数据分析基础之《pandas(2)—基本数据操作》
一、读取一个真实的股票数据
1、读取数据
# 基本数据操作
data = pd.read_csv("./stock_day.csv")
data
# 删除一些列,使数据简洁点
data = data.drop(['ma5','ma10','ma20','v_ma5','v_ma10','v_ma20'], axis=1)
data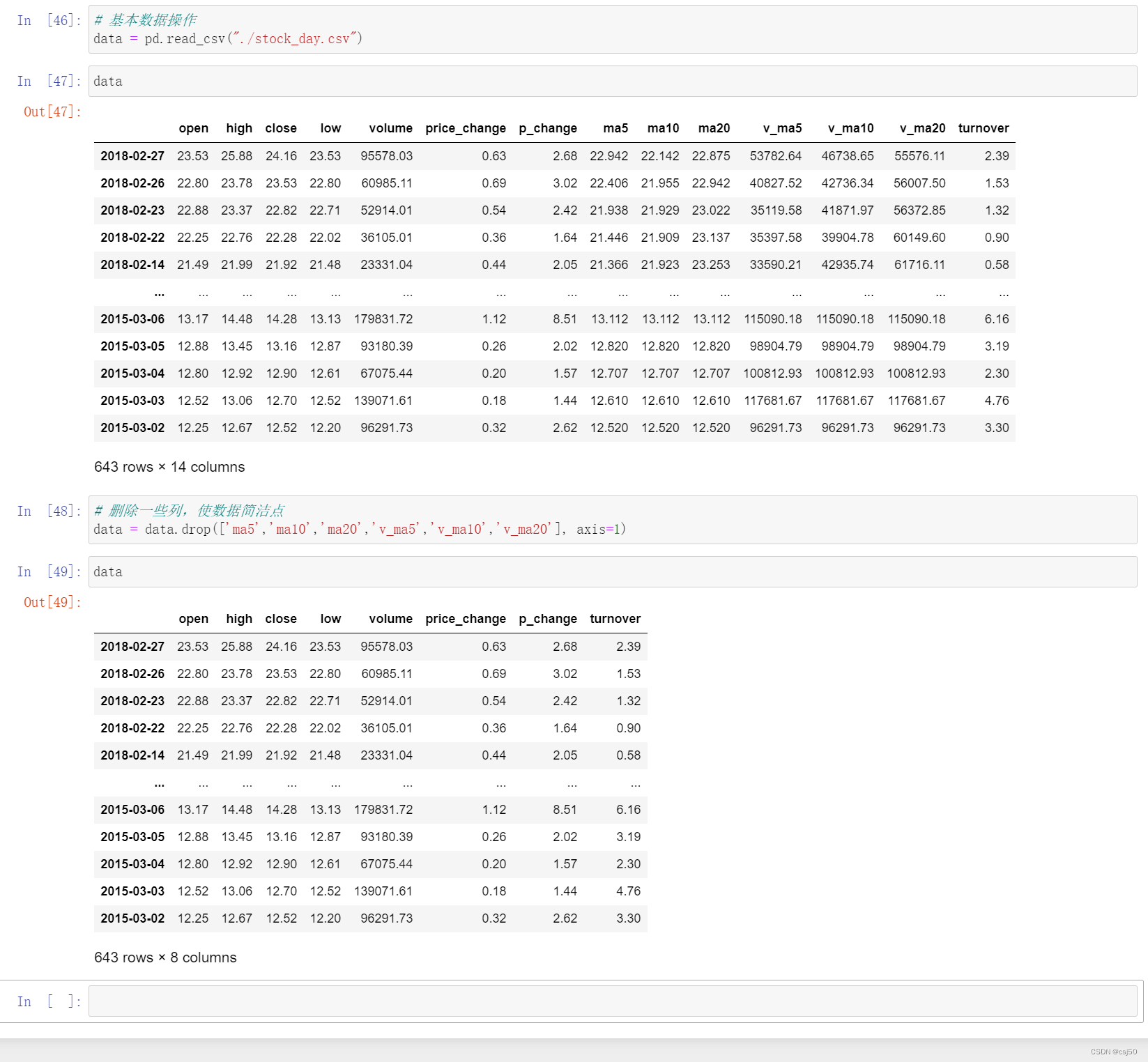
二、索引操作
1、numpy当中我们已经讲过使用索引选取序列和切片选择,pandas也支持类似操作
2、直接使用行列索引(先列后行)
