Spark - 继承 FileOutputFormat 实现向 HDFS 地址追加文件
目录
一.引言
二.源码浅析
1.RDD.saveAsTextFile
2.TextOutputFormat
3.FileOutputFormat
三.源码修改
1.修改文件生成逻辑 - getRecordWriter
2.允许目录存在 - checkoutputSpecs
3.全部代码 - TextOutputFormatV2
四.追加存储代码实战
五.总结
一.引言
Output directory file XXX already exists 目标目录已经存在,这个报错写 Spark 的同学都不会陌生,它不允许我们在同一个目录持续增加文件存储。在使用 Flink 文件流场景中,我们有向 HDFS 目录追加文件的需求,所以下面我们尝试继承 FileOutputFormat 实现自定义文件追加。

二.源码浅析
自定义实现之前,我们需要明确一下追加文件的两个主要问题:
- 允许目录存在
即避免 Output directory file XXX already exists 的报错
- 避免 File 重复
由于是追加文件,这里我们要避免文件名相同导致追加失败
1.RDD.saveAsTextFile
这个是我们日常使用的文本落地 API:
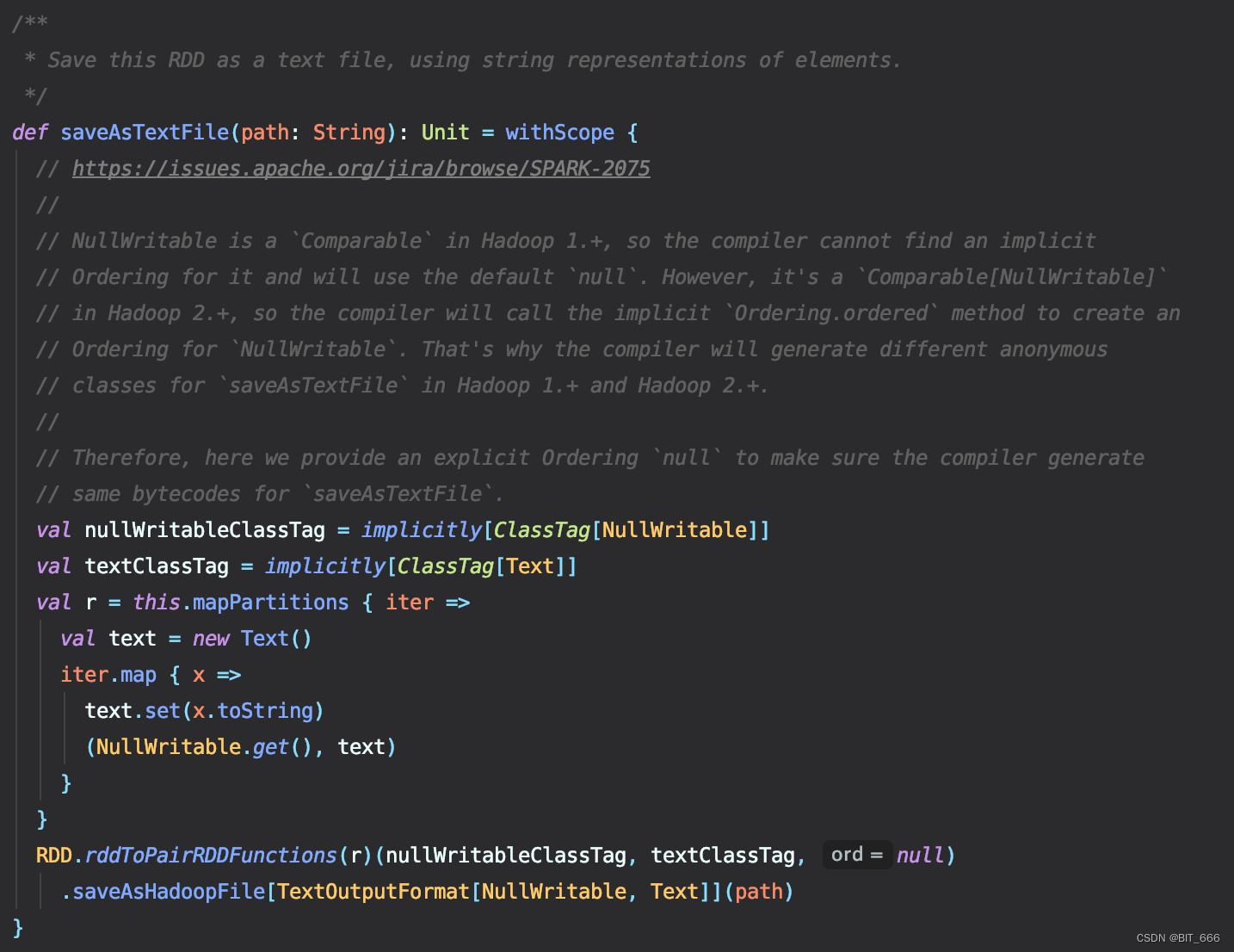
这里将原始的 RDD[String] 转化为 (NullWritable.get(), text) 的 pairRDD 并调用后续的 saveAsHadoopFile 并传入 TextOutputFormat:
