(四)elasticsearch 源码之索引流程分析
https://www.cnblogs.com/darcy-yuan/p/17024341.html
1.概览
前面我们讨论了es是如何启动,本文研究下es是如何索引文档的。
下面是启动流程图,我们按照流程图的顺序依次描述。
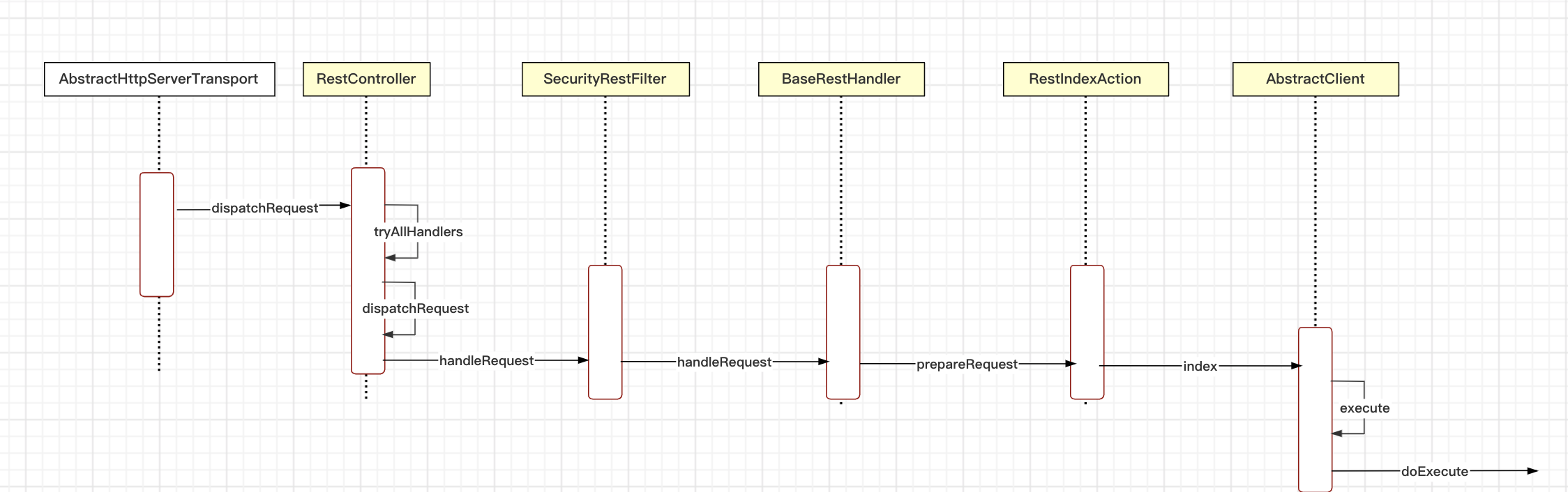


其中主要类的关系如下:

2. 索引流程 (primary)
我们用postman发送请求,创建一个文档
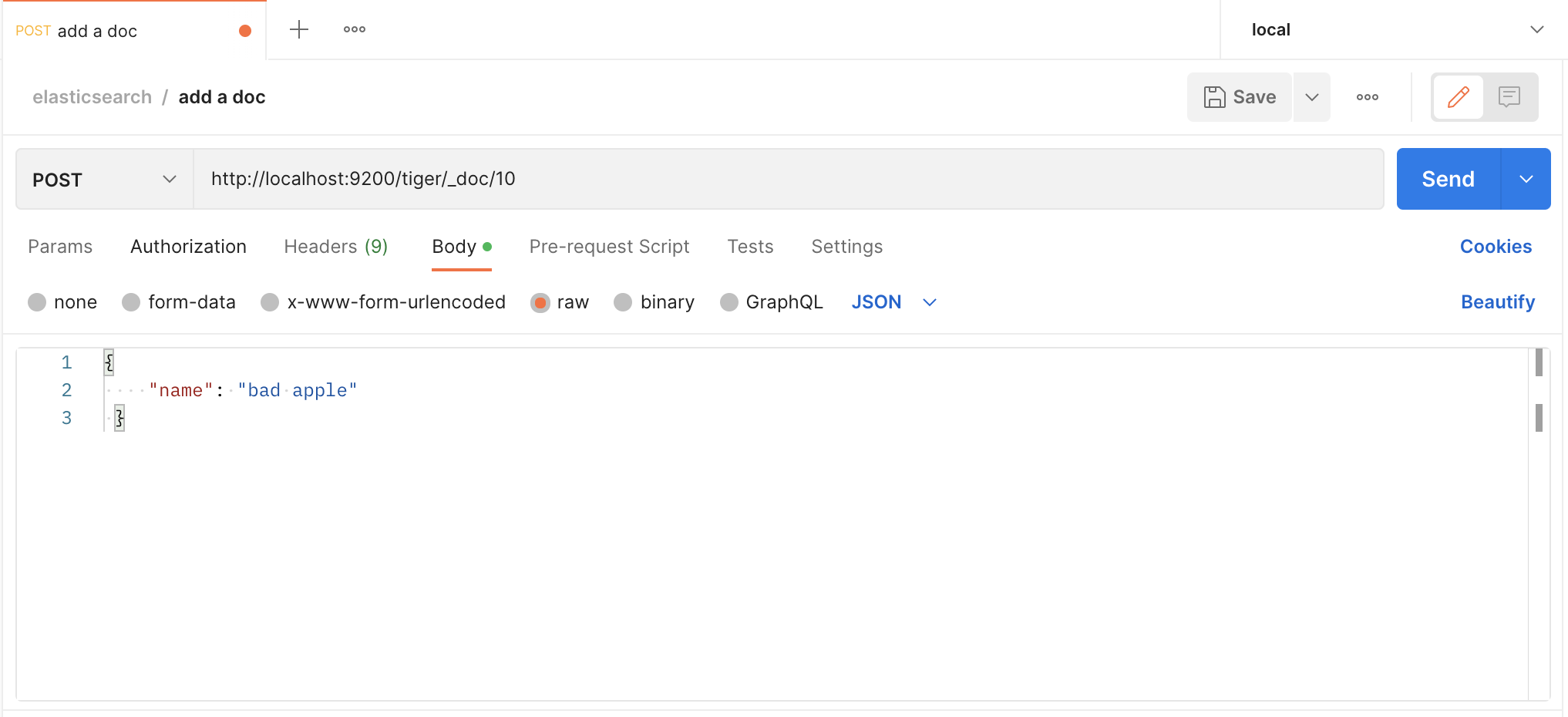
我们发送的是http请求,es也有一套http请求处理逻辑,和spring的mvc类似
// org.elasticsearch.rest.RestController
private void dispatchRequest(RestRequest request, RestChannel channel, RestHandler handler) throws Exception {
final int contentLength = request.content().length();
if (contentLength > 0) {
final XContentType xContentType = request.getXContentType(); // 校验content-type
if (xContentType == null) {
sendContentTypeErrorMessage(request.getAllHeaderValues("Content-Type"), channel);
return;
}
if (handler.supportsContentStream() && xContentType != XContentType.JSON && xContentType != XContentType.SMILE) {
channel.sendResponse(BytesRestResponse.createSimpleErrorResponse(channel, RestStatus.NOT_ACCEPTABLE,
"Content-Type [" + xContentType + "] does not support stream parsing. Use JSON or SMILE instead"));
return;
}
}
RestChannel responseChannel = channel;
try {
if (handler.canTripCircuitBreaker()) {
inFlightRequestsBreaker(circuitBreakerService).addEstimateBytesAndMaybeBreak(contentLength, "<http_request>");
} else {
inFlightRequestsBreaker(circuitBreakerService).addWithoutBreaking(contentLength);
}
// iff we could reserve bytes for the request we need to send the response also over this channel
responseChannel = new ResourceHandlingHttpChannel(channel, circuitBreakerService, contentLength);
handler.handleRequest(request, responseChannel, client);
} catch (Exception e) {
responseChannel.sendResponse(new BytesRestResponse(responseChannel, e));
}
}// org.elasticsearch.rest.BaseRestHandler
@Override
public final void handleRequest(RestRequest request, RestChannel channel, NodeClient client) throws Exception {
// prepare the request for execution; has the side effect of touching the request parameters
final RestChannelConsumer action = prepareRequest(request, client);
// validate unconsumed params, but we must exclude params used to format the response
// use a sorted set so the unconsumed parameters appear in a reliable sorted order
final SortedSet<String> unconsumedParams =
request.unconsumedParams().stream().filter(p -> !responseParams().contains(p)).collect(Collectors.toCollection(TreeSet::new));
// validate the non-response params
if (!unconsumedParams.isEmpty()) {
final Set<String> candidateParams = new HashSet<>();
candidateParams.addAll(request.consumedParams());
candidateParams.addAll(responseParams());
