ACK One Argo工作流:实现动态 Fan-out/Fan-in 任务编排
作者:庄宇
什么是 Fan-out Fan-in
在工作流编排过程中,为了加快大任务处理的效率,可以使用 Fan-out Fan-in 任务编排,将大任务分解成小任务,然后并行运行小任务,最后聚合结果。

由上图,可以使用 DAG(有向无环图)编排 Fan-out Fan-in 任务,子任务的拆分方式分为静态和动态,分别对应静态 DAG 和动态 DAG。动态 DAG Fan-out Fan-in 也可以理解为 MapReduce。每个子任务为 Map,最后聚合结果为 Reduce。
静态 DAG: 拆分的子任务分类是固定的,例如:在数据收集场景中,同时收集数据库 1 和数据库 2 中的数据,最后聚合结果。
动态 DAG: 拆分的子任务分类是动态的,取决于前一个任务的输出结果,例如:在数据处理场景中,任务 A 可以扫描待处理的数据集,为每个子数据集(例如:一个子目录)启动子任务 Bn 处理,当所有子任务 Bn 运行结束后,在子任务 C 中聚合结果,具体启动多少个子任务 B 取决由任务 A 的输出结果。根据实际的业务场景,可以在任务 A 中自定义子任务的拆分规则。
ACK One 分布式工作流 Argo 集群
在实际的业务场景中,为了加快大任务的执行,提升效率,往往需要将一个大任务分解成数千个子任务,为了保证数千个子任务的同时运行,需要调度数万核的 CPU 资源,叠加多任务需要竞争资源,一般 IDC 的离线任务集群难以满足需求。例如:自动驾驶仿真任务,修改算法后的回归测试,需要对所有驾驶场景仿真,每个小驾驶场景的仿真可以由一个子任务运行,开发团队为加快迭代速度,要求所有子场景测试并行执行。
如果您在数据处理,仿真计算和科学计算等场景中,需要使用动态 DAG 的方式编排任务,或者同时需要调度数万核的 CPU 资源加快任务运行,您可以使用阿里云 ACK One 分布式工作流 Argo 集群 [ 1] 。
ACK One 分布式工作流 Argo 集群,产品化托管 Argo Workflow [ 2] ,提供售后支持,支持动态 DAG Fan-out Fan-in 任务编排,支持按需调度云上算力,利用云上弹性,调度数万核 CPU 资源并行运行大规模子任务,减少运行时间,运行完成后及时回收资源节省成本。支持数据处理,机器学习,仿真计算,科学计算,CICD 等业务场景。
Argo Workflow 是开源 CNCF 毕业项目,聚焦云原生领域下的工作流编排,使用 Kubernetes CRD 编排离线任务和 DAG 工作流,并使用 Kubernetes Pod 在集群中调度运行。
本文介绍使用 Argo Workflow 编排动态 DAG Fan-out Fan-in 任务。
Argo Workflow 编排 Fan-out Fan-in 任务
我们将构建一个动态 DAG Fan-out Fan-in 工作流,读取阿里云 OSS 对象存储中的一个大日志文件,并将其拆分为多个小文件(split),启动多个子任务分别计算每个小文件中的关键词数量(count),最后聚合结果(merge)。
-
创建分布式工作流 Argo 集群 [ 3] 。
-
挂载阿里云 OSS 存储卷,工作流可以像操作本地文件一样,操作阿里云 OSS 上的文件。参考:工作流使用存储卷 [ 4] 。
-
使用以下工作流 YAML 创建一个工作流,参考:创建工作流 [ 5] 。具体说明参见注释。
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: dynamic-dag-map-reduce-
spec:
entrypoint: main
# claim a OSS PVC, workflow can read/write file in OSS through PVC.
volumes:
- name: workdir
persistentVolumeClaim:
claimName: pvc-oss
# how many tasks to split, default is 5.
arguments:
parameters:
- name: numParts
value: "5"
templates:
- name: main
# DAG definition.
dag:
tasks:
# split log files to several small files, based on numParts.
- name: split
template: split
arguments:
parameters:
- name: numParts
value: "{{workflow.parameters.numParts}}"
# multiple map task to count words in each small file.
- name: map
template: map
arguments:
parameters:
- name: partId
value: '{{item}}'
depends: "split"
# run as a loop, partId from split task json outputs.
withParam: '{{tasks.split.outputs.result}}'
- name: reduce
template: reduce
arguments:
parameters:
- name: numParts
value: "{{workflow.parameters.numParts}}"
depends: "map"
# The `split` task split the big log file to several small files. Each file has a unique ID (partId).
# Finally, it dumps a list of partId to stdout as output parameters
- name: split
inputs:
parameters:
- name: numParts
container:
image: acr-multiple-clusters-registry.cn-hangzhou.cr.aliyuncs.com/ack-multiple-clusters/python-log-count
command: [python]
args: ["split.py"]
env:
- name: NUM_PARTS
value: "{{inputs.parameters.numParts}}"
volumeMounts:
