如何使用查询路由构建更先进的 RAG
前言
目前大部分RAG的实践方案都是通过检索模型从外部数据库中获取与输入相关的文档或信息;然后,将这些信息与输入结合,输入到生成模型中进行文本生成。这种方案往往会有一个问题就是所有的数据都存储在一起,但这往往是没法在生产实践的,一般情况下单个prompt无法处理所有情况,单个数据源也可能无法适合所有数据。比如这个问题:假设现在需要构建一个聊天机器人来回答员工有关管理的问题,例如工资或绩效相关的问题。如果查询涉及员工福利、绩效评估、休假政策或任何与人力资源直接相关的主题,我们需要将查询路由到 HR 向量数据库。另一方面,如果查询涉及工资、工资单详细信息、费用报销或其他财务事项,则应将其定向到帐户向量数据库。
这个问题的解决方案复杂,生产应用程序可能需要多个向量存储。例如,应用程序可能是多模态的 RAG[1] ,可以处理不同的数据类型(文本、图像、音频)并使用不同的向量数据库。这时候就需要使用到查询理由了。
查询路由
查询路由是RAG中的一种智能查询分发功能,它根据用户输入的语义内容从多个选项中选择最合适的处理方法或数据源。查询路由可以显着增强RAG检索的相关性和效率,使其适用于复杂的信息检索场景,例如将用户查询分布到不同的知识库。查询路由的灵活性和智能性使其成为构建高效 RAG 系统的关键组件。
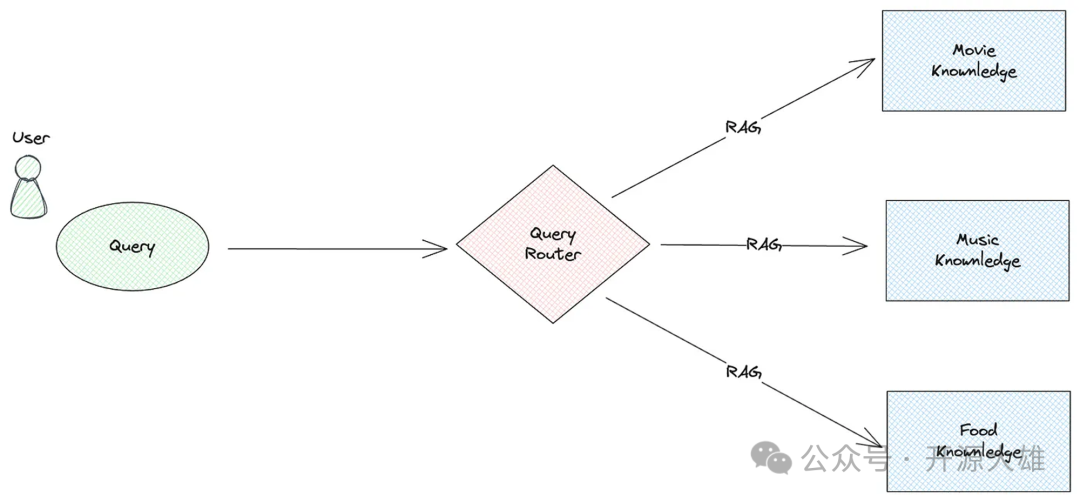
查询路由的类型
根据查询路由实现原理,我们可以将其分为两类:
•LLM Router:通过构建有效的提示,LLM确定用户查询的意图。现有的实现包括 LlamaIndex Router 等。•Embedding Router :通过使用 Embedding 模型,将用户查询转换为向量,并通过相似性检索确定意图。现有的实现包括语义路由器等。
LLM Router
使用LLM来确定用户意图是目前RAG中常见的路由方法。首先,提示中列出查询的所有类别,然后LLM对查询进行分类。最后根据分类结果选择合适的处理方法。
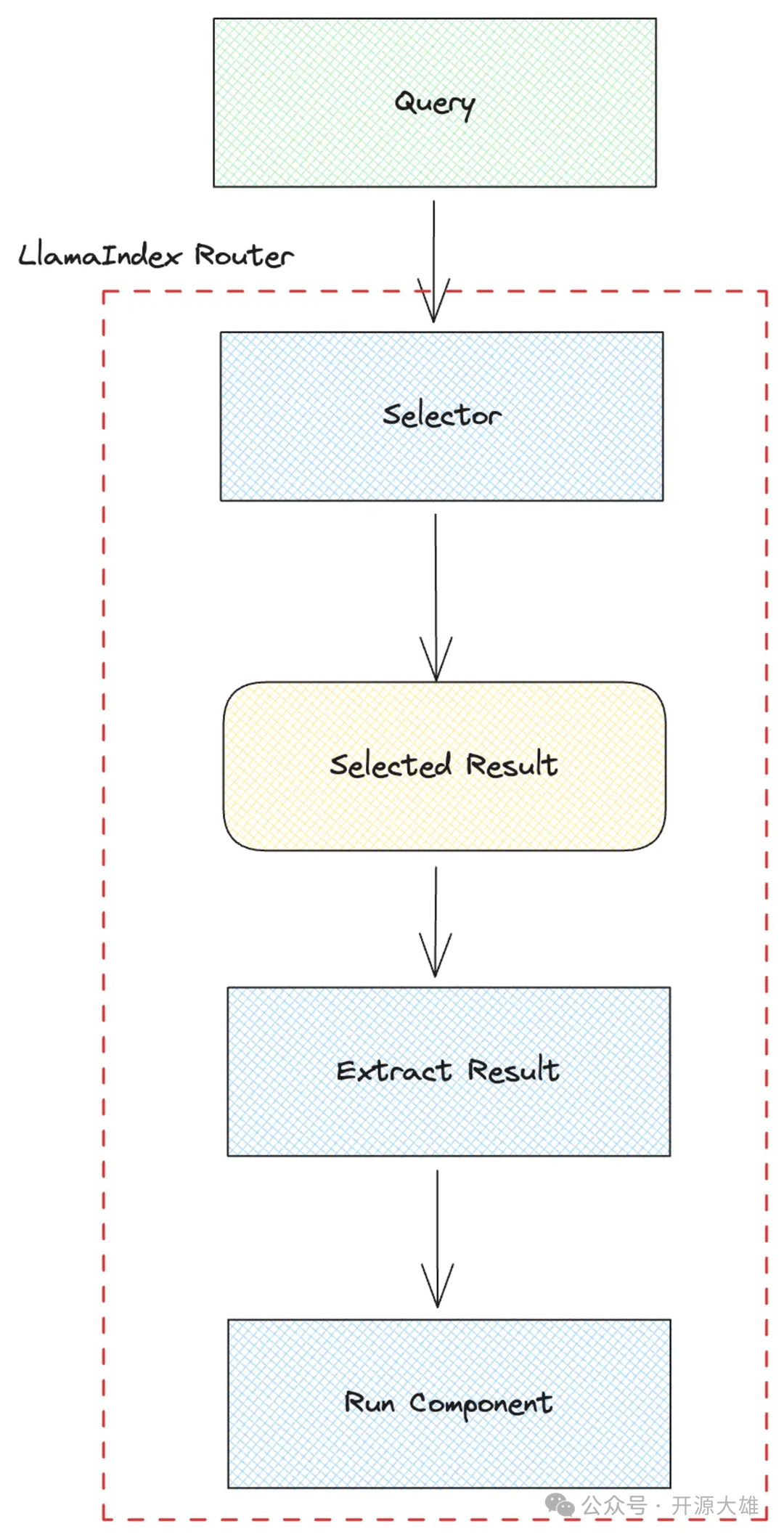
LLM 应用程序框架 LlamaIndex 使用 LLM 路由器。在 LlamaIndex 中,存在多种查询路由实现,例如 RouterRetriever 、 RouterQueryEngine 和 RouterComponent 。它们的基本原理是相似的:用一个选择器和一个工具组件列表进行初始化,通过选择器获取工具组件的索引,根据索引选择对应的工具组件,最后执行工具组件的处理逻辑。以下是 RouterQueryEngine 的示例代码:
from llama_index.core.query_engine import RouterQueryEnginefrom llama_index.core.selectors import LLMSingleSelectorfrom llama_index.core.tools import QueryEngineTool# initialize toolslist_tool = QueryEngineTool.from_defaults(query_engine=list_query_engine,description="Useful for summarization questions related to the data source",)vector_tool = QueryEngineTool.from_defaults(query_engine=vector_query_engine,description="Useful for retrieving specific context related to the data source",)# initialize router query engine (single selection, llm)query_engine = RouterQueryEngine(selector=LLMSingleSelector.from_defaults(),query_engine_tools=[list_tool,vector_tool,],)query_engine.query("<query>")
•首先,我们构建两个工具 list_tool 和 vector_tool ,分别用于汇总查询和向量查询。 list_tool 使用 SummaryIndex 构建检索引擎,而 vector_tool 使用 VectorStoreIndex 。•接下来,我们初始化 RouterQueryEngine ,传入选择器和工具列表。•这里的选择器是 LLMSingleSelector ,它使用 LLM 来确定用户意图并返回单个选择结果。•最后,通过用户查询调用query_engine.query方法,RouterQueryEngine根据查询选择适当的工具并执行它。
下面是LlamaIndex Router的流程图:
LlamaIndex 提供了四种选择器,如下图所示:
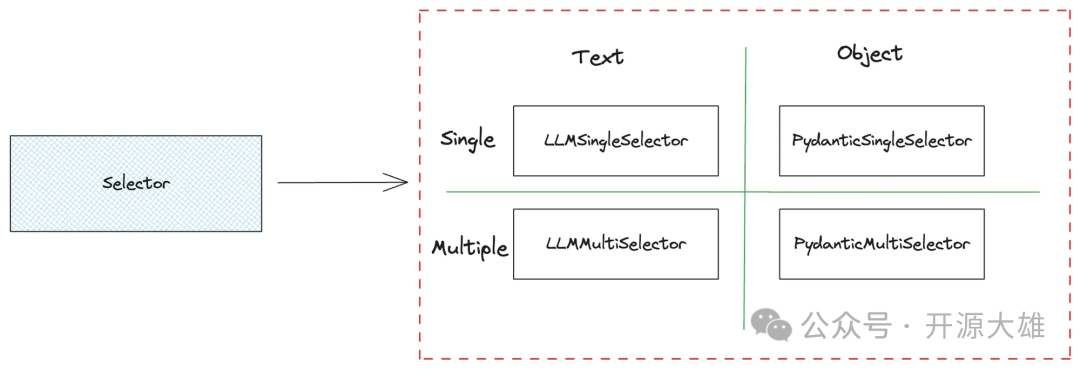
这四个选择器使用LLM来确定用户意图,可以分为单结果选择器和多结果选择器。单结果选择器仅返回一个选择,而多结果选择器返回多个选择,并将它们合并为最终结果。
根据解析结果,它们还可以分为文本结果选择器和对象结果选择器。文本结果选择器使用 LLM 的补全 API 生成格式为 <index>. <reason> 。其中 index 是选择索引,reason 是选择索引的基本解释。对象结果选择器使用LLM的函数调用API将选择结果解析为Python对象。默认对象是 SingleSelection ,定义如下:
class SingleSelection(BaseModel):"""A single selection of a choice."""index: intreason: str
两种解析结果示例如下:
# Text selector2. Useful for questions related to oranges# Object selectorSingleSelection(index=2, reason="Useful for questions related to oranges")
当使用文本结果选择器时,需要进一步处理,例如从结果中提取索引。对象结果选择器不需要额外的处理,因为对象的属性可以直接检索结果。
我们还检查一下选择器的提示模板:
DEFAULT_SINGLE_SELECT_PROMPT_TMPL = ("下面给出了一些选择。它以编号列表形式提供""(1 到 {num_choices}),""列表中的每个项目对应一个摘要。\n""----------\n""{context_list}""\n---------------------\n""仅使用上述选择而不使用先验知识,返回""与问题最相关的选择:'{query_str}'\n")
•这是 LLMSingleSelector 的默认提示模板。•{num_choices}表示选择的数量。•{context_list}是工具组件列表的文字描述,包括索引和描述。•{query_str} is the user query. {query_str} 是用户查询。
使用 LLM Router 的一个关键方面是构建有效的提示。如果LLM足够给力的话,提示不需要很精确也能达到想要的效果。然而,如果LLM不够强,则必须不断调整提示以获得满意的结果。笔者在使用LlamaIndex Router的过程中发现,在使用OpenAI的gpt-3.5-turbo模型时,LLMSingleSelector偶尔会无法正确解析。相比之下,PydanticSingleSelector相对稳定。
一旦获得选择索引,就可以使用它来选择工具组件,如RouterQueryEngine代码片段所示:
class RouterQueryEngine(BaseQueryEngine):def _query(self, query_bundle: QueryBundle) -> RESPONSE_TYPE:......result = self._selector.select(self._metadatas, query_bundle)selected_query_engine = self._query_engines[result.ind]final_response = selected_query_engine.query(query_bundle)......