throw new IllegalArgumentException(unrecognized(request, unconsumedParams, candidateParams, "parameter"));
}
if (request.hasContent() && request.isContentConsumed() == false) {
throw new IllegalArgumentException("request [" + request.method() + " " + request.path() + "] does not support having a body");
}
usageCount.increment();
// execute the action
action.accept(channel); // 执行action
}// org.elasticsearch.rest.action.document.RestIndexAction
public RestChannelConsumer prepareRequest(final RestRequest request, final NodeClient client) throws IOException {
IndexRequest indexRequest;
final String type = request.param("type");
if (type != null && type.equals(MapperService.SINGLE_MAPPING_NAME) == false) {
deprecationLogger.deprecatedAndMaybeLog("index_with_types", TYPES_DEPRECATION_MESSAGE); // type 已经废弃
indexRequest = new IndexRequest(request.param("index"), type, request.param("id"));
} else {
indexRequest = new IndexRequest(request.param("index"));
indexRequest.id(request.param("id"));
}
indexRequest.routing(request.param("routing"));
indexRequest.setPipeline(request.param("pipeline"));
indexRequest.source(request.requiredContent(), request.getXContentType());
indexRequest.timeout(request.paramAsTime("timeout", IndexRequest.DEFAULT_TIMEOUT));
indexRequest.setRefreshPolicy(request.param("refresh"));
indexRequest.version(RestActions.parseVersion(request));
indexRequest.versionType(VersionType.fromString(request.param("version_type"), indexRequest.versionType()));
indexRequest.setIfSeqNo(request.paramAsLong("if_seq_no", indexRequest.ifSeqNo()));
indexRequest.setIfPrimaryTerm(request.paramAsLong("if_primary_term", indexRequest.ifPrimaryTerm()));
String sOpType = request.param("op_type");
String waitForActiveShards = request.param("wait_for_active_shards");
if (waitForActiveShards != null) {
indexRequest.waitForActiveShards(ActiveShardCount.parseString(waitForActiveShards));
}
if (sOpType != null) {
indexRequest.opType(sOpType);
}
return channel ->
client.index(indexRequest, new RestStatusToXContentListener<>(channel, r -> r.getLocation(indexRequest.routing()))); // 执行index操作的consumer
}然后我们来看index操作具体是怎么处理的,主要由TransportAction管理
// org.elasticsearch.action.support.TransportAction
public final Task execute(Request request, ActionListener<Response> listener) {
/*
* While this version of execute could delegate to the TaskListener
* version of execute that'd add yet another layer of wrapping on the
* listener and prevent us from using the listener bare if there isn't a
* task. That just seems like too many objects. Thus the two versions of
* this method.
