【EAI 020】Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
论文标题:Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
论文作者:Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, Shuran Song
作者单位:Columbia University, Toyota Research Institute, MIT
论文原文:https://arxiv.org/abs/2303.04137
论文出处:–
论文被引:–(01/05/2024)
项目主页:https://diffusion-policy.cs.columbia.edu/
论文代码:–
Abstract
本文介绍了扩散策略(Diffusion Policy),这是一种生成机器人行为的新方法,它将机器人的视觉运动策略表示为条件去噪扩散过程。我们在 4 个不同的机器人操作基准中的 12 个不同任务中对 Diffusion Policy 进行了基准测试,结果发现它始终优于现有的最先进机器人学习方法,平均提高了 46.9%。Diffusion Policy 可以学习动作分布得分函数的梯度,并在推理过程中通过一系列随机 Langevin 动力学步骤对该梯度场进行迭代优化。我们发现,扩散公式在用于机器人策略时具有强大的优势,包括可以优雅地处理多模态动作分布,适用于高维动作空间,以及表现出令人印象深刻的训练稳定性。为了充分释放扩散模型在物理机器人视觉运动策略学习方面的潜力,本文提出了一系列关键技术贡献,包括后退视距控制合并(incorporation of receding horizon control),视觉调节(visual conditioning)和时间序列扩散Transformer(time-series diffusion transformer)。我们希望这项工作有助于推动新一代策略学习技术的发展,使其能够利用扩散模型强大的生成建模能力。
I. INTRODUCTION
从演示中学习策略,其最简单的形式可以表述为学习将观察结果映射到行动的监督回归任务。然而,在实践中,预测机器人行动的独特性质(如存在多模态分布,连续相关性和高精度要求)使得这项任务与其他监督学习问题相比,具有独特性和挑战性。

先前的工作试图通过探索不同的行动表示(图 1 a)来应对这一挑战,如使用高斯混合 [29],量化动作的分类表示 [42],或将策略表示(图 1 b)从显式转换为隐式,以更好地捕捉多模态分布 [12, 56]。
在这项工作中,我们试图通过引入一种新形式的机器人视觉运动策略(robot visuomotor policy)来应对这一挑战,即通过机器人动作空间的条件去噪扩散过程[18](扩散策略)来生成行为。在这种表述中,策略不是直接输出动作,而是根据视觉观察结果,在 K 次去噪迭代中推导出动作分数梯度(图 1 c)。这种表述方式使机器人策略继承了扩散模型的几个关键特性,从而显著提高了性能。
Expressing multimodal action distributions.
通过学习行动得分函数的梯度[46],并对该梯度场进行随机 Langevin 动力学采样,扩散策略可以表达任意可归一化的分布[32],其中包括多模态行动分布,这是策略学习面临的一个众所周知的挑战。
High-dimensional output space.
正如其令人印象深刻的图像生成结果所证明的那样,扩散模型对高维度输出空间具有出色的可扩展性。这一特性允许策略联合推断未来行动序列,而不是单步行动,这对于鼓励时间行动一致性和避免近视规划(myopic planning)至关重要。
Stable training.
训练基于能量的(energy-based)策略通常需要负采样来估算一个难以处理的归一化常数,众所周知,这会导致训练的不稳定性[11, 12]。扩散策略通过学习能量函数的梯度绕过了这一要求,从而在保持分布表达性的同时实现了稳定的训练。
我们的主要贡献是将上述优势引入机器人领域,并在复杂的真实世界机器人操作任务中展示其有效性。为了在视觉运动策略学习中成功运用扩散模型,我们提出了以下技术贡献,以提高扩散策略的性能,释放其在物理机器人上的全部潜力:
- Closed-loop action sequences:我们将策略预测高维行动序列的能力与后退视距控制(receding-horizon control)相结合,以实现稳健的执行。这种设计允许策略以闭环方式不断重新规划其行动,同时保持时间行动的一致性——在长视距规划和响应能力之间实现平衡。
- Visual conditioning:我们引入了一种视觉条件扩散策略,在这种策略中,视觉观察结果被视为条件,而不是联合数据分布的一部分。在这种方法中,无论去噪迭代多少次,该策略都能提取一次视觉表征,从而大大减少了计算量,实现了实时行动推理。
- Time-series diffusion transformer:我们提出了一种新的基于Transformer的扩散网络,它能最大限度地减少典型的基于 CNN 模型的过度平滑效应,并在需要高频动作变化和速度控制的任务中实现最先进的性能。
我们根据行为克隆公式,对 4 个不同基准[12, 15, 29, 42]的 12 项任务中的扩散策略进行了系统评估。评估包括模拟环境和真实环境,2DoF 到 6DoF 动作,单任务和多任务基准,全驱动和欠驱动系统(fully- and underactuated systems),刚性和流体物体,并使用了由单个和多个用户收集的演示数据。
从经验上看,我们发现所有基准的性能都得到了一致的提升,平均提升幅度为 46.9%,这为扩散策略的有效性提供了有力的证据。我们还提供了详细分析,仔细研究了所提算法的特点以及关键设计决策的影响。

II. DIFFUSION POLICY FORMULATION
我们将视觉运动机器人策略表述为去噪扩散概率模型(Denoising Diffusion Probabilistic Models,DDPMs)[18]。最重要的是,扩散策略能够表达复杂的多模态动作分布,并具有稳定的训练行为——几乎不需要针对特定任务进行超参数微调。下文将更详细地介绍 DDPMs,并解释如何将其用于表示视觉运动策略。
A. Denoising Diffusion Probabilistic Models
DDPM 是一类生成模型,其输出生成被模拟为一个去噪过程,通常称为随机朗文动力学(Stochastic Langevin Dynamics)[55]。
从高斯噪声采样的 x K x^K xK 开始,DDPM 执行 K K K 次迭代去噪,产生一系列噪声水平递减的中间动作 x k , x k − 1 , . . . , x 0 x^k, x^{k-1}, ..., x^0 xk,xk−1,...,x0,直到形成所需的无噪声输出 x 0 x^0 x0。该过程遵循以下公式:
