MySQL篇(leetcode刷题100(查询))(二)(持续更新迭代)
目录
一、普通查询
1. 可回收且低脂的产品(简单)
1.1. 题目描述
1.2. 解题思路
2. 寻找用户推荐人(简单)
2.1. 题目描述
2.2. 解题思路
3. 大的国家(简单)
3.1. 题目描述
3.2. 解题思路
4. 文章浏览 I(简单)
4.1. 题目描述
4.2. 解题思路
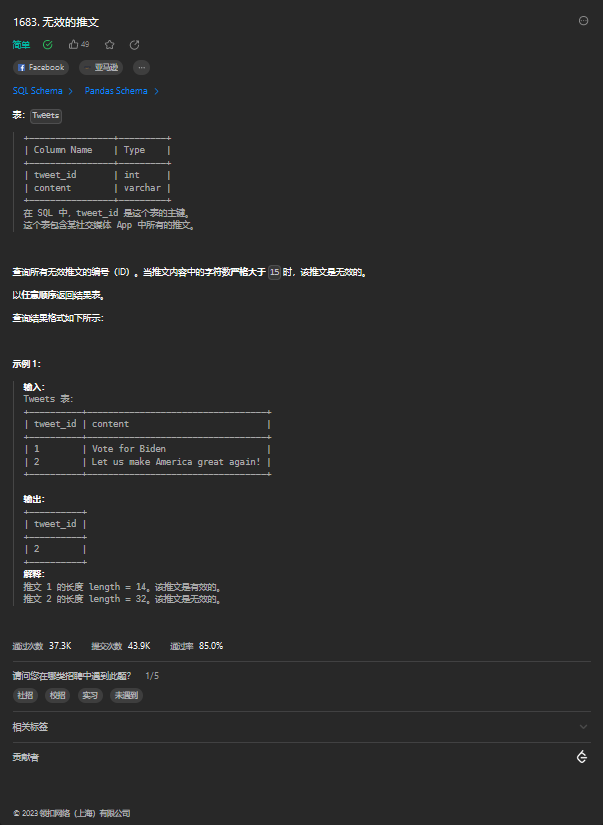
5. 无效的推文(简单)
5.1. 题目描述
5.2. 解题思路
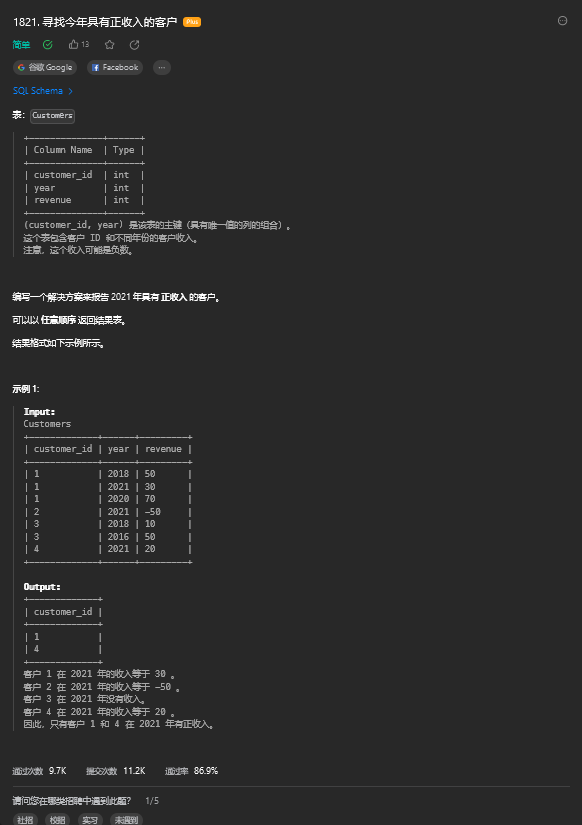
6. 寻找今年具有正收入的客户(简单)
6.1. 题目描述
6.2. 解题思路
方法一
方法二
方法三
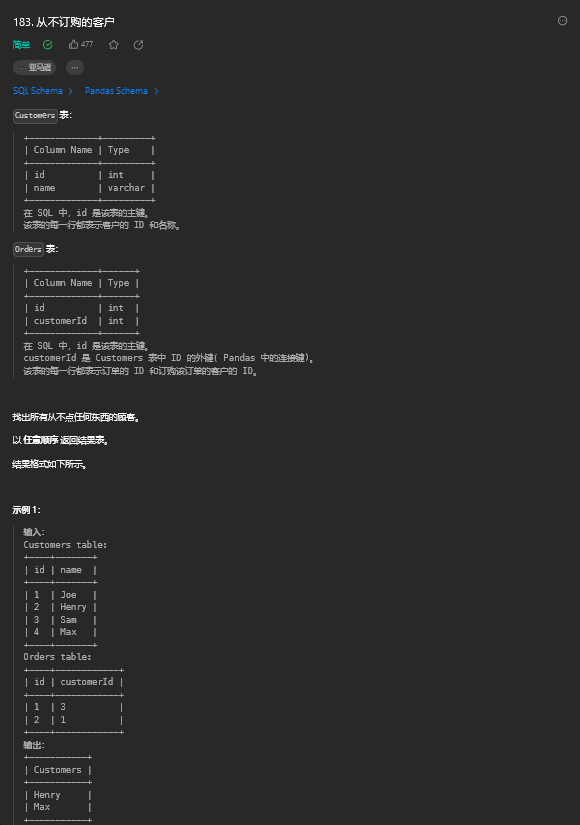
7. 从不订购的客户(简单)
7.1. 题目描述
7.2. 解题思路
方法一
方法二
8. 计算特殊奖金(简单)
8.1. 题目描述
8.2. 解题思路
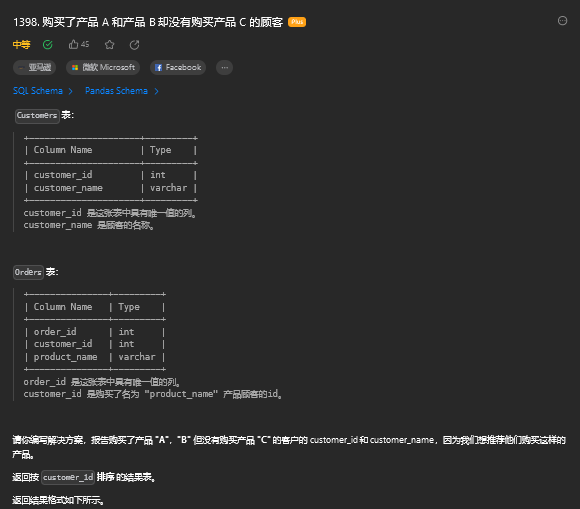
9. 购买了产品 A 和产品 B 却没有购买产品 C 的顾客(中等)
9.1. 题目描述
9.2. 解题思路
方法一:子查询
10. 每位学生的最高成绩(中等)
10.1. 题目描述
10.2. 解题思路
二、连接查询
1. 使用唯一标识码替换员工ID(简单)
1.1. 题目描述
1.2. 解题思路
2. 产品销售分析 I(简单)
2.1. 题目描述
2.2. 解题思路
3. 进店却未进行过交易的顾客(简单)
3.1. 题目描述
3.2. 解题思路
4. 上升的温度(简单)
4.1. 题目描述
4.2. 解题思路
5. 每台机器的进程平均运行时间(简单)
5.1. 题目描述
5.2. 解题思路
方法1
方法2
6. 员工奖金(简单)
6.1. 题目描述
6.2. 解题思路