*/
Task task = taskManager.register("transport", actionName, request); // 注册任务管理器,call -> task
execute(task, request, new ActionListener<Response>() { // ActionListener 封装
@Override
public void onResponse(Response response) {
try {
taskManager.unregister(task);
} finally {
listener.onResponse(response);
}
}
@Override
public void onFailure(Exception e) {
try {
taskManager.unregister(task);
} finally {
listener.onFailure(e);
}
}
});
return task;
}
...
public final void execute(Task task, Request request, ActionListener<Response> listener) {
ActionRequestValidationException validationException = request.validate();
if (validationException != null) {
listener.onFailure(validationException);
return;
}
if (task != null && request.getShouldStoreResult()) {
listener = new TaskResultStoringActionListener<>(taskManager, task, listener);
}
RequestFilterChain<Request, Response> requestFilterChain = new RequestFilterChain<>(this, logger); // 链式处理
requestFilterChain.proceed(task, actionName, request, listener);
}
...
public void proceed(Task task, String actionName, Request request, ActionListener<Response> listener) {
int i = index.getAndIncrement();
try {
if (i < this.action.filters.length) {
this.action.filters[i].apply(task, actionName, request, listener, this); // 先处理过滤器
} else if (i == this.action.filters.length) {
this.action.doExecute(task, request, listener); // 执行action操作
} else {
listener.onFailure(new IllegalStateException("proceed was called too many times"));
}
} catch(Exception e) {
logger.trace("Error during transport action execution.", e);
listener.onFailure(e);
}
}实际上是TransportBulkAction执行具体操作
// org.elasticsearch.action.bulk.TransportBulkAction
protected void doExecute(Task task, BulkRequest bulkRequest, ActionListener<BulkResponse> listener) {
final long startTime = relativeTime();
final AtomicArray<BulkItemResponse> responses = new AtomicArray<>(bulkRequest.requests.size());
boolean hasIndexRequestsWithPipelines = false;
final MetaData metaData = clusterService.state().getMetaData();
ImmutableOpenMap<String, IndexMetaData> indicesMetaData = metaData.indices();
for (DocWriteRequest<?> actionRequest : bulkRequest.requests) {
IndexRequest indexRequest = getIndexWriteRequest(actionRequest);
if (indexRequest != null) {
// get pipeline from request
String pipeline = indexRequest.getPipeline();
if (pipeline == null) { // 不是管道
// start to look for default pipeline via settings found in the index meta data
IndexMetaData indexMetaData = indicesMetaData.get(actionRequest.index());
// check the alias for the index request (this is how normal index requests are modeled)
if (indexMetaData == null && indexRequest.index() != null) {
AliasOrIndex indexOrAlias = metaData.getAliasAndIndexLookup().get(indexRequest.index()); // 使用别名
if (indexOrAlias != null && indexOrAlias.isAlias()) {
AliasOrIndex.Alias alias = (AliasOrIndex.Alias) indexOrAlias;
indexMetaData = alias.getWriteIndex();
}
}
// check the alias for the action request (this is how upserts are modeled)
if (indexMetaData == null && actionRequest.index() != null) {
AliasOrIndex indexOrAlias = metaData.getAliasAndIndexLookup().get(actionRequest.index());
if (indexOrAlias != null && indexOrAlias.isAlias()) {
AliasOrIndex.Alias alias = (AliasOrIndex.Alias) indexOrAlias;
indexMetaData = alias.getWriteIndex();
}
}
if (indexMetaData != null) {
// Find the default pipeline if one is defined from and existing index.
String defaultPipeline = IndexSettings.DEFAULT_PIPELINE.get(indexMetaData.getSettings());
indexRequest.setPipeline(defaultPipeline);
if (IngestService.NOOP_PIPELINE_NAME.equals(defaultPipeline) == false) {
hasIndexRequestsWithPipelines = true;
}
} else if (indexRequest.index() != null) {
// No index exists yet (and is valid request), so matching index templates to look for a default pipeline
List<IndexTemplateMetaData> templates = MetaDataIndexTemplateService.findTemplates(metaData, indexRequest.index());
assert (templates != null);
String defaultPipeline = IngestService.NOOP_PIPELINE_NAME;
// order of templates are highest order first, break if we find a default_pipeline
for (IndexTemplateMetaData template : templates) {
final Settings settings = template.settings();
if (IndexSettings.DEFAULT_PIPELINE.exists(settings)) {
defaultPipeline = IndexSettings.DEFAULT_PIPELINE.get(settings);
break;
}
}
indexRequest.setPipeline(defaultPipeline);
if (IngestService.NOOP_PIPELINE_NAME.equals(defaultPipeline) == false) {
hasIndexRequestsWithPipelines = true;
}
}
} else if (IngestService.NOOP_PIPELINE_NAME.equals(pipeline) == false) {
hasIndexRequestsWithPipelines = true;
}
}
}
if (hasIndexRequestsWithPipelines) {
// this method (doExecute) will be called again, but with the bulk requests updated from the ingest node processing but
// also with IngestService.NOOP_PIPELINE_NAME on each request. This ensures that this on the second time through this method,
// this path is never taken.
try {
if (clusterService.localNode().isIngestNode()) {
processBulkIndexIngestRequest(task, bulkRequest, listener);
} else {
ingestForwarder.forwardIngestRequest(BulkAction.INSTANCE, bulkRequest, listener);
}
} catch (Exception e) {
listener.onFailure(e);
}
return;
}
if (needToCheck()) { // 根据批量请求自动创建索引,方便后续写入数据
// Attempt to create all the indices that we're going to need during the bulk before we start.
