彻底学会系列:一、机器学习之线性回归(一)
1.基本概念(basic concept)
线性回归: 有监督学习的一种算法。主要关注多个因变量和一个目标变量之间的关系。
因变量: 影响目标变量的因素:
X
1
,
X
2
.
.
.
X_1, X_2...
X1,X2... ,连续值或离散值。
目标变量: 需要预测的值:
t
a
r
g
e
t
target
target,
y
y
y
因变量和目标变量之间的关系: 即模型,model
1.1连续值(continuous value)
连续值是可以在一个区间范围内取任意值的变量。例如,身高、体重、温度、时间等都是连续值

1.2离散值(discrete value)
离散值是只能取有限个数值或者可数值的变量。例如,学生人数、家庭成员数、考试分数等都是离散值

1.3简单线性回归(simple linear regression)
简单线性回归对应的公式:
y
=
w
x
+
b
y = wx + b
y=wx+b
y
y
y 是目标变量即未来要预测的值
x
x
x 是影响
y
y
y 的因素
w
,
b
w,b
w,b 是公式上的参数即要求的模型,
w
w
w就是斜率,
b
b
b就是截距
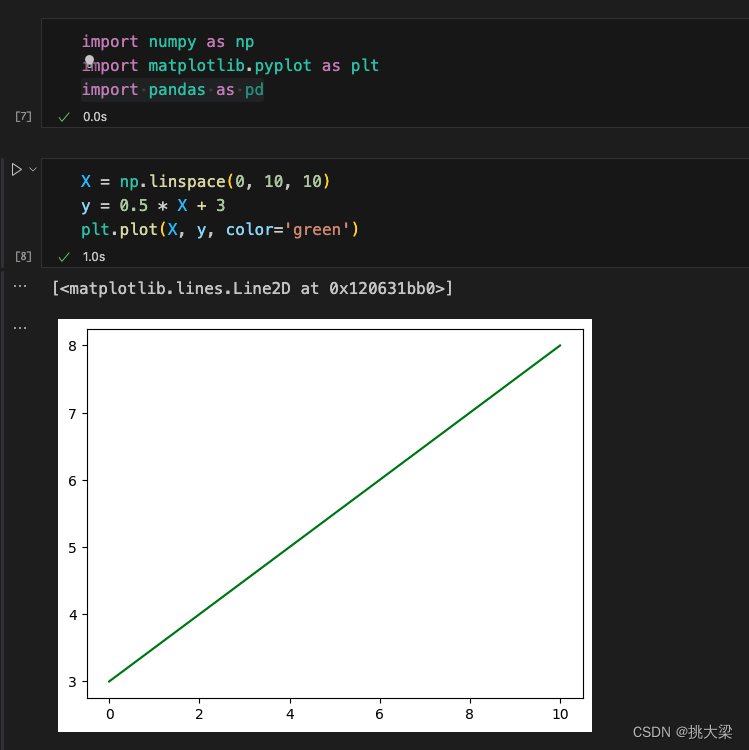
一元一次方程:
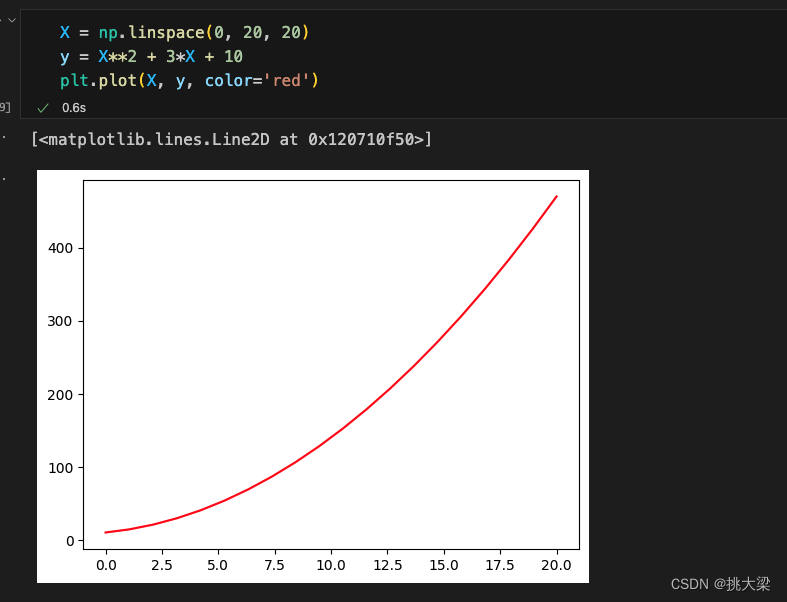
一元二次方程:
1.4多元线性回归(multiple linear regression)
现实生活中,往往影响结果 y 的因素不止一个,有可能是 n 个,
X
1
,
X
2
,
X
n
.
