[Xpath] Xpath基础知识
1.Xpath(XML Path Language)介绍
Xpath用于在HTML文档中通过元素(HTML标签)和属性(HTML标签的属性)进行数据定位
Xpath的优势:灵活且稳定
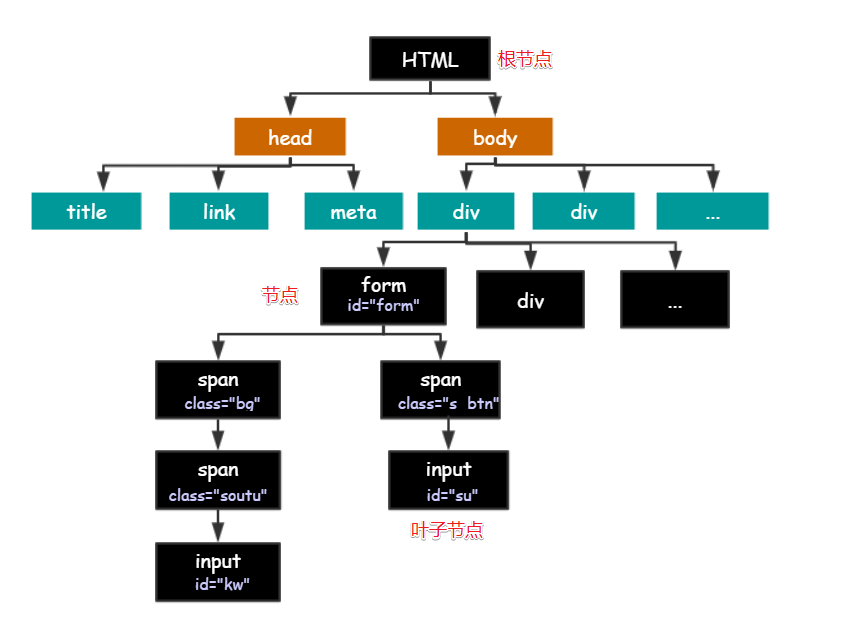
HTML的结构是树形结构,HTML是根节点,所有的其他元素节点都是从根节点发出的,其他元素都是这棵树上的节点Node,每个节点还可能有属性和文本
所有的HTML标签都有很强的层级关系,正是基于这种层级关系,Xpath语法能够选择出我们想要的数据
节点之间的关系
父节点(Parent):html 是 body 和 head 节点的父节点
子节点(Child):head 和 body 是 html 的子节点
兄弟节点(Sibling):拥有相同的父节点,head 和 body 就是兄弟节点,title 和 div 不是兄弟节点,因为他们不是同一个父节点
祖先节点(Ancestor):body 是 form 的祖先节点
后代节点(Descendant):form 是 html 的后代节点
Xpath中的绝对路径与相对路径
Xpath中的绝对路径从HTML根节点开始算,相对路径从任意节点开始
我们可以通过开发者工具,拷贝Xpath的绝对路径和相对路径
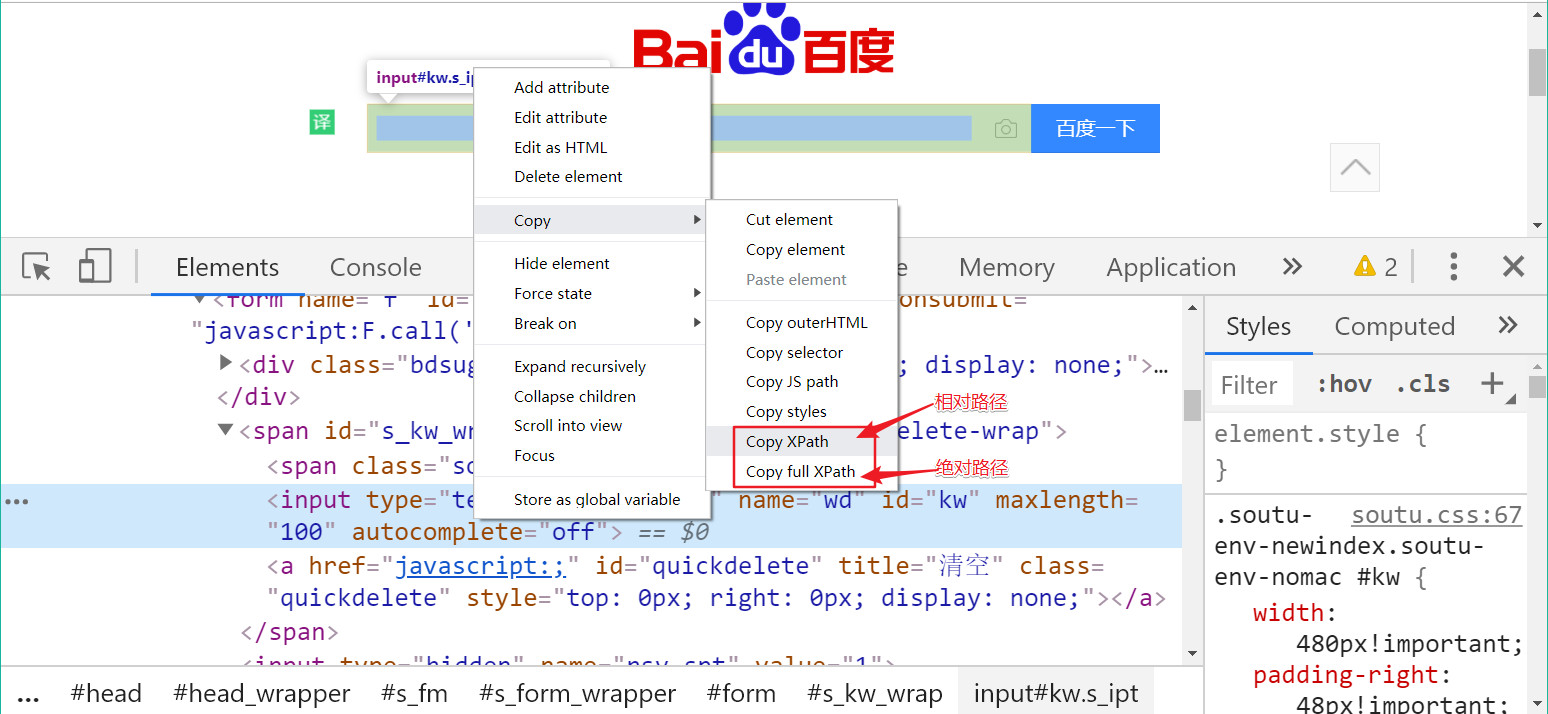
1.1 Xpath基础语法
| 表达式 | 描述 |
| / | 从根节点开始选取 |
| // | 从任意节点开始选取 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性或者根据属性选取 |
| * | 通配符,表示任意节点或任意属性 |
示例
1.如果想选择HTML文档中所有的<p>标签,使用的Xpath表达式://p
2.如果想选择拥有href属性的所有<a>标签,使用的Xpath表达式://a[@href]
用[]括号内添加@,将标签属性填入进去,将含有该标签属性的部分提取出来
3.如果想选择文本内容等于"Hello"的所有元素,使用的Xpath表达式://*[test()='Hello']
4.如果想选择所有<ul>标签的直接<li>子元素,使用的Xpath表达式://ul/li
5.如果想选择所有拥有id=u1的div标签下的所有节点,使用的Xpath表达式://div[@id='u1']/*
6.如果想选择所有拥有属性的meat标签,使用的Xpath表达式://meta[@*]
@*表示匹配任何属性节点
