【数据挖掘】实验3:常用的数据管理
实验3:常用的数据管理
一:实验目的与要求
1:熟悉和掌握常用的数据管理方法,包括变量重命名、缺失值分析、数据排序、随机抽样、字符串处理、文本分词。
二:实验内容
【创建新变量】
方法1:
| mydata <- iris[,1:2] mydata$square <- mydata$Sepal.Length*mydata$Sepal.Width |

方法2:
| rm(list=ls()) mydata <- iris[,1:2] attach(mydata) mydata$square <- Sepal.Length*Sepal.Width detach(mydata) |
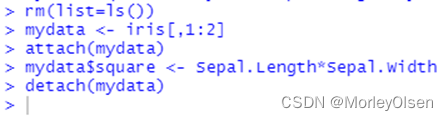
方法3:使用DT包(现在已经无法从CRAN下载)
| rm(list=ls()) mydata <- iris[,1:2] mydata <- transform(mydata,square=Sepal.Length*Sepal.Width) library(DT) datatable(mydata,rownames=F) |
【变量重新编码】
Eg1:
| rm(list = ls()) mydata <- mtcars (mydata$am <- ifelse(mydata$am == 0,'automatic','manual')) |

Eg2:将99岁这样的年龄重编码为缺失值
| manager <- c(1,2,3,4,5) date <- c('10/24/08','10/28/08','10/1/08','10/12/08','5/1/09') country <- c('US','US','UK','UK','UK') gender <- c('M','F','F','M','F') age <- c(32,45,25,39,99) q1 <- c(5,3,3,3,2) q2 <- c(4,5,5,3,2) q3 <- c(5,2,5,4,1) q4 <- c(5,5,5,NA,2) q5 <- c(5,5,2,NA,1) leadership <- data.frame(manager,date,country,gender,age,q1,q2,q3,q4,q5, stringsAsFactors = FALSE) leadership$age[leadership$age==99] <- NA |
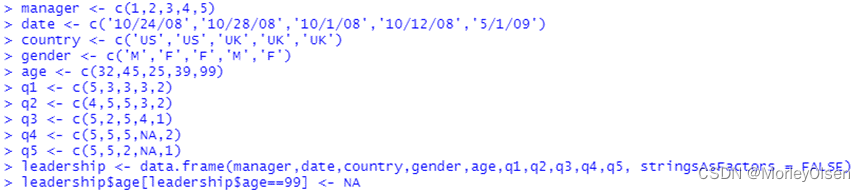
Eg3:将年龄离散化,将leadership中age(连续型变量)重新编码为类别型变量agecat
| leadership$agecat[leadership$age > 66] <- "Elder" leadership$agecat[leadership$age > 40 & leadership$age<66] <- "Middle Aged" leadership$agecat[leadership$age >=18 & leadership$age<=40] <- "Young" |

Eg4:同上,但使用within函数
| leadership <- within(leadership, {agecat <- NA agecat[age > 75] <- 'Elder' agecat[age >-55 & age <=75] <- 'Middle Aged' agecat[age < 55] <- 'Young'}) |

【变量的重命名】
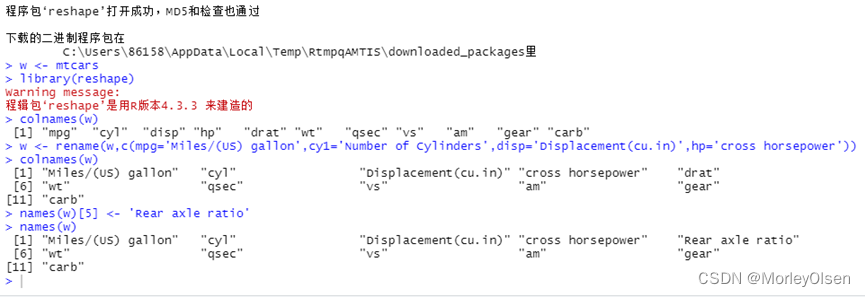
Eg1:
| install.packages("reshape", repos = "http://cran.r-project.org") w <- mtcars library(reshape) colnames(w) w <- rename(w,c(mpg='Miles/(US) gallon',cy1='Number of Cylinders',disp='Displacement(cu.in)',hp='cross horsepower')) colnames(w) names(w)[5] <- 'Rear axle ratio' names(w) |
【数据排序】
Eg1:
| x <- c(19, 84, 64, 2) order(x) rank(x) sort(x) |