- NullWritable
在Hadoop1.+中是 "Comparable",因此编译器无法找到隐式为其排序,并将使用默认的 "null"。然而,它是一个 `Comparable[NullWritable]` 在 Hadoop2.+ 中,编译器将调用隐式 "Ordering.ordered” 方法来创建为 "NullWritable" 排序。这就是为什么编译器会生成不同的匿名Hadoop1.+和Hadoop2.+中“saveAsTextFile”的类。因此,在这里我们提供了一个显式排序“null”,以确保编译器生成 "saveAsTextFile" 的字节码相同。
这里翻译自官方 API,简言之,我们后续自定义 OutputFormat 时需要将 RDD[String] 转换为 PairRDD 并将 key 置为 NullWritable,否则这里无法调用 saveAsHadoopFile:
2.TextOutputFormat
前者继承了后者,我们先看下前者复写了哪些函数:
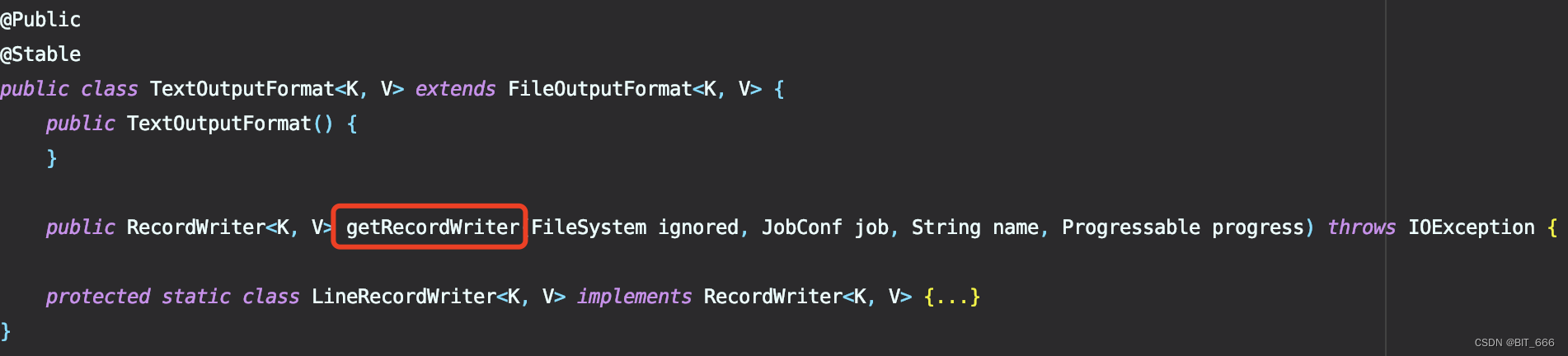
非常简洁,大部分方法都使用父类的实现,这里 getRecordWriter 的具体实现对应我们上面提到的第二个问题即避免文件重复,因为其负责根据 name 轮训生成落地的 Path 地址,我们修改这个函数即可避免追加时文件重复。
3.FileOutputFormat
