Elasticsearch:混合搜索是 GenAI 应用的未来

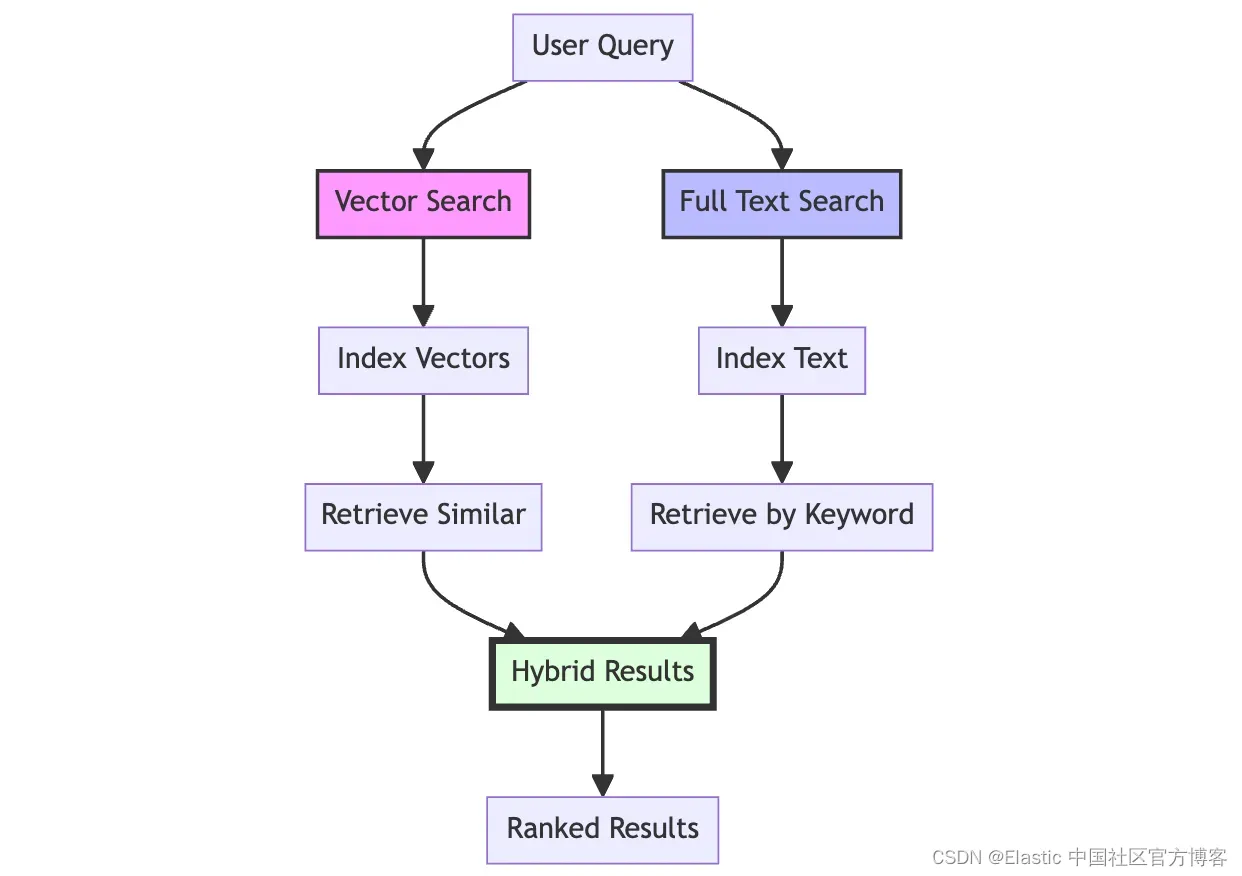
在这个竞争激烈的人工智能时代,自动化和数据为王。 从庞大的存储库中有效地自动化搜索和检索信息的过程的能力变得至关重要。 随着技术的进步,信息检索方法也在不断进步,从而导致了各种搜索机制的发展。 随着生成式人工智能模型成为吸引力的中心,应用程序需要可靠的搜索和检索技术。 其中,如果说旧的全文搜索具有信任因素,那么向量搜索则正在成为先进的搜索技术。
今天,我们将探索全文搜索和向量搜索,并了解如何在当今的数字环境中使用它们。
什么是全文检索?
