AIGC元年大模型发展现状手册
零、AIGC大模型概览
AIGC大模型在人工智能领域取得了重大突破,涵盖了LLM大模型、多模态大模型、图像生成大模型以及视频生成大模型等四种类型。这些模型不仅拓宽了人工智能的应用范围,也提升了其处理复杂任务的能力。a.) LLM大模型通过深度学习和自然语言处理技术,实现了对文本的高效理解和生成;b.) 多模态大模型则能够整合文本、图像、声音等多种信息,实现跨模态的交互和理解;c.) 图像/视频生成大模型则进一步将AI技术应用于视觉内容创作,为用户提供了全新的创作以及内容消费体验,给商业应用提供了无限畅想的可能性,将有机会重塑社交、短视频等领域的现象级APP。
随着技术的不断进步,AIGC大模型正朝着更加智能化、精细化和个性化的方向发展。一方面,模型将不断优化算法,提升处理速度和精度,以满足日益增长的数据处理需求;另一方面,模型将更加关注用户个性化需求,提供更加精准、符合用户口味的内容生成服务。此外,跨模态融合也将成为未来的发展趋势,各种模态之间的信息将更加无缝地整合,为用户提供更加自然、流畅的交互体验。
AIGC大模型在多个领域都有着广阔的应用前景。基于 LLM 大模型的智能客服、语音助手和文本生成等应用有望成为主流。在内容创作领域,图像生成大模型和视频生成大模型将助力创作者快速生成高质量的视觉内容,降低创作门槛,提高创作效率,可用于创意设计、影视制作等领域。多模态大模型可以应用于图像与文本之间的关联分析和生成,为视觉搜索、智能图像编辑、图像问答、同声翻译等领域提供强大支持。此外,AIGC大模型还可应用于医疗、金融等多个行业,推动行业的智能化升级。
随着技术的不断进步和应用场景的不断拓展,AIGC大模型将逐渐渗透到人们生活的各个方面,成为推动社会发展的重要力量。接下来让我梳理下现有的四大类型大模型技术概览以及相关应用前景。
一、大语言模型
1.)技术演进
历史重要节点:谷歌预训练模型Bert(开源预训练) -> OpenAI大模型ChatGPT(闭源大模型) -> LLaMA(开源大模型)。
当然目前LLM依然还在百家争鸣中,语言模型技术发展图鉴,出自最新的一篇survey:Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond,https://arxiv.org/pdf/2304.13712.pdf。
技术文章:LLM技术发展、能力增强模式和应用杂谈(一) - 知乎,人工智能 LLM 革命破晓:一文读懂当下超大语言模型发展现状 /麦克船长LLM革命系列2 - 知乎
行业观察:2023 年人工智能现状报告-36氪
2.)时间机器成本
百B级别:LLaMA 3个月,380+ A100 80G,GPT-3 2个月,1000+ A100 80G;初步估算,150左右A100卡年,大概3000千万+购买卡,算上平摊折旧,预计每次训练耗费超过1000万。
千B级别GPT-4:1800B参数,13万亿token训练,6300万美元。
3.)典型微调技术
SFT(不同程度参数放开学习,或者经典的额外低参数学习lora、adapter等)
prompt engineering
对齐学习(RLHF)
4.)开源LLM
a.)第一梯队
LLaMA 2,Meta的LLaMA 2 于 2023 年 7 月实现用于研究和商业用途,是一个预训练的生成文本模型,它已通过来自人类反馈的强化学习 (RLHF) 进行了微调。它是一种生成文本模型,可以用作聊天机器人,可以适应各种自然语言生成任务,包括编程任务。Meta 已经推出了 LLaMA 2, Llama Chat, 和 Code Llama 的开放定制版本。2023年国内多家企业,基于LLaMA已经加速完成了很多大模型的储备工作,LLaMA降低了国内自有大模型研发的门槛。
Falcon, 阿拉伯技术创新研究所的Falcon 40B曾在 Hugging Face 的开源大型语言模型排行榜上排名 #1Falcon 180B 于 2023 年 9 月发布,可以接受 1800 亿个参数和 3.5 万亿个 Token。凭借这种令人印象深刻的计算能力, Falcon 180B 在各种 NLP 任务中已经超过了 LLaMA 3 和 GPT-5.2,而 Hugging Face 表明它可以与谷歌的 PaLM 2 相媲美,后者是为 Google Bard 提供支持的 LLM。虽然免费用于商业和研究用途,但重要的是要注意 Falcon 180B 需要珍贵的计算资源才能运行。
XGen,Salesforce于 2023年 7 月推出了 XGen-7B LLM。根据作者的说法,大多数开源 LLM 专注于提供信息有限的大答案(即几乎没有上下文的简短提示)。XGen-7B 背后的想法是构建一个支持更长上下文窗口的工具。特别是,XGen (XGen-7B-8K-base) 的最高级方差允许 8K 上下文窗口,即输入和输出文本的累积大小。效率是 XGen 的另一个重要优先事项,它只使用 7B 参数进行训练,远低于大多数强大的开源 LLM,如 LLaMA 2 或 Falcon。尽管体积相对较小,但 XGen 仍然可以提供出色的效果。该模型可用于商业和研究目的,但 XGen-7B-{4K,8K}-inst 变体除外,该变体已在教学数据和 RLHF上进行了训练,并在非商业许可下发布。
BLOOM,Hugging Face于 2022 年推出,经过与来自 70+ 个国家的志愿者为期一年的合作项目,BLOOM 是一个自回归 LLM,经过训练,可以使用工业规模的计算资源在大量文本数据上从提示中连续文本化。BLOOM 拥有 176 亿个参数,是最强大的开源 LLM 之一,能够以 46 种语言和 13 种编程语言提供连贯准确的文本。每个人都可以访问源代码和训练数据,以便运行、研究和改进它。BLOOM 可以通过 Hugging Face 生态系统免费使用。
BERT(双向transformer),开启预训练模型时代,由OpenAI接力研发ChatGPT(单向transformer)进入大模型时代。BERT(Bidirectional Encoder Representations from Transformers)于 2018 年由 Google 作为开源 预训练模型推出,在许多自然语言处理任务中迅速实现了最先进的性能。在 2020 年,谷歌宣布已通过 70 多种语言的 Google 搜索采用了 Bert。目前有数以千计的开源、免费和预训练的 Bert 模型可用于特定用例,例如情感分析、临床笔记分析和有害评论检测。
