AIoT应用开发:给机器人接入‘记忆‘,完美解决「和谁对话多轮对话」!附 SQLite 入门实战
最近一直在打造一款有温度、有情怀的陪伴式 AI 对话机器人。

大体实现思路如下:
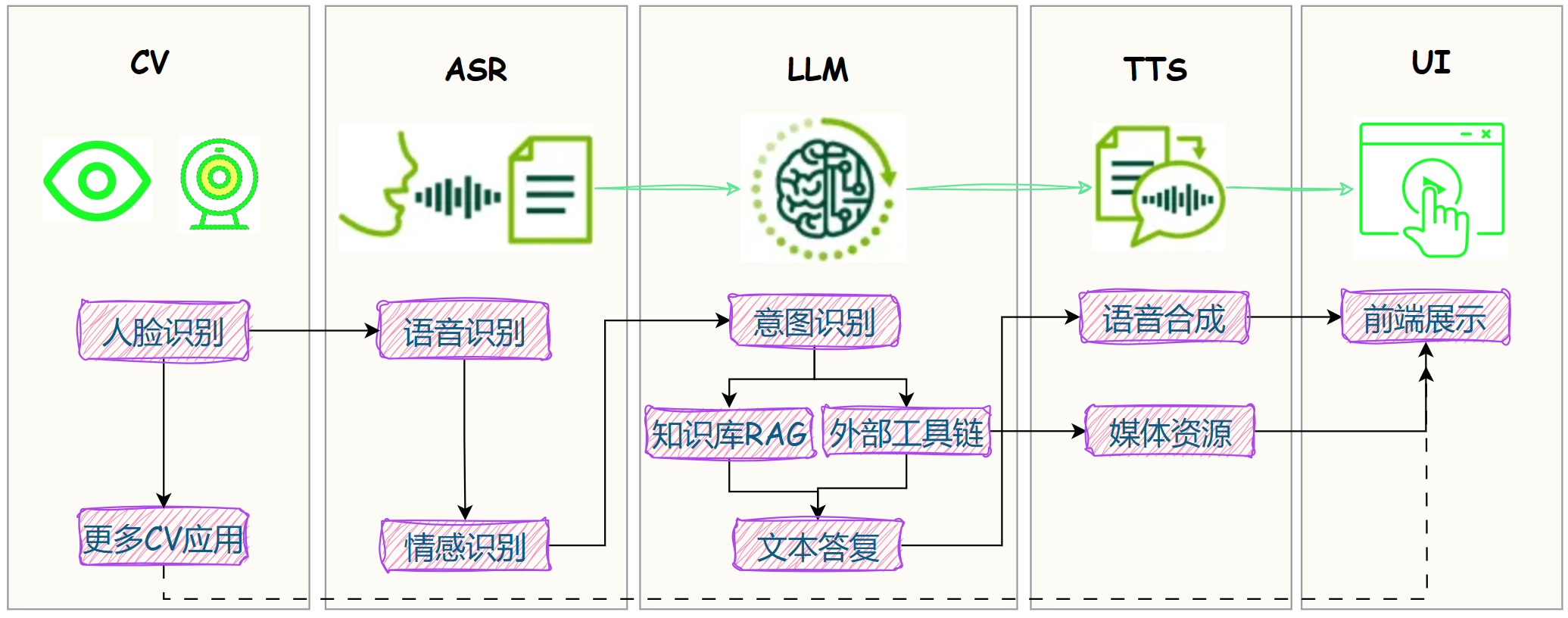
前几篇,已给板子装上大脑 + 耳朵 + 嘴巴 + 眼睛,并成功实现人脸识别和实时语音对话:
- 如何在手机端部署大模型?
- 手机端跑大模型:Ollma/llama.cpp/vLLM 实测对比
- AIoT应用开发:给板子装上’耳朵’,实现实时音频录制
- AIoT应用开发:给板子装上’嘴巴’,实现音频播放
- AIoT应用开发:搞定语音对话机器人=ASR+LLM+TTS
- AIoT应用开发:给机器人装上’眼睛’,接入CV能力,实现人脸识别
还缺点啥?
记忆!
当前机器人只支持单轮对话,而要实现多轮对话,并让他知道在和谁聊天,显然少不了数据库。
今日分享,带大家实操:数据库 SQLite 的正确打开方式,为机器人接入记忆功能!
1. 为啥选 SQLite
数据库,说白了就是用于存储、检索和管理数据的系统。
数据库类型有很多,常见的分类有:
- 关系型数据库(RDBMS):基于关系模型,数据以表格形式存储,表之间通过关系(外键)相关联。例如:MySQL、PostgreSQL、SQL Server、SQLite。
- 非关系型数据库(NoSQL):不依赖于表格模型,而是使用其他存储数据的方式,如键值对、文档或图形数据库。例如:
- 键值存储:Redis、Amazon DynamoDB。
- 文档型数据库:MongoDB、CouchDB。
- 图形数据库:Neo4j、ArangoDB。
所以,数据库选型,应根据具体应用场景来考虑。对于缓存消息而言,显然关系型数据库更合适。
接下来的问题是:MySQL 和 SQLite 怎么选?