// Step 1: collect all the indices in the request
final Set<String> indices = bulkRequest.requests.stream()
// delete requests should not attempt to create the index (if the index does not
// exists), unless an external versioning is used
.filter(request -> request.opType() != DocWriteRequest.OpType.DELETE
|| request.versionType() == VersionType.EXTERNAL
|| request.versionType() == VersionType.EXTERNAL_GTE)
.map(DocWriteRequest::index)
.collect(Collectors.toSet());
/* Step 2: filter that to indices that don't exist and we can create. At the same time build a map of indices we can't create
* that we'll use when we try to run the requests. */
final Map<String, IndexNotFoundException> indicesThatCannotBeCreated = new HashMap<>();
Set<String> autoCreateIndices = new HashSet<>();
ClusterState state = clusterService.state();
for (String index : indices) {
boolean shouldAutoCreate;
try {
shouldAutoCreate = shouldAutoCreate(index, state);
} catch (IndexNotFoundException e) {
shouldAutoCreate = false;
indicesThatCannotBeCreated.put(index, e);
}
if (shouldAutoCreate) {
autoCreateIndices.add(index);
}
}
// Step 3: create all the indices that are missing, if there are any missing. start the bulk after all the creates come back.
if (autoCreateIndices.isEmpty()) {
executeBulk(task, bulkRequest, startTime, listener, responses, indicesThatCannotBeCreated); // 索引
} else {
final AtomicInteger counter = new AtomicInteger(autoCreateIndices.size());
for (String index : autoCreateIndices) {
createIndex(index, bulkRequest.timeout(), new ActionListener<CreateIndexResponse>() {
@Override
public void onResponse(CreateIndexResponse result) {
if (counter.decrementAndGet() == 0) {
threadPool.executor(ThreadPool.Names.WRITE).execute(
() -> executeBulk(task, bulkRequest, startTime, listener, responses, indicesThatCannotBeCreated));
}
}
@Override
public void onFailure(Exception e) {
if (!(ExceptionsHelper.unwrapCause(e) instanceof ResourceAlreadyExistsException)) {
// fail all requests involving this index, if create didn't work
for (int i = 0; i < bulkRequest.requests.size(); i++) {
DocWriteRequest<?> request = bulkRequest.requests.get(i);
if (request != null && setResponseFailureIfIndexMatches(responses, i, request, index, e)) {
bulkRequest.requests.set(i, null);
}
}
}
if (counter.decrementAndGet() == 0) {
executeBulk(task, bulkRequest, startTime, ActionListener.wrap(listener::onResponse, inner -> {
inner.addSuppressed(e);
listener.onFailure(inner);
}), responses, indicesThatCannotBeCreated);
}
}
});
}
}
} else {
executeBulk(task, bulkRequest, startTime, listener, responses, emptyMap());
}
}接下来, BulkOperation将 BulkRequest 转换成 BulkShardRequest,也就是具体在哪个分片上执行操作
// org.elasticsearch.action.bulk.TransportBulkAction
protected void doRun() {
final ClusterState clusterState = observer.setAndGetObservedState();
if (handleBlockExceptions(clusterState)) {
return;
}
final ConcreteIndices concreteIndices = new ConcreteIndices(clusterState, indexNameExpressionResolver);
MetaData metaData = clusterState.metaData();
for (int i = 0; i < bulkRequest.requests.size(); i++) {
DocWriteRequest<?> docWriteRequest = bulkRequest.requests.get(i);
//the request can only be null because we set it to null in the previous step, so it gets ignored
if (docWriteRequest == null) {
continue;
}
if (addFailureIfIndexIsUnavailable(docWriteRequest, i, concreteIndices, metaData)) {
continue;
}
Index concreteIndex = concreteIndices.resolveIfAbsent(docWriteRequest); // 解析索引
try {
switch (docWriteRequest.opType()) {
case CREATE:
case INDEX:
IndexRequest indexRequest = (IndexRequest) docWriteRequest;
final IndexMetaData indexMetaData = metaData.index(concreteIndex);
MappingMetaData mappingMd = indexMetaData.mappingOrDefault();
Version indexCreated = indexMetaData.getCreationVersion();
indexRequest.resolveRouting(metaData);
indexRequest.process(indexCreated, mappingMd, concreteIndex.getName()); // 校验indexRequest,自动生成id
break;
case UPDATE:
TransportUpdateAction.resolveAndValidateRouting(metaData, concreteIndex.getName(),
(UpdateRequest) docWriteRequest);
break;
case DELETE:
docWriteRequest.routing(metaData.resolveWriteIndexRouting(docWriteRequest.routing(), docWriteRequest.index()));
// check if routing is required, if so, throw error if routing wasn't specified
if (docWriteRequest.routing() == null && metaData.routingRequired(concreteIndex.getName())) {
throw new RoutingMissingException(concreteIndex.getName(), docWriteRequest.type(), docWriteRequest.id());
}
break;
default: throw new AssertionError("request type not supported: [" + docWriteRequest.opType() + "]");
}
} catch (ElasticsearchParseException | IllegalArgumentException | RoutingMissingException e) {
BulkItemResponse.Failure failure = new BulkItemResponse.Failure(concreteIndex.getName(), docWriteRequest.type(),
docWriteRequest.id(), e);
BulkItemResponse bulkItemResponse = new BulkItemResponse(i, docWriteRequest.opType(), failure);
responses.set(i, bulkItemResponse);
// make sure the request gets never processed again
bulkRequest.requests.set(i, null);
}
}
// first, go over all the requests and create a ShardId -> Operations mapping
Map<ShardId, List<BulkItemRequest>> requestsByShard = new HashMap<>();
for (int i = 0; i < bulkRequest.requests.size(); i++) {
DocWriteRequest<?> request = bulkRequest.requests.get(i);
if (request == null) {
continue;
}
String concreteIndex = concreteIndices.getConcreteIndex(request.index()).getName();
ShardId shardId = clusterService.operationRouting().indexShards(clusterState, concreteIndex, request.id(),
request.routing()).shardId(); // 根据文档id路由确定分片
List<BulkItemRequest> shardRequests = requestsByShard.computeIfAbsent(shardId, shard -> new ArrayList<>());
shardRequests.add(new BulkItemRequest(i, request));
}
if (requestsByShard.isEmpty()) {
listener.onResponse(new BulkResponse(responses.toArray(new BulkItemResponse[responses.length()]),
buildTookInMillis(startTimeNanos)));
return;
}
final AtomicInteger counter = new AtomicInteger(requestsByShard.size());
String nodeId = clusterService.localNode().getId();