全文搜索是一种在大量文本数据中查找特定信息的强大技术。 与仅查找精确匹配的简单关键字搜索不同,全文搜索会分析文档的整个文本并了解查询的上下文。 这使得它能够找到相关结果,即使查询不使用你搜索的确切关键字。
这是它的工作原理
- 索引。 当你将文本数据添加到支持全文搜索的系统时,系统首先创建索引。 该索引就像文本的详细地图,列出了它包含的所有单词和短语以及它们出现的位置。
- 查询。 执行全文搜索时,你输入包含关键字或短语的查询。 然后,系统在索引中搜索包含全部或部分查询词的文档。
- 排名。 根据所使用的特定算法,系统将根据结果与你的查询的相关性对结果进行排名。 影响排名的因素包括文档中查询词的频率和接近度,以及文档的整体重要性或发布日期等其他因素。
在 Elasticsearch 中,我们很容易针对数据进行全文搜索,比如:
GET twitter/_search
"match": {
"city": "上海"
}
}
}更多关于全文搜索的知识,我们可以参考文章 “开始使用 Elasticsearch (2)”。
什么是向量搜索?

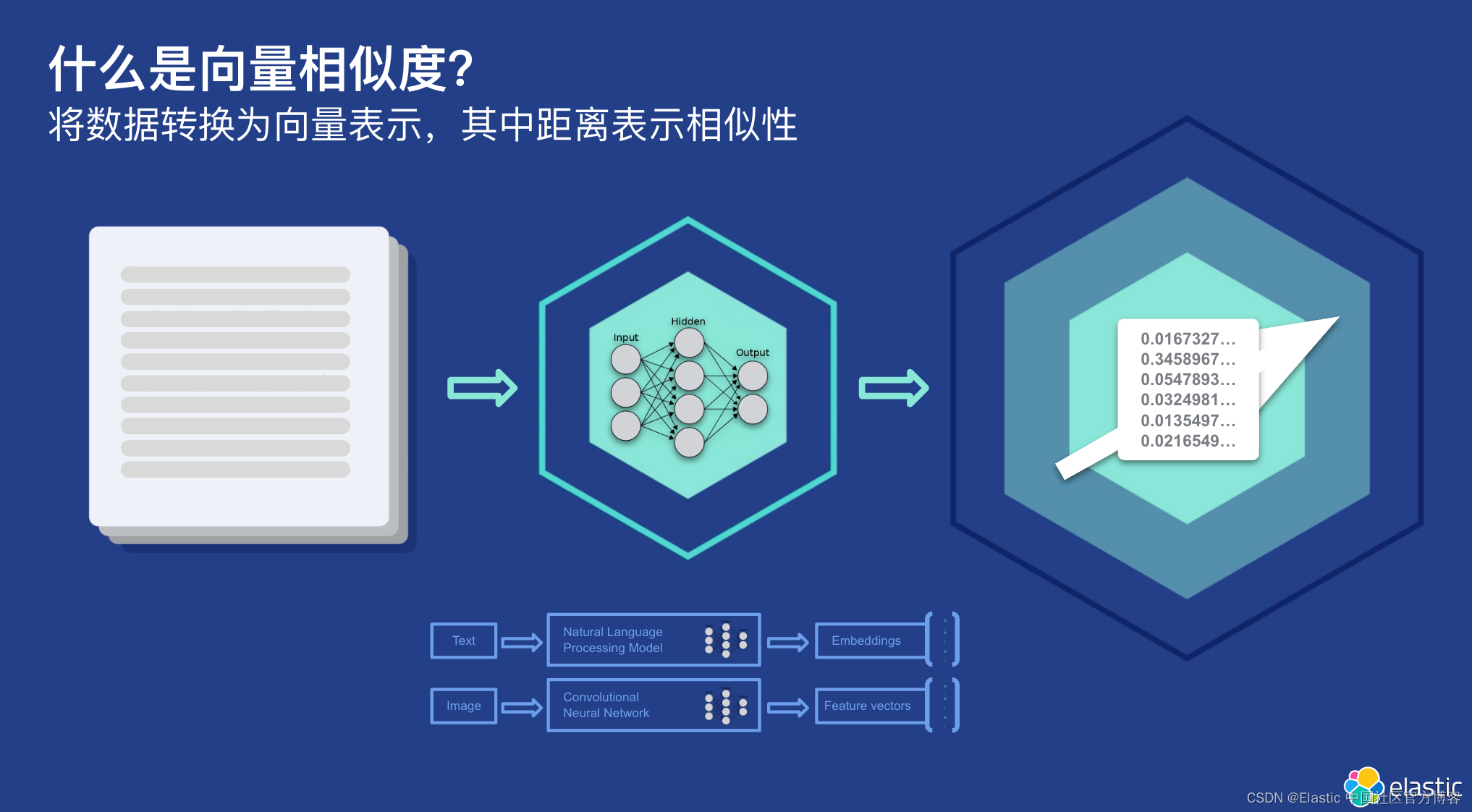