【随机抽样】
Eg1:
| install.packages("sampling",repos = "http://cran.r-project.org") library(sampling) LETTERS (s<-srswor(10,26)) (obs<-((1:26)[s!=0])) (sample<-LETTERS[obs]) |

Eg2:
| library(sampling) LETTERS (s<-srswr(10,26)) (obs<-((1:26)[s!=0])) (n<-s[s!=0]) (obs<-rep(obs,times=n)) (sample<-LETTERS[obs]) |

Eg3:
| library(sampling) LETTERS sample(LETTERS,5,replace=TRUE) sample(LETTERS,5,replace=FALSE) |

Eg4:
| library(sampling) LETTERS n<-sample(2,26,replace=T,prob=c(0.7,0.3)) n (sample1 <- LETTERS[n==1]) (sample2 <- LETTERS[n==2]) |

【数学函数】
Eg1:
| x <- c(1.12, -1.234, 3.1, 2.3, -4) abs(x) sqrt(25) ceiling(x) floor(x) round(x,digits=1) signif(x,digits=1) |

【统计函数】
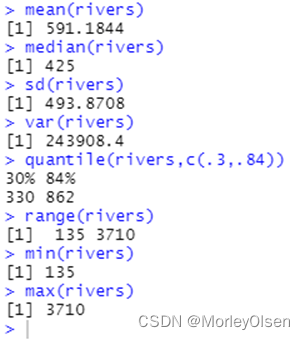
方法1:
| mean(rivers) median(rivers) sd(rivers) var(rivers) quantile(rivers,c(.3,.84)) range(rivers) min(rivers) max(rivers) |
【基本函数】
Eg1:鸢尾花数据集操作
| head(iris) colnames(iris) names(iris) sum(iris$Sepal.Length) max(iris$Sepal.Length) min(iris$Sepal.Length) which.max(iris$Sepal.Length) which.min(iris$Sepal.Length) range(iris$Sepal.Length) |

【高级函数】
Eg1:鸢尾花数据集操作
| (x<-rnorm(1)) round(x,2) index<-sample(1:150,30) iris1<-iris$Sepal.Length[index] sort(iris1) order(iris1) |

【概率函数】
Eg1:
| data<-rnorm(20) data dnorm(data) pnorm(data) qnorm(0.9,mean=0,sd=1) |

【字符串操作】
Eg1:字符串长度
| data<-'R语言是一门艺术' nchar(data) |

Eg2:字符串合并
| data1<-'用心去体会' paste(data,data1,sep="") |

Eg3:paste函数合并
| paste("AB",1:5,sep="") x<-list(a="1st",b="2nd",c="3rd") y<-list(d=1,e=2) paste(x,y,sep="-") paste(x,y,sep="-",collapse=";") paste(x,collapse=",") |

Eg4:分割字符串
| data<-c("2016年1月1日","2016年2月1日") strsplit(data,"年") strsplit(data,"年")[[1]][1] |

Eg5:字符串替换
| txt <- c("Whatever","is","worth","doing","is","worth","doing","well") sub("[tr]","k",txt) gsub("[tr]","k",txt) |

Eg6:
| (x<-'abadfa') (substr(x,2,4)) substr(x,2,4)<-'kkk' x |

Eg7:
| (x<-'abadfaf') (x<-chartr('k','h',x)) (x<-chartr('faf','tBt',x)) (x<-chartr('faf','ttt',x)) (x<-chartr('af','Tt',x)) |

