Linux进阶命令-sortwc
作者介绍:简历上没有一个精通的运维工程师。希望大家多多关注作者,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。

经过上一章Linux日志的讲解,我们对Linux系统自带的日志服务已经有了一些了解。我们接下来将讲解一些进阶命令,主要从以下几个方面来讲解:一些系统操作,系统查看处理,Linux文本处理,逻辑判断,重定向,网络传输,服务启动,文件句柄等内容。通过这些操作,让你对Linux的操作更加得心应手,具体分成以下章节进行讲解:
Linux进阶命令-echo&date&alias
Linux进阶命令-top
Linux进阶命令-ps&kill
Linux进阶命令-sort&wc(本章节)
Linux进阶命令-sed&split
Linux进阶命令-awk&uniq
Linux进阶命令-逻辑或&逻辑与
Linux进阶命令-重定向
Linux进阶命令-scp
Linux进阶命令-rsync
Linux进阶命令-rsync-daemon
Linux进阶命令-nohup&screen
Linux进阶命令-lsof
Linux进阶命令-小结
在前面几小节,我们讲了关于linux系统的一些命令,我们来接着讲一些对文件的进阶操作的命令。
sort
sort 命令用于对文本文件的内容进行排序。它默认按照字母顺序对每行进行排序,但也可以通过选项指定按照数字、日期等其他方式排序。sort 命令通常与管道(|)结合使用,以处理输出结果或对文本数据进行排序操作。
基本语法
sort [options] [file]-
options:排序选项,用于指定排序的方式。 -
file:要排序的文件名。如果不指定文件名,则从标准输入读取数据。
常用选项
-r 或 --reverse:反向排序,即降序排列。
sort -r file.txt-n 或 --numeric-sort:按照数值大小排序(而不是按照字典顺序)。
sort -n file.txt-k 字段1,字段2 或 --key=字段1,字段2:按照指定的字段进行排序。字段是基于空格分隔的,默认情况下整行都参与排序。
sort -k 2,2 file.txt-t 分隔符 或 --field-separator=分隔符:指定字段分隔符,默认为制表符。
sort -t : -k 3,3 /etc/passw-u 或 --unique:去除重复行,仅保留唯一的行。
sort -u file.txt-o 输出文件 或 --output=输出文件:将排序后的结果输出到指定文件中。
sort -o sorted_file.txt file.txt示例
-
对文件
file.txt按字母顺序排序并输出到终端:
sort file.txt对文件 numbers.txt 中的数字按数值大小降序排序:
sort -nr numbers.txt去除文件 names.txt 中的重复行并输出到新文件 unique_names.txt:
sort -u names.txt -o unique_names.txt使用场景
-
文本文件排序: 对文本文件中的内容按照不同的规则排序,如字母顺序、数值大小等。
-
数据处理:在数据处理流水线中,用于处理和整理输出结果。
-
文件比较: 将文件排序后与其他文件进行比较,查找差异或合并操作。
wc
wc 命令是一个用于统计文件中字节数、字数、行数的工具。它的名字代表 "word count",尽管它的功能不仅限于统计单词。wc 命令通常用于命令行环境,特别是在处理文本文件时,用来快速获取文件的基本统计信息。
基本语法
wc [options] [file]-
options:可选参数,用于指定输出的格式或增加额外的统计信息。 -
file:要统计的文件名。如果不指定文件名,则从标准输入读取数据。
常用选项
-l:统计文件中的行数。
wc -l file.txt-w:统计文件中的字数(单词数)。
wc -w file.txt-c:统计文件中的字节数。
wc -c file.txt-m:统计文件中的字符数(比 -c 更精确,包括换行符)。
wc -m file.txt-L:找出文件中最长行的长度。
wc -L file.txt示例
-
统计文件
file.txt的行数、字数和字节数
wc file.txt输出格式为:
10 20 150 file.txt使用场景
-
文件分析: 快速了解文本文件的大小、行数和字数。
-
脚本编程: 在脚本中用来检查输出结果的字符数或行数。
-
数据处理: 在数据处理管道中用来验证文件大小或内容的简单统计。
总结
1.sort主要是用于排序,现在主要用于对前面输出部分通过管道进行排序,已经对于文件的统计操作比较少。
2.wc 我用得比较多的就是统计文件行数。
3.比如在统计nginx日志里面的就会用到,先用命令取出来访问者的ip,然后排序,去重,再统计数量。
[root@localhost nginx]# awk '{print $1}' access.log |sort |wc -l
60 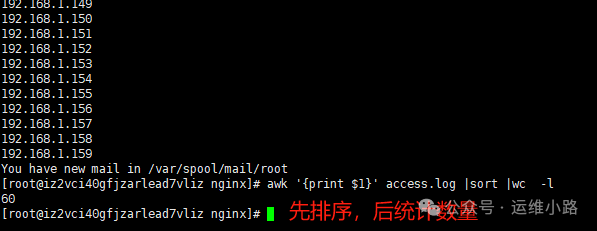

运维小路
一个不会开发的运维!一个要学开发的运维!一个学不会开发的运维!欢迎大家骚扰的运维!
关注微信公众号《运维小路》获取更多内容。