TextOutputFormat Extends FileOutputFormat,上面 TextOutputFormat 只实现了 Path 相关的工作,所以需要继续到父类 FileOutputFormat 寻找抛出异常的语句:
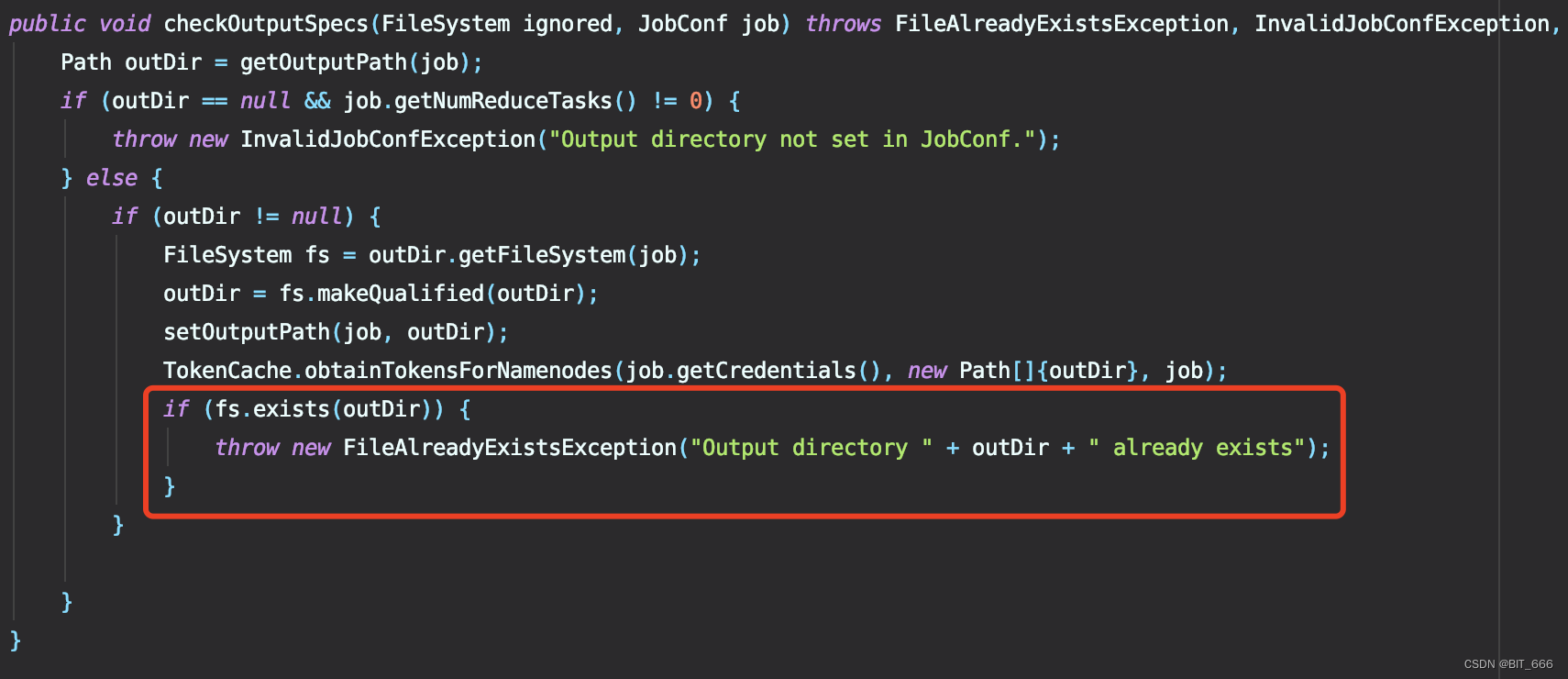
在文件中搜索 already exists 即可定位到当前函数,是不是很熟悉,因此针对第一个问题避免文件的报错就要修改这里了,最简单的我们把这三行注释掉即可。
三.源码修改
经过上面的源码三部曲,我们如何修改 TextOutputFormat 思路也很清晰了,修改文件生成逻辑、取消抛出异常即可,下面看一下代码实现:
1.修改文件生成逻辑 - getRecordWriter
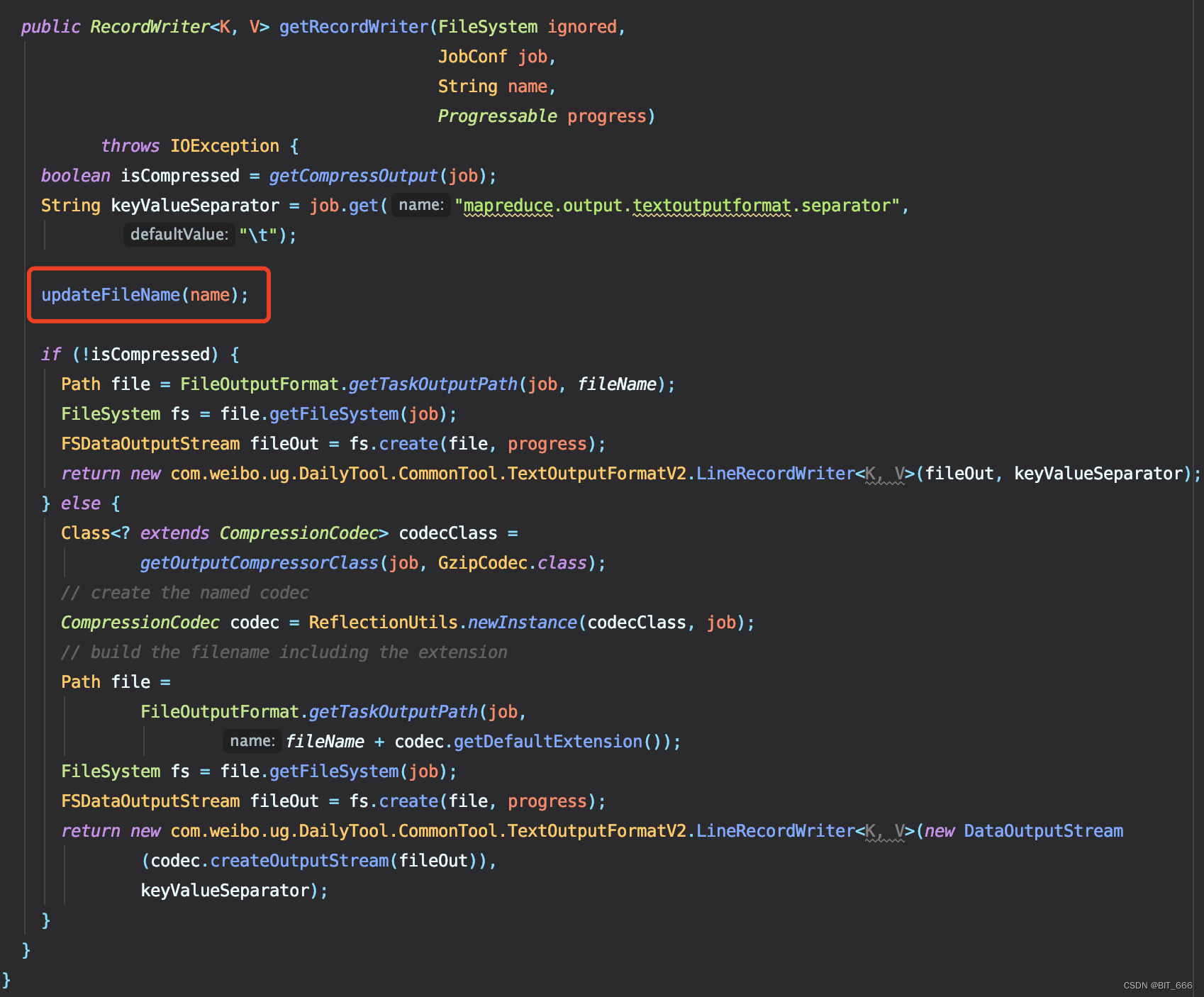
这里我们在源码中增加了 updateFileName 函数,该函数由用户自己定义输出文件名,常规的我们可以按照 part-00000、part-00001 的顺序继续存储下去,当然如果为了区分追加文件的添加时间与类型,我们也可以给其打上时间戳和自定义标记,都不想用的话也可以直接用 UUID 代替:
import java.util.UUID
UUID.randomUUID().toString
下面看一下 updateFileName 的实现:
这里初始化变量 fileName 为 "",更新时对其加锁并基于当前 name 进行判断,如果当前 fileName 为 "",则代表是第一次保存,因此默认使用 name 的 part-00000,后续再多次存储是,我们就可以获取 fileName 的后缀进行累加输出了,这里使用 DecimalFormat 实现了自动补 0 的操作。