【jiebaR】
Eg1:(由于未找到data.txt文件,因此未对文件进行分词)
| install.packages("jiebaR",repos = "http://cran.r-project.org") library(jiebaR) mixseg <- worker() mpseg <- worker(type="mp") hmmseg <- worker(type="hmm") word = "人们都说桂林山水甲天下" mixseg <= word mpseg <= word hmmseg <= word segment(word,mixseg) qseg <= word qseg[word] |

【apply家族】
Eg1:鸢尾花维度处理
| apply(iris[,1:4],1,mean) sapply(iris,mean) lapply(iris[,1:4],mean) |


Eg2:对列表x的每一个元素计算均值
| x <- list(a=1:5,b=exp(0:3)) lapply(x,mean) |

Eg3:计算矩阵x各行各列的均值
| x<-matrix(1:20,ncol=4) x apply(x,1,mean) apply(x,2,mean) |

Eg4:列表list中的元素与数字1-3连接,并以矩阵和列表两种形式输出
| list<-list(c("a","b","c"),c("A","B","C")) list sapply(list,paste,1:3,simplify=T) sapply(list,paste,1:3,simplify=F) |

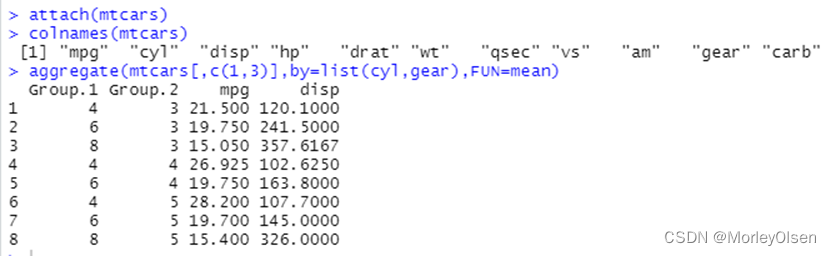
【数据汇总统计】
Eg1:
| attach(mtcars) colnames(mtcars) aggregate(mtcars[,c(1,3)],by=list(cyl,gear),FUN=mean) |
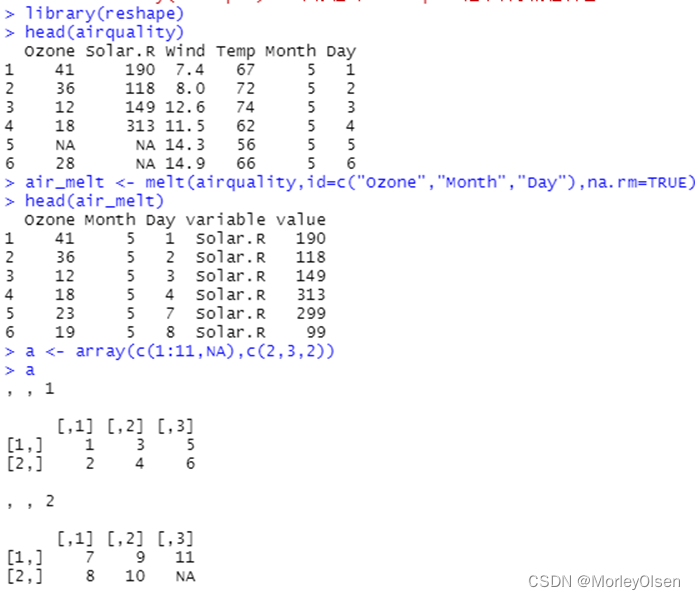
【数据融合】
Eg1:melt函数融合数据框和数组
| library(reshape) head(airquality) air_melt <- melt(airquality,id=c("Ozone","Month","Day"),na.rm=TRUE) head(air_melt) a <- array(c(1:11,NA),c(2,3,2)) a a_melt <- melt(a,na.rm=TRUE,varnames=c("X","Y","Z")) a_melt |

