Python自动化办公实战案例分享
点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
气蒸云梦泽,波撼岳阳城。
大家好,我是Python进阶者。
一、前言
前几天在粉丝群有个粉丝问了一个Python自动化办公的问题,这里拿出来给大家一起分享下。粉丝需求如下:
1、我有一个合同表格,里边有很多合同名称,但是合同,名称还需要做一些额外的处理,比方说正则表达式提起合同具体的名称、针对合同名称还需要替换当中的【第】、【批】字符等,最后得到合同名称。2、针对合同名称,我们需要读取,然后根据合同名称,去目标文件夹中匹配对应的合同,并且实现移动。
看上去这个需求不是特别难,就是繁琐一些,这里给大家一起分享下。
二、实现过程
这里实现的代码,如下所示:
import pandas as pd
import re
# df = pd.read_excel("test.xlsx")
# df["合同名称"] = df["合同名称"].str.replace("订单(", "")
# df["合同名称"] = df["合同名称"].str.replace(")", "")
# print(df["合同名称"].head(5))
# text = "xxx(2022年)xxx订单订单(xxx第十三批)"
# pattern = r'\(.*?\)'
# res = re.findall(pattern, text)
# print(res[1])
from chinesenumber import NumberParser
numberparse =NumberParser()
df = pd.read_excel("test.xlsx")
# df["合同名称"] = df["合同名称"].str.extract(r"((.*?))")
df["合同名称"] = df["合同名称"].str.extract(r"(.*?).*?((.*?))")
df["合同名称_new1"] = df["合同名称"].apply(lambda x: numberparse.numberify(x))
# df["合同名称_new2"] = df["合同名称_new1"].str.sub("第", "").sub("批", "")
# df["合同名称_new2"] = df["合同名称_new1"].str.replace("第", "").str.replace("批", "")
df['合同名称_new2'] = df['合同名称_new1'].str.replace(r'(第|批)', '', regex=True)
print(df["合同名称_new2"])
df.to_excel('test1.xlsx')得到的最后的合同名称如下所示: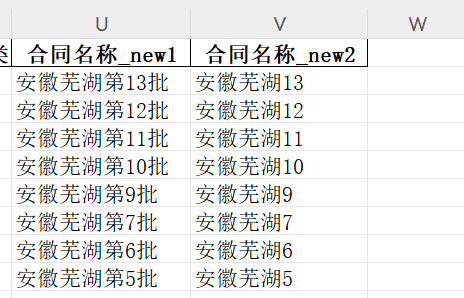
接下来就需要完成第二部,去原始文件夹中匹配目标文件,并且实现移动到新的文件夹下。
import pandas as pd
import re
import os
import shutil
def copy_file(file_name):
# (root,dirs,files)分别为:遍历的文件夹,遍历的文件夹下的所有文件夹,遍历的文件夹下的所有文件
for root, dirs, files in os.walk(source_path):
for file in files:
if file_name in file: # 多了一层限定条件
print(file)
shutil.copyfile(root + '\\' + file, target_path + '\\' + file)
print(root + '\\' + file + ' 复制成功-> ' + target_path)
if __name__ == '__main__':
# 文件夹路径
source_path = r'xxx\source_path'
# 输出路径
target_path = r'C:\Users\Desktop\res'
df = pd.read_excel("test1.xlsx")
df["合同名称_new2"] = df["合同名称_new2"].apply(lambda x: copy_file(x))
print("over!")可以看到文件已经顺利地完成既定的移动,顺利地完成粉丝的需求。
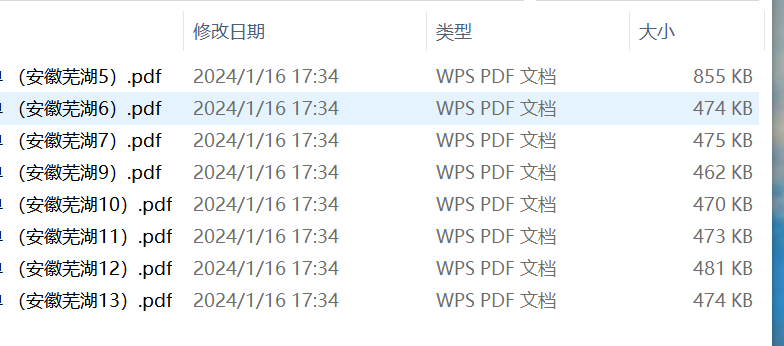
经过指导,这个方法顺利地解决了粉丝的问题。如果你还有方法,也欢迎多多交流~
如果你也有类似这种数据分析的小问题,欢迎随时来交流群学习交流哦,有问必答!
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python自动化办公的需求,帮助粉丝顺利解决了问题。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting1),应粉丝要求,我创建了一些ChatGPT机器人交流群和高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

------------------- End -------------------
往期精彩文章推荐:
盘点一个Pandas实现Excel判断写法的问题
Pandas实现这列股票代码中10-12之间的股票筛出来
从5亿行数据中,筛选出重复次数在1000行的数据行,也爆内存了
Python自动化办公——3个Excel表格中每个门店物品不同,想要汇总在一起(方法五)

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~