18.1 k8s服务组件之4大黄金指标讲解
本节重点介绍 :
- 监控4大黄金指标
- Latency:延时
- Utilization:使用率
- Saturation:饱和度
- Errors:错误数或错误率
- apiserver指标
- 400、500错误qps
- 访问延迟
- 队列深度
- etcd指标
- kube-scheduler和kube-controller-manager
监控4大黄金指标
Google的Google SRE Books一书中提出了系统监控的四个黄金指标
- Latency:延时
- Utilization:使用率
- Saturation:饱和度
- Errors:错误数或错误率
为什么是这4个
- 这个四个黄金指标在在任何系统中都是很好的性能状态指标
- 他们之所以被称为”黄金“指标,很大一个因素是因为他们反映了终端用户的感知
- 因此任何监控系统都会提供被监控对象的这些指标或其变形,并在此基础上辅助
两种系统分类
- 资源提供系统 : 对外提供简单的资源,比如CPU(计算资源),存储,网络带宽
- 服务提供系统 : 对外提供更高层次与业务相关的任务处理能力,比如订票,购物等等
站在资源角度分析
- Utilization :往往体现为资源使用的百分比
- Saturation : 资源使用的饱和度或过载程度,过载的系统往往意味着系统需要辅助的排队系统完成相关任务
- 以CPU为例,Utilization往往是CPU的使用百分比
- Saturation则是当前等待调度CPU的线程或进程队列长度
- Errors : 这个可能是使用资源的出错率或出错数量,比如网络的丢包率或误码率等等
站在服务角度分析
- Rate : 单位时间内完成服务请求的能力
- Errors : 错误率或错误数量:单位时间内服务出错的比列或数量
- Duration : 平均单次服务的持续时长(或用户得到服务响应的时延)
k8s服务组件服务组件指标
站在k8s集群管理员的角度,服务组件的健康状况需要额外的关注。
apiserver指标
apiserver作为k8s中消息总线