因为dataframe带了行列索引,所以可以直接用它的,要注意先列后行
data['open']['2018-02-26']
3、按名字索引
结合loc函数使用,通过行标签索引行数据,可以多行,可以[行标签, 列标签]
data.loc['2018-02-26','open']
4、按数字索引
结合iloc函数使用,通过行号索引行数据
data.iloc[1, 0]
5、组合索引
结合ix函数使用,注意ix函数在0.20.0版本已经废弃
获取行第1天到第4天,['open','close','high','low']这四个指标的结果
data.ix[0:4, ['open','close','high','low']]
组合索引目前已经整合到iloc里,直接用iloc进行组合索引
# 推荐使用loc和iloc方式获取
data.loc[data.index[0:4], ['open','close','high','low']]
data.iloc[0:4, data.columns.get_indexer(['open','close','high','low'])]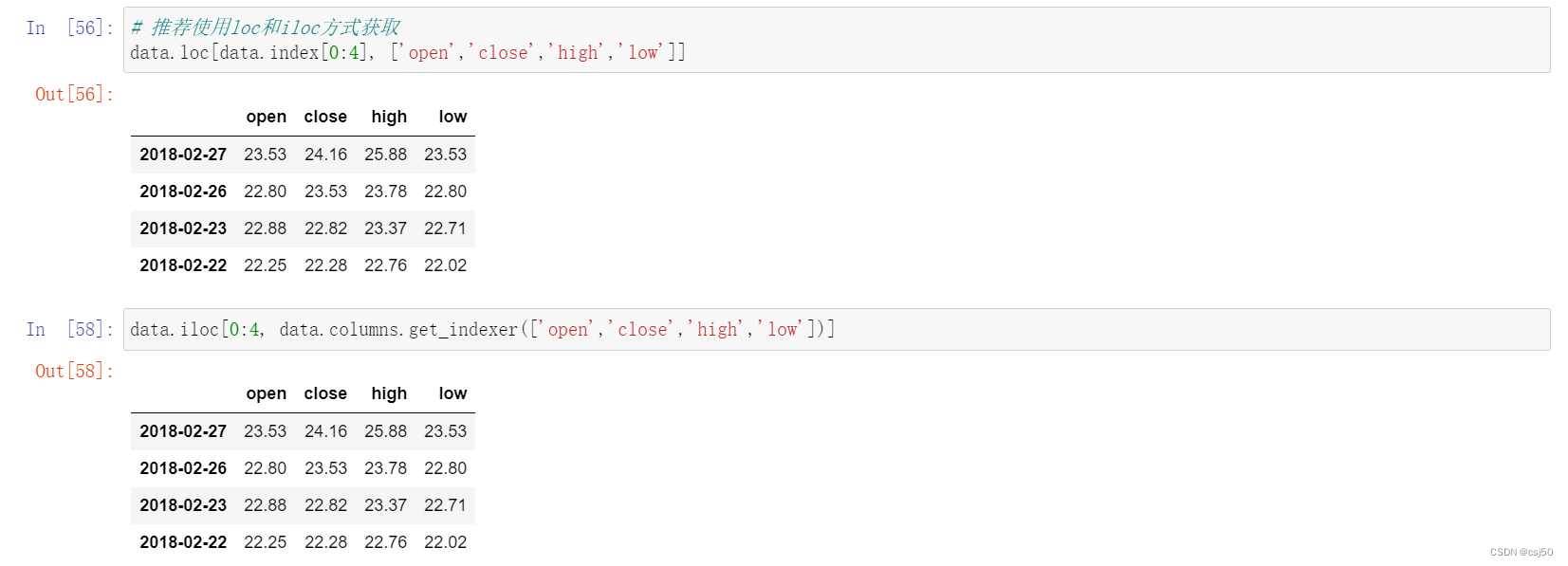
三、赋值操作
1、修改一整列
data.open = 100
2、赋值某一个字段
用上面索引方法找到这一个值,然后赋值
# 修改第2行第1列
data.iloc[1, 0] = 222
四、排序
1、排序有两种形式,一种对内容进行排序,一种对索引进行排序