b.)第二梯队
OPT,2022 年发布的 Open Pre-trained Transformers(OPT)语言模型标志着 Meta 通过开源解放 LLM 竞赛战略的又一个重要里程碑。OPT 包括一套仅解码器的预训练转换器,参数范围从 125M 到 175B。OPT-175B 是市场上最先进的开源 LLM 之一,是 GPT 最强大的兄弟,性能与 GPT-3 相似。预训练模型和源代码都向公众开放。然而,如果你正在考虑开发一家具有 LLM 的人工智能驱动型公司,你最好考虑另外的模型,因为OPT-175B 是在非商业许可下发布的,只允许将该模型用于研究。
GPT-NeoX 和 GPT-J 由非营利性 AI 研究实验室 EleutherAI 的研究人员开发,是 GPT 的两个很好的开源替代品。GPT-NeoX 有 20 亿个参数,而 GPT-J 有 6 亿个参数。尽管大多数高级 LLM 可以使用超过 100 亿个参数进行训练,但这两个 LLM 仍然可以提供高精度的结果。他们已经接受了来自不同来源的 22 个高质量数据集的训练,这些数据集使它们能够在多个领域和许多用例中使用。与 GPT-3 相比,GPT-NeoX 和 GPT-J 尚未使用 RLHF 进行训练。任何自然语言处理任务都可以使用 GPT-NeoX 和 GPT-J 执行,从文本生成和情感分析到研究和营销活动开发。这两个 LLM 都可以通过 NLP Cloud API 免费获得。
Vicuna-13B 是一个开源对话模型,通过使用从 ShareGPT 收集的用户共享对话对 LLaMa 13B 模型进行微调而训练而来。作为一款智能聊天机器人,Vicuna-13B 的应用不胜枚举,下面在客户服务、医疗、教育、金融、旅游/酒店等不同行业进行说明。使用 GPT-4 作为评委的初步评估显示,Vicuna-13B 达到了 ChatGPT 和 Google Bard 的 90% 以上质量,然后在超过 90% 的情况下优于 LLaMa 和 Alpaca 等其他模型。
二、多模态大模型
1.)现有案例
OpenAI:GPT4-V,背书强。来自阿卜杜拉国王科技大学开源MiniGPT-4,主要强调高效,省钱,只训练新加的一个线性层,据说4张A100训10小时。
微软:LLaVA是一个开源 LMM(MLLM),由威斯康星大学麦迪逊分校、微软研究院和哥伦比亚大学联合开发。该模型旨在提供多模态的开源版本 GPT4.
Meta:ImageBind是由 Meta 制作的开源模型,模拟人类感知关联多模态数据的能力。该模型集成了六种模式:文本、图像/视频、音频、3D 测量、温度数据和运动数据,学习跨这些不同数据类型的统一表示。
Meta:SeamlessM4T 是 Meta 设计的多模态模型,旨在促进多语言社区之间的沟通。 SeamlessM4T 擅长翻译和转录任务,支持语音到语音、语音到文本、文本到语音和文本到文本翻译。
谷歌:Gemini 的核心采用基于 Transformer 的架构,类似于 GPT-3 等成功的 NLP 模型中采用的架构。 然而,Gemini 的独特之处在于它能够处理和整合多种形式的信息,包括文本、图像和代码。 这是通过一种称为 跨模态注意力,它允许模型学习不同类型数据之间的关系和依赖关系。
谷歌:Flamingo 具备强大的多模态上下文少样本学习能力。Flamingo 走的技术路线是将大语言模型与一个预训练视觉编码器结合,并插入可学习的层来捕捉跨模态依赖,其采用图文对、图文交错文档、视频文本对组成的多模态数据训练,在少样本上下文学习方面表现出强大能力。但是,Flamingo 在训练时只使用预测下一个文本单词作为目标,所以只能支持以文本作为输出的多模态任务理解。 LAION 开源了 Flamingo 模型的复现版本 OpenFlamingo。
2.)基本模块
LMM(MLLM),它们通常涉及三个基本组件和操作。
a.)首先,模态嵌入,为每种数据模态采用编码器来生成特定于该模态的数据表示(称为嵌入)。
b.)其次,模态对齐,使用不同的机制将不同模态的嵌入对齐到统一的多模态嵌入空间中。
c.)最后,输出模态,对于生成模型,通常生成文本用于响应。由于输入可能由文本、图像、视频和音频组成,需考虑在给出响应时考虑不同的模式。
3.)技术趋势:
LMM(MLLM)的发展仍处于初级阶段,需要在以下方面进行改进:
- 提升感知能力:寻找更高效压缩视觉信息的视觉基模。
- 加强推理能力:多模态推理在推理过程中仍较容易出现错误,需要改进模态推理的方法。如多模态的思想链等。
- 提升指令跟随能力:指令调优覆盖更多任务以提高泛化能力。
- 解决对象幻觉问题:多模态细粒度的特征对齐。
- 实现参数高效的训练:多模态的高效融合训练。
三、图像大模型
图像生成技术是人工智能领域的重要研究方向,它可以通过学习现有图像的特征和分布,生成新的逼真图像。近年来,1.)基础图像生成模型如Midjourney和Stable Diffusion以及2.)保ID图像生成模型如FaceChain、PhotoMaker和InstantID等方法得到了广泛关注。这两类模型在图像生成领域具有重要意义,各自有着不同的特点和应用场景。
1.)基础图像生成模型
目前在基础图像生成模型领域的SOTA是Midjourney和Stable Diffusion,这是两种不同的图像生成模型算法,具有各自的特点和优势。
a.)Midjourney(闭源):
Midjourney是一种基于自编码器(Autoencoder)的图像生成模型,旨在实现高质量、高分辨率的图像生成。
该模型通过学习图像的潜在表示,然后从潜在空间中重建图像,从而生成逼真的图像。
Midjourney的优势在于可以生成高质量的图像,并且具有较好的稳定性和可控性。
b.)Stable Diffusion(开源):
Stable Diffusion是一种基于扩散过程的生成模型,最早由NVIDIA提出,旨在实现高质量、高分辨率图像的生成。该模型利用随机噪声逐步扩散和改进图像,通过多次迭代扩散过程,逐渐生成逼真的图像。Stable Diffusion的优势在于可以生成具有高度逼真性的图像,并且具有很高的灵活性和可控性。
2.)保ID图像生成模型:
在人像保ID图像生成方面有如下三类方法:facechain、photomaker和instantID,都是针对人脸生成任务的解决方案,各自具有独特的优势和局限性。以下是对它们优劣的总结及扩充:
2.1)FaceChain

