YOLO-World: Real-Time Open-Vocabulary Object Detection
文章目录
- 1. Introduction
- 2. Experiments
- 2.1 Implementation Details
- 2.2 Pre-training
- 2.3 Ablation Experiments
- 2.3.1 预训练数据
- 2.3.2 对RepVL-PAN的消融研究
- 2.3.3 文本编码器
- 2.4 Fine-tuning YOLO-World
- 2.5 Open-Vocabulary Instance Segmentation
- 2.6 Visualizations
- Reference

YOLO系列检测器已将自己确立为高效实用的工具。然而,它们依赖于预定义和训练的物体类别,这在开放场景中限制了它们的适用性。针对这一限制,作者引入了YOLO-World,这是一种创新的方法,通过视觉语言建模和在大型数据集上的预训练,将YOLO与开集检测能力相结合。具体来说,作者提出了一种新的可重参化的视觉语言路径聚合网络(RepVL-PAN)和区域文本对比损失,以促进视觉和语言信息之间的交互。作者的方法在以零样本方式检测广泛范围的物体时表现出色,且效率高。
在具有挑战性的LVIS数据集上,YOLO-World在V100上实现了35.4 AP和52.0 FPS,在准确性和速度上都超过了许多最先进的方法。此外,经过微调的YOLO-World在包括目标检测和开集实例分割在内的几个下游任务上取得了显著性能。
论文链接:https://arxiv.org/abs/2401.17270
代码链接:https://github.com/AILab-CVC/YOLO-World
1. Introduction
作者的主要贡献可以概括为三个方面:
-
作者介绍了YOLO-World,这是一个前沿的开集目标检测器,它具有高效率,适用于实际应用场景。
-