7.如果想选择所有的meat和title标签,使用的Xpath表达式://meta | //title
使用 | 来表示选择多个路径,等价于"和"或者"或"的效果
8.如果想选择所有<ul>标签的最后一个<li>子元素,使用的Xpath表达式://ul/li[last()]
9.如果想选择所有<ul>标签的倒数第二个<li>子元素,使用的Xpath表达式://ul/li[last()-1]
元素属性定位
① 根据属性名定位元素
定位具有特定属性名的元素:
//*[@attribute_name]
示例://*[@class] 会匹配所有具有 "class" 属性的元素
② 根据属性名和属性值定位元素
定位具有特定属性名和属性值的元素:
//*[@attribute_name='value']
示例://*[@id='myElement'] 会匹配 id 属性值为 "myElement" 的元素
③ 根据部分属性值定位元素
定位具有属性值包含特定文本的元素:
//*[contains(@attribute_name,'value')]
示例://*[contains(@class,'active')] 会匹配 class 属性值包含 "active" 的元素
④ 根据多个属性进行定位
定位具有多个属性及其对应值的元素:
//*[@attribute_name_1='value_1' and @attribute_name_2='value_2']
示例://*[@class='active' and @data-type='button'] 会匹配同时具有 class 属性值为"active" 和 data-type 属性值为 "button" 的元素
层级属性结合定位
① 定位父元素下的子元素
通过指定父元素和子元素的标签名来定位元素:
//父元素名/子元素名
② 定位特定属性的父元素下的子元素
通过指定父元素的属性和属性值,再结合子元素的标签名来定位元素
//父元素名[@属性名='属性值']/子元素名
示例://div[@class='container']/p 会匹配 class 属性为 "container" 的<div>元素下的所有<p>元素
③ 定位特定属性的父元素下的特定属性的子元素
通过指定父元素和子元素的属性条件来定位元素
//父元素名[@属性名1='属性值1']/子元素名[@属性名2='属性值2']
示例://ul[@id='menu']/li[@class='active'] 会匹配 id 属性为 "menu" 的<ul>元素下的class 属性为 "active" 的所有<li>元素
使用谓语定位
① 定位符合特定索引的元素