static String fileName = "";
DecimalFormat decimalFormat = new DecimalFormat("00000");
public void updateFileName(String name) {
synchronized (fileName) {
if (fileName.equals("")) {
fileName = name;
} else {
fileName = "part-" + decimalFormat.format(Integer.parseInt(fileName.split("-")[1]) + 1);
}
}
}2.允许目录存在 - checkoutputSpecs
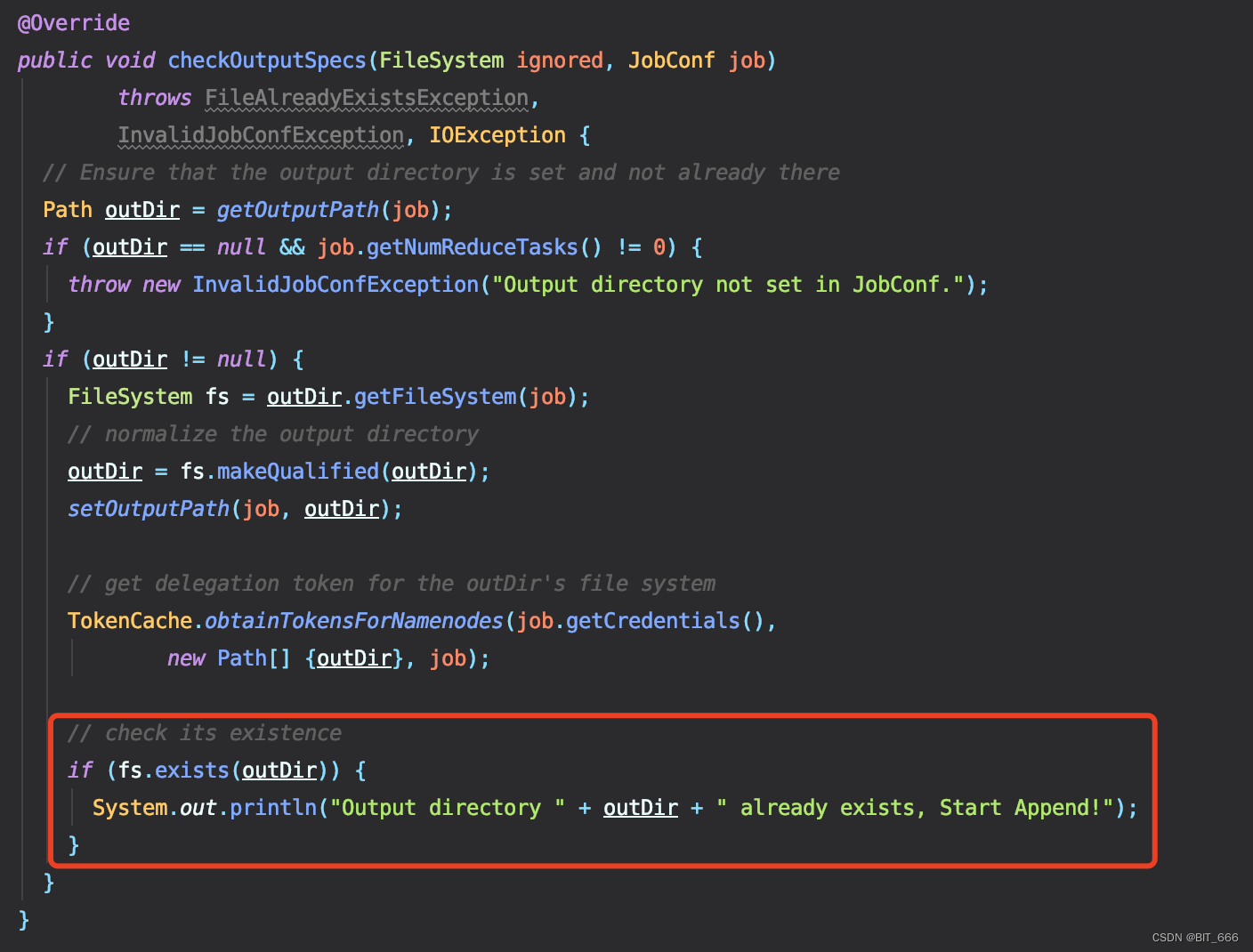
把 throw Exception 的异常去掉就好了,这里保留了 Println 提示目录已经存在并开始追加。
3.全部代码 - TextOutputFormatV2
换个 TextOutputFormatV2 实现我们追加文件存储的目的。
import java.io.DataOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.text.DecimalFormat;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.mapreduce.security.TokenCache;