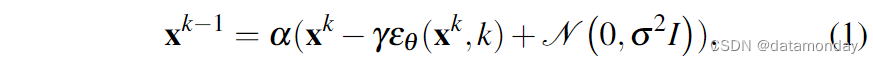
其中,εθ 是噪声预测网络,其参数 θ 将通过学习进行优化; N ( 0 , σ 2 I ) \mathscr{N}(0, σ^2I) N(0,σ2I) 是每次迭代时添加的高斯噪声。
上述公式 1 也可以理解为一个单一的噪声梯度下降步骤:
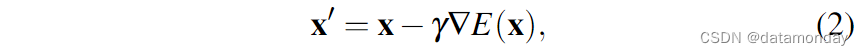
其中,噪声预测网络 εθ (x, k) 能有效预测梯度场 ∇E(x),γ 是学习率。
作为迭代步数 k 的函数,α,γ,σ 的选择也称为噪声调度(noise schedule),可以解释为梯度下降过程中的学习率调度。事实证明,略小于 1 的 α 可以提高稳定性 [18]。有关噪声调度的详细内容将在第三章 C 节中讨论。
B. DDPM Training
训练过程的第一步是从数据集中随机抽取未经修改的样本 x 0 x^0 x0。对于每个样本,我们随机选择一个去噪迭代 k,然后为迭代 k 采样一个具有适当方差的随机噪声 εk。
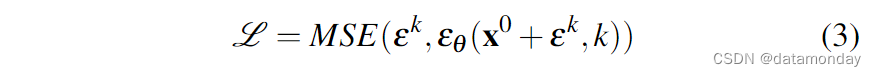
如文献 [18] 所示,最小化公式 3 中的损失函数也能最小化数据分布 p(x0) 与使用公式 1 从 DDPM q(x0) 中抽取的样本分布之间的 KL-散度 的变分下限。
C. Diffusion for Visuomotor Policy Learning
DDPM 通常用于生成图像(x 是一幅图像),而我们则使用 DDPM 来学习机器人视觉运动策略。这需要对公式进行两大修改:
- 1)将输出 x 改为代表机器人动作。
- 2)使去噪过程以输入观测 Ot 为条件。
以下段落将逐一讨论这些修改,图 3 显示了相关概述。
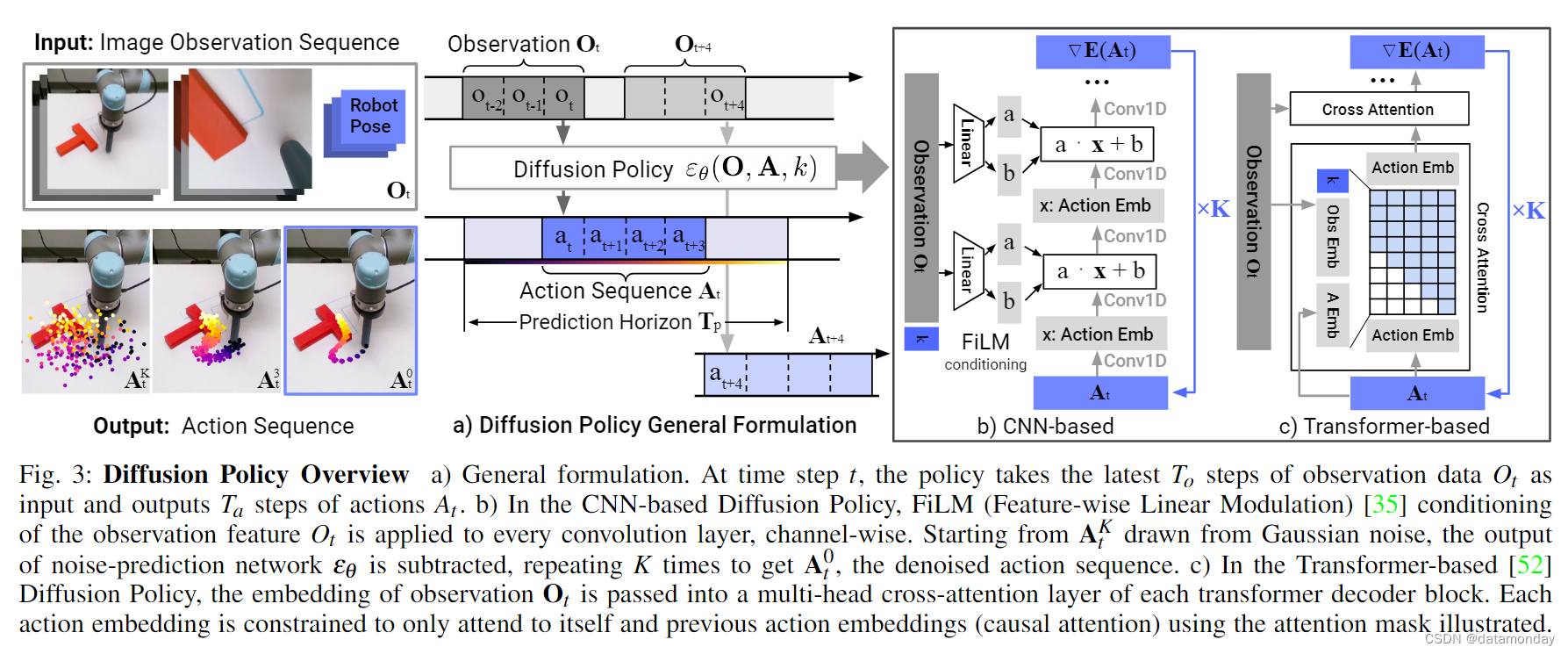
图 3: 扩散策略概述。a) 一般公式。在时间步 t 处,策略以观测数据 Ot 的最新的 To 步作为输入,输出动作 At 的 Ta 步。b) 在基于cnn的扩散策略中,观察特征 Ot 的FiLM (feature-wise Linear Modulation) [35] 调节被应用于每个卷积层,通道方向。从高斯噪声提取的 AK t 开始,减去噪声预测网络的输出 εθ,重复 K 次,得到去噪后的动作序列 A0t。c) 在基于 Transformer 的[52]扩散策略中,将观测值的嵌入传递到每个变压器译码块的多头交叉关注层中。每个动作嵌入都被限制为只关注自己和之前的动作嵌入 (因果注意),使用注意力掩码说明。
Closed-loop action-sequence prediction:有效的行动表述应鼓励长视距规划的时间一致性和平稳性,同时允许对意外观察做出迅速反应。为了实现这一目标,我们将扩散模型产生的行动序列预测与后退视距控制(receding horizon control)[30] 相结合,以实现稳健的行动执行。具体来说,在时间步长 t 处,策略将最新的 To 步观测数据 Ot 作为输入,并预测出 Tp 步行动,其中 Ta 步行动将在机器人身上执行,而无需重新规划。在这里,我们将 To 定义为观察范围,Tp 为行动预测范围,Ta 为行动执行范围。这样既能保证行动的时间一致性,又能保持反应灵敏。有关 Ta 影响的更多细节将在第 IV-C 节中讨论。
Visual observation conditioning:我们使用 DDPM 来近似条件分布 p(At |Ot) 而不是 Janner 等人[20]用于规划的联合分布 p(At , Ot)。这种表述方式使模型能够根据观察结果预测行动,而无需付出推断未来状态的代价,从而加快了扩散过程,提高了生成行动的准确性。为了捕捉条件分布 p(At |Ot), 我们将公式 1 修改为:
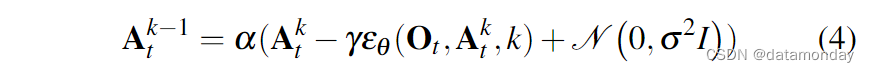
训练损失从等式 3 修改为:
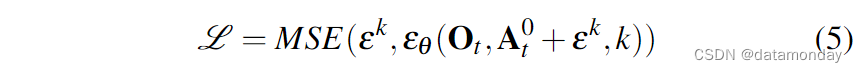
从去噪过程的输出中排除观测特征 Ot 能显著提高推理速度,更好地适应实时控制。它还有助于使视觉编码器的端到端训练变得可行。有关视觉编码器的详情将在第 III-B 节中介绍。
III. KEY DESIGN DECISIONS
在本节中,我们将介绍 “扩散策略” 的关键设计决策以及神经网络架构对 εθ 的具体实现。
A. Network Architecture Options
第一个设计决策是为 εθ 选择神经网络架构。在这项工作中,我们研究了两种常见的网络架构类型:卷积神经网络 (CNN) [40] 和变形器 [52],并比较了它们的性能和训练特性。请注意,噪声预测网络 εθ 的选择与视觉编码器无关,后者将在第三章 B 节中介绍。
CNN-based Diffusion Policy
我们采用 Janner 等人[21]的一维时空 CNN,并做了一些修改:
- 首先,我们只对条件分布 p(At |Ot )进行建模,方法是使用特征线性调制(Feature-wise Linear Modulation,FiLM)[35] 以及去噪迭代 k 对观测特征 Ot 的动作生成过程进行调节,如图 3 (b) 所示。
- 其次,我们只预测动作轨迹,而不是串联观测动作轨迹。
- 第三,由于与我们利用后退预测视距的框架不兼容,我们取消了基于内绘的目标状态调节。不过,目标状态调节仍然可以使用与观察结果相同的 FiLM 调节方法。
在实践中,我们发现基于 CNN 的骨干网络在大多数任务中都能很好地运行,无需进行过多的超参数调整。不过,当所需的动作序列随时间发生快速而剧烈的变化时(如速度指令动作空间),它的表现就会很差,这可能是由于时序卷积偏好低频信号的归纳偏差[49]。
Time-series diffusion transformer
为了减少 CNN 模型中的过平滑效应[49],我们引入了一种新颖的基于Transformer的 DDPM,该 DDPM 采用 minGPT [42] 中的Transformer架构进行动作预测。带有噪声 Ak t 的动作作为输入标记(tokens)传入Transformer解码器块,扩散迭代 k 的正弦波嵌入作为第一个标记。观测值 Ot 通过共享 MLP 转换为观测值嵌入序列,然后作为输入特征传入 Transformer 解码器堆栈。梯度 εθ(Ot, Atk, k)由解码器堆栈的每个相应输出标记预测。
在我们基于状态的实验中,大多数表现最佳的策略都是通过转换器主干实现的,尤其是在任务复杂度和行动变化率较高的情况下。不过,我们发现Transformer对超参数更为敏感。Transformer训练的困难[25]并非扩散策略所独有,未来有可能通过改进Transformer训练技术或扩大数据规模来解决。
Recommendations.