.
.
X_1,X_2,X_n...
X1,X2,Xn...
多元线性回归公式:
y ^ = w 1 X 1 + w 2 X 2 . . . w n X n + b \hat y = w_1X_1 + w_2X_2 ... w_nX_n + b y^=w1X1+w2X2...wnXn+b
b是截距,也可以表示成:
y ^ = w 1 X 1 + w 2 X 2 . . . w n X n + w 0 \hat y = w_1X_1 + w_2X_2 ... w_nX_n + w_0 y^=w1X1+w2X2...wnXn+w0
使用向量来表示:
y ^ = W T X \hat y = W^TX y^=WTX
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 转化矩阵
x1 = np.random.randint(-150, 150, size=(300, 1))
x2 = np.random.randint(0, 300, size=(300, 1))
# 斜率和截距,随机生成
w = np.random.randint(1, 5, size=2)
b = np.random.randint(1, 10, size=1)
# 根据二元一次方程计算目标值y,并加上"噪声"
y = x1 * w[0] + x2 * w[1] + b + np.random.randn(300, 1)
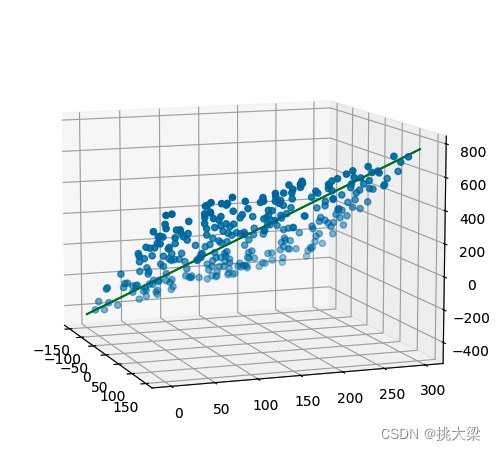
fig = plt.figure(figsize=(9, 6))
ax = plt.subplot(111, projection='3d')
ax.scatter(x1, x2, y) # 三维散点图
ax.view_init(elev=10, azim=-20) # 调整视角
#
X = np.concatenate([x1, x2], axis=1)
model = LinearRegression()
model.fit(X, y)
w_ = model.coef_.reshape(-1)
b_ = model.intercept_
print('一元一次方程真实的斜率和截距是:\n', w, b)
print('通过scikit-learn求解的斜率和截距是:\n', w_, b_)
x = np.linspace(-150, 150, 100)
y = np.linspace(0, 300, 100)
z = x * w_[0] + y * w_[1] + b_
ax.plot(x, y, z, color='green')
plt.show()
1.5 最优解(optimal solution)
y
y
y: 真实值(actual value)
y
^
\hat y
y^: 预测值(predicted value), 根据因变量
X
1
,
X
2
.
.
.
X_1,X_2...