向量搜索是大多数生成式人工智能应用最迫切的需求。 它通过理解机器和人类语言来检索上下文相关的信息,理解用户想要回报他/她的查询的含义。 这种方法需求量很大,并受到生成人工智能行业专家和组织的高度赞扬。 向量数据库使用这种方法为用户查询检索语义上正确的信息。
例如,用户在检索信息时不需要知道确切的单词 —— 即使他们知道一些相似的单词,向量搜索也可以检索到接近准确的结果。 在信息搜索需要人性化的地方(例如电子商务应用程序),这尤其有用。
通过更紧密地与人类的思维和沟通方式保持一致,它为用户和人工智能系统之间更自然、更高效的交互开辟了新的可能性。 随着这项技术的不断发展,其影响力预计将不断扩大,进一步巩固其作为生成人工智能行业现代信息检索策略基石的作用。
向量搜索拥有令人印象深刻的功能:
- 语义理解: 同义词、短语甚至隐含含义都不再是个谜。
- 关键词的相关性: 查找与你的意图真正相关的信息,而不仅仅是关键字填充的页面。
- 个性化:了解你的喜好并推荐你真正喜欢的东西。
但与其他事物一样,向量搜索也有其独特的不好的特点。 训练模型和计算这些奇特的向量可能会耗费大量的计算资源。 虽然它擅长理解含义,但有时你只需要精确的关键字搜索即可。