7. 学生们参加各科测试的次数(简单)
7.1. 题目描述
7.2. 解题思路
8. 至少有5名直接下属的经理(中等)
8.1. 题目描述
8.2. 解题思路
9. 确认率(中等)
9.1. 题目描述
9.2. 解题思路
10. 组合两个表(简单)
10.1. 题目描述
10.2. 解题思路
11. 没有卖出的卖家
11.1. 题目描述
11.2. 解题思路
12. 排名靠前的旅行者
12.1. 题目描述
12.2. 解题思路
13. 销售员
13.1. 题目描述
13.2. 解题思路
14. 计算布尔表达式的值
14.1. 题目描述
14.2. 解题思路
15. 查询球队积分
15.1. 题目描述
15.2. 解题思路
UNION ALL
CASE WHEN罗列大法
CASE WHEN中嵌套IF语句
三、子查询
1. 上级经理已离职的公司员工
1.1. 题目描述
1.2. 解题思路
2. 换座位
2.1. 题目描述
2.2. 解题思路
3. 电影评分
3.1. 题目描述
3.2. 解题思路
4. 餐馆营业额变化增长
4.1. 题目描述
4.2. 解题思路
5. 好友申请 II :谁有最多的好友
5.1. 题目描述
5.2. 解题思路
6. 2016年的投资
6.1. 题目描述
6.2. 解题思路
7. 部门工资前三高的所有员工
7.1. 题目描述
7.2. 解题思路
解法一
解法二
8. 院系无效的学生
8.1. 题目描述
8.2. 解题思路
9. 求团队人数
9.1. 题目描述
9.2. 解题思路
方法一:窗口函数
方法二:左联结+子查询
10. 游戏玩法分析 II
10.1. 题目描述
10.2. 解题思路
11. 部门工资最高的员工
11.1. 题目描述
11.2. 解题思路
12. 每件商品的最新订单
12.1. 题目描述
12.2. 解题思路
13. 最近的三笔订单
13.1. 题目描述
13.2. 解题思路
14. 每天的最大交易
14.1. 题目描述