通过位置索引来定位元素(索引值从1开始)
//tagname[position()]
示例://ul/li[position() = 3] 可以匹配位于<ul>下的第三个<li>元素
//head/meta[position() < 3] 选择所有<head>下的前2个<meta>元素
//head/meta[last()] 选择所有<head>下的最后一个<meta>元素
//head/meta[k] 选择所有<head>下的第k个<meta>元素
提示Tips:[k]表示当前位置下的第k个元素
② 定位满足特定属性条件的元素
通过属性条件来定位元素
//tagname[@attribute='value']
示例://input[@type='text'] 可以匹配所有type属性值为"text" 的<input>元素
③ 结合多个条件定位元素
使用逻辑运算符and结合多个属性条件来定位元素
示例://a[@class='active' and @href='/home'] 可以匹配同时满足class属性值为 "active" 和href属性值为 "/home" 的<a>元素
④ 通过文本内容定位元素
通过文本内容来定位元素
//tagname[text()='value']
示例://h1[text()='Welcome'] 可以匹配文本内容为 "Welcome" 的<h1>元素
使用逻辑运算符定位
① 使用 and 运算符
通过结合多个属性条件,使用and运算符定位元素
//tagname[@attribute1='value1' and @attribute2='value2']
示例://input[@type='text' and @name='username'] 可以匹配type属性为"text"且name属性为"username"的<input>元素
② 使用 or 运算符
通过结合多个属性条件,使用or运算符定位元素
//tagname[@attribute1='value1' or @attribute2='value2']
示例://a[@class='active' or @class='highlight'] 可以匹配class属性为"active"或"class"属性为"highlight"的<a>元素
③ 使用 not 运算符
使用not运算符否定一个属性条件,定位不满足该条件的元素
//tagname[not(@attribute='value')]
示例://div[not(@class='header')] 可以匹配class属性不为"header"的<div>元素
使用文本定位
① 定位文本内容相等的元素
