【大厂AI课学习笔记】【1.6 人工智能基础知识】(3)神经网络
深度学习是机器学习中一种基于对数据进行表征学习的算法。观测值(例如一幅草莓照片)可以使用
多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。
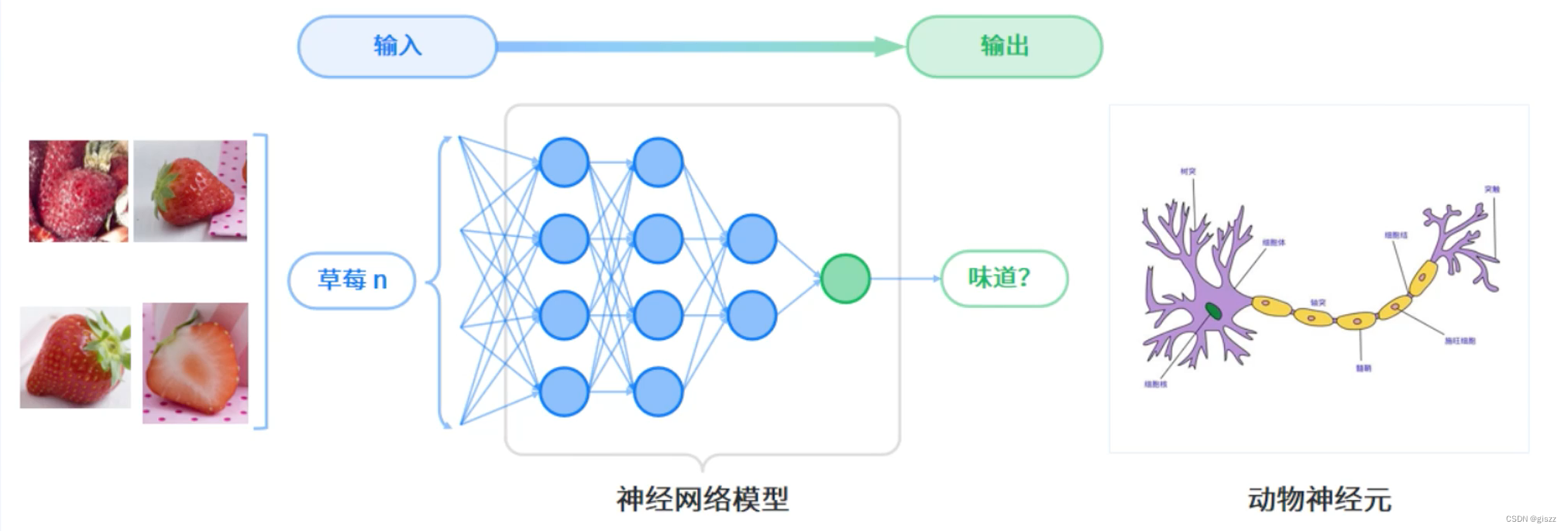
深度学习的最主要特征是使用神经网络作为计算模型。神经网络模型 得名于其对于动物神经元传递信息方式的模拟。
实际上,现在的神经网络模型,和神经,已经没有特别大的关系了。
深度学习的深度,一般指神经网络的层数。一般有2-3个隐藏层;深层神经网络,隐藏层可能有150层;
背景知识梳理:
神经网络的定义
神经网络(Neural Networks)是一种模拟人脑神经元连接方式的计算模型,用于处理信息、学习和识别模式。它由大量相互连接的神经元(或称为节点、单元)组成,每个神经元接收来自其他神经元的输入信号,并根据这些信号产生输出。神经网络通过调整神经元之间的连接权重来学习和适应新数据。
发展脉络
- 起源:神经网络的灵感来源于生物学中的神经系统。1943年,心理学家Warren McCulloch和数学家Walter Pitts提出了第一个基于生物神经系统的计算模型。
- 感知机:1957年,Frank Rosenblatt发明了感知机(Perceptron),这是一种简单的二元线性分类器,可以学习并解决一些基本问题。然而,它不能处理异或(XOR)等非线性问题。
- 反向传播算法:1986年,Rumelhart、Hinton和Williams提出了反向传播(Backpropagation)算法,这是训练多层神经网络的关键技术。它允许网络学习更复杂的非线性模式。
- 深度学习:2006年,Hinton等人提出了“深度学习”的概念,并展示了如何使用无监督预训练和有监督微调来训练深度置信网络(DBN)。这标志着深度学习时代的开始。
- 卷积神经网络(CNN):Yann LeCun等人在1998年提出了卷积神经网络(Convolutional Neural Networks, CNN),用于图像识别。CNN在图像处理任务中表现出色。
- 循环神经网络(RNN):RNN是为了处理序列数据而设计的,它能够捕捉序列中的时间依赖性。RNN在自然语言处理(NLP)和语音识别等领域有广泛应用。
- 生成对抗网络(GAN):2014年,Goodfellow等人提出了生成对抗网络(Generative Adversarial Networks, GAN),它由生成器和判别器两个神经网络组成,用于生成逼真的新数据。
- Transformer架构:2017年,Vaswani等人提出了Transformer架构,它完全基于自注意力机制(self-attention),并在自然语言处理任务中取得了巨大成功,如BERT、GPT等模型。
神经网络的类型与关键技术构成
- 前馈神经网络:信息从输入层单向传递到输出层,没有循环或反馈连接。关键技术包括激活函数(如ReLU、sigmoid、tanh等)、权重初始化和正则化(如L1、L2正则化)。
- 卷积神经网络(CNN):专门用于处理图像数据。关键技术包括卷积层、池化层、全连接层和激活函数。CNN通过卷积层提取图像特征,并通过池化层降低数据维度。
- 循环神经网络(RNN):处理序列数据,如文本或时间序列数据。关键技术包括循环连接、长短时记忆单元(LSTM)和门控循环单元(GRU),用于捕捉序列中的长期依赖性。