X1,X2...和计算出来的参数w,b得到
e
r
r
o
r
error
error: 误差,预测值和真实值的差距(
ε
\varepsilon
ε)
最优解: 尽可能的找到一个模型使得整体的误差最小,通常叫做损失 Loss,通过损失函数Loss Function计算得到。
from sklearn.linear_model import LinearRegression
X = np.linspace(0, 10, num=30).reshape(-1, 1)
w = np.random.randint(1, 5, size=1)
b = np.random.randint(1, 10, size=1)
y = X * w + b + np.random.randn(30, 1)
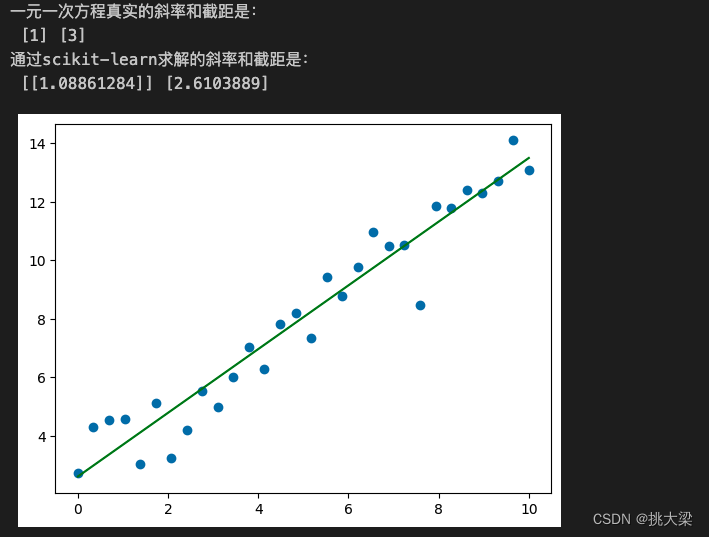
plt.scatter(X, y)
model = LinearRegression()
model.fit(X, y)
w_ = model.coef_
b_ = model.intercept_
print('一元一次方程真实的斜率和截距是:\n', w, b)
print('通过scikit-learn求解的斜率和截距是:\n', w_, b_)
plt.plot(X, X.dot(w_) + b_, color='green')
plt.show()
1.6 高斯密度函数 (Gaussian Density Function):
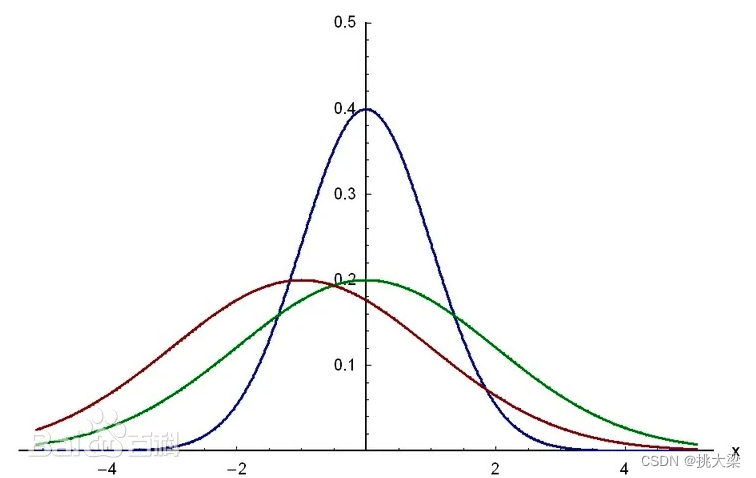
高斯密度函数(Gaussian Density Function)也被称为正态分布或钟形曲线,是统计学中最常用的概率分布之一。其概率密度函数(Probability Density Function, PDF)的表达式如下:
f ( x ; μ , σ 2 ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) \ f(x; \mu, \sigma^2) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) f(x;μ,σ2)=2πσ1exp(−2σ2(x−μ)2)
其中,(x) 是变量, μ \mu μ 是均值, σ 2 \sigma^2 σ2是方差。
- μ \mu μ 表示分布的均值,决定了曲线的中心位置。
- σ 2 \sigma^2 σ2 是方差,决定了曲线的宽度或分布的离散程度。标准差 σ \sigma σ是方差的平方根。
高斯密度函数的特征包括:
-
钟形曲线形状: 高斯分布呈现出典型的钟形曲线,对称分布在均值周围。
-
68-95-99.7 规则: 大约68% 的数据在均值的一个标准差范围内,95% 在两个标准差范围内,99.7% 在三个标准差范围内。
-
均值和方差唯一决定分布: 高斯分布的均值和方差是唯一确定整个分布的两个参数。
1.8 最大似然估计(Maximum Likelihood Estimation)
是一种用于估计模型参数的统计方法。它基于概率论的观点,寻找使观测数据出现的概率最大的参数值。通常记为 L ( θ ∣ d a t a ) L(θ∣data) L(θ∣data),其中 θ 是待估计的参数,为了方便计算,通常取似然函数的对数,得到对数似然函数(Log-Likelihood),记为 ℓ ( θ ∣ data ) \ell(\theta | \text{data}) ℓ(θ∣data)
公式:
Likelihood Function:
L
(
θ
∣
data
)
=
∏
i