2、DataFrame
sort_values(by=, ascending=)
对内容进行排序
说明:
(1)by:单个键或者多个键进行排序,默认升序
(2)ascending=False,降序
(3)ascending=True,升序
# 按照涨跌幅大小进行排序,使用ascending指定
data.sort_values(by='p_change', ascending=False)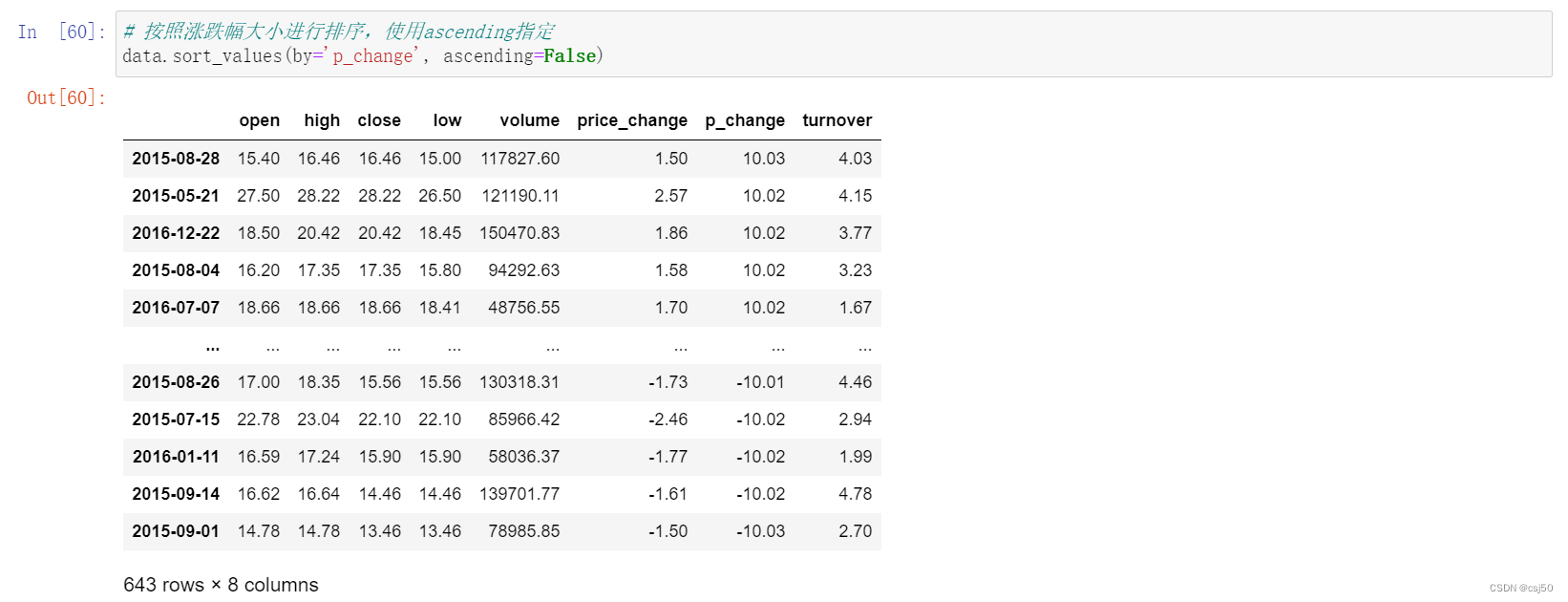
# 按多个字段进行排序
data.sort_values(by=['high','p_change'], ascending=False)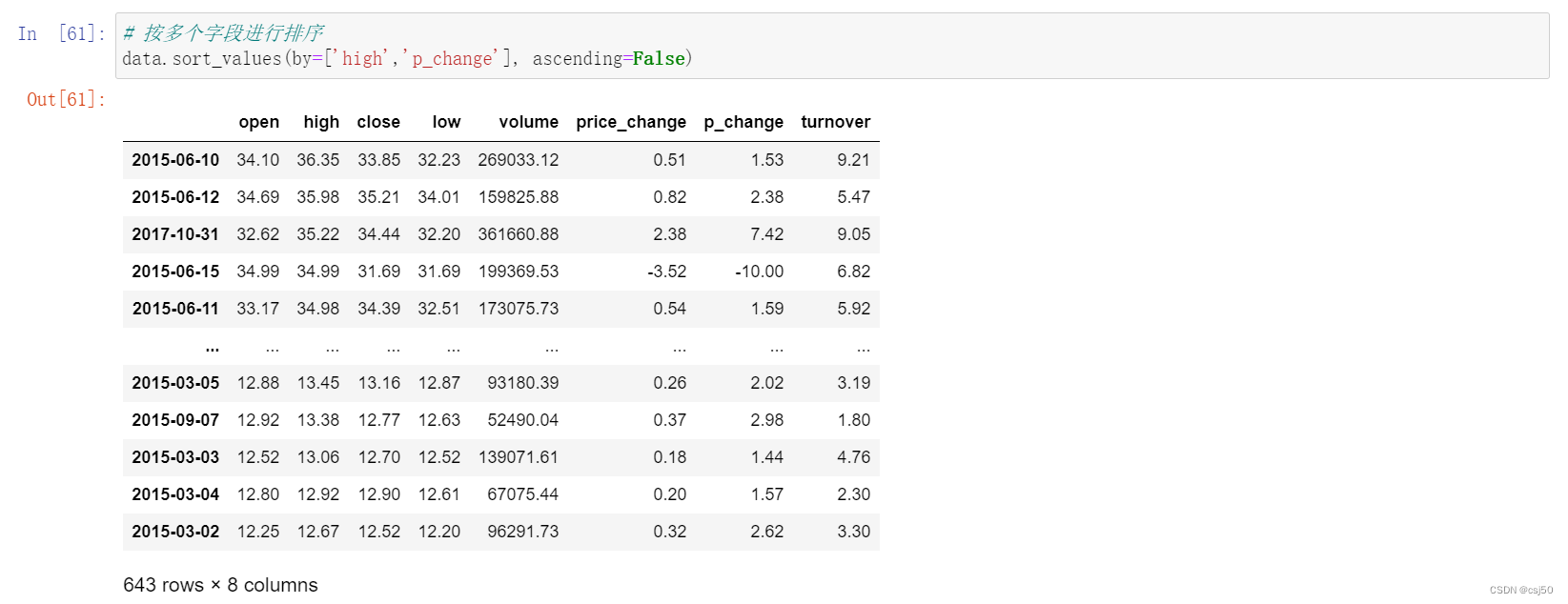