- 生成对抗网络(GAN):由生成器和判别器组成,通过对抗性训练生成新数据。关键技术包括生成器和判别器的设计、损失函数的选择以及训练策略。
- 自编码器:用于无监督学习,尝试复制其输入到输出。关键技术包括编码器和解码器的设计,以及损失函数(如均方误差)的选择。
- Transformer架构:基于自注意力机制处理序列数据。关键技术包括多头自注意力机制、位置编码和前馈神经网络层。
如何构建神经网络
构建神经网络通常涉及以下步骤:
- 定义网络结构:确定输入层、隐藏层和输出层的神经元数量以及层与层之间的连接方式。
- 初始化权重和偏置:随机初始化神经元的权重和偏置值。
- 选择激活函数:为神经网络的每一层选择一个激活函数。
- 定义损失函数:根据任务类型(分类、回归等)选择合适的损失函数。
- 选择优化器:如梯度下降、随机梯度下降(SGD)、Adam等,用于更新权重和偏置以最小化损失函数。
- 训练网络:使用训练数据集进行前向传播计算损失,然后通过反向传播算法计算梯度并更新权重和偏置。
- 评估网络性能:使用验证数据集评估网络的性能,并根据需要进行调整(如超参数调优)。
- 应用网络:使用测试数据集评估网络的最终性能,并将其应用于实际任务中。
示例
使用TensorFlow构建简单的神经网络进行MNIST手写数字分类
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.losses import SparseCategoricalCrossentropy
from tensorflow.keras.optimizers import Adam
# 加载MNIST数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 数据预处理:归一化和展平
train_images = train_images.reshape((60000, 28 * 28)) / 255.0
test_images = test_images.reshape((10000, 28 * 28)) / 255.0
# 构建神经网络模型
model = Sequential([
Dense(128, activation='relu', input_shape=(28 * 28,)), # 输入层与第一个隐藏层
Dense(64, activation='relu'), # 第二个隐藏层
Dense(10, activation='softmax') # 输出层,10个类别(0-9)
])
# 编译模型:指定损失函数、优化器和评估指标
model.compile(optimizer=Adam(),
loss=SparseCategoricalCrossentropy(),
metrics=['accuracy'])
# 训练模型
model.fit(train_images, train_labels, epochs=5, batch_size=32)
# 评估模型性能
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f'Test accuracy: {test_acc}')这段代码使用TensorFlow库构建了一个简单的三层神经网络(包括输入层、两个隐藏层和一个输出层),用于对MNIST手写数字数据集进行分类。通过调整网络结构、激活函数、损失函数和优化器等组件,可以进一步优化模型的性能。