:特征提取
具体运算方式:
卷积核从输入的最左上方开始,从左往右、从上往下进行滑动
当滑到某一位置时,窗口中的元素与输入的对应元素相乘,然后将所有乘积的结果相加,得到当前位置的输出
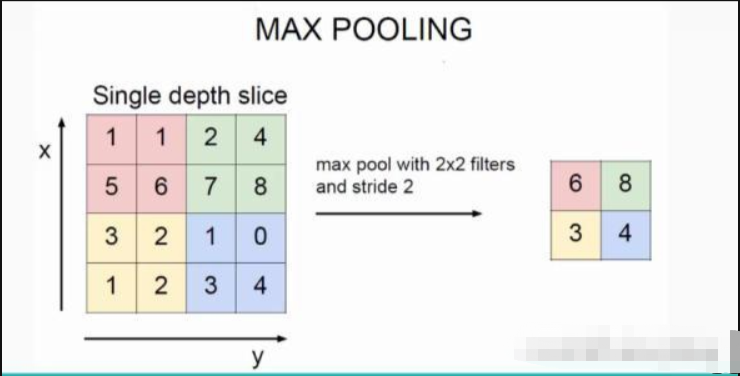
池化pooling
意义:本质是采样达到降维压缩的麦目的,以加快运算速度。
池化过程在一般卷积过程后。池化(pooling) 的本质,其实就是采样。Pooling 对于输入的 Feature Map,选择某种方式对其进行降维压缩,以加快运算速度。Pooling 层说到底还是一个特征选择,信息过滤的过程。也就是说我们损失了一部分信息,这是一个和计算性能的一个妥协,随着运算速度的不断提高,我认为这个妥协会越来越小。现在有些网络都开始少用或者不用pooling层了。
- 最大池化(Max Pooling)
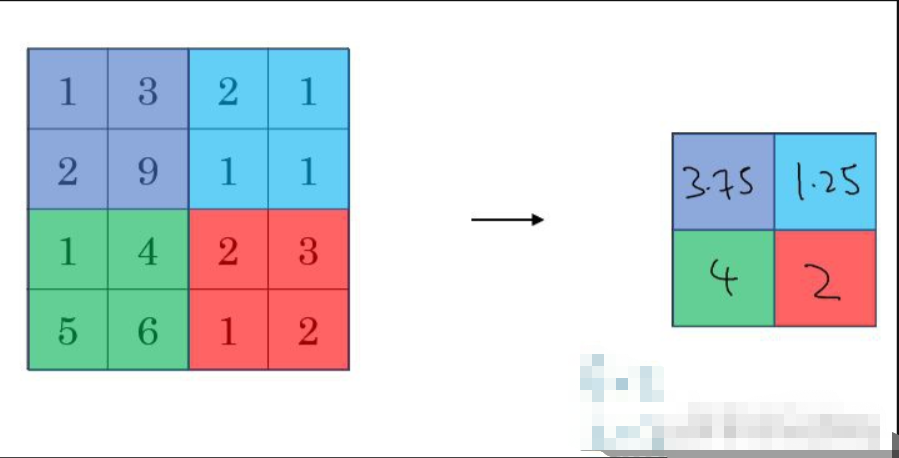
- 平均池化(Average Pooling)
填充pading
原图像没有pading的话每卷积一次,图像就会变小,卷积几次图像就会变得非常小,这并不是我们所希望的;第二点是,图像角落和边缘的像素卷积过程中被使用到的次数非常少,而其他地方的像素被多次重叠使用,丢失了边界上许多信息。所以为了解决上面两个问题,在卷积之前使用pad(填充)周边方式。
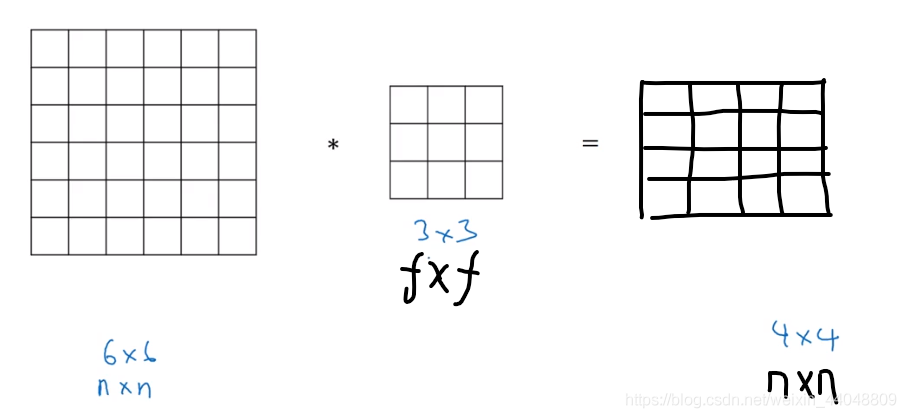
有了pading后可以让卷积hou的图像与原图像素大小一致
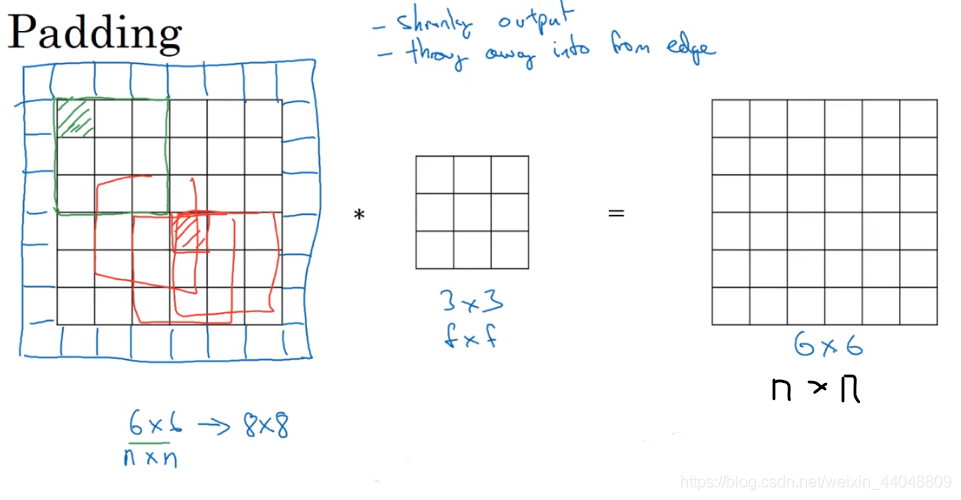
想要卷积后大小不变,pading的设置与卷积的步长相关:
参考文献
【1】https://blog.csdn.net/weixin_41480034/article/details/124814867
【2】https://blog.csdn.net/CltCj/article/details/120060543
【3】https://blog.csdn.net/weixin_44048809/article/details/105746351