- name: workdir
mountPath: /mnt/vol
# One `map` per partID is started. Finds its own "part file" and processes it.
- name: map
inputs:
parameters:
- name: partId
container:
image: acr-multiple-clusters-registry.cn-hangzhou.cr.aliyuncs.com/ack-multiple-clusters/python-log-count
command: [python]
args: ["count.py"]
env:
- name: PART_ID
value: "{{inputs.parameters.partId}}"
volumeMounts:
- name: workdir
mountPath: /mnt/vol
# The `reduce` task takes the "results directory" and returns a single result.
- name: reduce
inputs:
parameters:
- name: numParts
container:
image: acr-multiple-clusters-registry.cn-hangzhou.cr.aliyuncs.com/ack-multiple-clusters/python-log-count
command: [python]
args: ["merge.py"]
env:
- name: NUM_PARTS
value: "{{inputs.parameters.numParts}}"
volumeMounts:
- name: workdir
mountPath: /mnt/vol
outputs:
artifacts:
- name: result
path: /mnt/vol/result.json
- 动态 DAG 实现
1)split 任务在拆分大文件后,会在标准输出中输出一个 json 字符串,包含:子任务要处理的 partId,例如:
["0", "1", "2", "3", "4"]
2)map 任务使用 withParam 引用 split 任务的输出,并解析 json 字符串获得所有 {{item}},并使用每个 {{item}} 作为输入参数启动多个 map 任务。
- name: map
template: map
arguments:
parameters:
- name: partId
value: '{{item}}'
depends: "split"
withParam: '{{tasks.split.outputs.result}}'
更多定义方式,请参考开源 Argo Workflow 文档 [ 6] 。
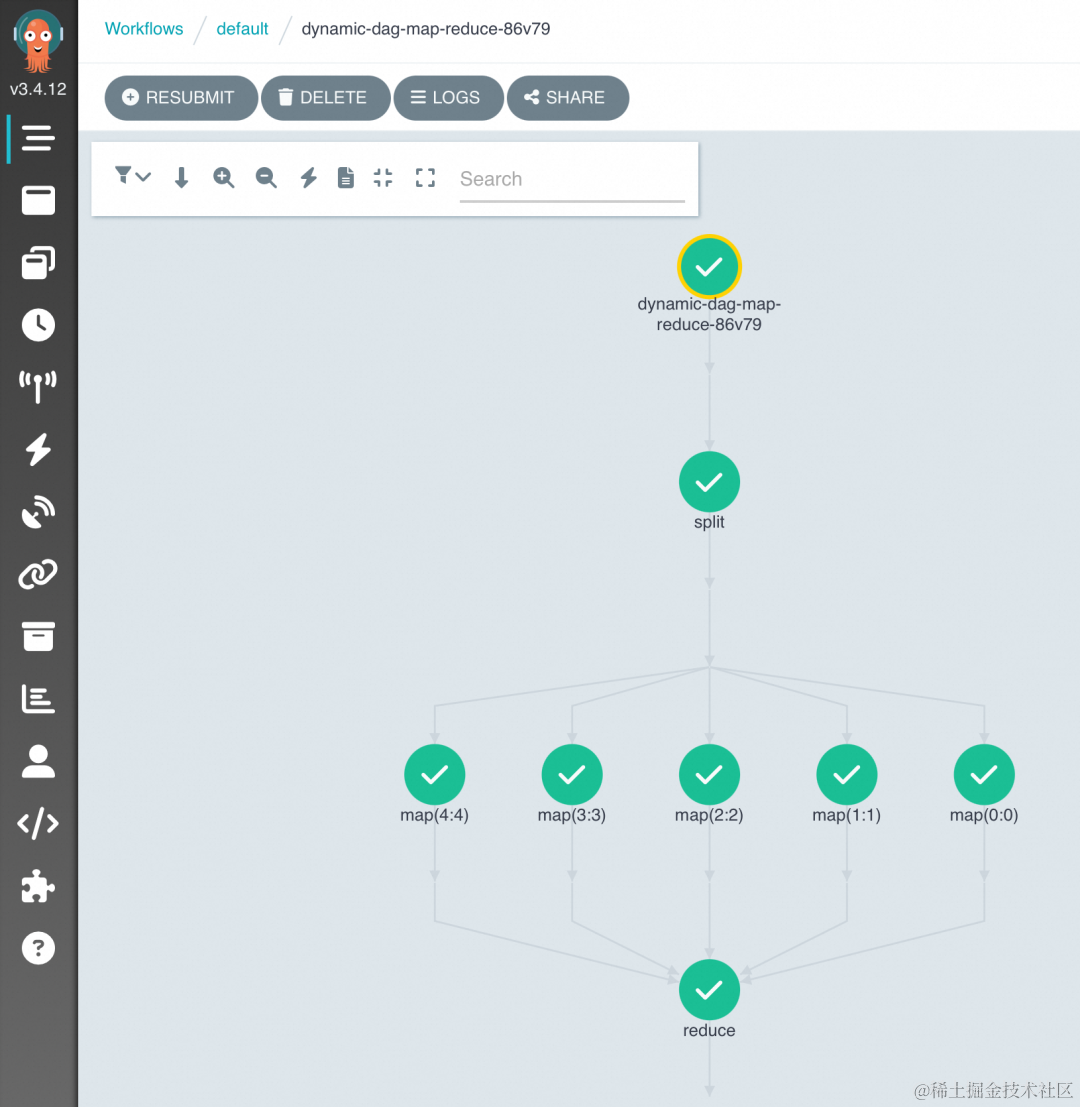
- 工作流运行后,通过分布式工作流 Argo 集群控制台 [ 7] 查看任务 DAG 流程与运行结果。