•RouterQueryEngine 的 _query 方法中,首先通过选择器获取选择结果。•根据选择结果中的索引,从 _query_engines 中选择相应的检索引擎。•最后调用检索引擎的query方法生成最终结果。
优点和缺点
•优点:方法简单,易于实施。•缺点:需要相对强大的LLM才能正确解释用户意图。如果选择结果需要解析为对象,LLM还必须支持函数调用能力。
Embedding Router
查询路由的另一种方法涉及使用Embedding模型对用户查询进行向量化,然后通过向量相似度对查询进行分类,然后确定适当的处理方法。
Semantic Router[2] 就是基于此原理构建的路由工具。它旨在提供超快速的AI决策能力,利用语义向量进行快速决策,以提高LLM应用程序和AI Agent的效率。Semantic Router 的使用非常简单,如以下示例代码所示:
import osfrom semantic_router import Routefrom semantic_router.encoders import CohereEncoder, OpenAIEncoderfrom semantic_router.layer import RouteLayer# we could use this as a guide for our chatbot to avoid political conversationspolitics = Route(name="politics",utterances=["isn't politics the best thing ever","why don't you tell me about your political opinions","don't you just love the president","they're going to destroy this country!","they will save the country!",],)# this could be used as an indicator to our chatbot to switch to a more# conversational promptchitchat = Route(name="chitchat",utterances=["how's the weather today?","how are things going?","lovely weather today","the weather is horrendous","let's go to the chippy",],)# we place both of our decisions together into single listroutes = [politics, chitchat]# OpenAI Encoderos.environ["OPENAI_API_KEY"] = "<YOUR_API_KEY>"encoder = OpenAIEncoder()rl = RouteLayer(encoder=encoder, routes=routes)rl("don't you love politics?").name# politicsrl("how's the weather today?").name# chitchat
•首先,我们定义两个路由: politics 和 chitchat ,每个路由包含多个示例话语。•然后,创建一个Encoder,这里使用 OpenAI 的Encoder通过 OpenAI 的Embedding生成向量。•最后,使用Encoder和路由列表作为输入创建 RouteLayer。•通过用户查询调用 RouteLayer 方法以获得分类结果。 注意:并非每个用户查询都会匹配预设的分类结果。如果用户查询不属于预定义类别,则分类结果可能为空。
OpenAI Encoder 默认的 Embedding 模型为 text-embedding-3-small ,其性能优于之前的 OpenAI text-embedding-ada-002 模型,并且也更具成本效益。此外,Semantic Router还支持其他Encoder,例如Huggingface Encoder,它默认使用sentence-transformers/all-MiniLM-L6-v2模型。该sentence-transformer模型将句子和段落映射到 384 维向量空间,适用于分类或语义搜索等任务。