一般来说,我们建议从基于 CNN 的扩散策略实施开始,作为新任务的首次尝试。如果由于任务复杂或动作变化率高而导致性能低下,则可以使用时间序列扩散Transformer公式来提高性能,但需要付出额外的微调代价。
B. Visual Encoder
视觉编码器将原始图像序列映射为潜在嵌入 Ot,并使用扩散策略进行端到端训练。不同的摄像机视角使用不同的编码器,每个时间步中的图像独立编码,然后串联形成 Ot。我们使用标准 ResNet18(无预训练)作为编码器,并做了以下修改:
- 1)用空间软最大池化取代全局平均池化,以保持空间信息 [29]。
- 2)用 GroupNorm [57] 代替 BatchNorm,以获得稳定的训练。当归一化层与指数移动平均[17](常用于 DDPMs)结合使用时,这一点非常重要。
C. Noise Schedule
噪声表由 σ,α,γ 和加性高斯噪声 εk 定义,是 k 的函数,已被广泛研究 [18, 33]。基本噪声表控制着扩散策略捕捉动作信号高频和低频特征的程度。在我们的控制任务中,我们根据经验发现 iDDPM [33] 中提出的平方余弦时间表最适合我们的任务。
D. Accelerating Inference for Real-time Control
我们使用扩散过程作为机器人的策略;因此,对于闭环实时控制而言,快速推理速度至关重要。去噪扩散隐含模型(Denoising Diffusion Implicit Models,DDIM)方法[45]将训练和推理中的去噪迭代次数分离开来,从而允许算法使用较少的迭代次数进行推理,以加快推理过程。在我们的实际实验中,使用 100 次训练迭代和 10 次推理迭代的 DDIM,在 Nvidia 3080 GPU 上实现了 0.1 秒的推理延迟。
IV. INTRIGUING PROPERTIES OF DIFFUSION POLICY
在本节中,我们将就扩散策略及其相对于其他策略表述形式的优势提出一些见解和直觉。
A. Model Multi-Modal Action Distributions
行为克隆文献[12, 42, 29]广泛讨论了人类示范中多模态分布建模的挑战。扩散策略能够自然而精确地表达多模态分布,这是其主要优势之一。
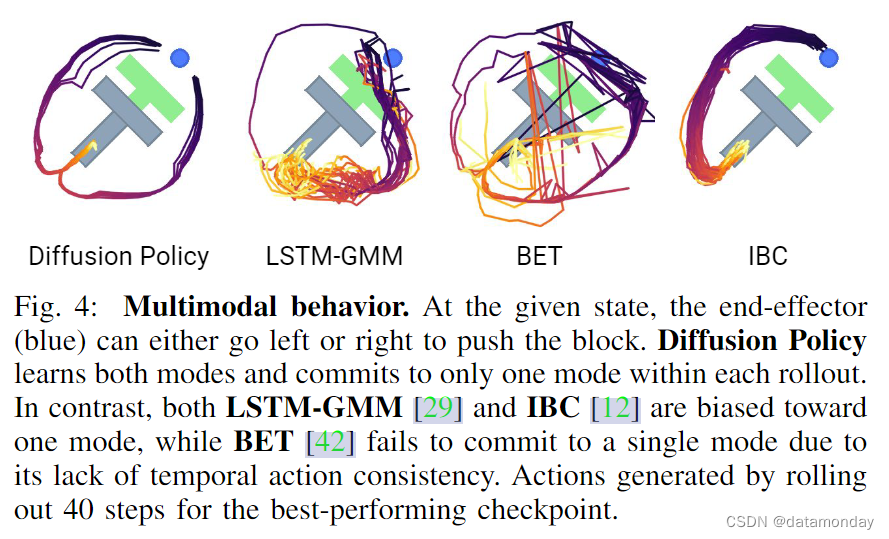
直观地说,扩散策略行动生成的多模式性来自两个方面——基本随机抽样过程和随机初始化。在随机朗文动力中,每个采样过程开始时都会从标准高斯中抽取一个初始样本 AK t,这有助于为最终行动预测 A0t 指定不同的可能收敛点。然后,在大量的迭代过程中,利用添加的高斯扰动对该动作进行进一步的随机优化,从而使单个动作样本在不同的多模态动作盆地之间收敛和移动。图 4 展示了扩散策略在平面推动任务(Push T,下文将介绍)中的多模态行为示例,但未对测试场景进行明确演示。
B. Synergy with Position Control
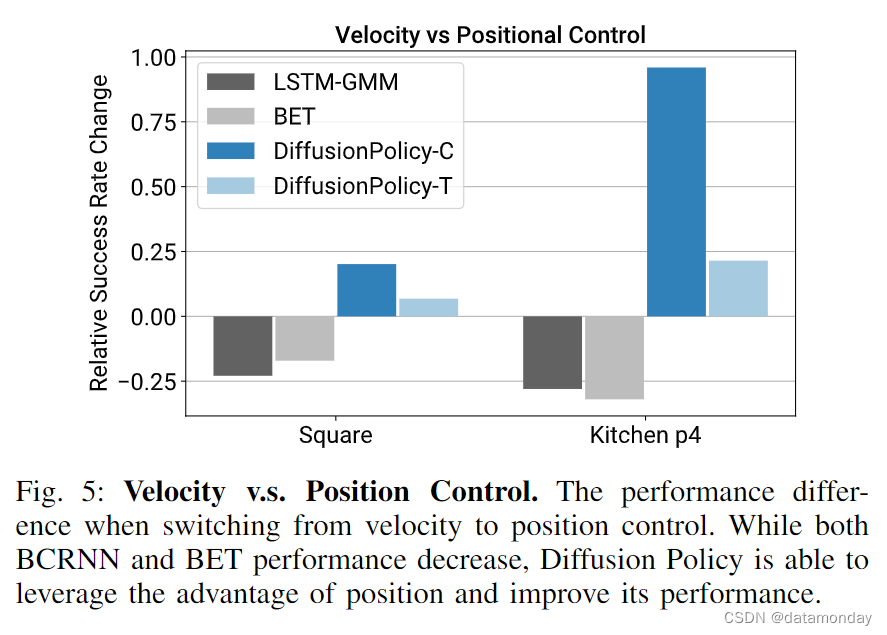
我们发现,采用位置控制行动空间的扩散策略始终优于采用速度控制的扩散策略,如图 5 所示。这一令人惊讶的结果与近期大多数行为克隆工作形成了鲜明对比,后者通常依赖于速度控制 [29, 42, 60, 13, 28, 27]。我们推测造成这种差异的主要原因有两个:
- 首先,在位置控制模式下,动作的多模态性比使用速度控制时更为明显。由于扩散策略能比现有方法更好地表达动作的多模态性,我们推测它在本质上比现有方法更少受到这一缺点的影响。