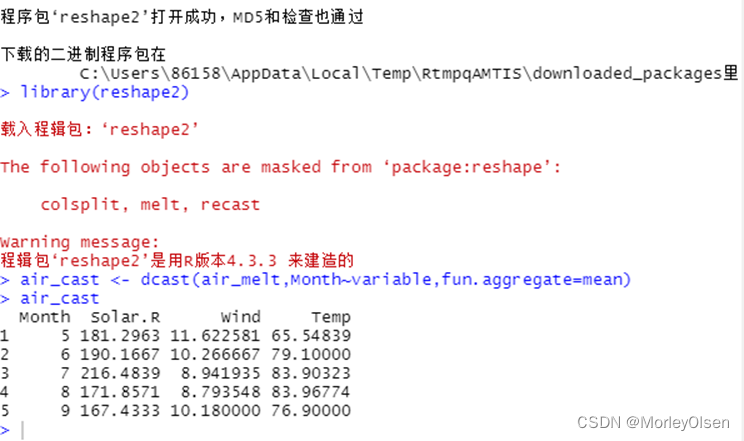
【数据重塑】
Eg1:
| install.packages("reshape2") library(reshape2) air_cast <- dcast(air_melt,Month~variable,fun.aggregate=mean) air_cast |
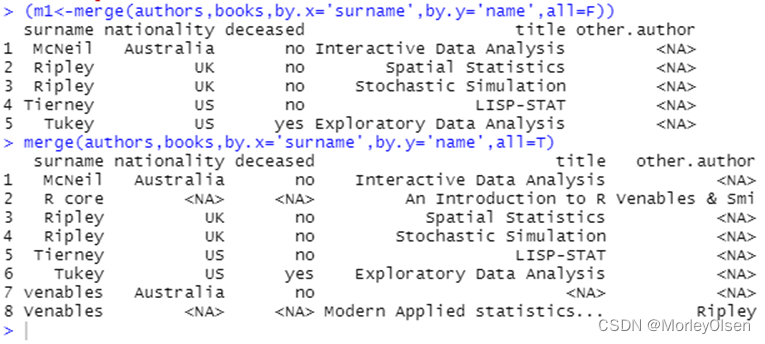
【粘贴数据结构】
Eg1:数据框加载
| authors <- data.frame( surname=I(c('Tukey','venables','Tierney','Ripley','McNeil')), nationality=c('US','Australia','US',"UK",'Australia'), deceased=c('yes',rep('no',4)) ) books<-data.frame( name=I(c('Tukey','Venables','Tierney','Ripley','Ripley','McNeil','R core')), title=c('Exploratory Data Analysis', 'Modern Applied statistics...', 'LISP-STAT', 'Spatial Statistics', 'Stochastic Simulation', 'Interactive Data Analysis', 'An Introduction to R'), other.author = c(NA,'Ripley',NA,NA,NA,NA,'Venables & Smi') ) |

Eg2:merge函数
| (m1<-merge(authors,books,by.x='surname',by.y='name',all=F)) merge(authors,books,by.x='surname',by.y='name',all=T) |
【转换函数】
Eg1:transform函数
| head(airquality) head(transform(airquality,Ozone=-Ozone)) head(transform(airquality,new=-Ozone)) |

【while循环语句】
Eg1:
| pv <- c(1,1,2,3,1,1,15,7,18) i<-1 result<-"" length(pv) while(i<=length(pv)){ if(pv[i]<=5){ result[i] <- "初级用户" }else if(pv[i]<=15){ result[i] <- "中级用户" }else{ result[i] <- "高级用户" } i <- i+1 } result |

【for循环】
Eg1:不知道循环次数
| pv <- c(1,1,2,3,1,1,15,7,18,1,1,2,3,1,1) result<-"" m<-1 for(i in pv){ if(i<=5){ result[m]<-"初级用户"; }else if(i<=15){ result[m]<-"中级用户"; }else{ result[m]<-"高级用户"; } m<-m+1 } result |

Eg2:知道循环次数
| pv <- c(1,1,2,3,1,1,15,7,18,1,1,2,3,1,1) result<-"" for(i in 1:length(pv)){ if(pv[i]<=5){ result[i]<-"初级用户"; }else if(pv[i]<=15){ result[i]<-"中级用户"; }else{ result[i]<-"高级用户"; } } result |

