聊点基础的,关于监控,关于告警(prometheus—+grafana+夜莺如何丝滑使用?)
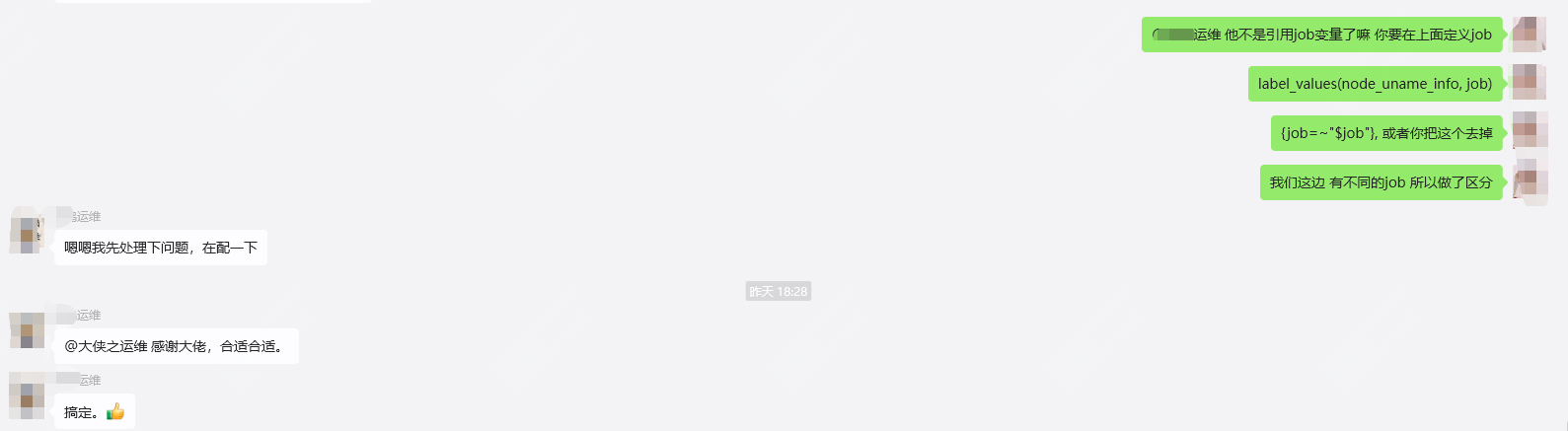
事情的起因是这样的,昨天又群友在群里咨询一个关于grafana和prometheus配置文件的用法,整了半天也没回复,正好知道就帮了一把,今天整理成文章,希望帮到更多的朋友