成功率和qps
- 请求成功率 :
apiserver_request_total代表apiserver的请求计数器,所以我们可以使用下面promql来计算apiserver请求成功的qps。
sum(rate(apiserver_request_total{job="kubernetes-apiservers",code=~"2.."}[5m]))
- 成功率低于95%的告警 : 响应=2xx的qps除以总的qps就是apiserver的请求成功率
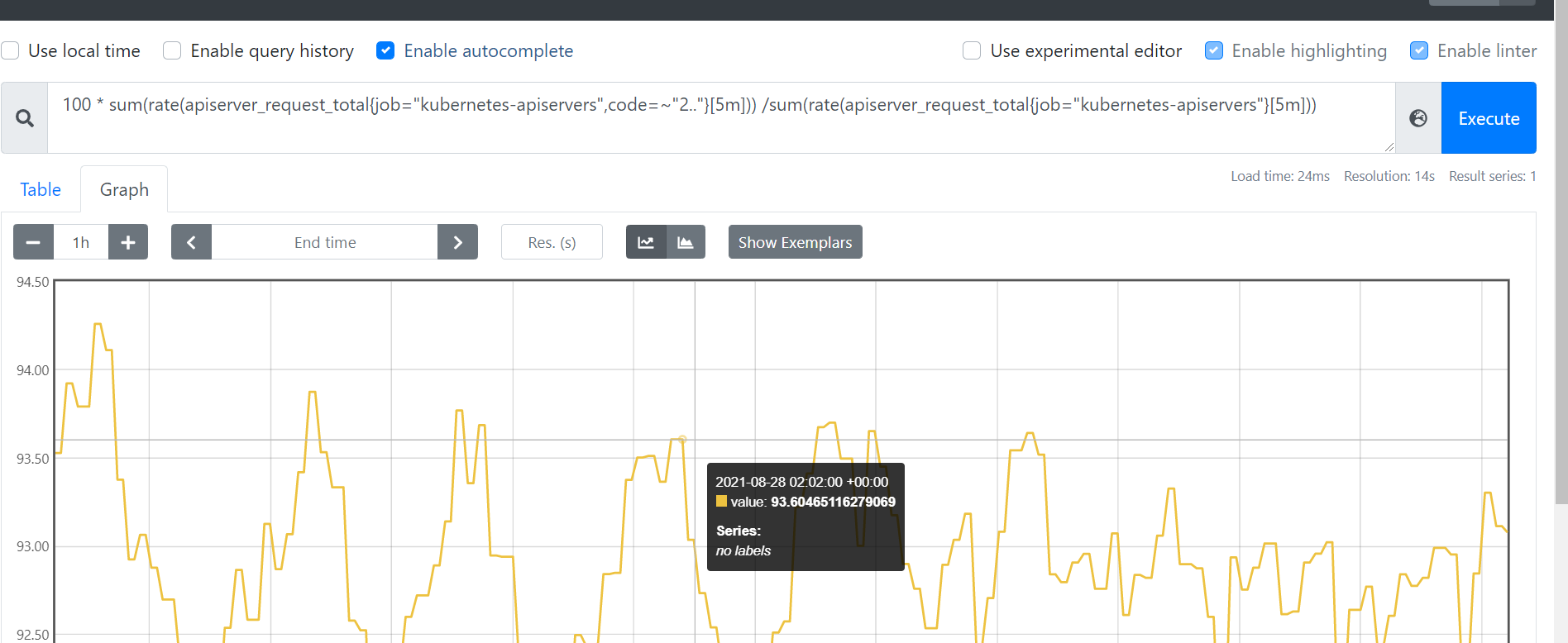
100 * sum(rate(apiserver_request_total{job="kubernetes-apiservers",code=~"2.."}[5m])) /sum(rate(apiserver_request_total{job="kubernetes-apiservers"}[5m]))
- 同理也可以关注4xx和5xx的错误qps,表达式如下
sum(rate(apiserver_request_total{job="kubernetes-apiservers",code=~"[45].."}[5m]))
- 错误的qps过高,可能是服务组件有问题,需要尽快排查。
延迟
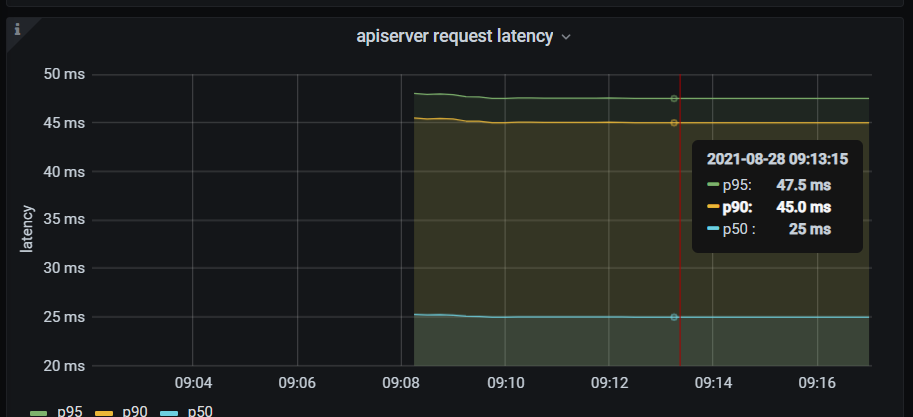
- 对于延迟,可以使用下面的表达式计算。
histogram_quantile(0.99, sum(rate(apiserver_request_duration_seconds_bucket{job="kubernetes-apiservers"}[5m])) by (verb, le))
- 可以得到各个http的请求方法的99分位延迟值。
{verb="WATCH"} 60
{verb="DELETE"} NaN
{verb="PATCH"} 0.0495
{verb="PUT"} 0.08797499999999975
{verb="GET"} 0.06524999999999985
