[ 网络 ] 应用层协议 —— HTTP协议
目录
1.HTTP协议
1.1URL
urlencode和urldecode
2. HTTP协议格式
HTTP请求
HTTP响应
3.告知服务器意图的HTTP方法
GET:获取资源
POST:传输实体主体
GET和POST的区别
使用Cookie的状态管理
4.返回结果的HTTP状态码
状态码告知从服务器端返回的请求结果
2XX成功
3XX重定向
4XX客户端错误
5XX服务器错误
5.HTTP的缺点
1.HTTP协议
应用层协议已经有大佬定义了一些现成的,有非常好用的应用层协议,我们可以直接参考使用。例如本篇所提到的HTTP(超文本传输协议)就是其中之一。
1.1URL
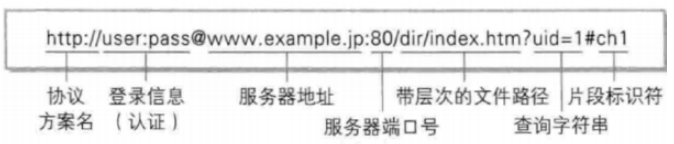
URL(统一资源定位符)就是我们俗称的"网址"

我们所常见到的网址:例如 https://www.baidu.com/ 是域名,这种字符串风格的域名,具有更好的字描述性。域名在解析时必须被转换成为IP地址,要访问网络服务,又必须具有port.
协议方案名和服务器端口号是强绑定的:
比如httpserver --- 80 ; httpsServer --- 443 ; sshd --- 22
HTTP协议的本质是要获得某种"资源",比如我们请求百度的官网时,我们所获取的资源是百度首页的网页信息。我们可以理解为HTTP是 获取网页资源的(视频,音乐等)。HTTP是向特定的服务器向特定端口申请特定的"资源"的,获取到本地进行展示或者某种展示的。而对应服务器上,你所要的资源所在的位置就是URL中带层次的文件路径。
实际上,上网的大部分行为,都在进行这进程间通信。既然是通信,就是获取信息和发送信息。所以我们对应到生活中,大部分的上网行为,无非两种:
- 把服务器上面的资源数据拿到本地(短视频,小说等等)
- 把本都的数据推送到服务器(搜索,注册,登录,下单等)
urlencode和urldecode
在URL中,像 / ? 等这样的字符已经被URL当做特殊意义理解了。因此这些字符不能随意出现。
比如:某个参数中需要带有这些特殊字符,就必须先对特殊字符进行转义。
转义规则:将需要转码的字符转为16进制,然后从右到做,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式。

我们可以看到 "C++" 中 "+"被转义成了 "%2B" 我们可以使用urlencode工具验证上述过程
UrlEncode编码/UrlDecode解码 | urldecode就是urlencode的逆过程。