优点和缺点
•优点:只需要Embedding模型,比LLM Router更高效、更节省资源。•缺点:需要预先加载选项。如果选项不充分或不够全面,分类性能可能不是最佳的。
查询路由的实际应用
现在让我们集成 LlamaIndex 和语义路由器来创建一个查询路由器,将用户查询分发到各种工具组件。这些组件包括与 LLM 进行聊天、使用 RAG 流程检索文档以生成答案,以及使用 Bing搜索引擎进行网络搜索。
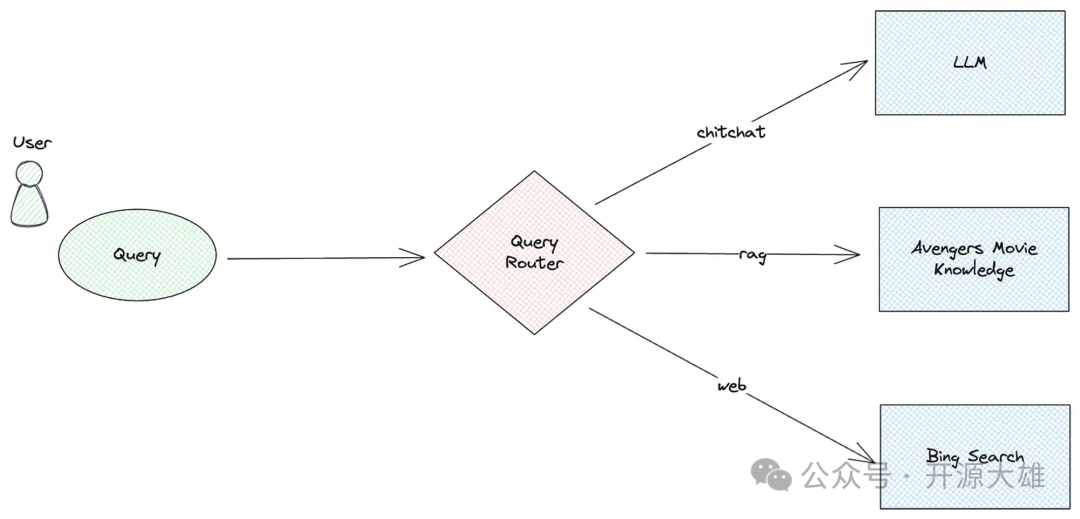
首先,我们定义一个与 LLM 聊天的工具组件,使用 LlamaIndex 的 Pipeline 功能构建查询pipeline。
from llama_index.llms.openai import OpenAIfrom llama_index.core.query_pipeline import QueryPipeline, InputComponentllm = OpenAI(model="gpt-3.5-turbo", system_prompt="You are a helpful assistant.")chitchat_p = QueryPipeline(verbose=True)chitchat_p.add_modules({"input": InputComponent(),"llm": llm,})chitchat_p.add_link("input", "llm")output = chitchat_p.run(input="hello")print(f"Output: {output}")# Display resultOutput: assistant: Hello! How can I assist you today?
•这里,我们使用OpenAI的gpt-3.5-turbo模型来构建LLM。•然后,构建 QueryPipeline,添加 input 和 llm 模块。 input 模块是一个输入组件,其默认输入参数键名为 input 。•接下来,在两个模块之间建立连接。•最后,通过用户查询调用 run 方法以获得响应。
接下来,我们通过类似地创建查询pipeline来添加基本 RAG 工具组件。为此,我们将使用有关《黑神话:悟空》文章作为我们的测试文档。这是示例代码:
from llama_index.core import SimpleDirectoryReader, VectorStoreIndexfrom llama_index.core.response_synthesizers.tree_summarize import TreeSummarizedocuments = SimpleDirectoryReader("./data").load_data()index = VectorStoreIndex.from_documents(documents)retriever = index.as_retriever(similarity_top_k=2)rag_p = QueryPipeline(verbose=True)rag_p.add_modules({"input": InputComponent(),"retriever": retriever,"output": TreeSummarize(),})rag_p.add_link("input", "retriever")rag_p.add_link("input", "output", dest_key="query_str")rag_p.add_link("retriever", "output", dest_key="nodes")output = rag_p.run(input="Introducing the Black Myth: Wukong?")print(f"Output: {output}")# Display resultOutput: Black Myth: Wukong is a 2024 action role-playing game developed and published by Game Science.