for (Map.Entry<ShardId, List<BulkItemRequest>> entry : requestsByShard.entrySet()) {
final ShardId shardId = entry.getKey();
final List<BulkItemRequest> requests = entry.getValue();
BulkShardRequest bulkShardRequest = new BulkShardRequest(shardId, bulkRequest.getRefreshPolicy(), // 构建BulkShardRequest
requests.toArray(new BulkItemRequest[requests.size()]));
bulkShardRequest.waitForActiveShards(bulkRequest.waitForActiveShards());
bulkShardRequest.timeout(bulkRequest.timeout());
if (task != null) {
bulkShardRequest.setParentTask(nodeId, task.getId());
}
shardBulkAction.execute(bulkShardRequest, new ActionListener<BulkShardResponse>() {
@Override
public void onResponse(BulkShardResponse bulkShardResponse) {
for (BulkItemResponse bulkItemResponse : bulkShardResponse.getResponses()) {
// we may have no response if item failed
if (bulkItemResponse.getResponse() != null) {
bulkItemResponse.getResponse().setShardInfo(bulkShardResponse.getShardInfo());
}
responses.set(bulkItemResponse.getItemId(), bulkItemResponse);
}
if (counter.decrementAndGet() == 0) {
finishHim();
}
}
@Override
public void onFailure(Exception e) {
// create failures for all relevant requests
for (BulkItemRequest request : requests) {
final String indexName = concreteIndices.getConcreteIndex(request.index()).getName();
DocWriteRequest<?> docWriteRequest = request.request();
responses.set(request.id(), new BulkItemResponse(request.id(), docWriteRequest.opType(),
new BulkItemResponse.Failure(indexName, docWriteRequest.type(), docWriteRequest.id(), e)));
}
if (counter.decrementAndGet() == 0) {
finishHim();
}
}
private void finishHim() {
listener.onResponse(new BulkResponse(responses.toArray(new BulkItemResponse[responses.length()]),
buildTookInMillis(startTimeNanos)));
}
});
}
}看下id路由逻辑
// org.elasticsearch.cluster.routing.OperationRouting
public static int generateShardId(IndexMetaData indexMetaData, @Nullable String id, @Nullable String routing) {
final String effectiveRouting;
final int partitionOffset;
if (routing == null) {
assert(indexMetaData.isRoutingPartitionedIndex() == false) : "A routing value is required for gets from a partitioned index";
effectiveRouting = id;
} else {
effectiveRouting = routing;
}
if (indexMetaData.isRoutingPartitionedIndex()) {
partitionOffset = Math.floorMod(Murmur3HashFunction.hash(id), indexMetaData.getRoutingPartitionSize());
} else {
// we would have still got 0 above but this check just saves us an unnecessary hash calculation
partitionOffset = 0;
}
return calculateScaledShardId(indexMetaData, effectiveRouting, partitionOffset);
}
private static int calculateScaledShardId(IndexMetaData indexMetaData, String effectiveRouting, int partitionOffset) {
final int hash = Murmur3HashFunction.hash(effectiveRouting) + partitionOffset; // hash
// we don't use IMD#getNumberOfShards since the index might have been shrunk such that we need to use the size
// of original index to hash documents
return Math.floorMod(hash, indexMetaData.getRoutingNumShards()) / indexMetaData.getRoutingFactor();
}然后看看此分片是在当前节点,还是远程节点上,现在进入routing阶段。(笔者这里只启动了一个节点,我们就看下本地节点的逻辑)
// org.elasticsearch.action.support.replication.TransportReplicationAction
protected void doRun() {
setPhase(task, "routing");
final ClusterState state = observer.setAndGetObservedState();
final String concreteIndex = concreteIndex(state, request);
final ClusterBlockException blockException = blockExceptions(state, concreteIndex);
if (blockException != null) {
if (blockException.retryable()) {
logger.trace("cluster is blocked, scheduling a retry", blockException);
retry(blockException);
} else {
finishAsFailed(blockException);
}
} else {
// request does not have a shardId yet, we need to pass the concrete index to resolve shardId
final IndexMetaData indexMetaData = state.metaData().index(concreteIndex);
if (indexMetaData == null) {
retry(new IndexNotFoundException(concreteIndex));
return;
}
if (indexMetaData.getState() == IndexMetaData.State.CLOSE) {
throw new IndexClosedException(indexMetaData.getIndex());
}
// resolve all derived request fields, so we can route and apply it
resolveRequest(indexMetaData, request);
assert request.waitForActiveShards() != ActiveShardCount.DEFAULT :
"request waitForActiveShards must be set in resolveRequest";
final ShardRouting primary = primary(state);
if (retryIfUnavailable(state, primary)) {
return;
}
final DiscoveryNode node = state.nodes().get(primary.currentNodeId());
if (primary.currentNodeId().equals(state.nodes().getLocalNodeId())) { // 根据路由确定primary在哪个node上,然后和当前node做比较
performLocalAction(state, primary, node, indexMetaData);
} else {
performRemoteAction(state, primary, node);
}
}
}既然是当前节点,那就是发送内部请求
// org.elasticsearch.transport.TransportService
private <T extends TransportResponse> void sendRequestInternal(final Transport.Connection connection, final String action,
final TransportRequest request,
final TransportRequestOptions options,
TransportResponseHandler<T> handler) {
if (connection == null) {
throw new IllegalStateException("can't send request to a null connection");
}
DiscoveryNode node = connection.getNode();
Supplier<ThreadContext.StoredContext> storedContextSupplier = threadPool.getThreadContext().newRestorableContext(true);
ContextRestoreResponseHandler<T> responseHandler = new ContextRestoreResponseHandler<>(storedContextSupplier, handler);
// TODO we can probably fold this entire request ID dance into connection.sendReqeust but it will be a bigger refactoring
final long requestId = responseHandlers.add(new Transport.ResponseContext<>(responseHandler, connection, action));
final TimeoutHandler timeoutHandler;
if (options.timeout() != null) {
timeoutHandler = new TimeoutHandler(requestId, connection.getNode(), action);
responseHandler.setTimeoutHandler(timeoutHandler);
} else {
timeoutHandler = null;
}
try {
if (lifecycle.stoppedOrClosed()) {
/*
* If we are not started the exception handling will remove the request holder again and calls the handler to notify the
* caller. It will only notify if toStop hasn't done the work yet.