import org.apache.hadoop.util.*;
/**
* An {@link OutputFormat} that writes plain text files.
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public class TextOutputFormatV2<K, V> extends FileOutputFormat<K, V> {
static String fileName = "";
DecimalFormat decimalFormat = new DecimalFormat("00000");
public void updateFileName(String name) {
synchronized (fileName) {
if (fileName.equals("")) {
fileName = name;
} else {
fileName = "part-" + decimalFormat.format(Integer.parseInt(fileName.split("-")[1]) + 1);
}
}
}
protected static class LineRecordWriter<K, V>
implements RecordWriter<K, V> {
private static final String utf8 = "UTF-8";
private static final byte[] newline;
static {
try {
newline = "\n".getBytes(utf8);
} catch (UnsupportedEncodingException uee) {
throw new IllegalArgumentException("can't find " + utf8 + " encoding");
}
}
protected DataOutputStream out;
private final byte[] keyValueSeparator;
public LineRecordWriter(DataOutputStream out, String keyValueSeparator) {
this.out = out;
try {
this.keyValueSeparator = keyValueSeparator.getBytes(utf8);
} catch (UnsupportedEncodingException uee) {
throw new IllegalArgumentException("can't find " + utf8 + " encoding");
}
}
public LineRecordWriter(DataOutputStream out) {
this(out, "\t");
}
/**
* Write the object to the byte stream, handling Text as a special
* case.