- 此外,位置控制比速度控制更少受到复合误差效应的影响,因此更适合于动作序列预测(将在下一节中讨论)。因此,扩散策略既较少受到位置控制主要缺点的影响,又能更好地利用位置控制的优势。
C. Benefits of Action-Sequence Prediction
由于难以从高维输出空间进行有效采样,大多数策略学习方法通常都会避免序列预测。例如,IBC 就很难有效地从能量景观不平滑的高维行动空间中采样。同样,BC-RNN 和 BET 也难以确定行动分布中存在的模式数量(GMM 或 kmeans 步骤需要)。
相比之下,DDPM 在不牺牲模型表现力的情况下,可以很好地扩展输出维度,这在许多图像生成应用中都得到了证明。利用这种能力,扩散策略以高维动作序列的形式表示动作,从而自然而然地解决了以下问题:
- Temporal action consistency:以图 4 为例。要从底部将 T 块推入目标,策略可以从左或从右绕过 T 块。但是,假设序列中的每个动作都是作为独立的多模态分布来预测的(如 BCRNN 和 BET 所做的)。在这种情况下,连续的动作可能来自不同的模式,从而产生在两种有效轨迹之间交替的抖动动作。
- Robustness to idle actions:当演示暂停时会出现空闲动作,导致一系列相同的位置动作或接近零速度的动作。这种情况在远程操作过程中很常见,有时还需要执行倒液体等任务。然而,单步策略很容易过度适应这种暂停行为。例如,BC-RNN 和 IBC 在实际实验中,如果没有从训练中明确移除空闲动作,就会经常卡住。
D. Training Stability
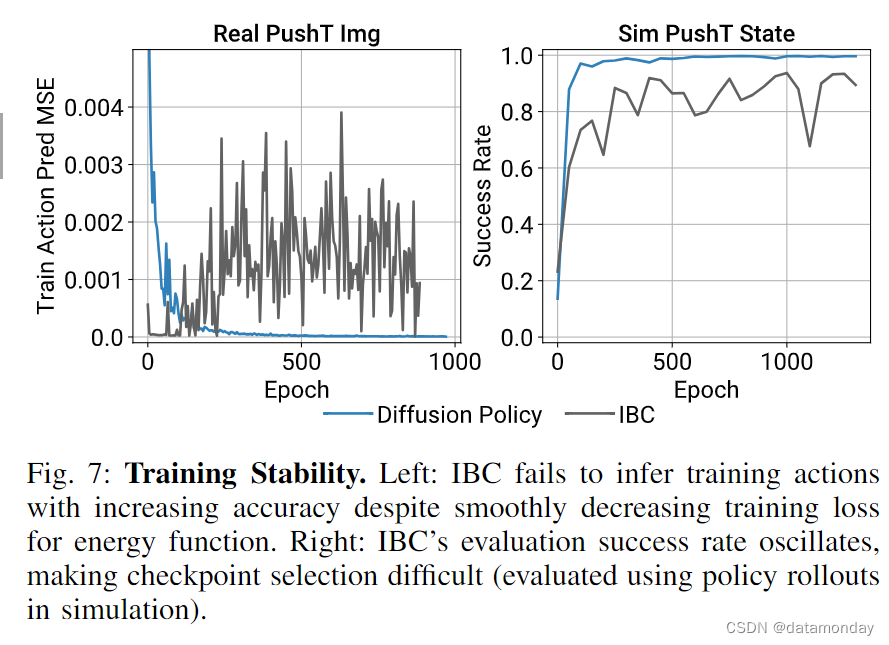
理论上,IBC 应具有与扩散策略类似的优势。然而,由于 IBC 固有的训练不稳定性 [48],在实践中从 IBC 中获得可靠和高性能的结果具有挑战性。图 7 显示了整个训练过程中的训练误差峰值和不稳定的评估性能,这使得超参数的转向和检查点的选择变得非常困难。因此,Florence 等人[12]评估了每个检查点,并报告了表现最好的检查点的结果。在现实世界中,这种工作流程需要对硬件上的许多策略进行评估,以选择最终策略。在此,我们将讨论为什么扩散策略在训练时显得更为稳定。
隐式策略使用基于能量的模型(Energy-Based Model,EBM)来表示行动分布:
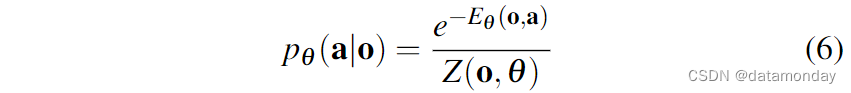
其中,Z(o, θ) 是一个难以处理的归一化常数(相对于 a)。
为训练隐式策略的 EBM,使用了 InfoNCE 式的损失函数,相当于公式 6 的负对数似然:
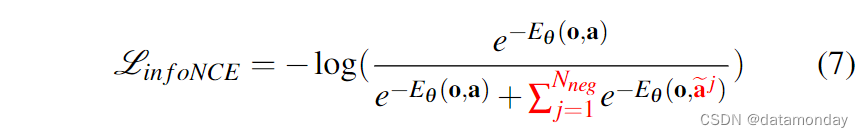
其中一组负样本 {aj}Nneg j=1 用于估计难以处理的归一化常数 Z(o, θ)。实际上,负采样的不准确性会导致 EBM 的训练不稳定 [11, 48]。
扩散策略和 DDPM 通过对公式 6 中相同行动分布的得分函数[46]建模,完全避免了估计 Z(a, θ) 的问题:
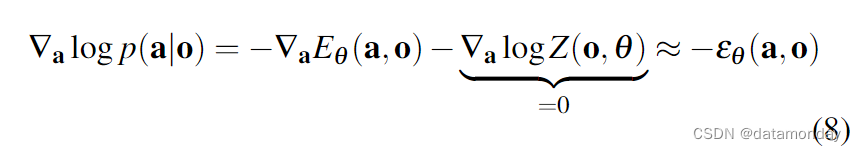
其中,噪声预测网络 εθ (a, o) 近似于评分函数 ∇a log p(a|o) 的负值[26],与归一化常数 Z(o, θ ) 无关。因此,扩散策略的推理(公式 4)和训练(公式 5)过程都不涉及对 Z(o, θ ) 的评估,从而使扩散策略的训练更加稳定。
V. EVALUATION