*
* Do not edit this exception message, it is currently relied upon in production code!
*/
// TODO: make a dedicated exception for a stopped transport service? cf. ExceptionsHelper#isTransportStoppedForAction
throw new TransportException("TransportService is closed stopped can't send request");
}
if (timeoutHandler != null) {
assert options.timeout() != null;
timeoutHandler.scheduleTimeout(options.timeout());
}
connection.sendRequest(requestId, action, request, options); // local node optimization happens upstream
...
private void sendLocalRequest(long requestId, final String action, final TransportRequest request, TransportRequestOptions options) {
final DirectResponseChannel channel = new DirectResponseChannel(localNode, action, requestId, this, threadPool);
try {
onRequestSent(localNode, requestId, action, request, options);
onRequestReceived(requestId, action);
final RequestHandlerRegistry reg = getRequestHandler(action); // 注册器模式 action -> handler
if (reg == null) {
throw new ActionNotFoundTransportException("Action [" + action + "] not found");
}
final String executor = reg.getExecutor();
if (ThreadPool.Names.SAME.equals(executor)) {
//noinspection unchecked
reg.processMessageReceived(request, channel);
} else {
threadPool.executor(executor).execute(new AbstractRunnable() {
@Override
protected void doRun() throws Exception {
//noinspection unchecked
reg.processMessageReceived(request, channel); // 处理请求
}
@Override
public boolean isForceExecution() {
return reg.isForceExecution();
}
@Override
public void onFailure(Exception e) {
try {
channel.sendResponse(e);
} catch (Exception inner) {
inner.addSuppressed(e);
logger.warn(() -> new ParameterizedMessage(
"failed to notify channel of error message for action [{}]", action), inner);
}
}
@Override
public String toString() {
return "processing of [" + requestId + "][" + action + "]: " + request;
}
});
}然后获取在分片上的执行请求许可
// org.elasticsearch.action.support.replication.TransportReplicationAction
protected void doRun() throws Exception {
final ShardId shardId = primaryRequest.getRequest().shardId();
final IndexShard indexShard = getIndexShard(shardId);
final ShardRouting shardRouting = indexShard.routingEntry();
// we may end up here if the cluster state used to route the primary is so stale that the underlying
// index shard was replaced with a replica. For example - in a two node cluster, if the primary fails
// the replica will take over and a replica will be assigned to the first node.
if (shardRouting.primary() == false) {
throw new ReplicationOperation.RetryOnPrimaryException(shardId, "actual shard is not a primary " + shardRouting);
}
final String actualAllocationId = shardRouting.allocationId().getId();
if (actualAllocationId.equals(primaryRequest.getTargetAllocationID()) == false) {
throw new ShardNotFoundException(shardId, "expected allocation id [{}] but found [{}]",
primaryRequest.getTargetAllocationID(), actualAllocationId);
}
final long actualTerm = indexShard.getPendingPrimaryTerm();
if (actualTerm != primaryRequest.getPrimaryTerm()) {
throw new ShardNotFoundException(shardId, "expected allocation id [{}] with term [{}] but found [{}]",
primaryRequest.getTargetAllocationID(), primaryRequest.getPrimaryTerm(), actualTerm);
}
acquirePrimaryOperationPermit( // 获取在primary分片上执行操作的许可
indexShard,
primaryRequest.getRequest(),
ActionListener.wrap(
releasable -> runWithPrimaryShardReference(new PrimaryShardReference(indexShard, releasable)),
e -> {
if (e instanceof ShardNotInPrimaryModeException) {
onFailure(new ReplicationOperation.RetryOnPrimaryException(shardId, "shard is not in primary mode", e));
} else {
onFailure(e);
}
}));
}现在进入primary阶段
// org.elasticsearch.action.support.replication.TransportReplicationAction
setPhase(replicationTask, "primary");
final ActionListener<Response> referenceClosingListener = ActionListener.wrap(response -> {
primaryShardReference.close(); // release shard operation lock before responding to caller
setPhase(replicationTask, "finished");
onCompletionListener.onResponse(response);
}, e -> handleException(primaryShardReference, e));
final ActionListener<Response> globalCheckpointSyncingListener = ActionListener.wrap(response -> {
if (syncGlobalCheckpointAfterOperation) {
final IndexShard shard = primaryShardReference.indexShard;
try {
shard.maybeSyncGlobalCheckpoint("post-operation");
} catch (final Exception e) {
// only log non-closed exceptions
if (ExceptionsHelper.unwrap(
e, AlreadyClosedException.class, IndexShardClosedException.class) == null) {
// intentionally swallow, a missed global checkpoint sync should not fail this operation
logger.info(
new ParameterizedMessage(
"{} failed to execute post-operation global checkpoint sync", shard.shardId()), e);
}
}
}
referenceClosingListener.onResponse(response);
}, referenceClosingListener::onFailure);
new ReplicationOperation<>(primaryRequest.getRequest(), primaryShardReference,
ActionListener.wrap(result -> result.respond(globalCheckpointSyncingListener), referenceClosingListener::onFailure),
newReplicasProxy(), logger, actionName, primaryRequest.getPrimaryTerm()).execute();中间的调用跳转不赘述,最后TransportShardBulkAction 调用索引引引擎
// org.elasticsearch.action.bulk.TransportShardBulkAction
static boolean executeBulkItemRequest(BulkPrimaryExecutionContext context, UpdateHelper updateHelper, LongSupplier nowInMillisSupplier,
MappingUpdatePerformer mappingUpdater, Consumer<ActionListener<Void>> waitForMappingUpdate,
ActionListener<Void> itemDoneListener) throws Exception {
final DocWriteRequest.OpType opType = context.getCurrent().opType();