2. HTTP协议格式
HTTP请求


- 首行:【方法】+【URL】+【版本】
- Header:请求的属性,冒号分割的键值对;每组属性之间使用\n分割;遇到空行表示Header部分结束
- Body:空行后面的内容都是Body.Body允许为空字符串.如果Body存在,则在Header中会有一个Content-Length字段用来表示Body的长度
常规情况下,HTTP(HTTPS)底层使用的传输层协议是TCP.
我们通过一段tcp套接字编程来查看HTTP请求格式
#include <iostream>
#include <cstring>
#include <cstdlib>
#include <unistd.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/wait.h>
using namespace std;
int main()
{
int listen_sock = socket(AF_INET,SOCK_STREAM,0);
if(listen_sock < 0){
std::cout<<"socket error" <<std::endl;
return 1;
}
struct sockaddr_in local;
memset(&local,0,sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(8082);
local.sin_addr.s_addr = INADDR_ANY;
if(bind(listen_sock,(struct sockaddr*)&local, sizeof(local))<0){
std::cout<<"bind error" << std::endl;
return 2;
}
if(listen(listen_sock,5) < 0){
std::cout<<"listen error" << std::endl;
return 3;
}
struct sockaddr_in peer;
for(;;){
socklen_t len = sizeof(peer);
int sock = accept(listen_sock,(struct sockaddr*)&peer,&len);
if(sock < 0){
std::cout<<"accept error "<<std::endl;
continue;
}
if(fork() == 0){
if(fork() > 0) exit(0);
close(listen_sock);
char buffer[1024];
recv(sock,buffer,sizeof(buffer),0);
std::cout<<"###################HTTP request begin####################"<<std::endl;
std::cout<< buffer << std::endl;
std::cout<<"###################HTTP request end####################"<<std::endl;
exit(0);
}
close(sock);
waitpid(-1,nullptr,0);
}
}
我们在直接打印出请求的格式
第一部分 首行:请求方法 请求url HTTP协议的版本
常用的请求方法:GET和POST (后面详解)
刚刚我们请求的是 / . " / " 是Web根目录不是系统根目录。那我们也可以请求 /a/b/c/d.html 我们再次看看请求报文:

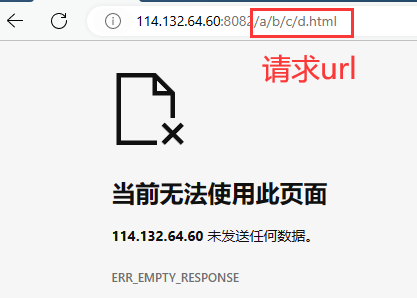

第二部分是一组Key:value的请求报头
请求报头是一堆Key: Value 请求属性,包括是否需要长链接,浏览器的编码类型,数据类型,我们想发送给服务器的相关信息等等.....通常存在多行,是一堆的Key: Value值

服务器端可以按行循环读取,一直读到\n (空行)就证明已经把报头读完了
第三部分:空行
是报头和有效载荷的分离符,为了就是将报头和有效载荷进行分离

前三部分都必须是按行方式陈列的

第四部分:请求正文(有效载荷) ——非必须 | 可以没有
根据我们的需求,有时候我们需要登录账号和密码,个人信息,音乐,视频等等一般都是用户的相关信息或者数据。
以上就是HTTP协议的请求(HTTP request)。
HTTP响应

- 首行: 【版本号】 + 【状态码】 + 【状态码解释】
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度; 如果服务器返回了一个html页面, 那么html页面内容就是在body中.