【repeat-break循环】
Eg1:
| pv <- c(1,1,2,3,1,1,15,7,18) i<-1 result<-"" repeat{ if(i>length(pv)){ break } if(pv[i]<=5){ result[i]<-"初级用户" }else if(pv[i]<=15){ result[i]<-"中级用户" }else{ result[i]<-"高级用户" } i<-i+1 } result |

【自定义函数】
Eg1:自定义一个求两数之和的函数
| s <- function(x,y){ a<-x+y return(a) } s(2,3) |

三:课堂练习
【练习1】PPT-05第27页
案例1:
| scale(cars,center=T,scale=F) # centrialize scale(cars,center=T,scale=T) # standarlize diff(cars[,1]) # differentiate |
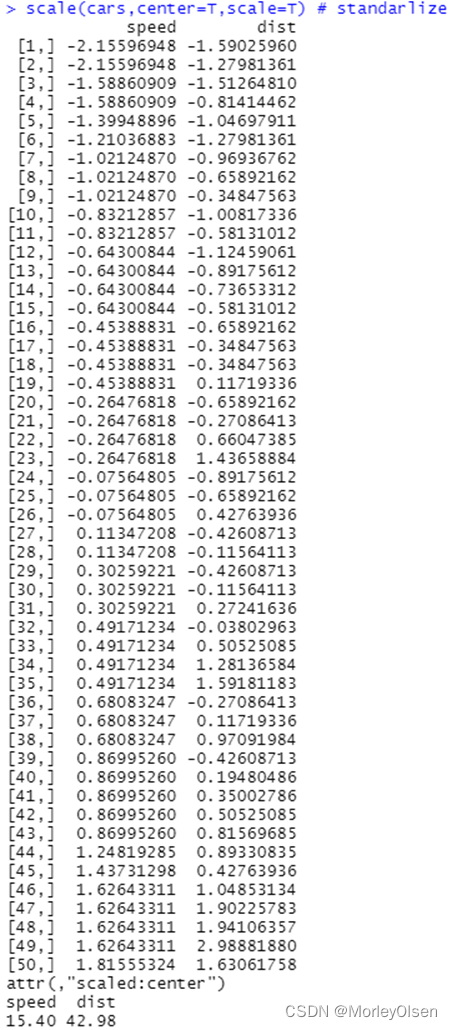

案例2:
| date <- c("2016-01-27","2016-02-27") difftime(date[2],date[1],units="days") difftime(date[2],date[1],units="weeks") |

【练习2】PPT-05第27页
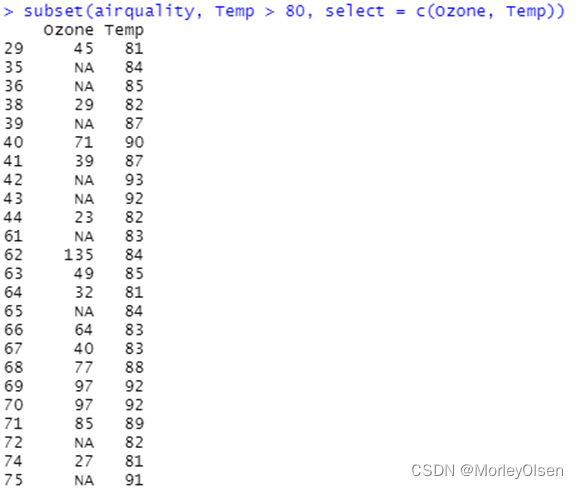
案例1:subset函数选定特定行或子集
| subset(airquality, Temp > 80, select = c(Ozone, Temp)) |
案例2:
| subset(airquality, Day == 1, select=-Temp) |

