【正则表达式】获取html代码文本内所有<script>标签内容
文章目录
- 一. 背景
- 二. 思路与过程
- 1. 正则表达式中需要限定`<script>`开头与结尾
- 2. 增加标签格式的限定
- 3. 不限制`<script>`首尾的内部内容
- 4. 中间的内容不能出现闭合的情况
- 三. 结果与代码
- 四. 正则辅助工具
一. 背景
之前要对学生提交的html代码进行检查,在获取了学生提交的html代码文本后,需要使用正则去截取内部的script标签内容做进一步的检查。
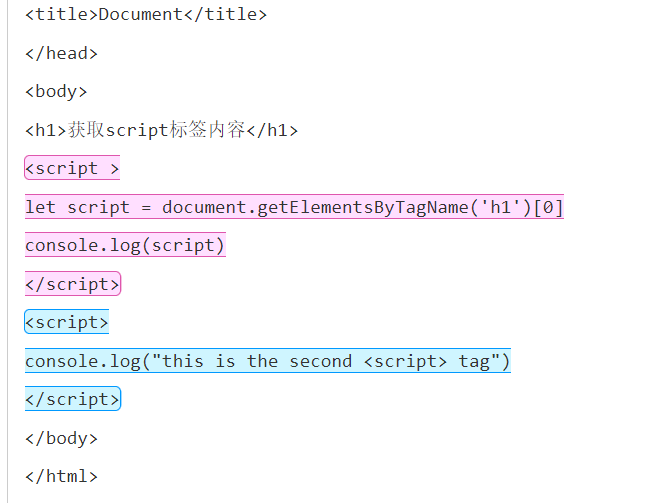
假设得到html文本如下(不是代码),我们要得到全部的script标签内容并提取出来。

看上去不难,但是实际操作起来有一定的坑,最大的问题是学生可能在标签内部写的代码里也出现了“script”或“<script>”文本。就如上方所截图的两个蓝色横线。
二. 思路与过程
为了解决第一个蓝线问题(出现“script”文本)
我们需要依靠html中script标签的闭合特性来实现排除。
所以我们得到了第一个结论:
1. 正则表达式中需要限定<script>开头与结尾
第一个正则:
<script[^>]*><\/script>

这里需要注意:
- 闭合标签中
/符号需要通过\进行转义 - 末尾的三个参数
- 忽略大小写 - i
- 多行模式 - m
- 全局匹配 - g
但是学生仍有可能写成<script >(标签内部有空格)
所以我们需要更进一步限定标签:
2. 增加标签格式的限定
第二个表达式:
<script[^>]*><\/script>
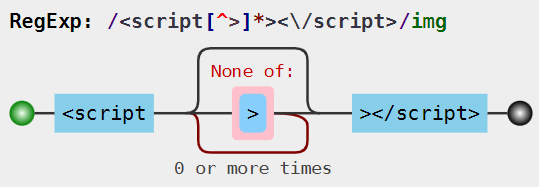
这意味着只要<script 接下来的字符(包括空格)没到闭合>处,就一直囊括进去。
但是这样不能匹配到首尾<script>xxx</script>里面有字符xxx的情况,所以我们还需要放开对里面字符的限制。这一步是最难的一步。
3. 不限制<script>首尾的内部内容
我们试着不限制内部的字符,可以得到第三个表达式:
<script[^>]*>[\w\W]*<\/script>
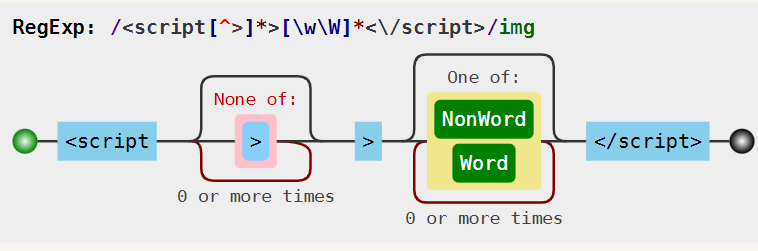

但是,这样会带来新的问题,所有的字符都被囊括进去,无法匹配到所有的标签。
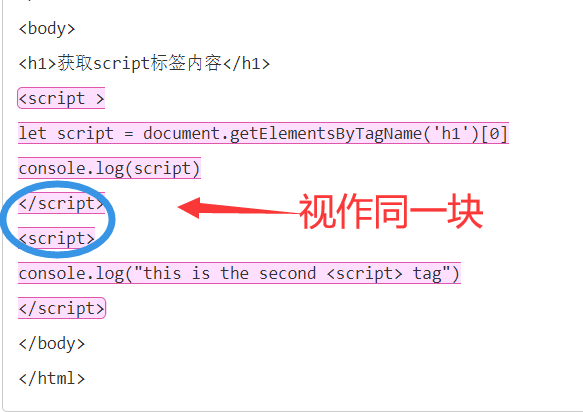
如果在两个script内部增加html代码,那也是不行的。
为了分段获取,也为了解决内容中出现<script>的问题,我们限定:
4. 中间的内容不能出现闭合的情况
我们这么理解:中间的内容,要么不能出现闭合<,如果出现了<,它后面跟随的就不能是/script.
最终正则如下:
/<script[^>]*>([^<]|<(?!\/script))*<\/script>/gmi

三. 结果与代码
使用最后得出的正则,我们得到如下结果:
在实际应用中,我们得到这些标签内容后可以进一步刨去两个首尾标签。
// 这是js的代码
let str = document.body.innerHTML
// 获取script标签内的内容
let reg = /<script[^>]*>([^<]|<(?!\/script))*<\/script>/gmi
let res = str.match(reg)
console.log('匹配的结果:', res)
// 如果具有script标签
if (res != null) {
res.forEach((ele) => {
let startIndex = ele.indexOf('>')
let endIndex = ele.lastIndexOf('<')
ele = ele.slice(startIndex + 1, endIndex)
console.log(ele) //每一段script标签的内容
})
}
下方给出整合的测试代码。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<h1>获取script标签内容</h1>
<script>
let script = document.getElementsByTagName('h1')[0]
console.log(script)
</script>
<script>
console.log("this is the second <script> tag")
</script>
<script>
let str = document.body.innerHTML
console.log(str);
// 获取script标签内的内容
let reg = /<script[^>]*>([^<]|<(?!\/script))*<\/script>/gmi
let res = str.match(reg)
console.log('匹配的结果:', res)
// 如果具有script标签
if (res != null) {
res.forEach((ele) => {
let startIndex = ele.indexOf('>')
let endIndex = ele.lastIndexOf('<')
ele = ele.slice(startIndex + 1, endIndex)
console.log(ele) //每一段script标签的内容
})
}
</script>
</body>
</html>
四. 正则辅助工具
- 正则表达式可视化工具
- 正则表达式在线测试
原文地址:https://blog.csdn.net/HYY_2000/article/details/128985177
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.kler.cn/a/234839.html 如若内容造成侵权/违法违规/事实不符,请联系邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.kler.cn/a/234839.html 如若内容造成侵权/违法违规/事实不符,请联系邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!