HTTP响应也是由4部分组成,其中响应正文也是可以被省略的。客户端如何判断已经将response报头读取完毕呢,仍然是客户端可以循环按行读取,知道读取到空行。
#include <iostream>
#include <string>
#include <cstring>
#include <cstdlib>
#include <unistd.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/wait.h>
#include <fstream>
using namespace std;
int main()
{
int listen_sock = socket(AF_INET,SOCK_STREAM,0);
if(listen_sock < 0){
std::cout<<"socket error" <<std::endl;
return 1;
}
struct sockaddr_in local;
memset(&local,0,sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(8083);
local.sin_addr.s_addr = INADDR_ANY;
if(bind(listen_sock,(struct sockaddr*)&local, sizeof(local))<0){
std::cout<<"bind error" << std::endl;
return 2;
}
if(listen(listen_sock,5) < 0){
std::cout<<"listen error" << std::endl;
return 3;
}
struct sockaddr_in peer;
for(;;){
socklen_t len = sizeof(peer);
int sock = accept(listen_sock,(struct sockaddr*)&peer,&len);
if(sock < 0){
std::cout<<"accept error "<<std::endl;
continue;
}
if(fork() == 0){
if(fork() > 0) exit(0);
close(listen_sock);
char buffer[1024];
recv(sock,buffer,sizeof(buffer),0);
// std::cout<<"###################HTTP request begin####################"<<std::endl;
// std::cout<< buffer << std::endl;
// std::cout<<"###################HTTP request end####################"<<std::endl;
#define PAGE "./wwwroot/index.html"
std::ifstream in(PAGE);
if(in.is_open()){
in.seekg(0,std::ios::end);
size_t len = in.tellg();
in.seekg(0,std::ios::beg);
char *file = new char[len];
in.read(file,len);
in.close();
std::string status_line = "http/1.0 200 OK\n";
std::string response_header = "Content-Length: "+std::to_string(len);
response_header+="\n";
std::string blank = "\n";
send(sock,status_line.c_str(),status_line.size(),0);
send(sock,response_header.c_str(),response_header.size(),0);
send(sock,blank.c_str(),blank.size(),0);
send(sock,file,len,0);
delete[] file;
}
close(sock);
exit(0);
}
close(sock);
waitpid(-1,nullptr,0);
}
}
3.告知服务器意图的HTTP方法
在众多的HTTP方法中最常用的是GET和POST方法,因此在此我们对GET和POST进行详细了解