我们在 4 个基准[12, 15, 29, 42]中的 12 个任务上对扩散策略进行了系统评估。这套评估包括模拟环境和真实环境,单任务和多任务基准,全驱动和欠驱动系统,刚性和流体物体。我们发现,在所有测试基准中,扩散策略的表现始终优于之前的先进水平,平均成功率提高了 46.9%。在下面的章节中,我们将概述每项任务,我们对该任务的评估方法以及我们的主要收获。
A. Simulation Environments and datasets
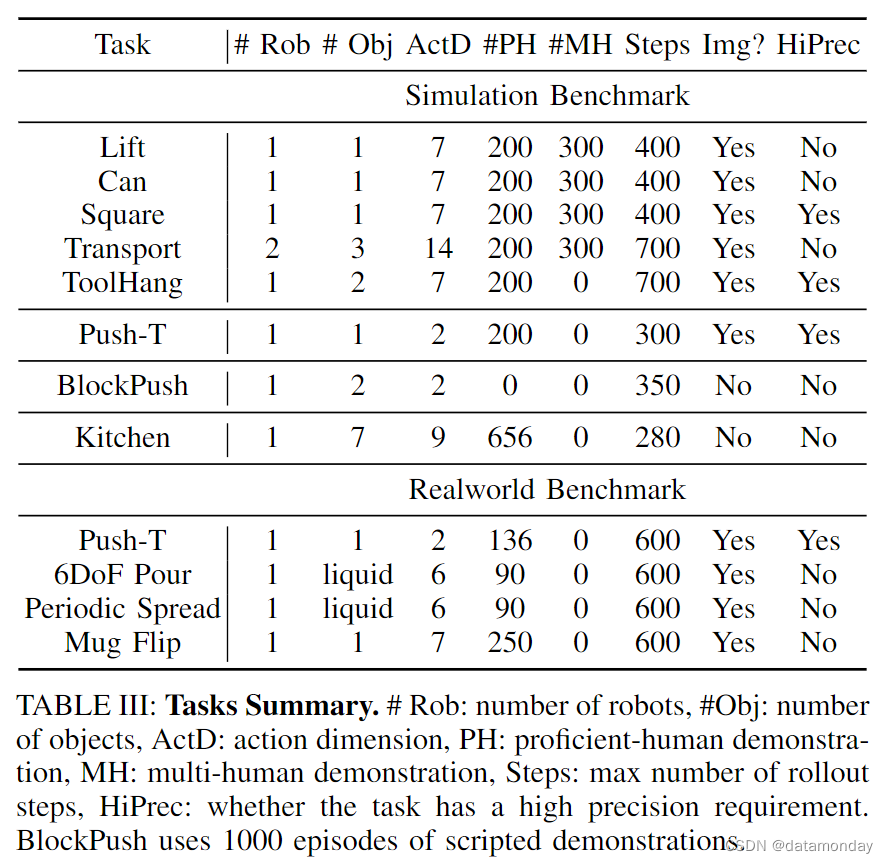
1)Robomimic:[29] 是一个大型机器人操作基准,旨在研究模仿学习和离线 RL。该基准包括 5 个任务,每个任务都有一个熟练人类(PH)远程操作演示数据集,其中 4 个任务有熟练/非熟练人类(MH)混合演示数据集(共 9 个变体)。对于每个变体,我们都报告了基于状态和图像的观测结果。表 III 总结了每个任务的属性。
2)Push-T:改编自 IBC [12],要求用圆形末端执行器(蓝色)s 推一个 T 形块(灰色)到固定目标(红色)。T 形块和末端执行器的随机初始条件增加了变化。任务要求利用复杂且接触丰富的物体动力学,通过点接触精确推动 T 形块。有两种变体:一种是使用 RGB 图像观测,另一种是使用从 T 块的地面真实姿态中获得的 9 个 2D 关键点,两种变体都使用本体感觉来确定末端执行器的位置。
3)Multimodal Block Pushing:该任务改编自 BET [42],通过以任意顺序将两个方块推入两个方格来测试策略对多模态动作分布建模的能力。演示数据由一个脚本甲骨文生成,该甲骨文可以访问真实状态信息。甲骨文会随机选择一个初始图块,并将其移动到随机选择的方格中。然后将剩余的区块推入剩余的方格中。这项任务包含长视距多模态,无法通过从观察到行动的单一函数映射来建模。
4)Franka Kitchen:是评估 IL 和离线-RL 方法学习多个长视距任务能力的常用环境。Relay Policy Learning [15]中提出的 Franka Kitchen 环境包含 7 个交互对象,并附带一个由 566 个演示组成的人类演示数据集,每个演示以任意顺序完成 4 个任务。目标是执行尽可能多的演示任务,而不考虑顺序,同时展示短视距和长视距多模态。
B. Evaluation Methodology
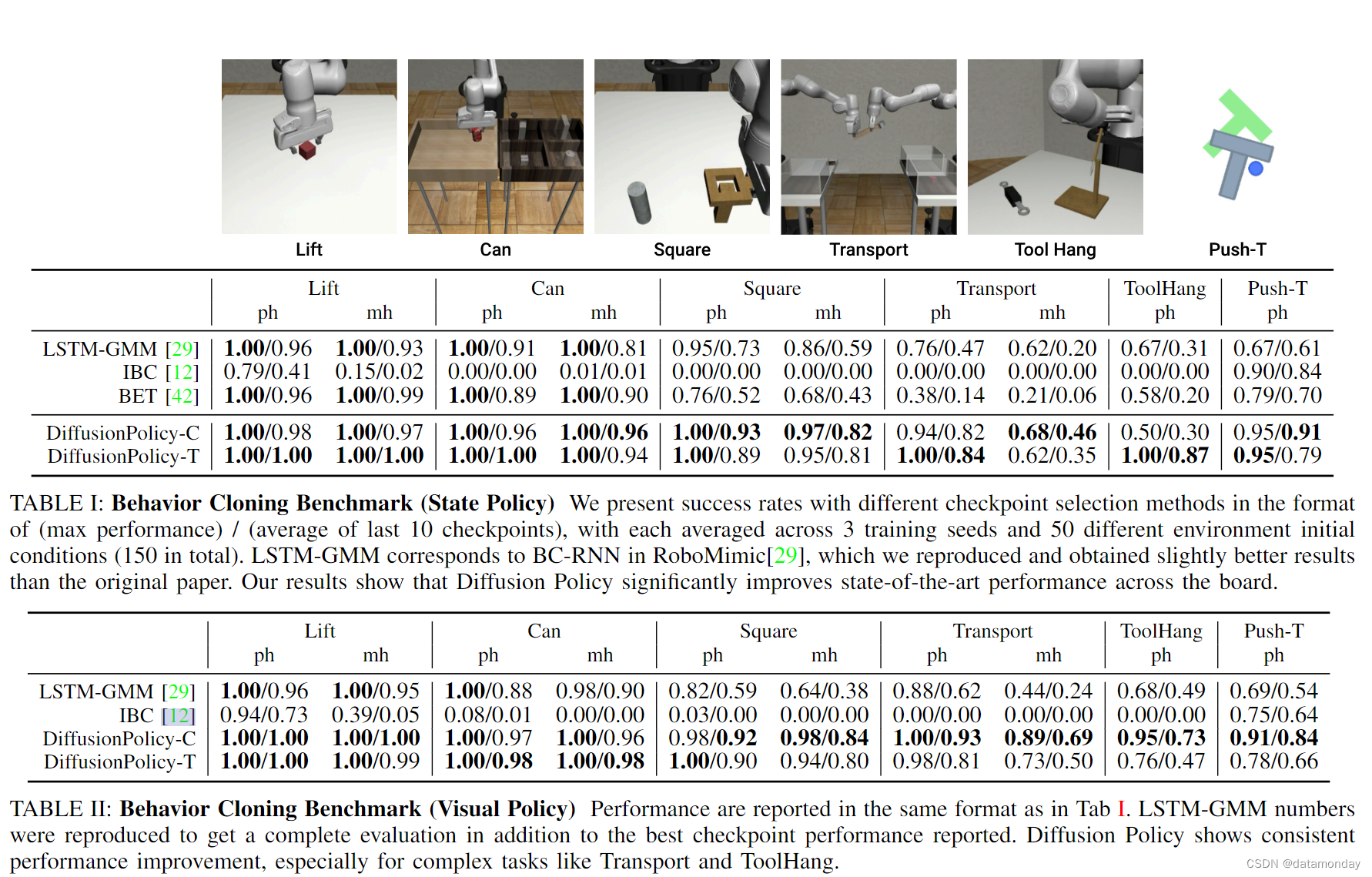
我们列出了每种基线方法在每种基准上的最佳表现,这些基准来自所有可能的来源–我们复制的结果(LSTM-GMM)或论文中报告的原始数据(BET,IBC)。我们报告的结果来自 3 个训练种子和 50 个环境初始化 1 的最后 10 个检查点(每 50 个epoch保存一次)的平均值(共 1500 次实验的平均值)。大多数任务的指标都是成功率,但 Push-T 任务除外,该任务使用的是目标区域覆盖率。此外,我们还报告了机器人仿真任务和 Push-T 任务中表现最好的检查点的平均值,以便与它们各自原始论文[29, 12]中的评估方法保持一致。所有基于状态的任务都训练了 4500 个epoch,基于图像的任务训练了 3000 个epoch。每种方法都使用其表现最佳的动作空间进行评估:扩散策略的位置控制和基线的速度控制(动作空间的影响将在第 V-C 章中详细讨论)。表 I 和表 II 总结了这些模拟基准的结果。
C. Key Findings
在我们的模拟基准研究(表 I,表 II 和 表 IV)中,扩散策略在所有任务和变体上,以及在状态和视觉观测方面,都优于其他方法,平均提高了 46.9%。以下段落总结了主要启示。
Diffusion Policy can express short-horizon multimodality.