sort_index()
对索引进行排序
# 对索引进行排序
data.sort_index()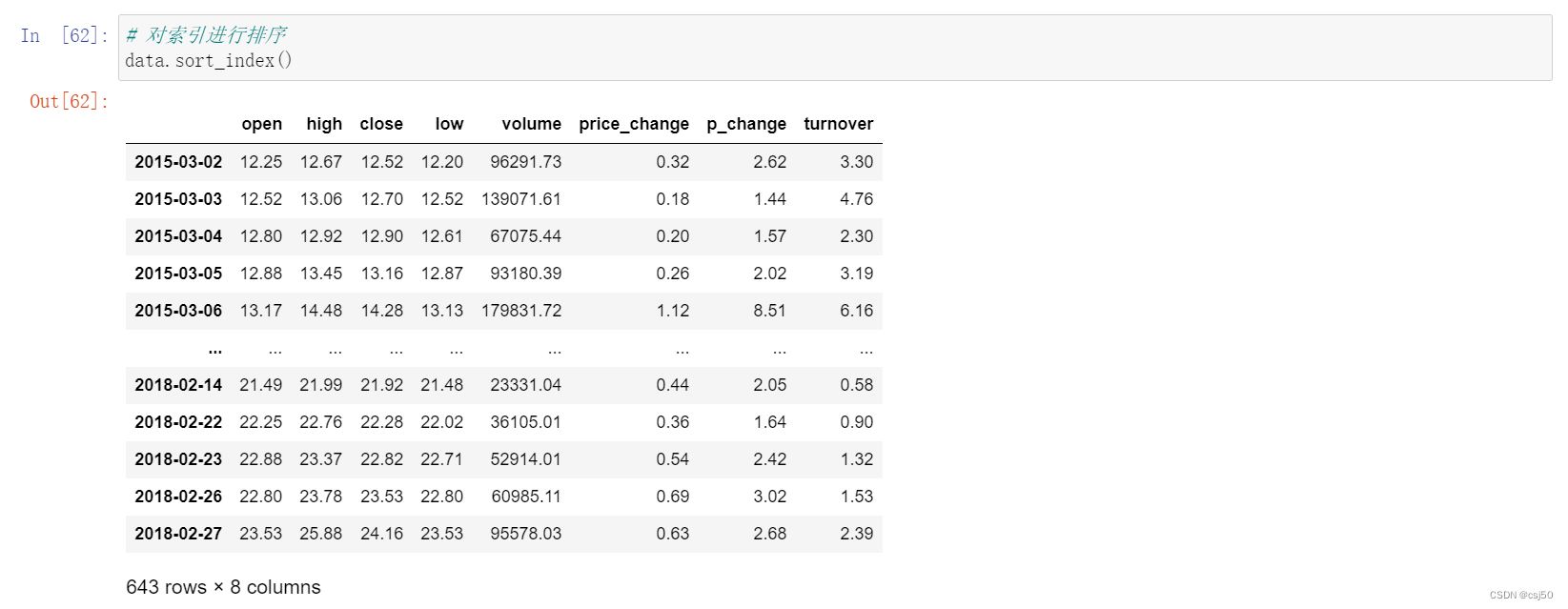
3、Series
sort_values(ascending=)
对内容进行排序
sort_index()
对索引进行排序
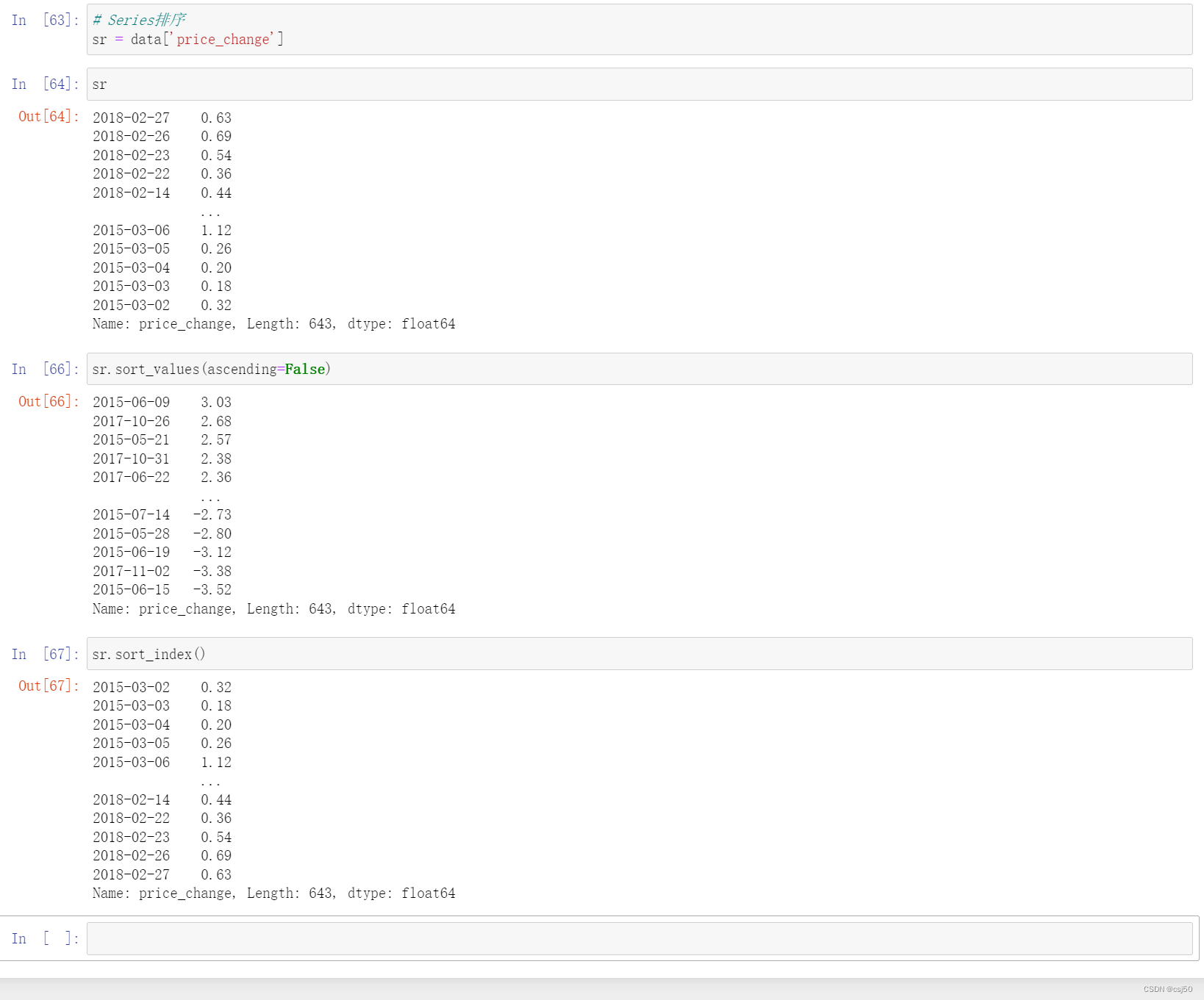
# Series排序
sr = data['price_change']
sr
sr.sort_values(ascending=False)
sr.sort_index()