案例3:
| subset(airquality, select = Ozone:Wind) |
详细结果如下表所示
| Ozone Solar.R Wind 1 41 190 7.4 2 36 118 8.0 3 12 149 12.6 4 18 313 11.5 5 NA NA 14.3 6 28 NA 14.9 7 23 299 8.6 8 19 99 13.8 9 8 19 20.1 10 NA 194 8.6 11 7 NA 6.9 12 16 256 9.7 13 11 290 9.2 14 14 274 10.9 15 18 65 13.2 16 14 334 11.5 17 34 307 12.0 18 6 78 18.4 19 30 322 11.5 20 11 44 9.7 21 1 8 9.7 22 11 320 16.6 23 4 25 9.7 24 32 92 12.0 25 NA 66 16.6 26 NA 266 14.9 27 NA NA 8.0 28 23 13 12.0 29 45 252 14.9 30 115 223 5.7 31 37 279 7.4 32 NA 286 8.6 33 NA 287 9.7 34 NA 242 16.1 35 NA 186 9.2 36 NA 220 8.6 37 NA 264 14.3 38 29 127 9.7 39 NA 273 6.9 40 71 291 13.8 41 39 323 11.5 42 NA 259 10.9 43 NA 250 9.2 44 23 148 8.0 45 NA 332 13.8 46 NA 322 11.5 47 21 191 14.9 48 37 284 20.7 49 20 37 9.2 50 12 120 11.5 51 13 137 10.3 52 NA 150 6.3 53 NA 59 1.7 54 NA 91 4.6 55 NA 250 6.3 56 NA 135 8.0 57 NA 127 8.0 58 NA 47 10.3 59 NA 98 11.5 60 NA 31 14.9 61 NA 138 8.0 62 135 269 4.1 63 49 248 9.2 64 32 236 9.2 65 NA 101 10.9 66 64 175 4.6 67 40 314 10.9 68 77 276 5.1 69 97 267 6.3 70 97 272 5.7 71 85 175 7.4 72 NA 139 8.6 73 10 264 14.3 74 27 175 14.9 75 NA 291 14.9 76 7 48 14.3 77 48 260 6.9 78 35 274 10.3 79 61 285 6.3 80 79 187 5.1 81 63 220 11.5 82 16 7 6.9 83 NA 258 9.7 84 NA 295 11.5 85 80 294 8.6 86 108 223 8.0 87 20 81 8.6 88 52 82 12.0 89 82 213 7.4 90 50 275 7.4 91 64 253 7.4 92 59 254 9.2 93 39 83 6.9 94 9 24 13.8 95 16 77 7.4 96 78 NA 6.9 97 35 NA 7.4 98 66 NA 4.6 99 122 255 4.0 100 89 229 10.3 101 110 207 8.0 102 NA 222 8.6 103 NA 137 11.5 104 44 192 11.5 105 28 273 11.5 106 65 157 9.7 107 NA 64 11.5 108 22 71 10.3 109 59 51 6.3 110 23 115 7.4 111 31 244 10.9 112 44 190 10.3 113 21 259 15.5 114 9 36 14.3 115 NA 255 12.6 116 45 212 9.7 117 168 238 3.4 118 73 215 8.0 119 NA 153 5.7 120 76 203 9.7 121 118 225 2.3 122 84 237 6.3 123 85 188 6.3 124 96 167 6.9 125 78 197 5.1 126 73 183 2.8 127 91 189 4.6 128 47 95 7.4 129 32 92 15.5 130 20 252 10.9 131 23 220 10.3 132 21 230 10.9 133 24 259 9.7 134 44 236 14.9 135 21 259 15.5 136 28 238 6.3 137 9 24 10.9 138 13 112 11.5 139 46 237 6.9 140 18 224 13.8 141 13 27 10.3 142 24 238 10.3 143 16 201 8.0 144 13 238 12.6 145 23 14 9.2 146 36 139 10.3 147 7 49 10.3 148 14 20 16.6 149 30 193 6.9 150 NA 145 13.2 151 14 191 14.3 152 18 131 8.0 153 20 223 11.5 |
【练习3】PPT-05第37页
案例1:求给定向量中的偶数个数
| Num <- function(x){ k=0 stopifnot(is.numeric(x)) for(i in x){ if(i %% 2==0){ k=k+1 } } return(k) } Num(1:9) |