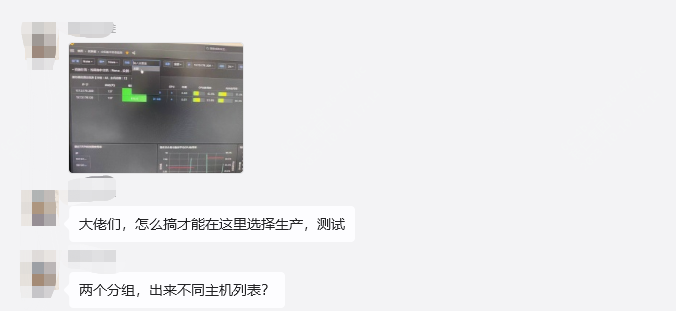
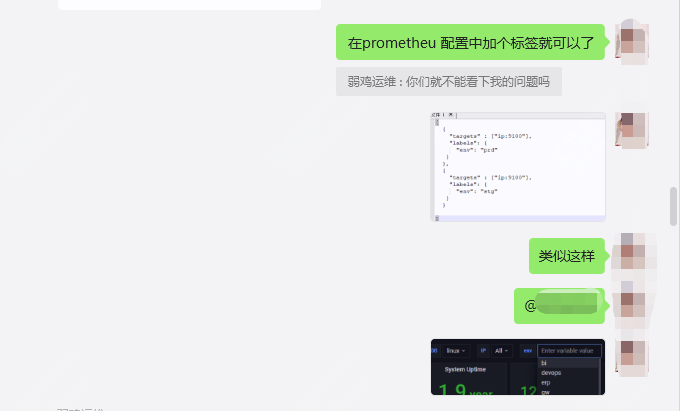
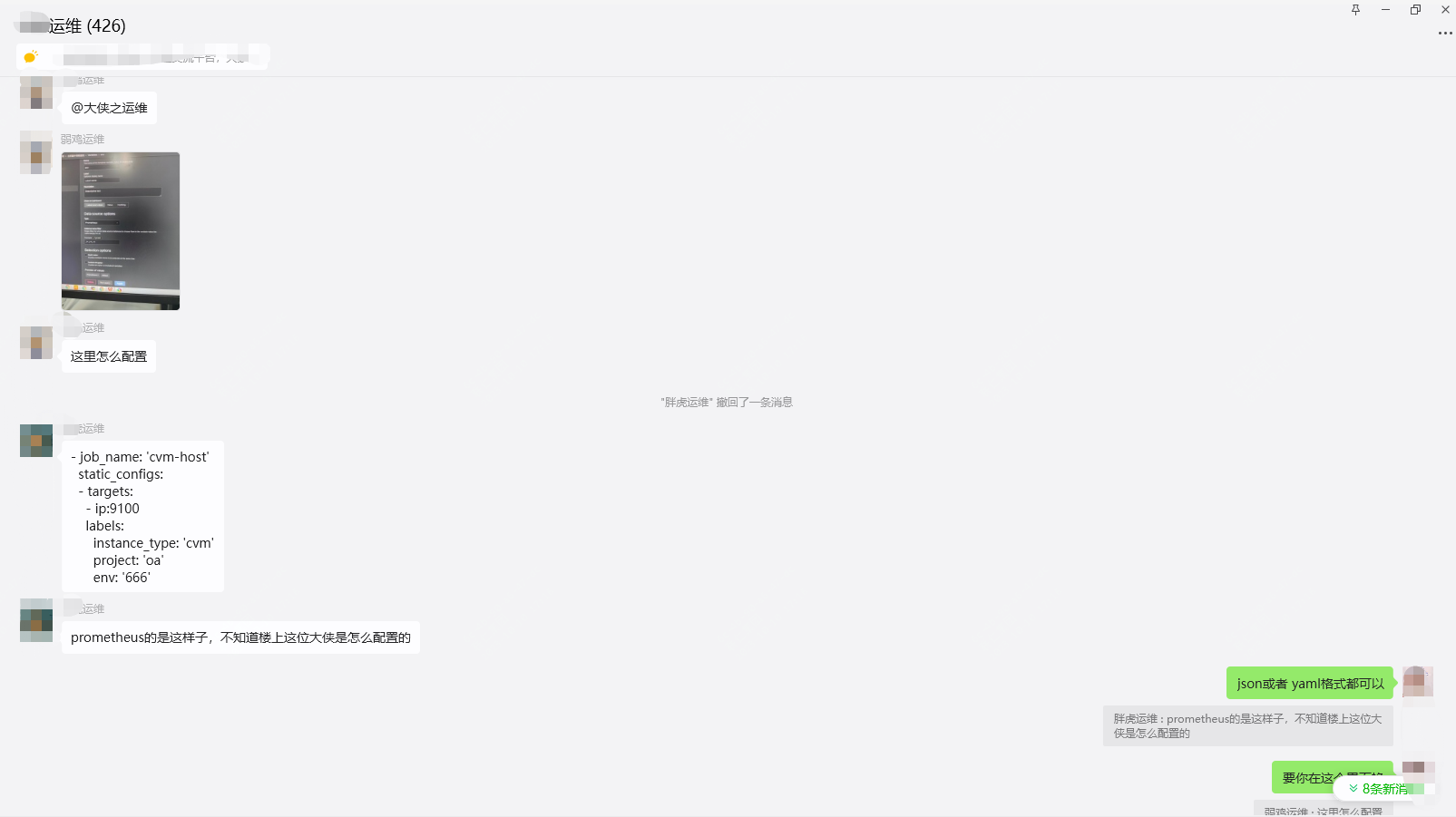
大致问题的话就是图里面提到的几个,其实都是一些日常的用法了!!