{verb="LIST"} 0.09421428571428572
{verb="POST"} 0.0495
- 如果99分位延迟值很高,可能是apiserver处理能力达到上限,可以考虑扩容一下。
饱和度
- 对于饱和度可以查看apiserver请求队列的情况,如
apiserver_current_inqueue_requests很大的话,说明排队严重。 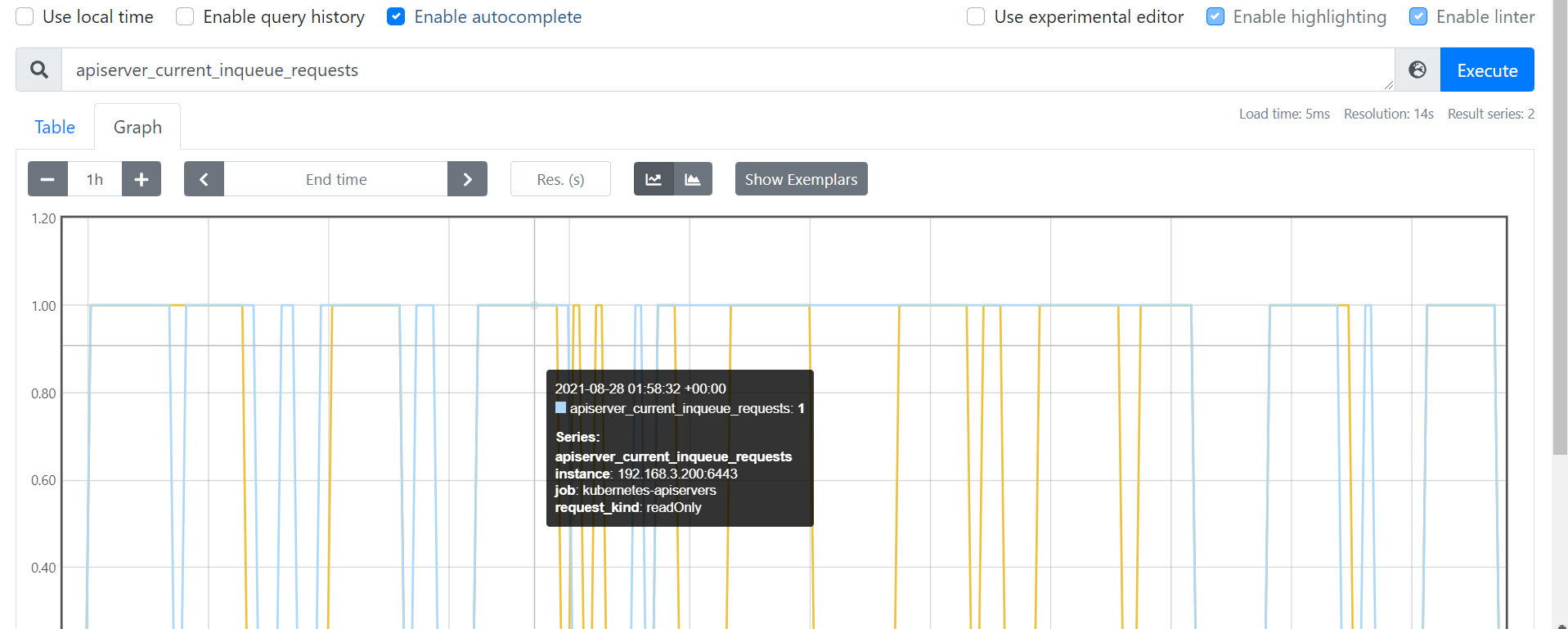
etcd指标
etcd作为k8s中元信息存储的数据库也需要额外关注下
- etcd存储文件大小相关指标,比如
etcd_db_total_size_in_bytes表征db物理文件大小。 - 使用下面表达式可以得到etcd存储空间使用率: 当前使用量/配额。如果使用率大于80%需要扩容
(etcd_mvcc_db_total_size_in_bytes / etcd_server_quota_backend_bytes)*100
- 关于etcd的网络流量可以使用下面两个指标表示。
# 代表client调etcd的流量。
etcd_network_client_grpc_received_bytes_total
# 代表etcd发送的流量。
etcd_network_client_grpc_sent_bytes_total
- etcd中存储key和相关key操作的qps指标,如
etcd_debugging_mvcc_keys_total代表etcd中存储的key总数,数量太多也会影响性能。 - 同时关于etcd key的操作的qps,
rate(etcd_debugging_mvcc_put_total[1m])代表put的qps,同理rate(etcd_debugging_mvcc_delete_total[1m])代表删除的qps。 - 存储的fsync刷盘99分位延迟可以使用下面的分位值计算得到
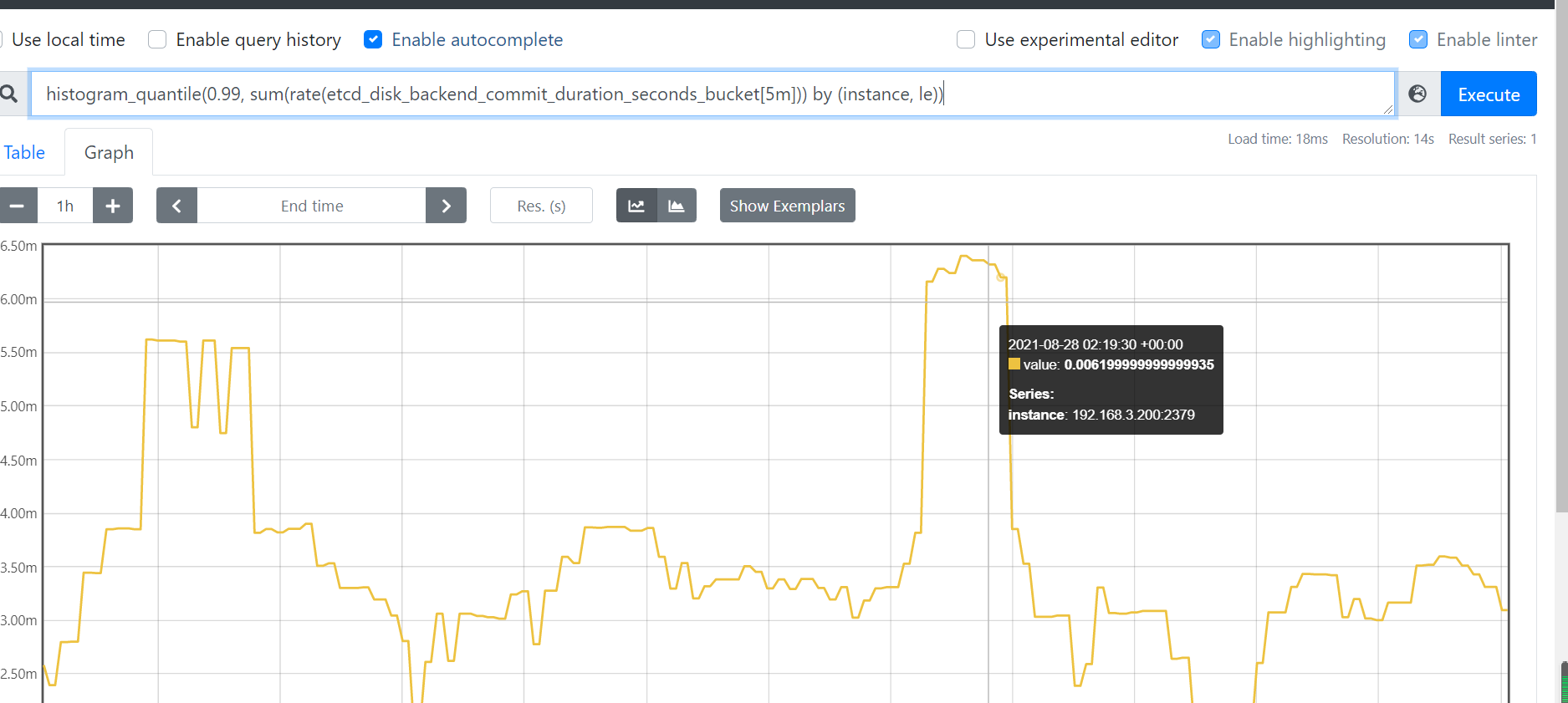