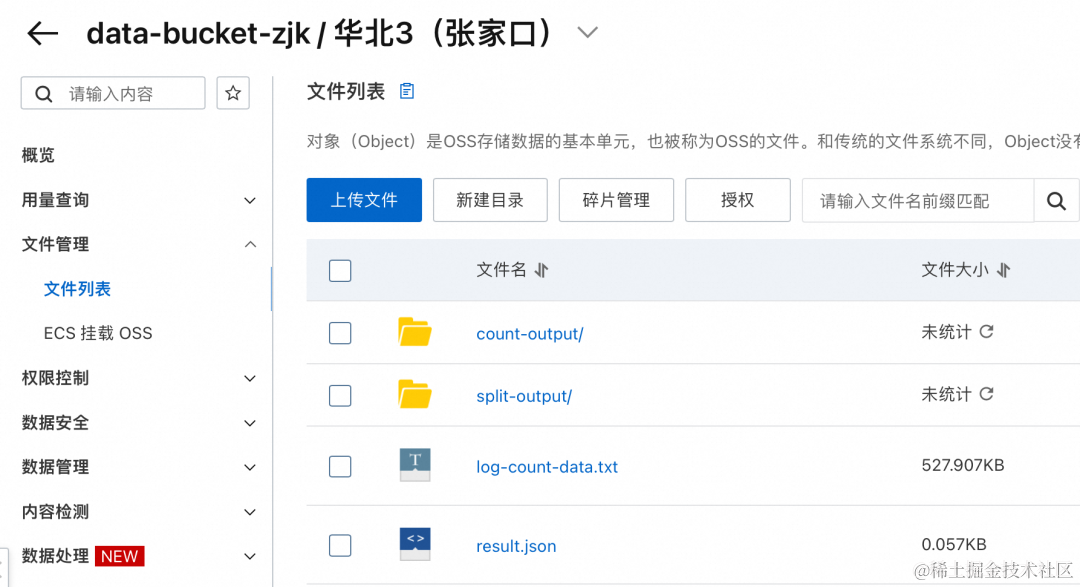
- 阿里云 OSS 文件列表,log-count-data.txt 为输入日志文件,split-output,cout-output 中间结果目录,result.json 为最终结果文件。
- 示例中的源代码可以参考:AliyunContainerService GitHub argo-workflow-examples [ 8] 。
总结
Argo Workflow 是开源 CNCF 毕业项目,聚焦云原生领域下的工作流编排,使用 Kubernetes CRD 编排离线任务和 DAG 工作流,并使用 Kubernetes Pod 在集群中调度运行。
阿里云 ACK One 分布式工作流 Argo 集群,产品化托管 Argo Workflow,提供售后支持,加固控制面实现数万子任务(Pod)稳定高效调度运行,数据面支持无服务器方式调度云上大规模算力,无需运维集群或者节点,支持按需调度云上算力,利用云上弹性,调度数万核 CPU 资源并行运行大规模子任务,减少运行时间,支持数据处理,机器学习,仿真计算,科学计算,CICD 等业务场景。
欢迎加入 ACK One 客户交流钉钉群与我们进行交流。(钉钉群号:35688562)
相关链接:
[1] 阿里云 ACK One 分布式工作流 Argo 集群
https://help.aliyun.com/zh/ack/overview-12
[2] Argo Workflow
https://argo-workflows.readthedocs.io/en/latest/
[3] 创建分布式工作流 Argo 集群
https://help.aliyun.com/zh/ack/create-a-workflow-cluster
[4] 工作流使用存储卷
https://help.aliyun.com/zh/ack/use-volumes
[5] 创建工作流
https://help.aliyun.com/zh/ack/create-a-workflow
[6] 开源 Argo Workflow 文档
https://argo-workflows.readthedocs.io/en/latest/walk-through/loops/
[7] 分布式工作流 Argo 集群控制台
https://account.aliyun.com/login/login.htm?oauth_callback=https%3A%2F%2Fcs.console.aliyun.com%2Fone%3Fspm%3Da2c4g.11186623.0.0.7e2f1428OwzMip#/argowf/cluster/detail
[8] AliyunContainerService GitHub argo-workflow-examples
https://github.com/AliyunContainerService/argo-workflow-examples/tree/main/log-count