* @param o the object to print
* @throws IOException if the write throws, we pass it on
*/
private void writeObject(Object o) throws IOException {
if (o instanceof Text) {
Text to = (Text) o;
out.write(to.getBytes(), 0, to.getLength());
} else {
out.write(o.toString().getBytes(utf8));
}
}
public synchronized void write(K key, V value)
throws IOException {
boolean nullKey = key == null || key instanceof NullWritable;
boolean nullValue = value == null || value instanceof NullWritable;
if (nullKey && nullValue) {
return;
}
if (!nullKey) {
writeObject(key);
}
if (!(nullKey || nullValue)) {
out.write(keyValueSeparator);
}
if (!nullValue) {
writeObject(value);
}
out.write(newline);
}
public synchronized void close(Reporter reporter) throws IOException {
out.close();
}
}
@Override
public void checkOutputSpecs(FileSystem ignored, JobConf job)
throws FileAlreadyExistsException,
InvalidJobConfException, IOException {
// Ensure that the output directory is set and not already there
Path outDir = getOutputPath(job);
if (outDir == null && job.getNumReduceTasks() != 0) {
throw new InvalidJobConfException("Output directory not set in JobConf.");
}
if (outDir != null) {
FileSystem fs = outDir.getFileSystem(job);
// normalize the output directory
outDir = fs.makeQualified(outDir);
setOutputPath(job, outDir);
// get delegation token for the outDir's file system
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] {outDir}, job);
// check its existence
if (fs.exists(outDir)) {
System.out.println("Output directory " + outDir + " already exists, Start Append!");
}
}
}
public RecordWriter<K, V> getRecordWriter(FileSystem ignored,
JobConf job,
String name,
Progressable progress)
throws IOException {
boolean isCompressed = getCompressOutput(job);
String keyValueSeparator = job.get("mapreduce.output.textoutputformat.separator",
"\t");
updateFileName(name);
if (!isCompressed) {
Path file = FileOutputFormat.getTaskOutputPath(job, fileName);
FileSystem fs = file.getFileSystem(job);
FSDataOutputStream fileOut = fs.create(file, progress);
return new com.CommonTool.TextOutputFormatV2.LineRecordWriter<K, V>(fileOut, keyValueSeparator);
} else {
Class<? extends CompressionCodec> codecClass =
getOutputCompressorClass(job, GzipCodec.class);
// create the named codec
CompressionCodec codec = ReflectionUtils.newInstance(codecClass, job);
// build the filename including the extension
Path file =
FileOutputFormat.getTaskOutputPath(job,
fileName + codec.getDefaultExtension());
FileSystem fs = file.getFileSystem(job);
FSDataOutputStream fileOut = fs.create(file, progress);
return new com.CommonTool.TextOutputFormatV2.LineRecordWriter<K, V>(new DataOutputStream
(codec.createOutputStream(fileOut)),
keyValueSeparator);
}
}
}四.追加存储代码实战
def main(args: Array[String]): Unit = {
val (argsList, argsMap) = ArgsParseUtil.parseArgs(args)
val conf = (new SparkConf).setAppName("AppendFileToHdfs").setMaster("local[*]")
val spark = SparkSession
.builder
.config(conf)
.getOrCreate()
val sc = spark.sparkContext
val output = argsMap.getOrElse("output", "./append_output")
val data = sc.parallelize(0 to 1000).mapPartitions { iter =>
val text = new Text()
iter.map { x =>
text.set(x.toString)
(NullWritable.get(), text)
}
}
(0 until 10).foreach(epoch => {
// 存储一次无法继续存储
// data.saveAsTextFile(output)
data.saveAsHadoopFile(output, classOf[NullWritable], classOf[Text], classOf[TextOutputFormatV2[NullWritable, String]])
})
}首先转化为 (NullWritable.get(), text) 的 pairRDD,随后调用 saveAsHadoopFile 方法并传入我们自定义的 TextOutputFormatV2 即可,由于我们 for 循环了 10 次,所以打印了 10 个相关日志。

下面再看下生成的文件:
![]()
每个文件存 250 个数字,每次存储 4 个 part,10 次 40 个且保持递增顺序。
五.总结
想要结合源码进行修改时,结合自己的需求,带着问题去找对应的函数再复写就 OK 了,由于这里逻辑比较简单所以我们也没踩太多坑。上面采用的是单次 Job 连续存储,所以 Format 里 FileName 能够达到累加的情况,如果是多个 Job 重复启动,则每次获取的都是 part-00000,这时如果还想要保持文件名递增的话可以使用 FileSystem.listStatus 遍历文件夹获取 modifyTime 最新的文件并取其 name 即可拿到最新的文件名 part,此时将参数传入 TextFormat 并修改 update 逻辑即可实现多 Job 重复启动且文件名递增的需求了。当然了,使用 UUID + Date 是最省事滴。