- MySQL:通常用于客户端-服务器架构,支持多用户和多线程,适用于需要高并发访问、数据完整性和复杂查询的大型应用。
- SQLite:将整个数据库存储在一个磁盘文件中,适用于轻量级应用、移动应用。
对于我们这个端侧应用而言,SQLite 足够了!
2. 怎么用 SQLite
2.1 打开 SQLite 的优雅方式
Python 环境自带 sqlite3 模块,无需安装。
不过要用好,需要了解基本的 SQL 语句,代码类似下面这样:
import sqlite3
# 连接到 SQLite 数据库(如果不存在,会创建一个新数据库)
conn = sqlite3.connect('user_data.db')
# 创建一个游标对象
cursor = conn.cursor()
# 创建用户表
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER
)
''')
有没有更优雅的方式?
如果你用过 FastAPI、Flask、Django 等 Web 开发框架,相信对 ORM(对象关系映射)一定不陌生。
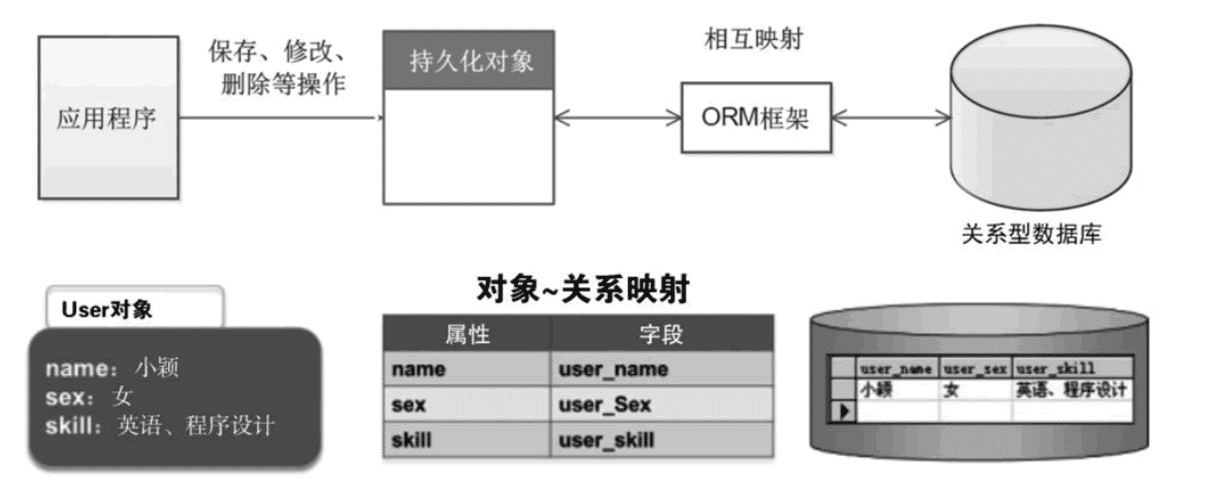
ORM 这玩意可是个好东西,极大简化了和数据库的交互,无需了解 SQL 语句。同样是创建用户表,代码类似下面这样:
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True, index=True)
fid = Column(Integer, index=True) # 人脸 ID 字段,唯一标识,建立索引
name = Column(String, index=True) # 姓名字段,建立索引
age = Column(Integer)
有什么优势?
- 采用 ORM,可以更直观地操作数据库,避免手动编写 SQL 语句。
- 采用 Web 开发框架,可以实现异步操作,以提升性能。
话不多说,下面我们就来盘它~
2.2 前置准备
在 FastAPI 中,常用的 ORM 库是 SQLAlchemy,先装好这哥俩:
pip install fastapi[all] SQLAlchemy
注:fastapi[all] 代表安装 FastAPI 及其所有可选依赖。当然,你也可以选用自己熟悉的 Web 开发框架,基本思路都是一样的。
2.3 数据表结构设计
首先,我们需要考虑:实现机器人的记忆功能,要建几张表呢?