作者提出了一个可重新参数化的视觉-语言PAN模型,用以连接视觉和语言特征,并针对YOLO-World设计了一套开集区域文本对比预训练方案。
-
YOLO-World在大规模数据集上的预训练展示了强大的零样本性能,在LVIS上达到35.4 AP的同时,还能保持52.0 FPS的速度。预训练的YOLO-World可以轻松适应下游任务,例如,开集实例分割和指代目标检测。此外,YOLO-World的预训练权重和代码将开源,以促进更多实际应用。
2. Experiments
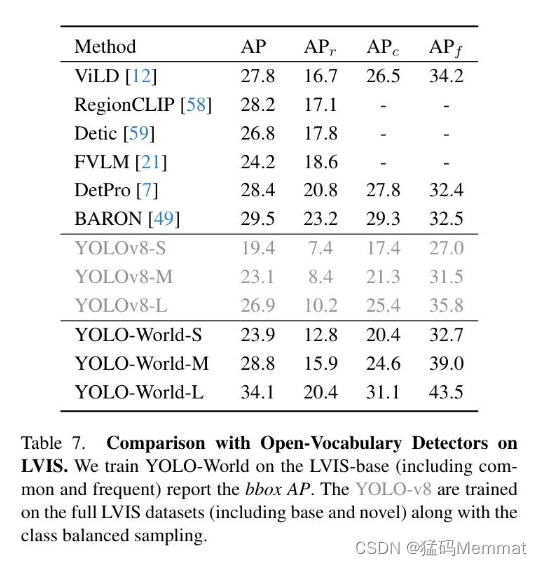
在本节中,作者通过在大规模数据集上对所提出的YOLO-World进行预训练,展示了其有效性,并以零样本方式在LVIS基准和COCO基准上评估了YOLO-World(第4.2节)。作者还评估了YOLO-World在COCO、LVIS数据集上进行目标检测的微调性能。
2.1 Implementation Details
YOLO-World是基于MMYOLO工具箱和MMDetection工具箱开发的。遵循,作者为不同的延迟需求提供了YOLO-World的三个变体,例如小型(S)、中型(M)和大型(L)。作者采用了开源的CLIP文本编码器及其预训练权重来编码输入文本。除非特别指明,作者将所有模型的推理速度测量在单个NVIDIA V100 GPU上,且不使用额外的加速机制,例如FP16或TensorRT。
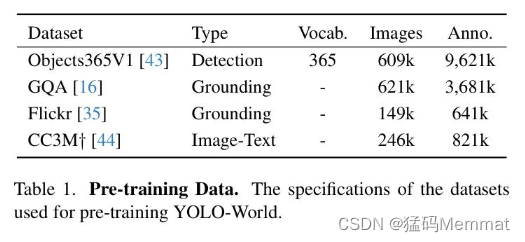
2.2 Pre-training
实验设置。在预训练阶段,作者采用了AdamW优化器,初始学习率为0.002,权重衰减为0.05。YOLO-World在32个NVIDIA V100 GPU上以总批处理大小512进行预训练,共100个周期。在预训练期间,作者遵循之前的工作,采用了颜色增强、随机仿射变换、随机翻转以及包含4张图片的马赛克数据进行数据增强。在预训练期间,文本编码器被冻结。