final UpdateHelper.Result updateResult;
if (opType == DocWriteRequest.OpType.UPDATE) {
final UpdateRequest updateRequest = (UpdateRequest) context.getCurrent();
try {
updateResult = updateHelper.prepare(updateRequest, context.getPrimary(), nowInMillisSupplier);
} catch (Exception failure) {
// we may fail translating a update to index or delete operation
// we use index result to communicate failure while translating update request
final Engine.Result result =
new Engine.IndexResult(failure, updateRequest.version());
context.setRequestToExecute(updateRequest);
context.markOperationAsExecuted(result);
context.markAsCompleted(context.getExecutionResult());
return true;
}
// execute translated update request
switch (updateResult.getResponseResult()) {
case CREATED:
case UPDATED:
IndexRequest indexRequest = updateResult.action();
IndexMetaData metaData = context.getPrimary().indexSettings().getIndexMetaData();
MappingMetaData mappingMd = metaData.mappingOrDefault();
indexRequest.process(metaData.getCreationVersion(), mappingMd, updateRequest.concreteIndex());
context.setRequestToExecute(indexRequest);
break;
case DELETED:
context.setRequestToExecute(updateResult.action());
break;
case NOOP:
context.markOperationAsNoOp(updateResult.action());
context.markAsCompleted(context.getExecutionResult());
return true;
default:
throw new IllegalStateException("Illegal update operation " + updateResult.getResponseResult());
}
} else {
context.setRequestToExecute(context.getCurrent());
updateResult = null;
}
assert context.getRequestToExecute() != null; // also checks that we're in TRANSLATED state
final IndexShard primary = context.getPrimary();
final long version = context.getRequestToExecute().version();
final boolean isDelete = context.getRequestToExecute().opType() == DocWriteRequest.OpType.DELETE;
final Engine.Result result;
if (isDelete) {
final DeleteRequest request = context.getRequestToExecute();
result = primary.applyDeleteOperationOnPrimary(version, request.type(), request.id(), request.versionType(),
request.ifSeqNo(), request.ifPrimaryTerm());
} else {
final IndexRequest request = context.getRequestToExecute();
result = primary.applyIndexOperationOnPrimary(version, request.versionType(), new SourceToParse( // lucene 执行引擎
request.index(), request.type(), request.id(), request.source(), request.getContentType(), request.routing()),
request.ifSeqNo(), request.ifPrimaryTerm(), request.getAutoGeneratedTimestamp(), request.isRetry());
}3.索引流程(replica)
在ReplicationOperation的execute方法中,primary分片执行完操作后,监听器会向复制分片发送请求
// org.elasticsearch.action.support.replication.ReplicationOperation
public void execute() throws Exception {
final String activeShardCountFailure = checkActiveShardCount();
final ShardRouting primaryRouting = primary.routingEntry();
final ShardId primaryId = primaryRouting.shardId();
if (activeShardCountFailure != null) {
finishAsFailed(new UnavailableShardsException(primaryId,
"{} Timeout: [{}], request: [{}]", activeShardCountFailure, request.timeout(), request));
return;
}
totalShards.incrementAndGet();
pendingActions.incrementAndGet(); // increase by 1 until we finish all primary coordination
primary.perform(request, ActionListener.wrap(this::handlePrimaryResult, resultListener::onFailure)); // 监听器调用 handlePrimaryResult
}
private void handlePrimaryResult(final PrimaryResultT primaryResult) {
this.primaryResult = primaryResult;
primary.updateLocalCheckpointForShard(primary.routingEntry().allocationId().getId(), primary.localCheckpoint());
primary.updateGlobalCheckpointForShard(primary.routingEntry().allocationId().getId(), primary.globalCheckpoint());
final ReplicaRequest replicaRequest = primaryResult.replicaRequest();
if (replicaRequest != null) {
if (logger.isTraceEnabled()) {
logger.trace("[{}] op [{}] completed on primary for request [{}]", primary.routingEntry().shardId(), opType, request);
}
// we have to get the replication group after successfully indexing into the primary in order to honour recovery semantics.
// we have to make sure that every operation indexed into the primary after recovery start will also be replicated
// to the recovery target. If we used an old replication group, we may miss a recovery that has started since then.
// we also have to make sure to get the global checkpoint before the replication group, to ensure that the global checkpoint
// is valid for this replication group. If we would sample in the reverse, the global checkpoint might be based on a subset
// of the sampled replication group, and advanced further than what the given replication group would allow it to.
// This would entail that some shards could learn about a global checkpoint that would be higher than its local checkpoint.
final long globalCheckpoint = primary.computedGlobalCheckpoint();
// we have to capture the max_seq_no_of_updates after this request was completed on the primary to make sure the value of
// max_seq_no_of_updates on replica when this request is executed is at least the value on the primary when it was executed
// on.
final long maxSeqNoOfUpdatesOrDeletes = primary.maxSeqNoOfUpdatesOrDeletes();
assert maxSeqNoOfUpdatesOrDeletes != SequenceNumbers.UNASSIGNED_SEQ_NO : "seqno_of_updates still uninitialized";
final ReplicationGroup replicationGroup = primary.getReplicationGroup();
markUnavailableShardsAsStale(replicaRequest, replicationGroup);
performOnReplicas(replicaRequest, globalCheckpoint, maxSeqNoOfUpdatesOrDeletes, replicationGroup); // 在复制分片上执行操作
}
successfulShards.incrementAndGet(); // mark primary as successful
decPendingAndFinishIfNeeded();
}
...