我们将短视距行动多模态定义为实现同一即时目标的多种方式,这在人类演示数据中非常普遍[29]。在图 4 中,我们展示了在推-T 任务中这种短视距多模态的案例研究。Diffusion Policy 学习从左侧或右侧接近接触点的可能性相同,而 LSTM-GMM [29] 和 IBC [12] 则表现出偏向一侧,而 BET [42] 则无法致力于一种模式。
Diffusion Policy can express long-horizon multimodality.
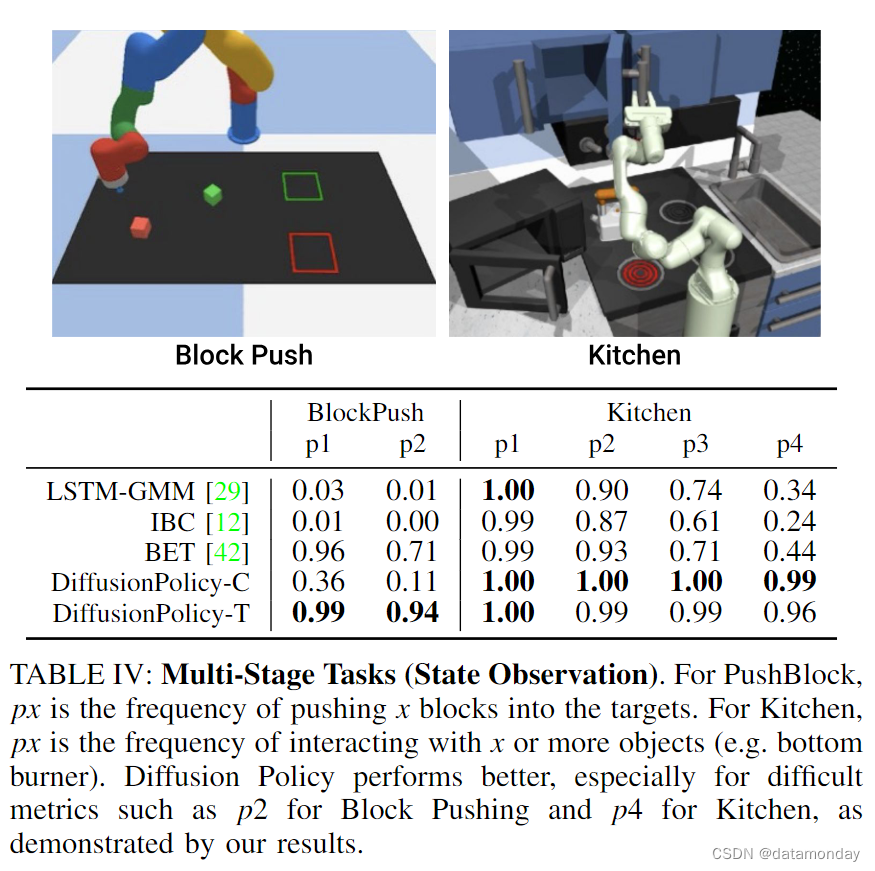
长视距多模态是指以不一致的顺序完成不同的子目标。例如,在 Block Push 任务中推送特定区块的顺序,或者在 Kitchen 任务中与 7 个可能物体互动的顺序都是任意的。我们发现,扩散策略能很好地应对这类多模态问题;它在这两项任务中的表现都远远优于基线:在 Block Push 的 p2 指标上提高了 32%,在 Kitchen 的 p4 指标上提高了 213%。
Diffusion Policy can better leverage position control.
我们的消融研究(图 5)显示,选择位置控制作为扩散策略行动空间的效果明显优于速度控制。然而,我们评估的基线方法中,速度控制的效果最好。这也反映在文献中,大多数现有研究报告都使用了速度控制行动空间[29, 42, 60, 13, 28, 27]。
The tradeoff in action horizon.
正如第四章 C 节所讨论的,行动时间跨度大于 1 有助于策略预测一致的行动并补偿演示中的空闲部分,但过长的时间跨度会因反应时间过慢而降低性能。我们的实验证实了这一点(图 6 左),并发现对于我们测试的大多数任务来说,8 步的行动时间跨度是最佳的。
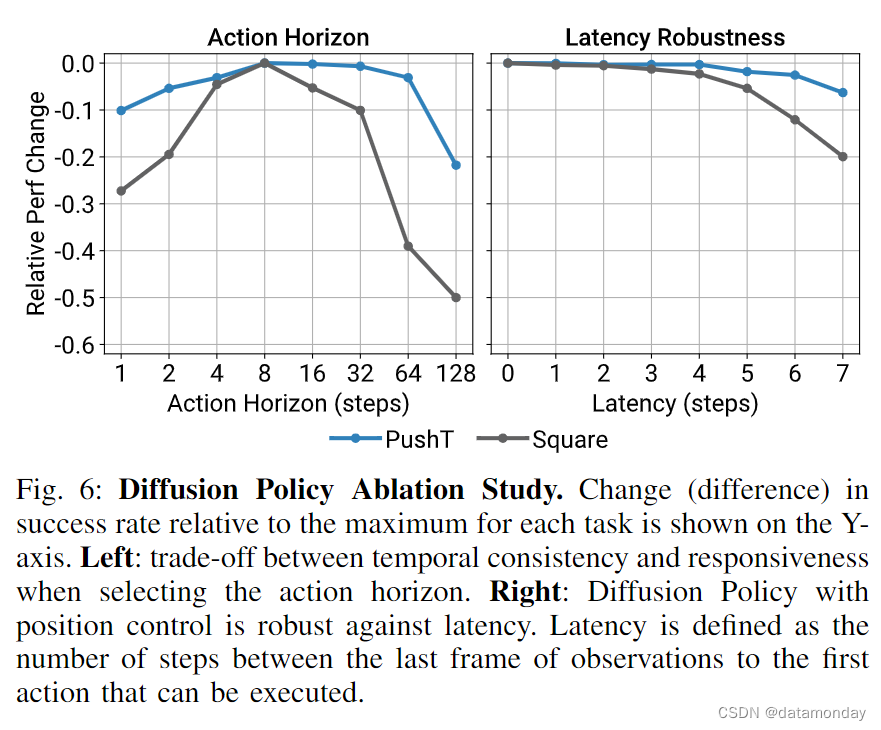
Robustness against latency.
扩散策略采用后退视距位置控制来预测未来的行动序列。这种设计有助于解决由图像处理,策略推理和网络延迟造成的延迟差距。我们利用模拟延迟进行的消融研究表明,扩散策略能够在延迟达 4 步的情况下保持峰值性能(图 6)。我们还发现,速度控制比位置控制受延迟的影响更大,这可能是由于复合误差效应造成的。
Diffusion Policy is stable to train.