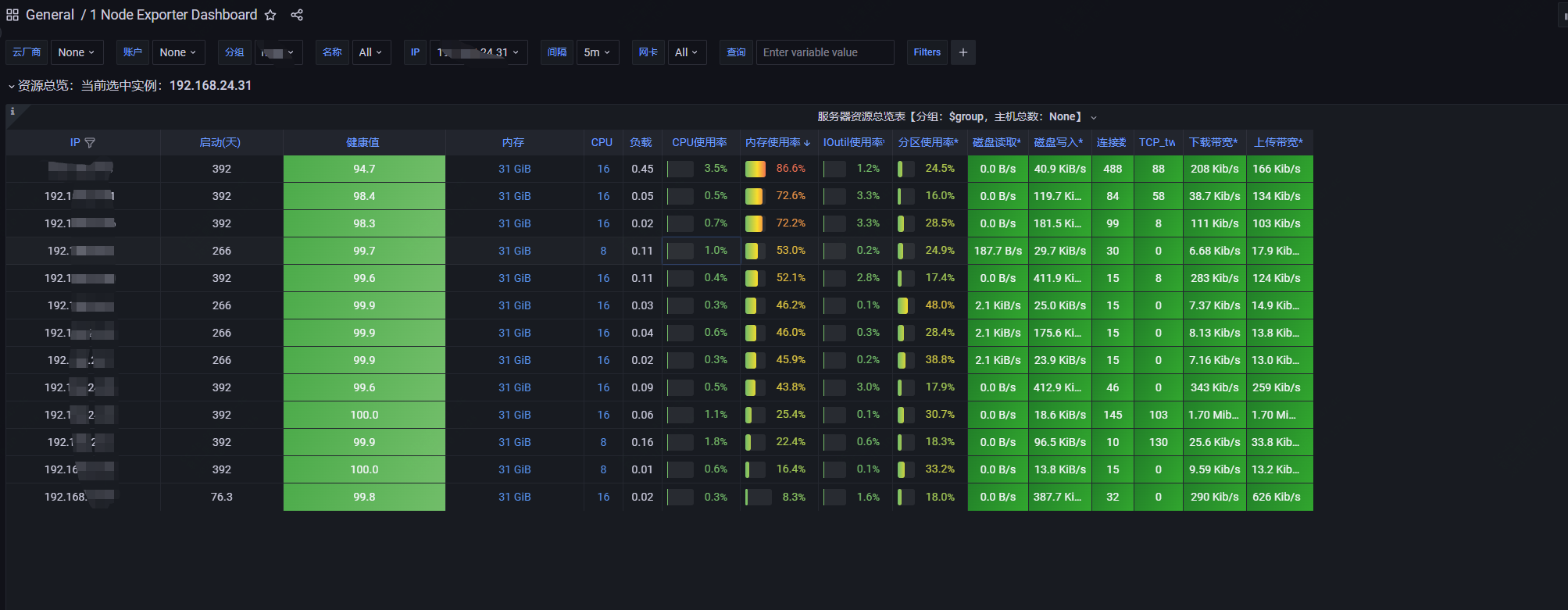
先来看下,我们目前生产的一个示例,可以根据不同的维度去筛选:
上面有两个同学有问题,一个是如何实现筛选?还有就是prometheus的配置文件如何配置?
要能够筛选,第一步是需要配置文件修改,先得给不同的主机打标签
这里给出我们生产的配置文件作为参考:
prometheus主配置文件:
- job_name: linux
file_sd_configs:
- refresh_interval: 1m
files:
- config_exporter.json
relabel_configs:
- source_labels: [__address__]
regex: (.*):(\d+)
target_label: instance
replacement: $1
关于主机信息的配置在如下配置文件中“config_exporter.json”
{
"targets" : ["ip1:9100"],
"labels": {
"env": "stg"
}
},
{
"targets" : ["ip2:9100"],
"labels": {
"env": "prd"
}
}
]
打了标签之后就可以在prometheus中根据env做筛选了
然后你要在grafana中配置,可以根据需要去调整:
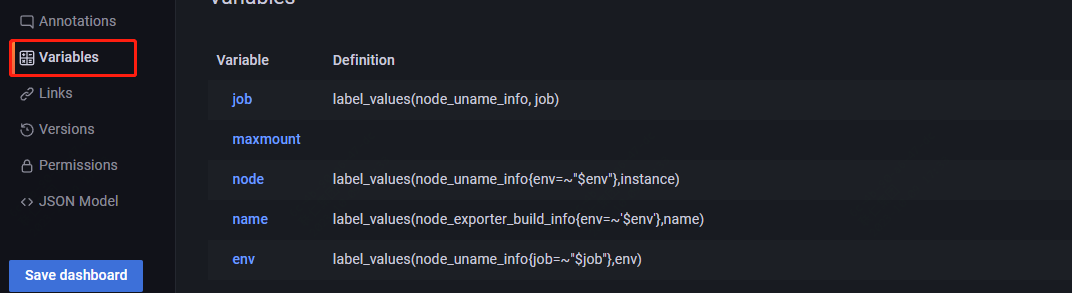
然后就解决了:
除了上面的内容外,也介绍下另外一个内容
不知道大家目前的日志监控是怎么做的?是用的kibana的插件?还是elasalert?或者是其它的方式
因为我们用的是elk是8.0版本的,所以一些插件目前无法使用,elasalert调研了下也不是很理想,所以索性自己写了个脚本,大致的思路是
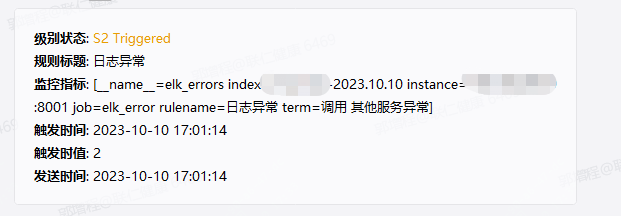
脚本根据配置的关键字策略去elk中查找–然后生成prometheus的指标–通过夜莺去告警
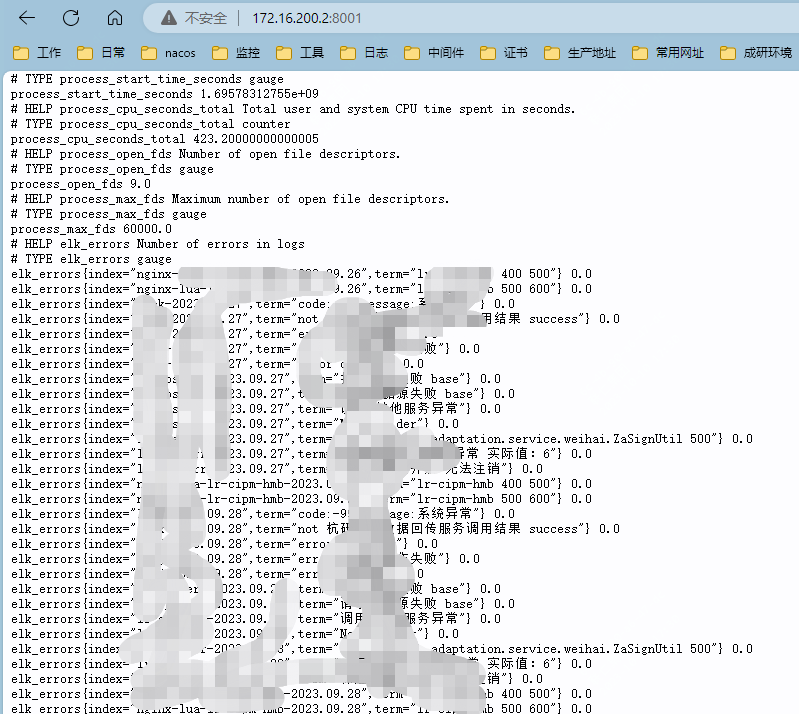
prometheus中数据如下
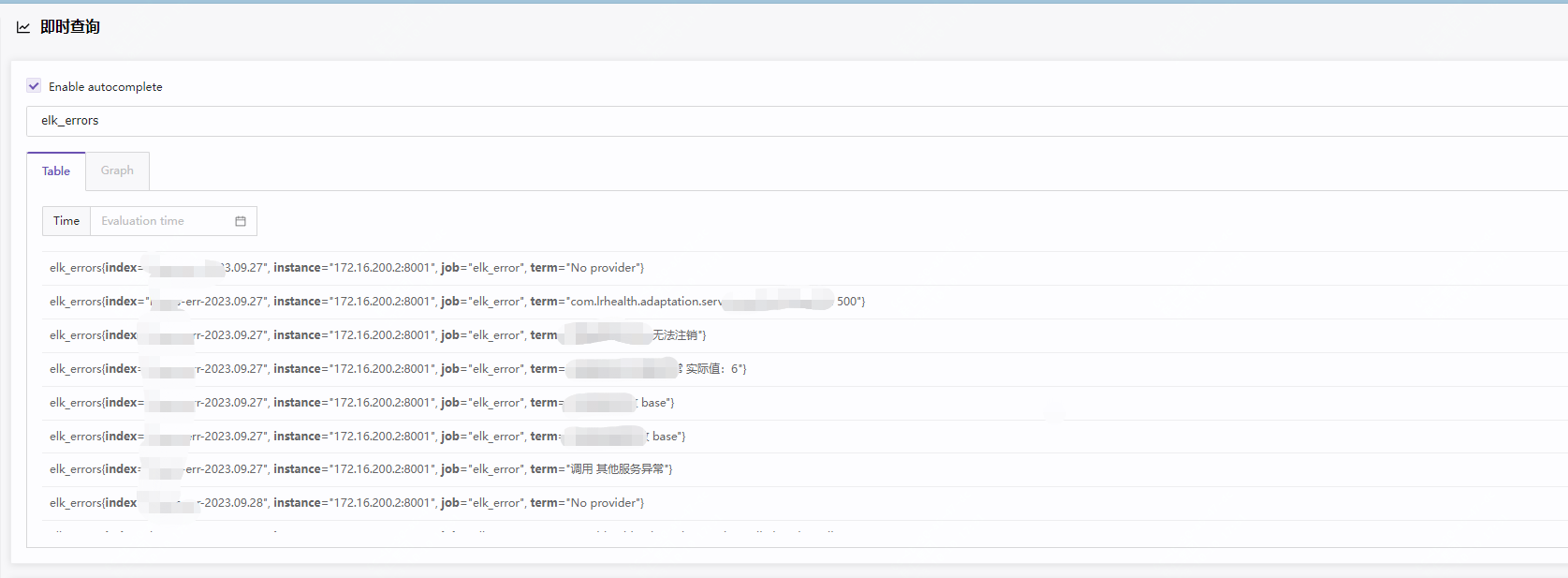
然后就可以根据实际业务需要配置具体的告警策略了,关于告警配置啥的之前的文章都有介绍过,可以去翻下。
关于日志监控部分代码如下可以参考.写的很粗糙,也有一些问题:
from elasticsearch import Elasticsearch