向量搜索的工作原理
以下是向量搜索工作原理的简化说明:
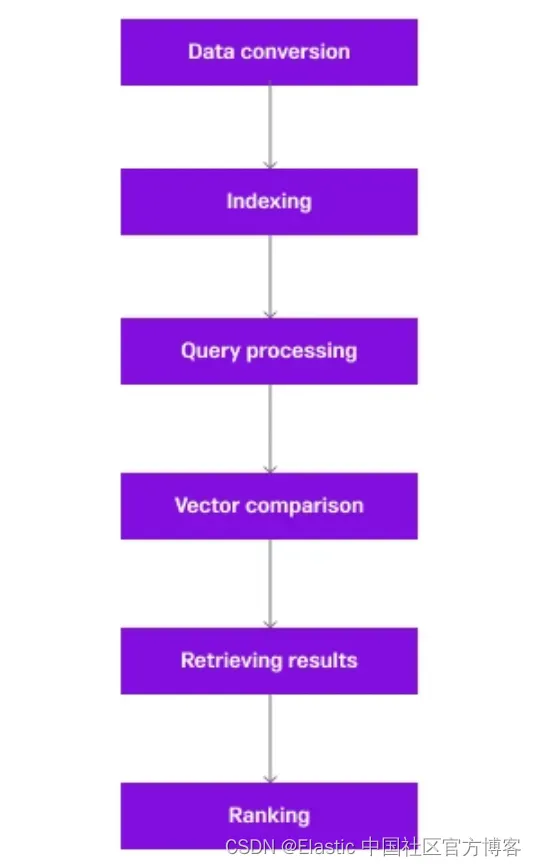
- 数据转换:使用文本的词嵌入或图像的卷积神经网络等模型将每个项目(如文本文档或图像)转换为向量。 这些模型旨在捕获内容的语义或视觉本质。
- 索引:然后,这些向量会在数据库中建立索引(例如 Elasticsearch),Elasticsearch 专为高效、高维向量搜索而设计。 这种索引通常涉及以相似的项目在向量空间中更接近的方式组织向量。
- 查询处理:当收到搜索查询时,它也会使用与数据所用的相同模型转换为向量。
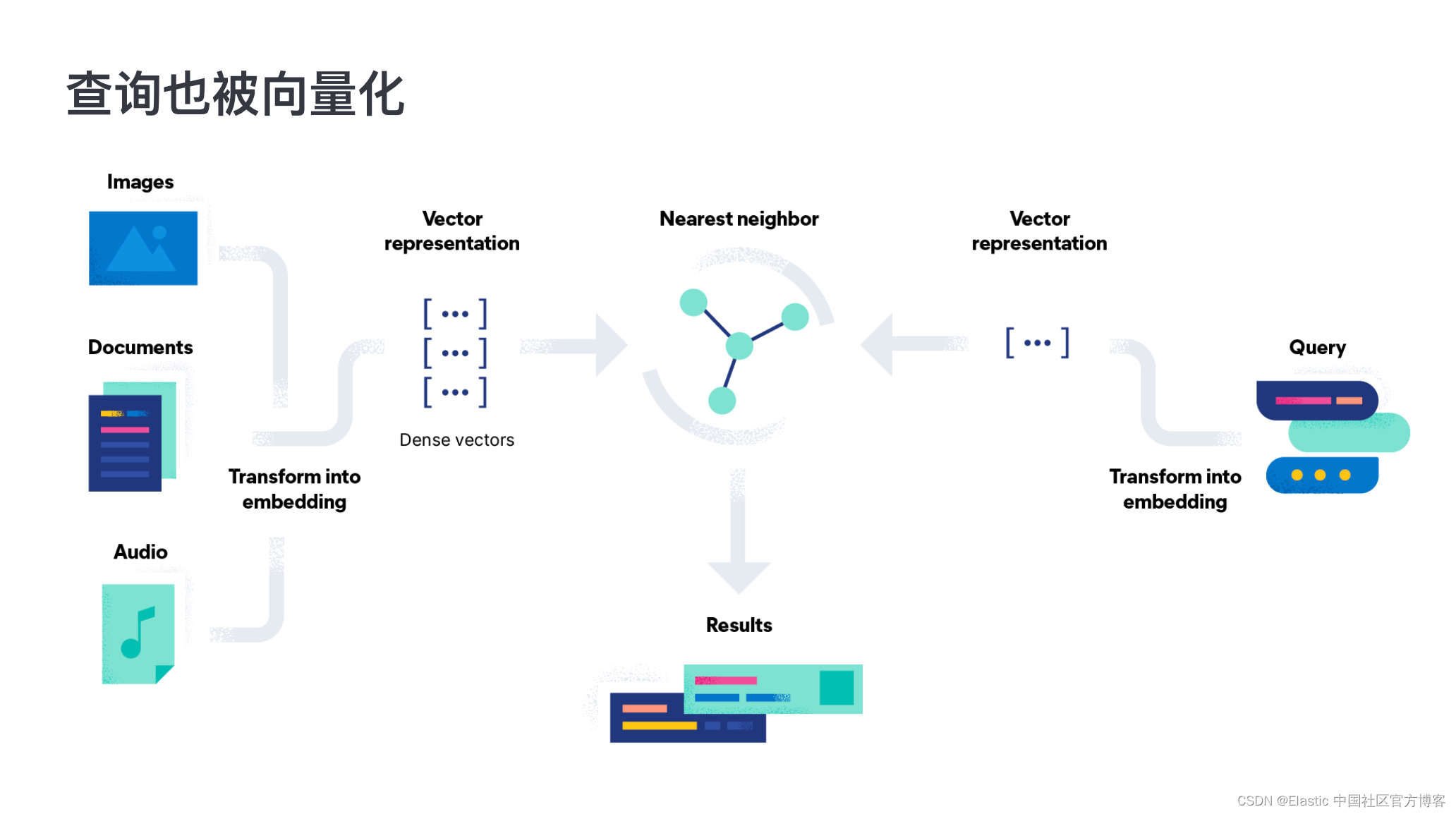
- 向量比较:搜索涉及将查询向量与索引中的向量进行比较。 这通常是使用余弦相似度或欧几里得距离等相似度度量来完成的。 这个想法是找到最接近查询向量的向量

如果你想了解更多关于向量搜索的知识,请详细观看视频:
Elasticsearch Relevance Engine
全文搜索与向量搜索:谁赢了?