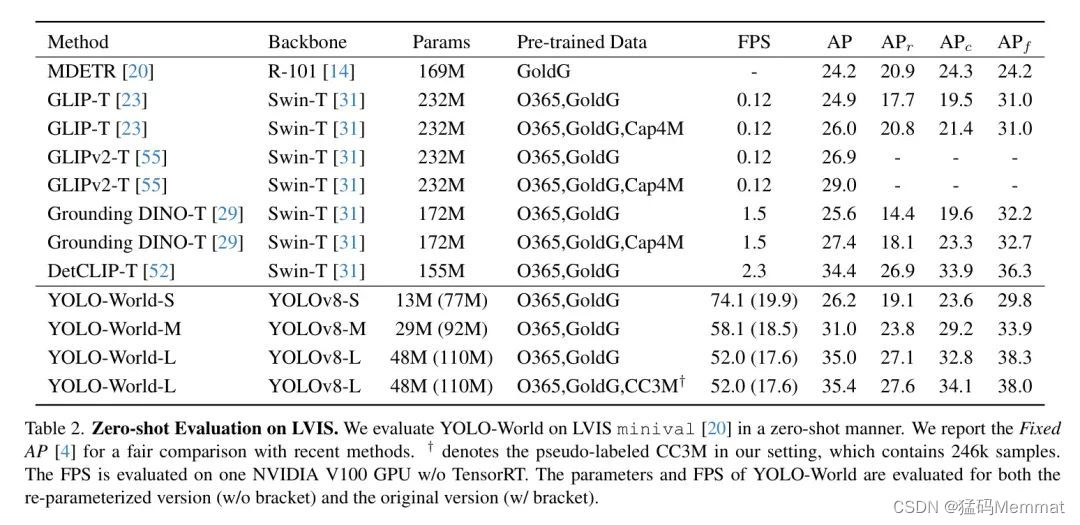
2.3 Ablation Experiments
作者提供了广泛的消融研究,从两个主要方面分析YOLO-World,即预训练和架构。除非另有指定,作者主要基于YOLO-World-L进行消融实验,并使用零样本评估在LVIS minival上预训练Objects365。
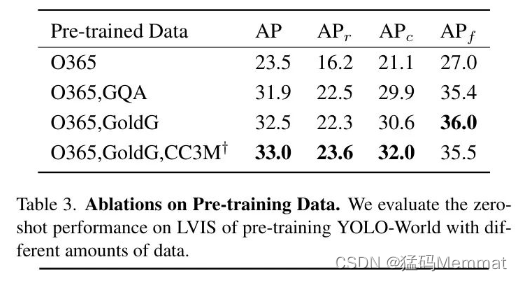
2.3.1 预训练数据
2.3.2 对RepVL-PAN的消融研究
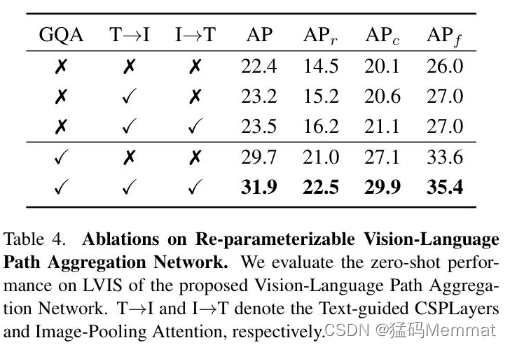
表4展示了所提出的YOLO-World中的RepVL-PAN对于零样本LVIS检测的有效性,包括文本引导的CSPLayers和图像池化注意力。
2.3.3 文本编码器
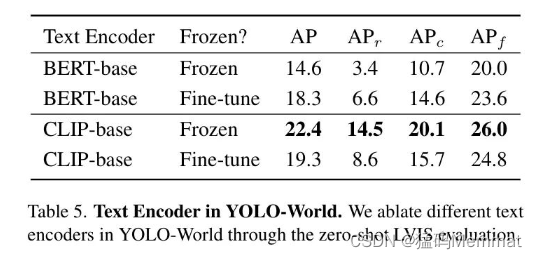
2.4 Fine-tuning YOLO-World
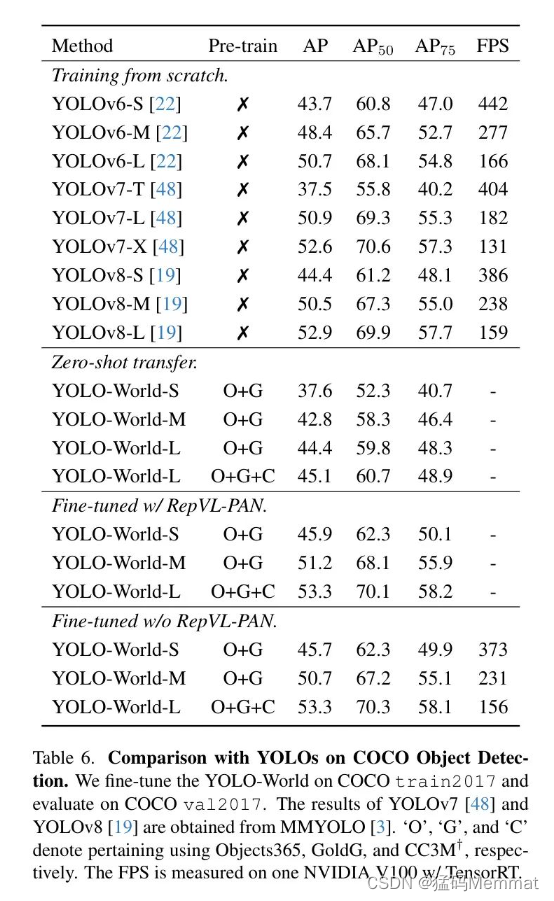
在本节中,作者进一步对YOLO-World进行微调,以在COCO数据集和LVIS数据集上进行闭集目标检测,以展示预训练的有效性。
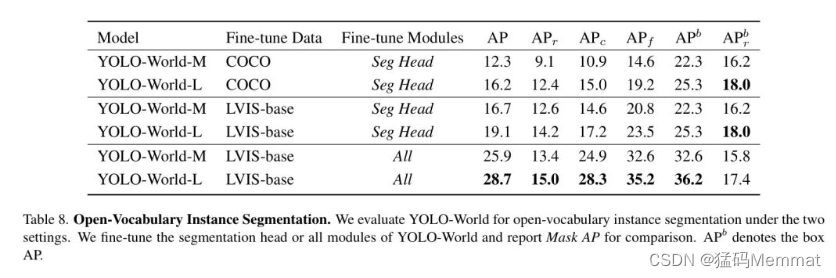
2.5 Open-Vocabulary Instance Segmentation
2.6 Visualizations



Reference
论文链接:https://arxiv.org/abs/2401.17270
代码链接:https://github.com/AILab-CVC/YOLO-World
https://mp.weixin.qq.com/s/Fj6wzARTo1l7UEwKxDAh6w
https://mp.weixin.qq.com/s/Mt1Tyo0zj3MZ-LR4HLjtnQ