写实风格写真:facechain生成的人脸图像具有高度写实的特点,能够准确还原真实人物的特征和表情,使得生成的人脸图像更加逼真。开源代码,https://github.com/modelscope/facechain。
推理速度快:FaceChain-fact:Face Adapter for Human AIGC,10秒的推理时间使得facechain-fact在实时性要求较高的场景下具有显著优势,如即时AI写真生成、AI虚拟试衣、AI虚拟试妆等场景。
自研Transofrmer架构:基于自研的Transofrmer架构的人脸特征提取器,https://github.com/modelscope/facechain/tree/main/face_module/TransFace,使得facechain在人脸特征提取方面更加精准,更符合SD(Stable Diffusion)的架构需求,提高了人脸生成的准确性。
深入SD底层的Block人脸信息注入:通过深入SD底层的Block进行人脸信息注入,facechain能够更好地控制人脸生成的细节,使得生成的人脸图像更加精细。
无缝兼容LoRA模型与ControlNet:facechain能够无缝兼容LoRA模型与ControlNet,这使得它在风格保持度方面具有显著优势,能够生成具有一致性和稳定性的人脸图像。
用法上,facechain对于自定义的文本生成写真上未做更多探索,在与风格lora结合、固定模版重绘上有较大友好性,比较契合现有爆款写真应用。
2.2)Photomaker