GET:获取资源
GET方法是用来请求访问已被URL识别的资源。指定的资源经服务器端解析后返回响应内容。

我们也可以使用Postman工具抓取HTTP请求

POST:传输实体主体
POST方法是用来传输实体的主体
虽然用GET方法也可以传输实体的主体,但是一般不用GET方法进行传输,而是用POST方法。虽然POST的功能和GET很相似,但是POST的主要目的并不是获取响应的主体内容。

GET和POST的区别
- GET方法可以带参,参数在URL " ?"的后面
- POST方法通过正文传参
- GET方法传参不私密
- POST方法因为通过正文传参,所以相对私密一些
GET通过url传参,POST通过正文传参,所以一般一些大的内容都是通过POST传参。
使用Cookie的状态管理
HTTP是无状态协议,它不对之前发生过的请求和响应的状态进行管理。也就是说,无法根据之前的状态进行本次的请求管理。那么我们在日常上网的过程中,假设要求登录认证的Web页面本身无法进行状态的管理(不记录已登录的状态),那么每次跳转新页面的时候都要再次登录,或者每次请求报文中附加参数来管理登录状态。那么这对我们用户是非常不友好的,就相当于我们每次登录C站我们都要进行登录认证。因此Cookie技术就是通过在请求和响应报文中写入Cookie信息来控制客户端的状态。