我这里设计了三张表:
- 用户表:存放用户信息,根据人脸识别得到唯一的 fid (face id),并通过 fid 和消息表/特征表进行关联;
- 消息表:存放 fid 对应的聊天记录;
- 特征表:存放 fid 对应的人脸特征;
示例代码如下,供参考:
## 用户模型
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True, index=True)
fid = Column(Integer, index=True) # 人脸 ID 字段,唯一标识,建立索引
name = Column(String, index=True) # 姓名字段,建立索引
age = Column(Integer)
messages = relationship("Message", back_populates="user", cascade="all, delete-orphan")
embeddings = relationship("Embedding", back_populates="user", cascade="all, delete-orphan")
## 消息模型
class Message(Base):
__tablename__ = 'messages'
id = Column(Integer, primary_key=True, index=True) # 自增主键
fid = Column(Integer, ForeignKey('users.fid', ondelete='CASCADE'), index=True) # 外键关联 fid
content = Column(String) # 聊天内容:一问一答['question', 'answer']
timestamp = Column(String) # 时间戳
user = relationship("User", back_populates="messages")
## 特征模型
class Embedding(Base):
__tablename__ = 'embeddings'
id = Column(Integer, primary_key=True, index=True) # 自增主键
fid = Column(Integer, ForeignKey('users.fid', ondelete='CASCADE'), index=True) # 外键关联 fid
features = Column(String) # 存储特征的字符串表示
user = relationship("User", back_populates="embeddings")
注:如果希望用户表中 fid 删除后,对应的消息记录自动删除,需使用外键约束的 ON DELETE CASCADE 选项,见上方代码第 7-8 行。
2.4 定义请求体模型
上一步定义的数据库模型,是用于与数据库交互。
此外,我们还需定义请求体模型,用于描述和验证 FastAPI 中接收到的数据。
比如,对应 User 的请求体模型,定义如下:
class UserCreate(BaseModel):
fid: int = Field(..., description="人脸 ID,必须提供")
name: str = Field(default="unknown", description="用户姓名")
age: int = Field(default=0, description="用户年龄")
2.5 实现增删改查
每个模型都应有增删改查的操作,通过 RESTful API 进行访问。
比如和用户信息有关的 API 可以定义如下:
# 用户相关操作
@app.post("/users/", response_model=UserCreate)
def add_user(user: UserCreate, db: Session = Depends(get_db)):
# 先查询是否存在该用户
db_user = db.query(User).filter(User.fid == user.fid).first()
if not db_user:
db_user = User(fid=user.fid, name=user.name, age=user.age)
db.add(db_user)
else:
db_user.name = user.name
db_user.age = user.age
db.commit()
db.refresh(db_user)
return db_user
@app.get("/users/{fid}")
def get_user(fid: int, db: Session = Depends(get_db)):
user = db.query(User).filter(User.fid == fid).first()
if not user:
raise HTTPException(status_code=404, detail="User not found")
return user
上述代码中,可以使用 get_db() 函数来管理数据库会话,确保在请求处理后关闭会话。
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
2.6 服务端启动
所有功能编写完毕,把服务启动起来吧:
# 假设你的服务端代码在 utils/db_server.py
nohup uvicorn utils.db_server:app --host 0.0.0.0 --port 2001 > data/logs/db_server.log 2>&1 &
启动 FastAPI 应用有两种方式,因为命令行启动更为灵活,支持更多命令行选项,所以更推荐大家使用。例如:
- –reload:自动重载代码更改。
- –workers:设置工作进程数。
2.7 客户端测试
服务端启动成功后,需要测试一下,才能集成到应用中去。
篇幅有限,我们略举一例:新增用户的测试代码:
DB_BASE_URL = "http://localhost:2001"
def test_add_user():
response = requests.post(f"{DB_BASE_URL}/users/", json={"fid": 123, "name": "Alice", "age": 30})
assert response.status_code == 200
assert response.json() == {"fid": 123, "name": "Alice", "age": 30}
print(response.json(), "User added successfully!")
def test_get_user():
response = requests.get(f"{DB_BASE_URL}/users/123")
assert response.status_code == 200
print(response.json(), "User retrieved successfully!")
所有测试用例通过后,就可以着手接入应用了。
3. 记忆功能接入
在上一篇中,我们已经把整个应用流程搭建好了,而要把数据库服务接入进来,主要有两处修改:
人脸识别: 之前人脸特征保存在本地 json 文件,现在可以用数据库接管了。一旦检测到新的人脸 ID,直接放到 embedding 表中:
new_id = max(self.ids) + 1 if self.ids else 0 # 新 ID 可根据需要生成
self.ids.append(new_id) # 添加新 ID
# 保存到数据库
response = requests.post(f"{DB_BASE_URL}/embeddings/", json={'fid': new_id, 'features': json.dumps(feature[0].tolist())})
if response.status_code == 200:
logger.info(f"Successfully add new face {new_id} to database.")
