sparksql简介
什么是sparksql
sparksql是一个用来处理结构话数据的spark模块,它允许开发者便捷地使用sql语句的方式来处理数据;它是用来处理大规模结构化数据的分布式计算引擎,其他分布式计算引擎比较火的还有hive,map-reduce方式。
sparksql的特点
- 融合性 – 无缝集成在代码里,随时使用sql语句
- 统一数据访问方式 – 一套标准api访问多种数据源
- 兼容hive – 可以使用sparksql直接计算并生成hive数据表,这对老的hive数据仓的兼容还是比较好的
- 标准化连接,支持jdbc/odbc连接,方便和各种数据库进行数据交互
sparksql与hive的异同对比
- 都是分布式计算引擎,都广泛用于大规模结构化数据计算,但spark性能更佳
- sparksql底层允许sparkRDD,hive底层允许map-reduce, sparksql是基于内存迭代的,hive是基于磁盘迭代的,这也是他们性能差异的主要来源之一
- sparksql不支持元数据管理,hive有metastore管理元数据,但spark可以和hive集成,从而使用hive的元数据管理
- 二者都可以允许到yarn之上
- hive只支持sql开发,spark支持代码+sql融合开发
sparksql数据抽像与pandas、sparkcore对比
- pandas中,数据抽象单元是DataFrame,是一个二维表结构,用于单机/本地数据集合的处理
- sparkcore中,数据抽象是RDD,用于分布式数据集合,没有固定数据结构,可存储任意数据
- sparksql中,数据抽象是DataFrame,是一个二维表结构,与pandas不同的在于可以用于处理分布式数据集合
实际上,sparksql有三种数据抽象,一个是早期的SchemaRDD抽象,现在已经废弃了,一个是DataSet数据抽象,主要是为scala/java提供的泛型数据对象支持,另外就是DataFrame,可支持python/java/scala。
在spark中,RDD和sparksql是两个很常见的数据抽象形式,怎么理解这两种数据抽象,我们可以看下图:
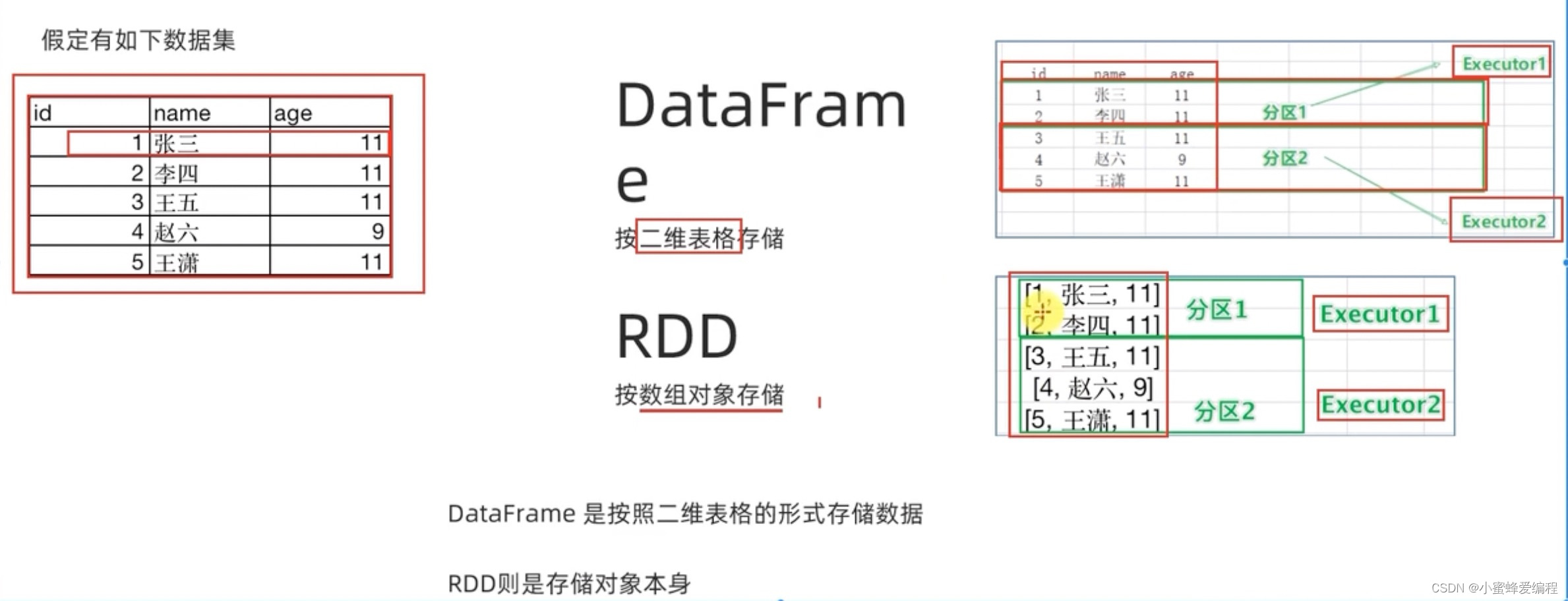
- RDD是可以存储任意结构数据了,上面只是假设数据对象是一个二维数据的结构,我们也可以用字符串(如"id,name,age")、类(三个成员)等存储,RDD存储对象本身,但dataframe不一样,只能按二维表存储;
- RDD和DataFrame都可以进行分区处理,dataframe更适合用sql处理;