Cookie会根据从服务器端发送的响应报文内的一个叫Set-Cookie的首部字段信息,通知客户端保存Cookie。当下次客户端再往服务器发送请求时,客户端会自动在请求报文中加入Cookie值后发送出去。服务器端发现过来的Cookie后,会检查究竟是从哪一个客户端的连接请求,然后对比服务器上的记录,最后得到之前的状态信息。
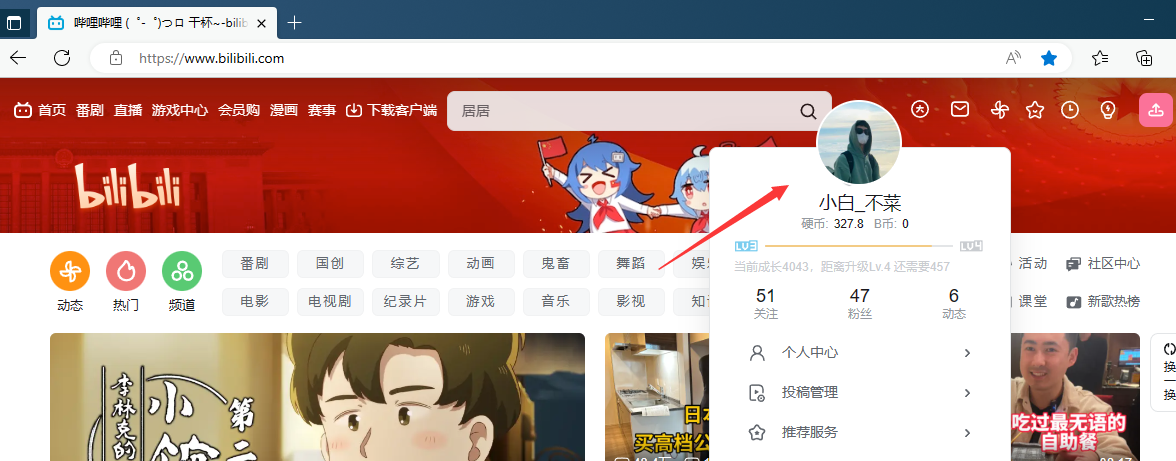
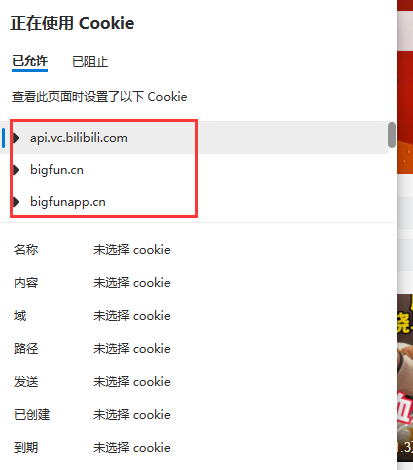
举例:我们用B站来进行举例。
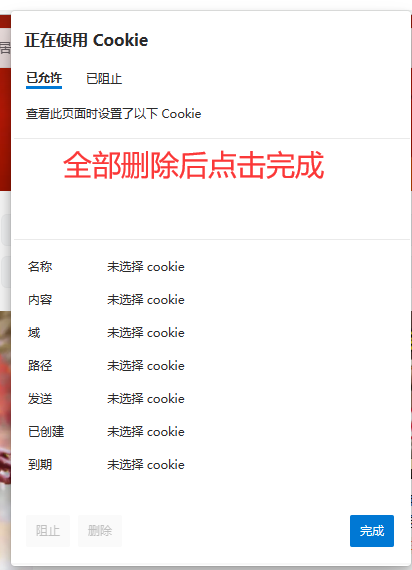
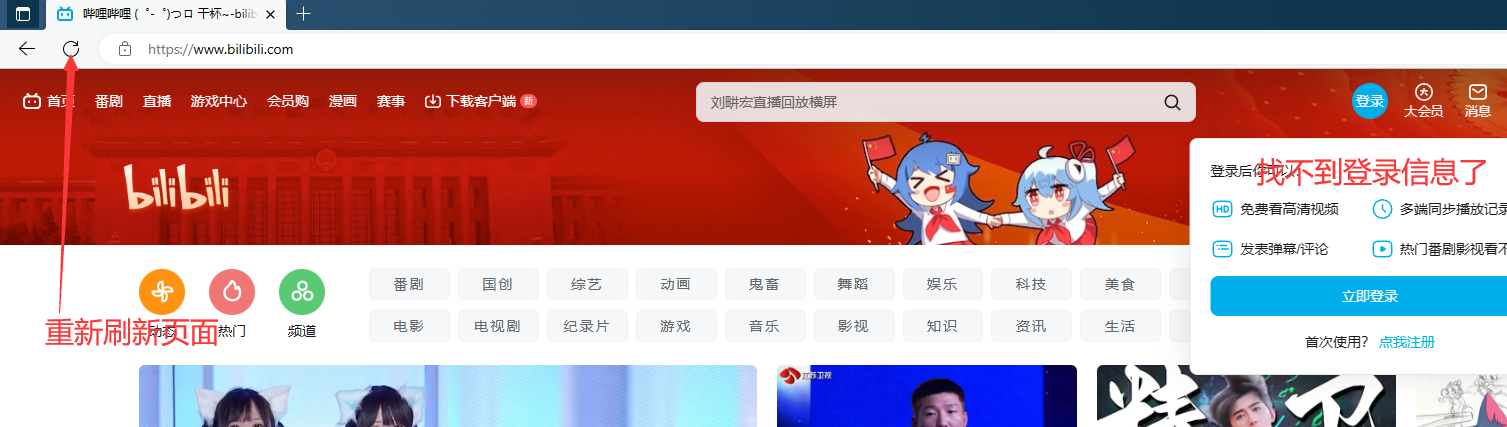
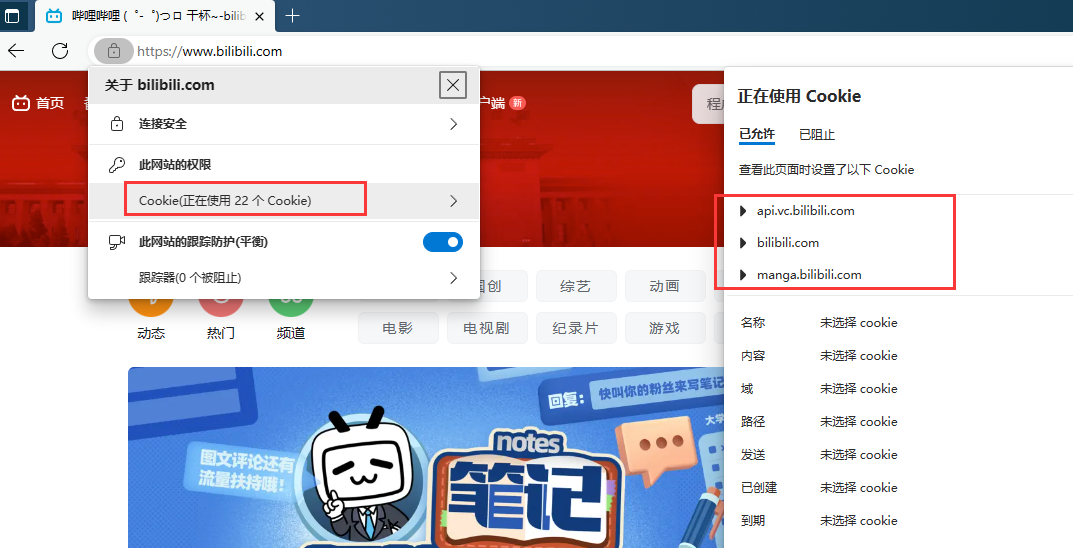
我只要登录过B站之后,再之后再次登录B站时会自动登录我的账号, 点击网址左边的锁,就会看到Cookie,点进去就会看到当前页面下的Cookie信息,我们全部进行删除后点击完成,再次刷新该页面,就发现无法找到之前的登录信息了。登录后再次查询发现Cookie信息被重新填写上了。