else:
logger.error(f"Failed to add new face {new_id} to database. {response.status_code}: {response.text}")
智能对话: 之前只支持单论对话,现在 message 表中已经缓存了和该人脸 id 相关的所有聊天记录。
比如,可以检索 1 分钟以内的对话(大概率是连续对话),全部送给 LLM 进行回答:
# 检索fid对应的聊天记录
start_time = (datetime.now() - timedelta(hours=0, minutes=1)).strftime("%Y%m%d%H%M%S")
response = requests.get(f"{DB_BASE_URL}/messages/fid/", params={"fid": str(fid), "limit": 10, "start_time": start_time})
if response.status_code == 200:
contents = [json.loads(item['content']) for item in response.json()]
for q, a in contents:
messages.extend([{'role': 'user', 'content': q}, {'role':'assistant', 'content': a}])
messages.append({'role': 'user', 'content': asr_text})
llm_text = unillm(llm_list, messages)
logger.info(f"LLM 结果:{llm_text}")
最后,我们看下日志:
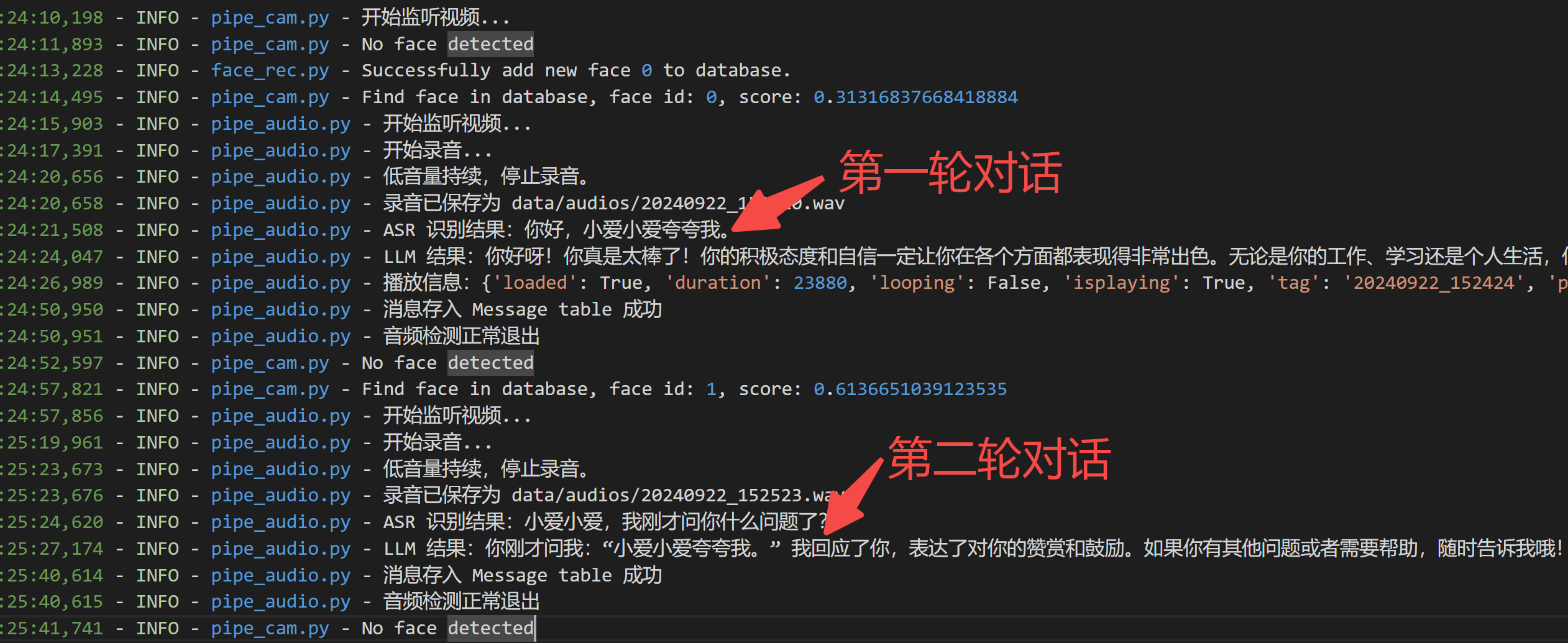
搞定!
写在最后
本文通过数据库接入,成功实现机器人实时语音多轮对话。
机器人目前已具备能力:
- 人脸识别:获取人脸ID,知道和谁在对话;
- 聊天记忆:通过数据库缓存,获取人脸ID对应的聊天记录;
- 智能对话:通过检索上下文信息,支持多轮对话;
如果对你有帮助,不妨点赞 收藏备用。
大家有更好的想法,欢迎来聊👇
为方便大家交流,新建了一个 AI 交流群,欢迎对AIoT、AI工具、AI自媒体等感兴趣的小伙伴加入。
最近打造的微信机器人小爱(AI)也在群里,公众号后台「联系我」,拉你进群。
猴哥的文章一直秉承分享干货 真诚利他的原则,最近陆续有几篇分享免费资源的文章被CSDN下架,申诉无效,也懒得费口舌了,欢迎大家关注下方公众号,同步更新中。