匹配文本内容与指定值相等的元素
//tagname[text()='value']
示例://a[text()='Login'] 可以匹配文本为"Login"的所有<a>元素
② 定位包含指定文本内容的元素
匹配包含指定值的文本内容的元素
//tagname[contains(text(), 'value')]
示例://p[contains(text(), 'Lorem ipsum')] 可以匹配包含"Lorem ipsum"文本的所有<p>元素
③ 根据包含特定关键词的文本内容定位元素
匹配文本内容中包含特定关键词的元素
//tagname[contains(text(), 'keyword')]
示例://h2[contains(text(), 'Contact')] 可以匹配文本内容中包含"Contact"关键词的<h2>元素
使用函数定位
| 函数 | 说明 | 举例 |
| contains | 选取属性或者文本包含某些字符 | //div[contains(@id, 'data')] 选取 id 属性包含 data 的 div 元素 |
| starts-with | 选取属性或者文本以某些字符开头 | //div[starts-with(@id, 'data')] 选取 id 属性以 data 开头的 div 元素 |
| ends-with | 选取属性或者文本以某些字符结尾 | //div[ends-with(@id, 'require')] 选取 id 属性以 require 结尾的 div 元素 |
轴方式定位
轴表达式说明
parent::* :表示当前节点的父节点元素
ancestor::* :表示当前节点的祖先节点元素
child::* :表示当前节点的子元素
descendant::* 表示当前节点的后代元素
self::* :表示当前节点的自身元素
ancestor-or-self::* :表示当前节点本身以及它的祖先节点元素
descendant-or-self::* :表示当前节点本身以及它的后代元素
following-sibling::* :表示当前节点的后序所有兄弟节点元素
preceding-sibling::* :表示当前节点的之前所有兄弟节点元素
following::* :表示当前节点的结束标签之后的所有节点元素
preceding::* :表示当前节点的开始标签之前的所有节点元素
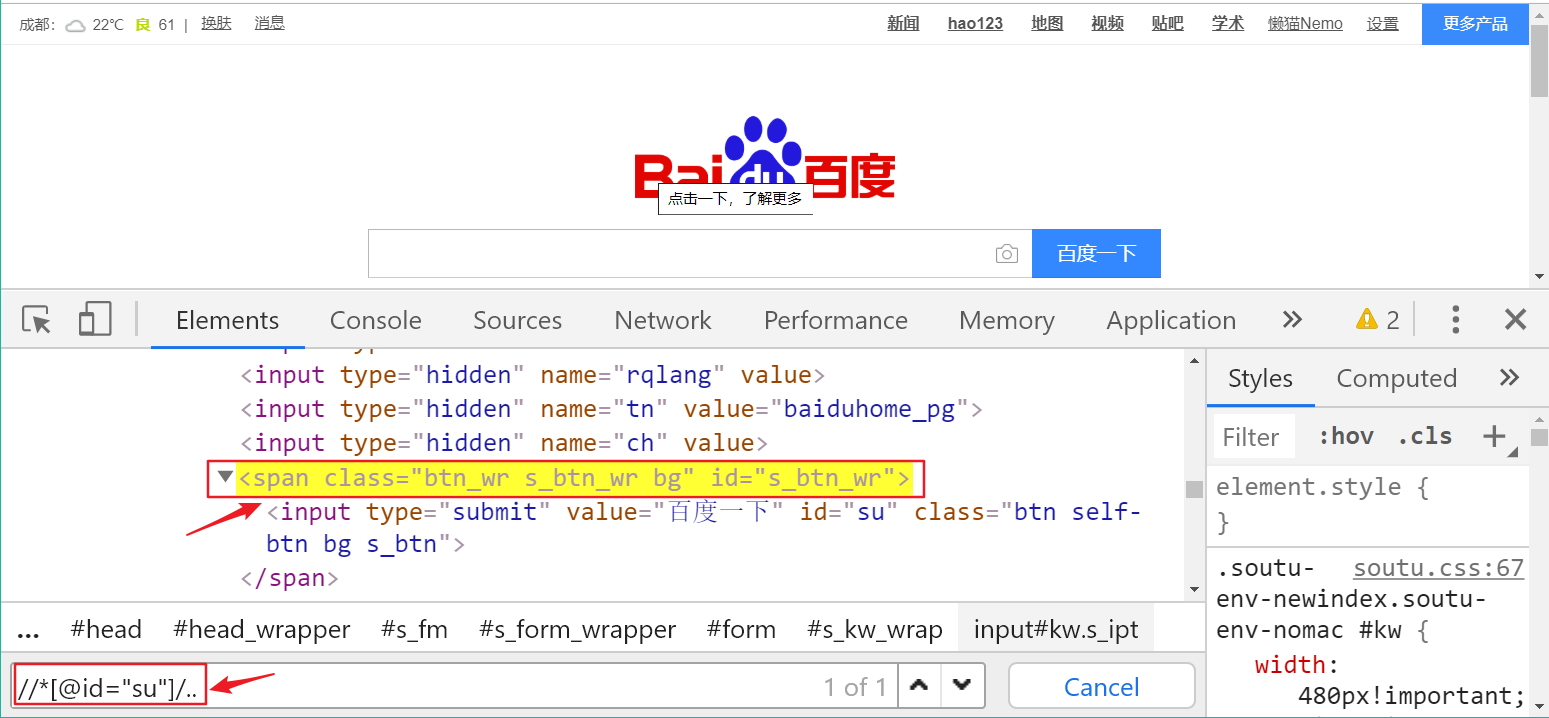
① parent::* 表示当前节点的父节点元素
//div[@class="cell" and text()='1338']/parent::*
