SSA优化最近邻分类预测(matlab代码)
SSA-最近邻分类预测matlab代码
麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种新型的群智能优化算法,在2020年提出,主要是受麻雀的觅食行为和反捕食行为的启发。
数据为Excel分类数据集数据。
数据集划分为训练集、验证集、测试集,比例为8:1:1
模块化结构:代码按照功能模块进行划分,清晰地分为数据准备、参数设置、算法处理块和结果展示等部分,提高了代码的可读性和可维护性。
数据处理流程清晰:对数据进行了标准化处理,包括Zscore标准化,将数据分为训练集、验证集和测试集,有助于保证模型训练的准确性和可靠性。
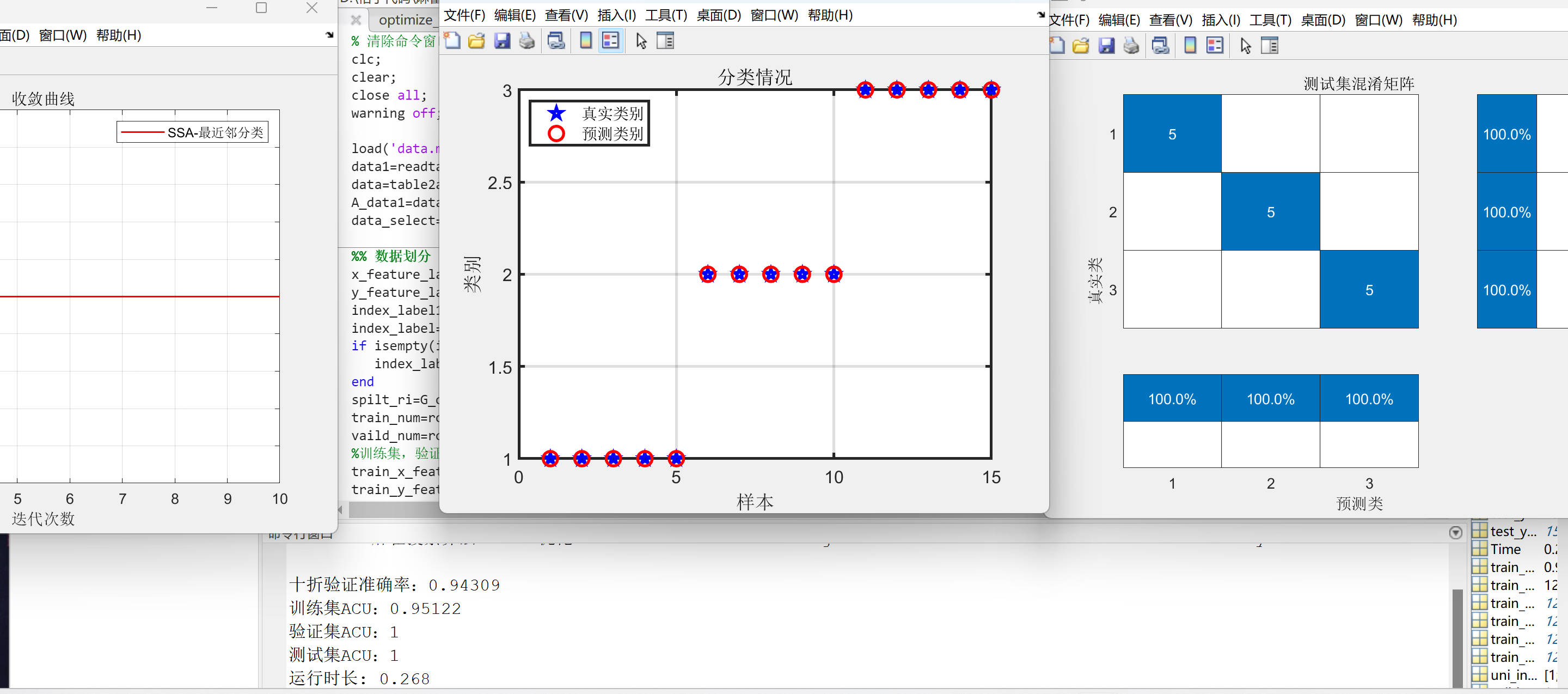
模型评估: 代码中通过十折交叉验证等方法评估了模型的性能,计算了训练集、验证集和测试集的准确率,并输出了十折验证准确率和运行时长。此外,还通过绘制分类情况图和混淆矩阵对模型的分类效果进行了可视化展示,帮助更直观地了解模型的性能和分类结果。
结果可视化: 通过绘制通过绘制SSA寻优过程收敛曲线、分类情况图和混淆矩阵,直观展示了模型的分类效果,有助于对模型性能进行直观分析和比较。
输出定量结果如下:
十折验证准确率:0.94309
训练集ACU:0.95122
验证集ACU:1
测试集ACU:1
运行时长: 0.268
代码有中文介绍。
代码能正常运行时不负责答疑!
代码运行结果如下:


部分代码如下:
% 清除命令窗口、工作区数据、图形窗口、警告
clc;
clear;
close all;
warning off;
load('data.mat')
data1=readtable('分类数据集.xlsx'); %读取数据
data=table2array(data1(:,2:end));
A_data1=data;
data_select=A_data1;
%% 数据划分
x_feature_label=data_select(:,1:end-1); %x特征
y_feature_label=data_select(:,end); %y标签
index_label1=randperm(size(x_feature_label,1));
index_label=G_out_data.spilt_label_data; % 数据索引
if isempty(index_label)
index_label=index_label1;
end
spilt_ri=G_out_data.spilt_rio; %划分比例 训练集:验证集:测试集
train_num=round(spilt_ri(1)/(sum(spilt_ri))*size(x_feature_label,1)); %训练集个数
vaild_num=round((spilt_ri(1)+spilt_ri(2))/(sum(spilt_ri))*size(x_feature_label,1)); %验证集个数
%训练集,验证集,测试集
train_x_feature_label=x_feature_label(index_label(1:train_num),:);
train_y_feature_label=y_feature_label(index_label(1:train_num),:);
vaild_x_feature_label=x_feature_label(index_label(train_num+1:vaild_num),:);
vaild_y_feature_label=y_feature_label(index_label(train_num+1:vaild_num),:);
test_x_feature_label=x_feature_label(index_label(vaild_num+1:end),:);
test_y_feature_label=y_feature_label(index_label(vaild_num+1:end),:);