虽然全文搜索在精度和速度方面表现出色,而向量搜索解锁了语义理解,但混合方法成为真正的冠军。 想象一下,一个搜索不仅可以理解你的精确关键字(例如“red shoes”),而且还可以找到你未提及的那些舒适的 crimson sneakers。 即使你不使用完美的措辞,这种组合也能提供高度相关的结果。 可以将其视为两全其美:准确性与偶然性相结合,确保你永远不会因为未准确拼写而错过隐藏的宝石。 从本质上讲,混合搜索超越了限制 —— 突破了信息检索的界限,提供了既精确又令人惊喜的体验。
Elasticsearch 在全文搜索积累了深厚的搜索基础,加上在最新的发布中的向量搜索技术,从而使其成为理想的混合搜索工具。这个和一些在世面上的纯向量搜索有无可替代的优势。
混合搜索
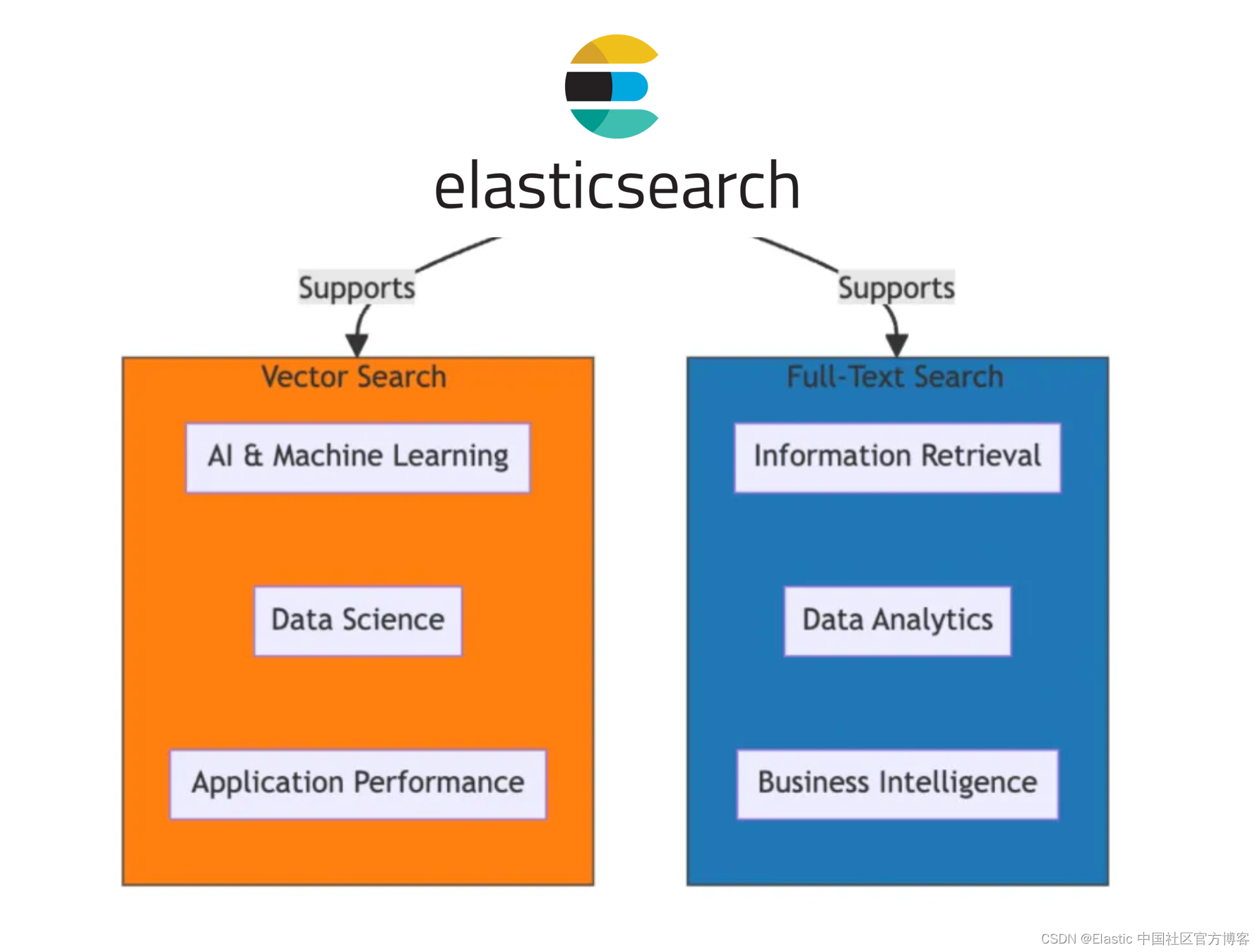
在信息检索领域,出现了一股新力量:混合搜索。Elasticsearch 处于领先地位,使开发人员能够开发丰富的人工智能和分析应用程序,利用向量搜索和全文搜索的综合优势。
在构建人工智能应用程序时,这对你意味着什么? 你不再被迫在机器人的精确性和细致入微的理解之间做出选择。 Elasticsearch 弥合了这一鸿沟,使你能够释放搜索的全部潜力并提供真正有意义的体验。
Elasticsearch 通过索引向量搜索加速信息检索。 这一改变游戏规则的功能无缝地融合了闪电般快速的向量搜索、精确的全文搜索和尖端的索引技术 —— 所有这些都由近似最近邻 (ANN) 搜索提供支持。 准备好在浩瀚的数据海洋中体验 100-1,000 倍的更快搜索速度和准确性。
倒数排序融合 - Reciprocal rank fusion