 如上图所示,我们要定位到商品ID为1338元素的父节点元素,可以使用上面的xpath轴定位, “*” 表示匹配所有
如上图所示,我们要定位到商品ID为1338元素的父节点元素,可以使用上面的xpath轴定位, “*” 表示匹配所有
② following-sibling::* 表示当前节点的后序所有兄弟节点元素
//div[3]/table/tbody/tr[1]/td[1]/following-sibling::*
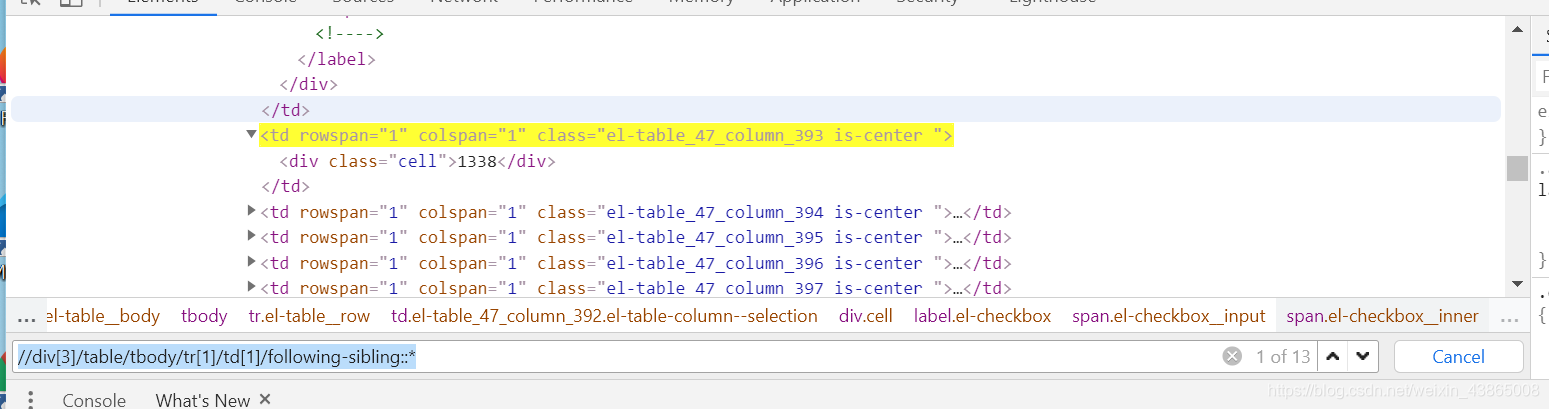
查找td[1]下同级的所有节点,“*”表示所有
③ parent::* 表示当前节点的父节点元素
/bookstore/book[2]/year/parent::*
④ descendant::* 表示当前节点的所有后代元素
/bookstore/book[2]/descendant::*
1.2 Xpath语法验证
在开发者工具的 Elements 中按Ctrl + F,在搜索框中输入 Xpath
1.3 lxml的基本使用
Python中的lxml库能够将html字符串进行解析,供Xpath语法进行数据提取
# 导入模块
from lxml import etree
# html源代码
web_data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
# 使用etree.HTML将字符串解析为HTML文档
element = etree.HTML(web_data)
# 打印解析后的html文档
# result = etree.tostring(element,encoding='utf-8').decode('utf-8')
# 使用xpath函数填写相应的Xpath语法完成内容提取(xpath函数提取数据返回的结果是列表)
# 获取li标签下面的a标签的href
links = element.xpath('//ul/li/a/@href')
print(links) # ['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
# 获取li标签下面的a标签的文本数据
items = element.xpath('//ul/li/a/text()')
print(items) # ['first item', 'second item', 'third item', 'fourth item', 'fifth item']补充扩展:使用Xpath提取指定内容信息以后,存储全部信息