我们发现,Diffusion Policy 的最优超参数在不同任务中基本保持一致。相比之下,IBC [12] 容易出现训练不稳定的情况。第 IV-D 章中讨论了该特性。
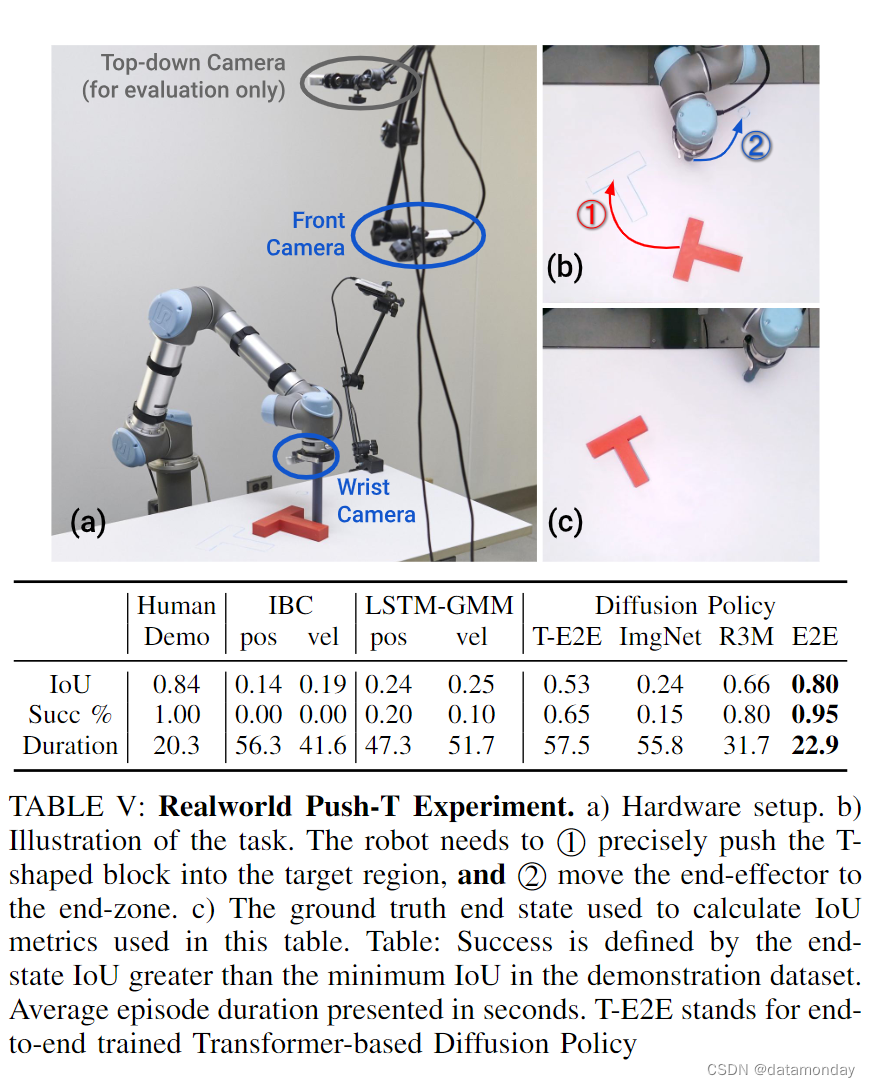
VI. REALWORLD EVALUATION
我们评估了 Diffusion Policy 在现实世界中 2 种硬件设置的 4 项任务中的表现,每种设置的训练数据来自不同的演示者。在真实世界的 PushT 任务中,我们在 2 个架构选项和 3 个视觉编码器选项上对 Diffusion Policy 进行了消融测试;我们还使用位置控制和速度控制动作空间对 2 种基准方法进行了基准测试。在所有任务中,采用 CNN 主干网和端到端训练视觉编码器的 Diffusion Policy 变体都取得了最佳性能。有关任务设置和参数的更多详情,请参阅补充材料。
A. Realworld Push-T Task
现实世界中的 Push-T 比模拟版本要难得多,原因有三点:
- 1)真实世界中的 Push-T 任务是多阶段的。它要求机器人 1 将 T 块推入目标,然后 2 将其末端执行器移动到指定的末端区域,以避免遮挡。
- 2)该策略需要进行微调,以确保 T 块完全进入目标区域,然后再前往末端区域,这就产生了额外的短期多模态性。
- 3)IoU 指标在最后一步测量,而不是取所有步骤的最大值。我们以人类演示数据集中的最小 IoU 指标作为成功率阈值。扩散策略以 10 Hz 的频率预测机器人指令,然后将这些指令线性插值到 125 Hz,供机器人执行。
Result Analysis.
与表现最好的 IBC 和 LSTM-GMM 变体的 0% 和 20% 成功率相比,扩散策略的成功率为 95%,平均 IoU 为 0.8,接近人类水平。图 8 定性地说明了每种方法从相同初始条件开始的行为。我们观察到,在阶段之间的转换过程中表现不佳是基线方法最常见的失败案例,原因是这些部分的多模态性很高,而且决策边界模糊不清。在 20 次评估中,LSTM-GMM 有 8 次(第 3 行)卡在了 T 区块附近,而在 20 次评估中,IBC 有 6 次(第 4 行)过早地离开了 T 区块。由于任务需要,我们没有按照通常的做法从训练数据中删除空闲动作,这也导致 LSTM 和 IBC 倾向于过拟合小动作,并在这项任务中陷入困境。通过补充材料中的视频可以更好地了解结果。

End-to-end v.s. pre-trained vision encoders
我们使用预先训练的视觉编码器(ImageNet [9] 和 R3M[31])测试了扩散策略,如表 V 所示。使用 R3M 的扩散策略取得了 80% 的成功率,但与端到端训练版本相比,它预测的动作抖动,更容易卡住。使用 ImageNet 的扩散策略的结果不尽如人意,行动突然,性能较差。我们发现,端到端训练仍然是将视觉观察纳入 Diffusion Policy 的最有效方法,我们表现最好的模型都是端到端训练的。
Robustness against perturbation
扩散策略对视觉和物理扰动的稳健性在表 V 的实验中进行了单独评估。
- 1)前置摄像头被一只挥动的手挡住了 3 秒钟(左侧一列),但扩散策略尽管表现出一些抖动,但仍能保持正常运行,并将 T 块推到位置上。
- 2)当扩散策略对 T 块的位置进行微调时,我们移动了 T 块。扩散策略立即重新规划,从相反方向推进,消除了扰动的影响。
- 3)第一阶段完成后,我们在机器人前往终点区的途中移动了 T 区块。扩散策略立即改变方向,将 T 型块调整回目标位置,然后继续向终点区前进。这个实验表明,扩散策略可以根据未见的观察结果合成新的行为。

B. Mug Flipping Task

马克杯翻转任务旨在测试 Diffusion Policy 在接近硬件运动学极限的情况下处理复杂三维旋转的能力。如图 10 所示,我们的目标是调整一个随机放置的马克杯的方向,使 ① 杯口朝下 ② 手柄朝左。根据马克杯的初始姿态,演示者可以直接将马克杯放置在所需的方向上,也可以通过推动手柄来旋转马克杯。因此,演示数据集具有高度的多模态性:抓握与推动,不同类型的抓握(正手与反手)或局部抓握调整(围绕马克杯主轴的旋转),这对基线方法的捕捉尤其具有挑战性。
Result Analysis.