from prometheus_client import Counter, start_http_server,Gauge
import time
import json
from datetime import datetime,timedelta
# Elasticsearch 配置
ELASTICSEARCH_HOST = ""
ELASTICSEARCH_PORT = 9200
ELASTICSEARCH_USER = "elastic"
ELASTICSEARCH_PASSWORD = ""
# Prometheus 监控指标
ERRORS = Gauge("elk_errors", "Number of errors in logs", ["index", "term"])
# Elasticsearch 实例化
es = Elasticsearch(
[f"https://{ELASTICSEARCH_HOST}:{ELASTICSEARCH_PORT}"],
http_auth=(ELASTICSEARCH_USER, ELASTICSEARCH_PASSWORD),
ca_certs = './http_ca.crt',
verify_certs=True
)
def load_config():
with open(config_file, "r", encoding='utf-8') as f:
config_data = f.read()
config = eval(config_data) # 将字符串转换为字典
return config
# 定时执行 Elasticsearch 查询并更新 Prometheus 监控指标
def update_metrics():
for index in ES_QUERY.keys():
for term in ES_QUERY.get(index):
print (index)
if term.startswith("not "):
query = {
"query": {
"bool": {
"must": [{"match_phrase": {"message":term.split()[1]}}],
"must_not":[{"match_phrase": {"message":term.split()[2]}}],
"filter": {"range": {"@timestamp": {"gte": "now-5m","lte": "now"}}}
}
}
}