•初始部分涉及通常的 LlamaIndex 检索引擎构建过程,使用 SimpleDirectoryReader 加载测试文档,使用 VectorStoreIndex 构建检索器。•创建查询pipeline,添加 input 、 retriever 和 output 模块。 output 模块是一个树状汇总组件。•在三个模块之间添加连接,output 模块利用 input 和 retriever 模块的输出。•最后,使用用户查询调用 run 方法来生成响应。
接下来,让我们添加一个使用 Bing 搜索引擎的工具组件。同样,我们将创建一个查询pipeline,但这次我们需要使用自定义模块。这是示例代码:
web_p = QueryPipeline(verbose=True)web_p.add_modules({"input": InputComponent(),"web_search": WebSearchComponent(),})web_p.add_link("input", "web_search")
•网络搜索工具相对简单,仅包含两个模块: input 和 web_search 。•WebSearchComponent 是一个自定义模块,我们将详细探讨它。
在实现此自定义模块之前,我们需要在 Azure 上创建 Bing 搜索服务并获取 API 密钥。详细步骤可以参考微软官方文档[3]。然后,安装 LlamaIndex 的 Bing 查询工具库: pip install llama-index-tools-bing-search 。完成后,我们就可以开始实现自定义模块了,如下所示:
import osfrom typing import Dict, Anyfrom llama_index.core.query_pipeline import CustomQueryComponentfrom llama_index.tools.bing_search import BingSearchToolSpecfrom llama_index.agent.openai import OpenAIAgentclass WebSearchComponent(CustomQueryComponent):"""Web search component."""def _validate_component_inputs(self, input: Dict[str, Any]) -> Dict[str, Any]:"""Validate component inputs during run_component."""assert "input" in input, "input is required"return input@propertydef _input_keys(self) -> set:"""Input keys dict."""return {"input"}@propertydef _output_keys(self) -> set:return {"output"}def _run_component(self, **kwargs) -> Dict[str, Any]:"""Run the component."""tool_spec = BingSearchToolSpec(api_key=os.getenv("BING_SEARCH_API_KEY"))agent = OpenAIAgent.from_tools(tool_spec.to_tool_list())question = kwargs["input"]result = agent.chat(question)return {"output": result}
•让我们重点关注自定义组件中的核心方法 _run_component。•首先创建 BingSearchToolSpec 对象,并将 Bing 搜索引擎的 API 密钥作为参数传递。这里,API Key 存储在 BING_SEARCH_API_KEY 环境变量中。•我们使用 LlamaIndex 的 Agent 功能,创建一个 OpenAIAgent 对象并传入 Bing 搜索工具。•最后,使用 kwargs["input"] 获取用户的查询并将其传递给 agent.chat 方法以获取搜索结果,然后返回搜索结果。•有关如何使用 Bing 搜索工具的更多信息,您可以参考其文档[4]。
创建完三个工具组件后,我们需要创建一个路由模块。我们将使用语义路由器通过定义多个路由来实现此路由模块,如以下代码所示:
chitchat = Route(name="chitchat",utterances=["how's the weather today?","how are things going?","lovely weather today","the weather is horrendous","let's go to the chippy",],)rag = Route(name="rag",utterances=["What kind of game is "Black Myth: Wukong"? What are the main features and highlights of this game?","What is the development progress of this game? When is it expected to be officially released?","What aspects of gameplay and storyline are worth looking forward to? How will it interpret the classic story of Sun Wukong?"],)web = Route(name="web",utterances=["Search online for the top three countries in the 2024 Paris Olympics medal table.","Find the latest news about the U.S. presidential election.","Look up the current updates on NVIDIA'sstock performance today.","Search for what Musk said on X last month.","Find the latest AI news.",],)
•在这里,我们定义了三个路由,每个路由针对不同类型的查询。•chitchat 路由由对话的示例话语组成,对应于 chitchat 工具组件。•rag 路由包括与《黑神话.悟空》游戏相关的示例查询,与 rag 工具组件保持一致。•web 路由由与 Web 搜索相关的查询组成,其中包含许多关键字,例如 Search 和 Find ,对应于 web 工具组件。
接下来,我们使用Semantic Router创建一个自定义路由模块来实现查询路由,如下所示:
from llama_index.core.base.query_pipeline.query import (QueryComponent,QUERY_COMPONENT_TYPE,)from llama_index.core.bridge.pydantic import Fieldclass SemanticRouterComponent(CustomQueryComponent):"""Semantic router component."""components: Dict[str, QueryComponent] = Field(..., description="Components (must correspond to choices)")def __init__(self, components: Dict[str, QUERY_COMPONENT_TYPE]) -> None:"""Init."""super().__init__(components=components)def _validate_component_inputs(self, input: Dict[str, Any]) -> Dict[str, Any]:"""Validate component inputs during run_component."""return input@propertydef _input_keys(self) -> set:"""Input keys dict."""return {"input"}@propertydef _output_keys(self) -> set:return {"output", "selection"}def _run_component(self, **kwargs) -> Dict[str, Any]:"""Run the component."""if len(self.components) < 1:raise ValueError("No components")if chitchat.name not in self.components.keys():raise ValueError("No chitchat component")routes = [chitchat, rag, web]encoder = OpenAIEncoder()rl = RouteLayer(encoder=encoder, routes=routes)question = kwargs["input"]selection = rl(question).nameif selection is not None:output = self.components[selection].run_component(input=question)else:output = self.components["chitchat"].run_component(input=question)return {"output": output, "selection": selection}
•在自定义模块的构造函数__init__中,传递了一个字典,其中包含表示路由名称的键和与各个工具组件相对应的值。•在_output_keys方法中,返回两个输出键:一个用于输出结果,一个用于选择结果。•在 _run_component 方法中,首先验证工具组件参数以确保 chitchat 工具组件存在,因为无法分类的查询需要分派到 工具组件。•语义路由器用于判断用户的查询意图,得到选择结果 selection 。•然后根据选择结果选择并执行适当的工具组件。•如果选择结果为空,则选择并执行chitchat工具组件。•最后返回输出结果和选择结果。
最后,我们将所有工具组件和路由模块添加到单独的查询pipeline中,如下所示:
p = QueryPipeline(verbose=True)p.add_modules({"router": SemanticRouterComponent(components={"chitchat": chitchat_p,"rag": rag_p,"web": web_p,}),})
•新创建的查询pipeline仅包含一个模块 router ,这是我们的自定义路由模块 SemanticRouterComponent 。•在路由模块中,我们传递了三个先前定义的查询pipeline,表明不同的用户意图触发不同的查询pipeline。•由于只有一个模块,因此无需进行连接设置。
让我们执行这个pipeline并观察它的执行情况:
output = p.run(input="hello")# Selection: chitchat# Output: assistant: Hello! How can I assist you today?output = p.run(input="Introducing the Black Myth: Wukong?")# Selection: rag# Output: Black Myth: Wukong is a 2024 action role-playing game developed and published by Game Science.output = p.run(input="Search online for the top three countries in the 2024 Paris Olympics medal table.")# Selection: web# Output: The top three countries in the latest medal table for the 2024 Paris Olympics are as follows:# 1. United States# 2. China# 3. Great Britain
正如所观察到的,我们的查询路由器有效地运行,根据不同的用户查询意图选择不同的工具组件并提供相应的结果。
总结
今天,我们探讨了 RAG 检索策略中的查询路由,并讨论了 LLM Router 和 Embedding Router 背后的原理,展示了它们在实际项目中的实现。然而,当前的查询路由方法仍然存在一些不确定性,这意味着我们不能保证始终完全准确的决策。要创建更可靠的 RAG 应用程序,需要进行彻底的测试。
References
[1] 多模态的 RAG: https://developer.nvidia.com/blog/an-easy-introduction-to-multimodal-retrieval-augmented-generation/[2] Semantic Router: https://github.com/aurelio-labs/semantic-router[3] 微软官方文档: https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/overview[4] 参考其文档: https://llamahub.ai/l/tools/llama-index-tools-bing-search?from=