4.返回结果的HTTP状态码
HTTP状态码负责表示客户端HTTP请求的返回结果,标记服务器端的处理是否正常,通知出现的错误等工作。
状态码告知从服务器端返回的请求结果
状态码的职责是当客户端向服务器端发送请求时,描述返回的请求结果。借助状态码,用户可以知道服务器端是正常处理了请求还是出现了错误。
状态码的类别
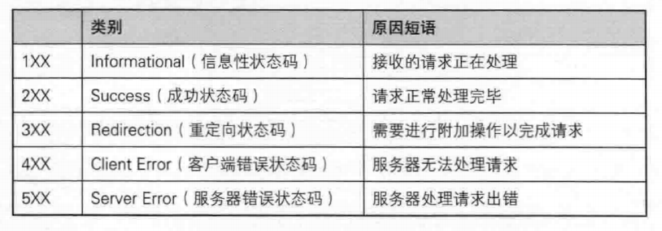
2XX成功
2XX的响应结果表明请求被正常处理了。
例如:
- 200 OK表示从客户端发来的请求在服务器端被正常处理了。
- 204 No Content 表示服务器接受的请求已成功处理,但在返回的响应报文中不含有实体的主体部分,也就是说请求处理成功但是没有资源可以返回。因此返回204响应后浏览器的显示页面不会发生更新。
3XX重定向
- 301 Moved Permanently 永久重定向。该状态码表示请求的资源已被分配了新的URL,以后应使用现在所指的URL。
- 302 Found 临时重定向。该状态码表示请求的资源已被分配了新的URL,希望用户本次能使用新的URL访问。
- 302和301状态码相似,但是302状态码代表的资源不是永久移动,只是临时性质的。换句话说,302的资源对应的URL将来还有可能发生变。
if(fork() == 0){
if(fork() > 0) exit(0);
close(listen_sock);
char buffer[1024];
recv(sock,buffer,sizeof(buffer),0);
//重定向到腾讯网
std::string response = "HTTP/1.1 301 Permanently Moved\r\n";
response += "Location: https://www.qq.com/\r\n";
response += "\r\n";
send(sock, response.c_str(), response.size(), 0);
close(sock);
exit(0);
}
当服务器启动之后在浏览器输入ip:port后按下回车发现URL自动跳转到了腾讯网
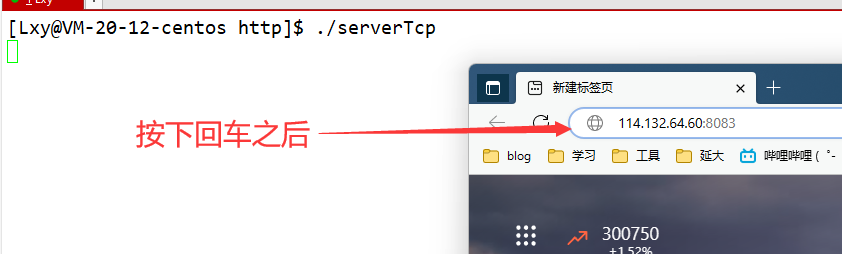
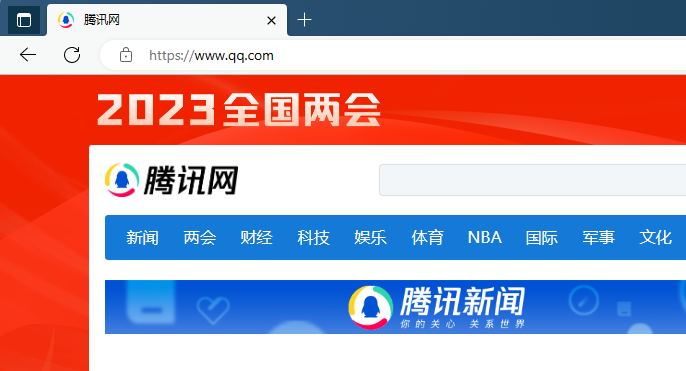
4XX客户端错误
- 403 Forbidden 表示请求资源的访问被服务器拒绝了。服务器端没有必要给出拒绝的详细理由。
- 发生403的原因:未获得文件系统的访问授权,访问权限出现某些问题(从未授权的发送源IP地址试图访问)
- 404 Not Found 表示服务器上无法找到请求的资源。除此之外,也可能在服务器端拒绝请求且不想说明理由时使用。
5XX服务器错误
5XX的响应结果表名服务器本身发生错误
- 500 Internal Server Error 表示服务器端在执行请求时发生了错误。也可能是Web应用存在的Bug或某些临时的故障。
5.HTTP的缺点
HTTP主要有如下不足之处:
- 通信使用明文(不加密),内容可能会被窃听
- 不验证通信方的身份,因此有可能遭遇伪装
- 无法证明报文的完整性,所以有可能已经遭到篡改
因此解决如上三个不足之处正是HTTPS的主要功能,因此HTTPS = HTTP+加密+认证+完整性保护。具体3个功能的实现细节,将单独整理成一篇博客HTTPS