elif index.startswith("nginx"):
query = {
"query": {
"bool": {
"must": [
{"match_phrase": {"app_name": term.split()[0]}},
{"range": {"status": {"gte": term.split()[1], "lt": term.split()[2]}}}
],
"filter": {"range": {"@timestamp": {"gte": "now-5m", "lte": "now"}}}
}
}
}
else:
query = {
"query": {
"bool": {
"must": [
{"match_phrase": {"message":term.split()[0]}},
{"match_phrase": {"message":term.split()[1]}}
],
"filter": {"range": {"@timestamp": {"gte": "now-5m","lte": "now"}}}
}
}
}
try:
res = es.search(index=index, body=query)
ERRORS.labels(index, term).set(res["hits"]["total"]["value"])
except Exception as e:
# 处理异常情况
print("Elasticsearch search error:", e)
# 启动 Prometheus HTTP 服务器并定时执行 Elasticsearch 查询
if __name__ == "__main__":
start_http_server(8001)
while True:
today = datetime.now().strftime("%Y.%m.%d")
yesterday = datetime.now() - timedelta(days=1)
yesterday_str = yesterday.strftime("%Y.%m.%d")
ES_QUERY = load_config()
new_config = load_config()
if ES_QUERY != new_config: # 如果新配置和旧配置不一样,则更新变量值
print("Config updated:", new_config)
ES_QUERY = new_config
update_metrics()
time.sleep(60)