【练习4】PPT-05第39页
案例1:自编函数计算标准差代码
| BZC <- function(x){ stopifnot(is.numeric(x)) stopifnot(length(x)>1) avg<-mean(x) sum=0 for(i in x){ sum=sum+(i-avg)**2 } return(sqrt(sum/length(x))) } BZC(c(1:5)) |
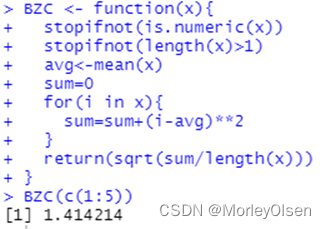
函数设计流程:

四:实验知识点总结
0:PPT-05上第29页中【na.rm=FALSE】的作用是——保留数据集中的缺失值,并尝试计算包含这些缺失值的统计量。当na.rm=TRUE时,函数会在计算统计量之前从数据集中删除所有的缺失值。
1:在变量的重命名中,rename函数可修改数据库和列表(不改变原数据集中的变量名),不能修改矩阵;names函数可修改数据库和列表(改变原数据集中的变量名),不能修改矩阵;colnames函数和rownames函数可修改矩阵和数据库的行名和列名。
2:数据排序函数的区别。

3:随机抽样函数的区别。

4:常用的数学函数。
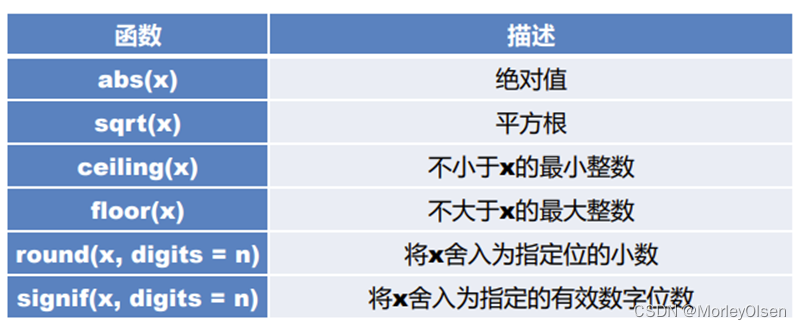
5:常用的统计函数。
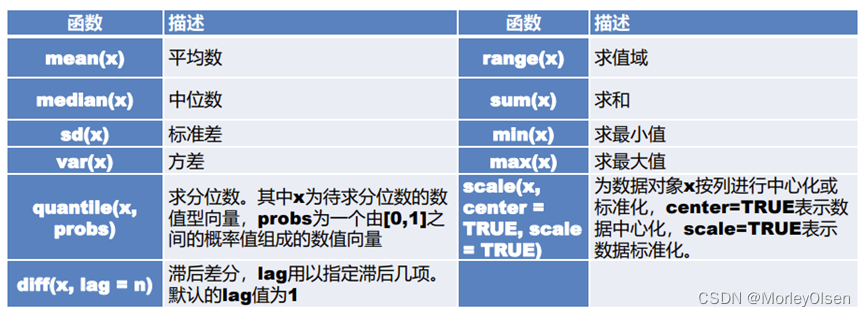
6:常用的高级数学函数。

7:apply家族的使用方法。

8:函数体的组成部分。

五:遇到的问题和解决方法
问题&解决1:reshape2和reshape不是一个依赖包,只载入reshape包而不载入reshape2包,无法调用reshape2中的封装功能。因此,需要看清楚封装功能所来源的依赖包是哪一个,再进行调用。
问题&解决2:如果当前使用的镜像源太卡,会导致install.packages()失败。此时需要使用【chooseCRANmirror()】,并选择新的镜像源,然后再进行依赖包的安装和载入。或者通过例如【options(repos = c(CRAN = "https://cloud.r-project.org/"))】的方式更换。
问题&解决3:PPT中的思考题通过以下网页进行学习。
R语言数据框中的缺失值_na.rm=true什么意思-CSDN博客
https://www.cnblogs.com/chenwenyan/p/16384901.html