由于全文搜索及向量搜索是使用不同的算法进行打分的,这就造成把两个不同搜索结果综合起来统一排名的困难。向量搜索的分数处于 0-1.0 之间,而全文搜索的结果排名分数可能是高于10或者更大的值。我们需要一种方法把两种搜索方法的结果进行综合处理,并得出一个唯一的排名。
倒数排序融合(RRF)是一种将具有不同相关性指标的多个结果集组合成单个结果集的方法。 RRF 无需调优,不同的相关性指标也不必相互关联即可获得高质量的结果。该方法的优势在于不利用相关分数,而仅靠排名计算。相关分数存在的问题在于不同模型的分数范围差。

具体 RRF 是如何工作的,请详细阅读文章 “Elasticsearch:倒数排序融合 - Reciprocal rank fusion (RRF)”。
更为重要的是:Elasticsearch 目前支持第三方的密集向量搜索,全文搜索(基于 BM25 打分)及稀疏向量搜索(ELSER)。我们可以通过 RRF 来针对所有的搜索方法进行混合搜索,无论是多种搜索方法在一起进行搜索:

有关 Elasticsearch 向量搜索及混合评分的更多阅读,请参考 “NLP - 自然语言处理及向量搜索”。
更多阅读:
-
使用 Elastic Learned Sparse Encoder 和混合评分的卓越相关性
-
改进 Elastic Stack 中的信息检索:混合检索 - hybrid retrieval
-
通过 Elasticsearch 和 Go 使用混合搜索进行地鼠狩猎
-
Elasticsearch:结合两全其美:Elasticsearch 与 BM25 和 HNSW 的混合搜索
-
Elastic Search 8.9:与 RRF 的混合搜索、更快的向量搜索和面向公众的搜索端点
-
Elasticsearch:Search tutorial - 使用 Python 进行搜索 (一)(二)(三)(四)
-
Elasticsearch:语义搜索快速入门