扩散策略能够在 20 次试验中以 90% 的成功率完成这项任务。通过视频可以更好地欣赏到捕捉到的丰富行为。虽然从未演示过,但该策略也能在必要时对多个推力进行排序,以进行手柄对齐或重新抓取掉落的杯子。为了进行比较,我们还使用相同数据的子集对 LSTMGMM 策略进行了训练。在 20 个不分布的初始条件下,LSTM-GMM 策略从未正确地与马克杯对齐,并且在所有试验中都无法抓取。
C. Sauce Pouring and Spreading

倒酱汁和撒酱汁任务旨在测试 Diffusion Policy 处理非刚性物体,6 Dof 动作空间和真实世界中周期性动作的能力。我们的 Franka Panda 设置和任务如图 11 所示。6DoF 浇注任务的目标是将满满一勺酱汁浇到披萨面团的中心,其性能由浇注的酱汁掩模与披萨面团中心的一个标称圆圈(图 11 中的绿色圆圈表示)之间的 IoU 来衡量。周期性涂抹任务的目标是在披萨面团上涂抹酱汁,性能以酱汁覆盖率来衡量。各评估事件之间的差异来自于面团和酱碗的随机位置。成功率根据人类的最低表现进行阈值计算。最好在补充视频中查看结果。这两项任务均采用相同的 Push-T 超参数进行训练,并且首次尝试就能获得成功的策略。
倒酱汁任务要求机器人在一段时间内保持静止,以便将粘稠的番茄酱装满勺子。众所周知,由此产生的空闲动作对行为克隆算法来说具有挑战性,因此通常会被避免或过滤掉。在浇注酱汁的过程中,有必要进行微调,以确保覆盖范围并达到所需的形状。
所展示的撒酱汁策略受到人类厨师技术的启发,它既需要长视距循环模式来最大化覆盖范围,又需要短视距反馈来实现均匀分布(因为所使用的番茄酱经常以不可预测大小的块状滴出)。众所周知,周期性运动很难学习,因此通常由专门的行动表示法来解决 [58]。这两项任务都要求策略通过提起勺子/汤匙来自我终止。
Result Analysis.
扩散策略在这两项任务中都取得了接近人类的表现,在浇注任务中的覆盖率为 0.74 比 0.79,在铺展任务中的覆盖率为 0.77 比 0.79。扩散策略能从容应对外部扰动,例如在倒入和摊开过程中用手移动披萨面团。通过补充材料中的视频可以更好地了解结果。
LSTM-GMM 在倒酱汁和撒酱汁任务中的表现都很差。在 20 次浇注试验中,有 15 次在成功舀起酱汁后未能提起勺子。当成功提起勺子时,酱汁倒得偏离了中心。LSTM-GMM 在所有试验中都未能自我终止。我们怀疑 LSTM-GMM 的隐藏状态未能捕捉到足够长的历史记录,因此无法区分任务中的勺蘸和提起阶段。在涂抹酱汁时,LSTMGMM 总是在开始后立即举起勺子,并且在所有 20 次实验中都未能接触到酱汁。
VII. RELATED WORK
无需对行为进行明确编程就能制造出功能强大的机器人,是该领域的一项长期挑战[3, 2, 38]。虽然概念上很简单,但行为克隆在一系列现实世界的机器人任务中,包括操作 [60, 13, 28, 27, 59, 37, 4] 和自动驾驶 [36, 6],都显示出令人惊喜的前景。根据策略结构的不同,目前的行为克隆方法可分为两类。
Explicit Policy.
最简单的显式策略是从世界状态或观测结果直接映射到行动[36, 60, 13, 41, 50, 37, 6]。它们可以通过直接回归损失进行监督,并通过一次前向传递实现高效推理。遗憾的是,这种策略并不适合多模态演示行为建模,在高精度任务中也很难发挥作用 [12]。
- 在对多模态动作分布建模的同时保持方向动作映射的简单性,一种流行的方法是通过将动作空间离散化,将回归任务转换为分类任务 [59, 56, 4]。然而,随着维度的增加,近似连续动作空间所需的分仓数量会呈指数增长。
- 另一种方法是通过使用 MDN [5, 29] 或偏移预测聚类 [42, 43],结合分类和高斯分布来表示连续的多模态分布。然而,这些模型往往对超参数调整很敏感,表现出模式崩溃,在表达高精度行为的能力方面仍然有限[12]。
Implicit Policy.
隐式策略[12, 22]通过使用基于能量的模型(EBM)[24, 10, 8, 14, 11]来定义行动的分布。在这种情况下,每个行动都会被分配一个能量值,行动预测与寻找最小能量行动的优化问题相对应。由于不同的行动可能会被分配较低的能量,隐式策略自然就代表了多模态分布。然而,由于在计算基础 Info-NCE 损失时必须提取负样本,现有的隐式策略 [12] 在训练时并不稳定。
Diffusion Models.
扩散模型是一种概率生成模型,它能将随机采样的噪声迭代细化为来自底层分布的抽样。在概念上,它们也可以理解为学习隐式动作得分的梯度场,然后在推理过程中优化该梯度。扩散模型 [44, 18] 最近已被用于解决各种不同的控制任务 [20, 51, 1]。
其中,Janner 等人[20] 和 Huang 等人[19] 探讨了如何将扩散模型用于规划和推断在给定环境中可能执行的行动轨迹。在强化学习方面,Wang 等人[53] 利用扩散模型进行策略表示,并通过基于状态的观测进行正则化。相比之下,在这项工作中,我们将探索如何在行为克隆的背景下有效地应用扩散模型来制定有效的视觉运动控制策略。为了构建有效的视觉运动控制策略,我们建议将 DDPM 预测高维动作方差的能力与闭环控制相结合,并采用新的动作扩散转换器架构和将视觉输入整合到动作扩散模型中的方法。
Wang 等人[54] 探讨了如何利用从专家示范中学到的扩散模型来增强经典的显式策略,而不直接利用扩散模型作为策略表示。
与我们同时,Pearce 等人[34],Reuss 等人[39]和 Hansen-Estruch 等人[16]对模拟环境中基于扩散的策略进行了补充分析。虽然他们更关注有效的采样策略,利用无分类器指导的目标条件以及强化学习中的应用,而我们则关注有效的行动空间,但我们在模拟环境中的经验发现基本一致。此外,我们在现实世界的大量实验也有力地证明了后退视距预测方案的重要性,在速度和位置控制之间谨慎选择的重要性,实时推理优化的必要性以及物理机器人系统的其他关键设计决策。
VIII. LIMITATIONS AND FUTURE WORK
尽管我们已经在模拟和真实世界系统中证明了扩散策略的有效性,但仍存在一些局限性,未来的工作可以加以改进。首先,我们的实现继承了行为克隆的局限性,例如在演示数据不足的情况下,我们的实现效果并不理想。扩散策略可应用于其他范式,如强化学习 [54, 16],以利用次优数据和负面数据。其次,与 LSTM-GMM 等简单方法相比,扩散策略具有更高的计算成本和推理延迟。我们的动作序列预测方法部分缓解了这一问题,但对于需要高速率控制的任务来说可能还不够。未来的工作可以利用扩散模型加速方法的最新进展,减少所需的推理步骤,如新的噪声时间表[7],推理求解器[23]和一致性模型[47]。
IX. CONCLUSION
在这项工作中,我们评估了基于扩散的机器人行为策略的可行性。通过对模拟和真实世界中的 12 项任务进行综合评估,我们证明了基于扩散的视觉运动策略能够持续,明确地优于现有方法,而且稳定,易于训练。我们的研究结果还强调了关键的设计因素,包括后退视距行动预测,末端执行器位置控制和高效视觉调节,这些因素对于释放基于扩散的策略的全部潜力至关重要。虽然影响行为克隆策略最终质量的因素很多,包括演示的质量和数量,机器人的物理能力,策略架构以及所使用的预训练机制,但我们的实验结果强烈表明,策略结构是行为克隆过程中的一个重要性能瓶颈。我们希望这项工作能推动该领域进一步探索基于扩散的策略,并强调在行为克隆过程中,除了考虑用于策略训练的数据外,还要考虑各个方面的因素。