Clip通用图像编码器:photomaker采用Clip通用图像编码器,使得它能够处理多种类型的图像数据,提高了通用性和灵活性。
以ID为中心的训练数据:通过以ID为中心的训练数据,photomaker能够生成具有一致性和连续性的人脸图像,使得不同图像中的人物特征能够保持一致。
相对来讲Photomaker会比较擅长非写实类写真,另外将人脸信息融入文本信息可能会导致两者之间的干扰,影响生成图像的准确性和一致性。
2.3)InstantID

人脸编码器:instantID具备专业的人脸编码器,能够准确提取人脸特征,为生成高质量的人脸图像奠定基础。
深入至SD底层Block的人脸信息注入:通过深入至SD底层的Block进行人脸信息注入,instantID能够实现对人脸生成细节的精准控制。
IdentifyNet利用关键点联合控制人脸:IdentifyNet的引入使得instantID能够利用关键点联合控制人脸,提高了人脸生成的准确性和自然度。
与photomaker类似,instantID生成的人脸图像也会更擅长非写实类写真生成。
2.4)总结
综上所述,facechain在写实风格写真以及当前具体应用上具有优势,适用于需要高度还原真实人物特征的场景;photomaker和instantID则更偏向于非写实的人脸生成,适用于艺术创作或个性化风格需求较高的场景。在选择使用哪种方法时,需要根据具体需求和场景进行权衡和选择。
四、视频大模型
视频生成大模型分为通用视频生成大模型和人像视频生成大模型两种。通用视频生成大模型旨在生成各种类型的视频内容,包括风景、动物、人物等,具有较强的通用性和泛化能力。而人像视频生成大模型则专注于生成与人物相关的视频内容,如人物动作、表情、姿态等,更贴近实际应用场景。
通用视频生成大模型在生成各种类型的视频内容时具有较好的效果,可以生成具有丰富内容和多样风格的视频。然而,由于需要考虑多种场景和内容,通用视频生成大模型可能在生成人物相关的视频时表现不如人像视频生成大模型。
人像视频生成大模型专注于人物相关的视频内容,可以更准确地捕捉人物的动作、表情和姿态,生成更具真实感和细节丰富的人物视频。这使得人像视频生成大模型在人物相关的应用场景中具有更大的优势,如视频特效、虚拟人物创建等领域。
总的来说,通用视频生成大模型具有较强的通用性和泛化能力,适用于生成各种类型的视频内容;而人像视频生成大模型更贴近实际应用场景,可以生成更具真实感和细节丰富的人物视频,具有更广阔的应用前景。
1.)通用视频生成
1.1.)sora
报告:
Video generation models as world simulators
核心:

训练:

推理:

1.2.) svd (stable video diffusion)
论文:https://static1.squarespace.com/static/6213c340453c3f502425776e/t/655ce779b9d47d342a93c890/1700587395994/stable_video_diffusion.pdf
HF:https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
Git:https://github.com/Stability-AI/generative-models
官方提供的样例图片,尺寸为(1024, 576),在所有参数均选择默认的情况下,占用显存约为60G。从效果来看,在前几帧的生成效果通常比较好,随着帧数的推移,视频的部分内容可能会发生形变。

模型框架:Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
https://arxiv.org/pdf/2304.08818.pdf
训练侧:

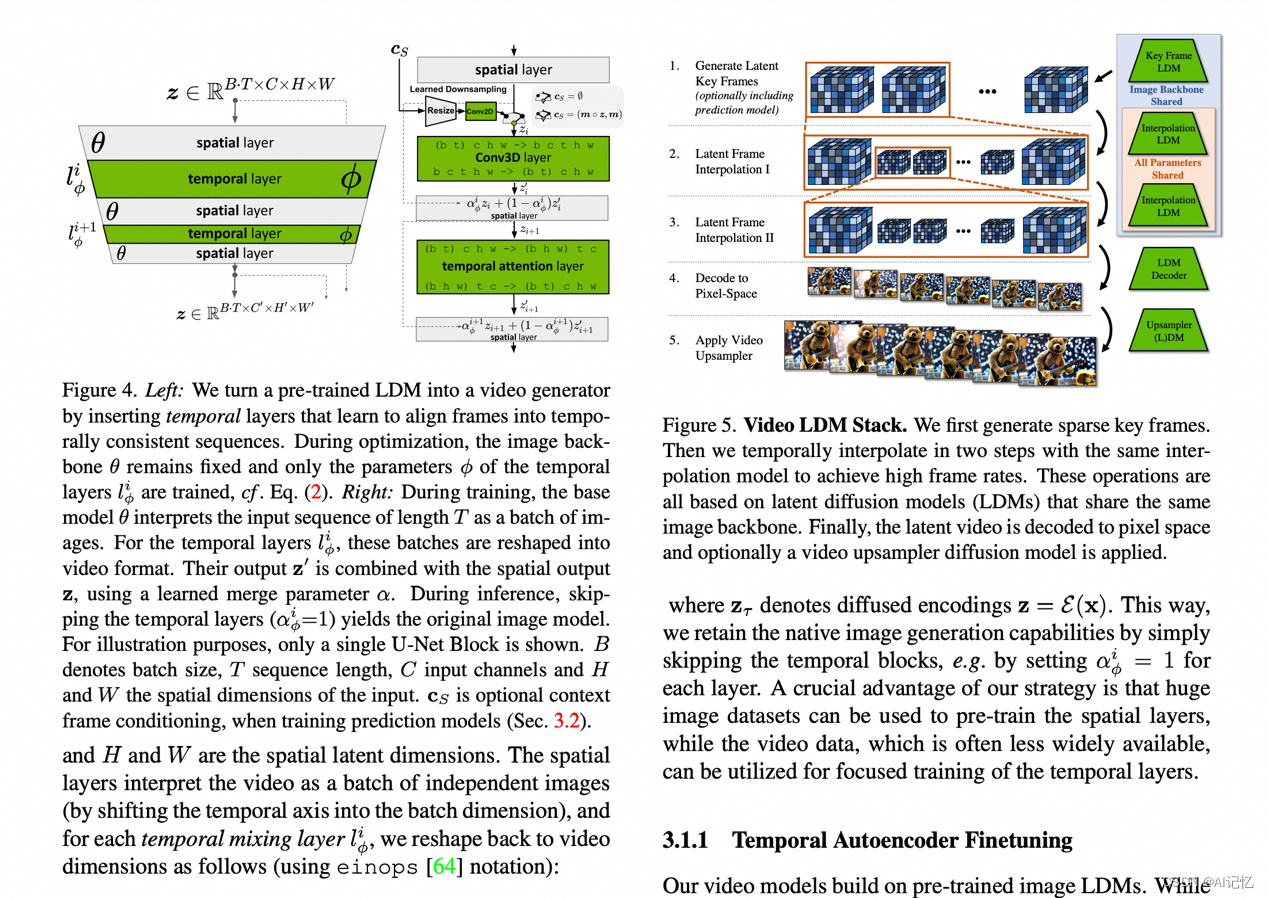
推理侧:

video LDM decoder(encoder是独立的,decoder容易过拟合,实际现象进一步推理更长视频时可能还是会存在闪烁):

超分:

1.3.) animatediff
论文:AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
项目主页:https://animatediff.github.io/
核心原理:

2.)人像视频生成
2.1.) animate anyone
论文:https://arxiv.org/pdf/2311.17117.pdf


训练:
阶段一:

阶段二:
In the second stage, we introduce the temporal layer into the previously trained model and initialize it using pretrained weights from AnimateDiff[11]. The input for the model consists of a 24-frames video clip. During this stage, we only train the temporal layer while fixing the weights of the rest of the network.
较为简洁合理,并且设计上保障了appearance、pose的准确性,将temporal放在了第二阶段学习。这样整体保障了视频逐帧的质量(appearance强保留原内容,pose强准确)。
2.2.)DreamMoving
论文:https://arxiv.org/abs/2312.05107
核心内容:
1、拓展animatediff + 2、3D control + 3、id引导的refnet