=
1
n
P
(
X
i
;
θ
)
\text{Likelihood Function: } L(\theta | \text{data}) = \prod_{i=1}^{n} P(X_i; \theta)
Likelihood Function: L(θ∣data)=∏i=1nP(Xi;θ)
Log-Likelihood Function:
ℓ
(
θ
∣
data
)
=
∑
i
=
1
n
log
P
(
X
i
;
θ
)
\text{Log-Likelihood Function: } \ell(\theta | \text{data}) = \sum_{i=1}^{n} \log P(X_i; \theta)
Log-Likelihood Function: ℓ(θ∣data)=∑i=1nlogP(Xi;θ)
其中, X i X_i Xi 表示每个观测数据点。
1.7 最小二乘法(Least Squares Method)
是一种用于拟合数据和估计模型参数的优化方法。其核心思想是通过最小化观测数据的残差平方和来找到最优的模型参数。这种方法常用于线性回归和其他模型拟合问题
J
(
θ
)
=
1
2
∑
i
=
1
n
(
h
θ
(
x
i
)
−
y
i
)
2
J(\theta) = \frac{1}{2} \sum_{i=1}^{n} (h_\theta(x_i) - y_i)^2
J(θ)=21∑i=1n(hθ(xi)−yi)2
其中, h θ ( x i ) h_\theta(x_i) hθ(xi) 是模型对样本 x i x_i xi 的预测 y ^ \hat y y^, y i y_i yi 是实际观测值。
1.8正规方程 (Normal Equations)
正规方程是用于求解线性回归模型参数的一种解析方法(解方程的一种方法)
θ = ( X T X ) − 1 X T y \theta = (X^T X)^{-1} X^T y θ=(XTX)−1XTy
其中, ( X T X ) − 1 (X^T X)^{-1} (XTX)−1 是矩阵 X T X X^T X XTX 的逆矩阵, X T X^T XT是 X X X的转置矩阵, y y y 是实际观测值。
1.9均方误差(Mean Squared Error, MSE)
MSE是一个用于衡量模型预测与实际观测值之间的差异的指标。对于线性回归模型,MSE定义如下:
MSE = 1 n ∑ i = 1 n ( h θ ( x i ) − y i ) 2 \text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (h_\theta(x_i) - y_i)^2 MSE=n1∑i=1n(hθ(xi)−yi)2
其中, h θ ( x i ) h_\theta(x_i) hθ(xi) 是模型对第 i 个样本的预测值, y i y_i yi是实际观测值,n 是样本数量。MSE计算的是平方误差的平均值,其值越小,表示模型对数据的拟合程度越好。
总结:
均方误差 (MSE):
- 用于度量模型预测值与实际观测值之间的平方差的平均值。
- 是一种评估模型性能的指标,越小越好。
最小二乘法 (Least Squares Method):
- 是一种用于估计线性回归模型参数的方法。
- 通过最小化均方误差或其他损失函数来找到最优参数。
- 目标是找到参数,使得模型对观测值的预测误差最小。
通俗理解:
MSE是评估模型好不好,预测准不准用的。最小二乘法是求解方程参数
w
1
,
w
2
.
.
.
w_1,w_2...
w1,w2...用的
彻底学会系列:一、机器学习之线性回归(二)