histogram_quantile(0.99, sum(rate(etcd_disk_backend_commit_duration_seconds_bucket[5m])) by (instance, le))
kube-scheduler和kube-controller-manager
kube-scheduler是调度器,所以有关调度成功统计的指标都应被关注。
- 如
scheduler_pod_scheduling_attempts_sum/scheduler_pod_scheduling_attempts_count代表成功调度一个pod 的平均尝试次数。如果尝试次数过高,可能当前node剩余量不多,或者集群出错,建议排查下。 - 如
histogram_quantile(0.99, sum(rate(scheduler_pod_scheduling_duration_seconds_bucket[5m])) by ( le))代码pod调度的99分位延迟,如果过高,考虑schduler压力大或者其他原因。
在kube-controller-manager负责集群内的 Node、Pod 等所有资源的管理。
- 如
rate(workqueue_adds_total[2m])表征工作队列新增的qps,其实就是请求的qps,太高考虑压力大。 - 如
histogram_quantile(0.99, sum(rate(rest_client_request_latency_seconds_bucket{job="kube-controller-manager"}[5m])) by (verb, url, le))",可以查看和apiserver通信的延迟99分位值,太高考虑扩容下apiserver。
本节重点总结 :
- 监控4大黄金指标
- Latency:延时
- Utilization:使用率
- Saturation:饱和度
- Errors:错误数或错误率
- apiserver指标
- 400、500错误qps
- 访问延迟
- 队列深度
- etcd指标
- kube-scheduler和kube-controller-manager