private void performOnReplicas(final ReplicaRequest replicaRequest, final long globalCheckpoint,
final long maxSeqNoOfUpdatesOrDeletes, final ReplicationGroup replicationGroup) {
// for total stats, add number of unassigned shards and
// number of initializing shards that are not ready yet to receive operations (recovery has not opened engine yet on the target)
totalShards.addAndGet(replicationGroup.getSkippedShards().size());
final ShardRouting primaryRouting = primary.routingEntry();
for (final ShardRouting shard : replicationGroup.getReplicationTargets()) { // 轮询各个复制分片
if (shard.isSameAllocation(primaryRouting) == false) {
performOnReplica(shard, replicaRequest, globalCheckpoint, maxSeqNoOfUpdatesOrDeletes);
}
}
}
private void performOnReplica(final ShardRouting shard, final ReplicaRequest replicaRequest,
final long globalCheckpoint, final long maxSeqNoOfUpdatesOrDeletes) {
if (logger.isTraceEnabled()) {
logger.trace("[{}] sending op [{}] to replica {} for request [{}]", shard.shardId(), opType, shard, replicaRequest);
}
totalShards.incrementAndGet();
pendingActions.incrementAndGet();
replicasProxy.performOn(shard, replicaRequest, primaryTerm, globalCheckpoint, maxSeqNoOfUpdatesOrDeletes, // 调用代理ReplicasProxy
new ActionListener<ReplicaResponse>() {
@Override
public void onResponse(ReplicaResponse response) {
successfulShards.incrementAndGet();
try {
primary.updateLocalCheckpointForShard(shard.allocationId().getId(), response.localCheckpoint());
primary.updateGlobalCheckpointForShard(shard.allocationId().getId(), response.globalCheckpoint());
} catch (final AlreadyClosedException e) {
// the index was deleted or this shard was never activated after a relocation; fall through and finish normally
} catch (final Exception e) {
// fail the primary but fall through and let the rest of operation processing complete
final String message = String.format(Locale.ROOT, "primary failed updating local checkpoint for replica %s", shard);
primary.failShard(message, e);
}
decPendingAndFinishIfNeeded();
}
@Override
public void onFailure(Exception replicaException) {
logger.trace(() -> new ParameterizedMessage(
"[{}] failure while performing [{}] on replica {}, request [{}]",
shard.shardId(), opType, shard, replicaRequest), replicaException);
// Only report "critical" exceptions - TODO: Reach out to the master node to get the latest shard state then report.
if (TransportActions.isShardNotAvailableException(replicaException) == false) {
RestStatus restStatus = ExceptionsHelper.status(replicaException);
shardReplicaFailures.add(new ReplicationResponse.ShardInfo.Failure(
shard.shardId(), shard.currentNodeId(), replicaException, restStatus, false));
}
String message = String.format(Locale.ROOT, "failed to perform %s on replica %s", opType, shard);
replicasProxy.failShardIfNeeded(shard, primaryTerm, message, replicaException,
ActionListener.wrap(r -> decPendingAndFinishIfNeeded(), ReplicationOperation.this::onNoLongerPrimary));
}
@Override
public String toString() {
return "[" + replicaRequest + "][" + shard + "]";
}
});
}
发送transport请求
// org.elasticsearch.action.support.replication.TransportReplicationAction
public void performOn(
final ShardRouting replica,
final ReplicaRequest request,
final long primaryTerm,
final long globalCheckpoint,
final long maxSeqNoOfUpdatesOrDeletes,
final ActionListener<ReplicationOperation.ReplicaResponse> listener) {
String nodeId = replica.currentNodeId();
final DiscoveryNode node = clusterService.state().nodes().get(nodeId);
if (node == null) {
listener.onFailure(new NoNodeAvailableException("unknown node [" + nodeId + "]"));
return;
}
final ConcreteReplicaRequest<ReplicaRequest> replicaRequest = new ConcreteReplicaRequest<>(
request, replica.allocationId().getId(), primaryTerm, globalCheckpoint, maxSeqNoOfUpdatesOrDeletes);
final ActionListenerResponseHandler<ReplicaResponse> handler = new ActionListenerResponseHandler<>(listener,
ReplicaResponse::new);
transportService.sendRequest(node, transportReplicaAction, replicaRequest, transportOptions, handler); // 发送transport请求
}副分片收到请求处理结果与主分片类似,最后调用lucene引擎
// org.elasticsearch.action.bulk.TransportShardBulkAction
private static Engine.Result performOpOnReplica(DocWriteResponse primaryResponse, DocWriteRequest<?> docWriteRequest,
IndexShard replica) throws Exception {
final Engine.Result result;
switch (docWriteRequest.opType()) {
case CREATE:
case INDEX:
final IndexRequest indexRequest = (IndexRequest) docWriteRequest;
final ShardId shardId = replica.shardId();
final SourceToParse sourceToParse = new SourceToParse(shardId.getIndexName(), indexRequest.type(), indexRequest.id(),
indexRequest.source(), indexRequest.getContentType(), indexRequest.routing());
result = replica.applyIndexOperationOnReplica(primaryResponse.getSeqNo(), primaryResponse.getVersion(), // 调用lucene引擎
indexRequest.getAutoGeneratedTimestamp(), indexRequest.isRetry(), sourceToParse);
break;
case DELETE:
DeleteRequest deleteRequest = (DeleteRequest) docWriteRequest;
result = replica.applyDeleteOperationOnReplica(primaryResponse.getSeqNo(), primaryResponse.getVersion(),
deleteRequest.type(), deleteRequest.id());
break;
default:
assert false : "Unexpected request operation type on replica: " + docWriteRequest + ";primary result: " + primaryResponse;
throw new IllegalStateException("Unexpected request operation type on replica: " + docWriteRequest.opType().getLowercase());
}4.总结
本文简单描述了es索引流程,包括了http请求是如何解析的,如何确定分片的。但是仍有许多不足,比如没有讨论远程节点是如何处理的,lucene执行引擎的细节,后面博客会继续探讨这些课题。