14.2. 解题思路
四、高级查询和连接
1. 每位经理的下属员工数量
1.1. 题目描述
1.2. 解题思路
2. 员工的直属部门
2.1. 题目描述
2.2. 解题思路
3. 判断三角形
3.1. 题目描述
3.2. 解题思路
4. 连续出现的数字
4.1. 题目描述
4.2. 解题思路
解法一:自关联使用三张表
解法二:利用变量
解法三: 存在量词
5. 指定日期的产品价格
5.1. 题目描述
5.2. 解题思路
6. 最后一个能进入电梯的人
6.1. 题目描述
6.2. 解题思路
方法一:自连接
方法二:自定义变量
7. 按分类统计薪水
7.1. 题目描述
7.2. 解题思路
8. 连续空余座位
8.1. 题目描述
8.2. 解题思路
join
row_number() over()
变量
9. 每个产品在不同商店的价格
9.1 题目描述
9.2 解题思路
10. 直线上的最近距离
10.1 题目描述
10.2 解题思路
11. 丢失信息的雇员
11.1 题目描述
11.2 解题思路
12. 页面推荐
12.1 题目描述
12.2 解题思路
方法一
方法二
13. 树节点
13.1 题目描述
13.2 解题思路
14. 游戏玩法分析 III
14.1 题目描述
14.2 解题思路
sum() over()
join
变量
15. 大满贯数量
15.1 题目描述
15.2 解题思路
1. 方法一
2. 方法二
16. 应该被禁止的 Leetflex 账户
16.1 题目描述
16.2 解题思路
1. 方法一
2. 方法二
一、普通查询
1. 可回收且低脂的产品(简单)
1.1. 题目描述
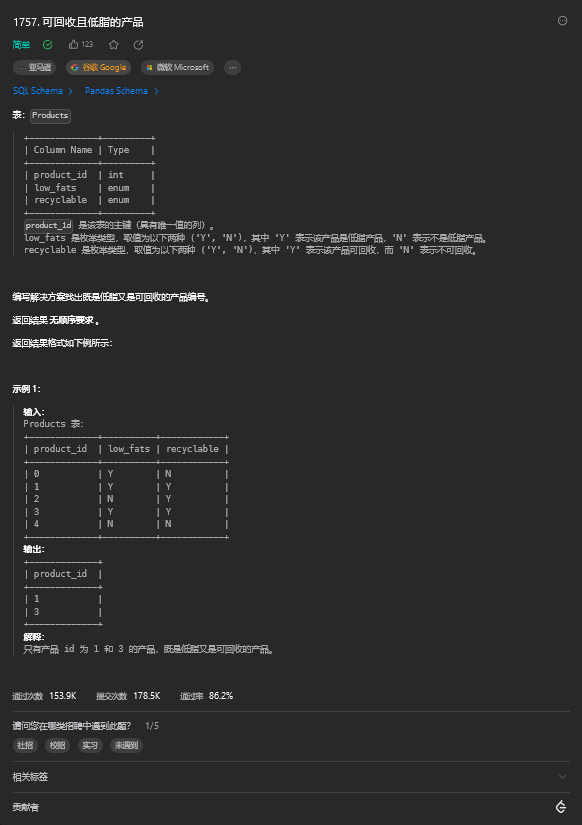
1.2. 解题思路
SELECT
product_id
FROM
Products
WHERE
low_fats = 'Y' AND recyclable = 'Y'2. 寻找用户推荐人(简单)
2.1. 题目描述
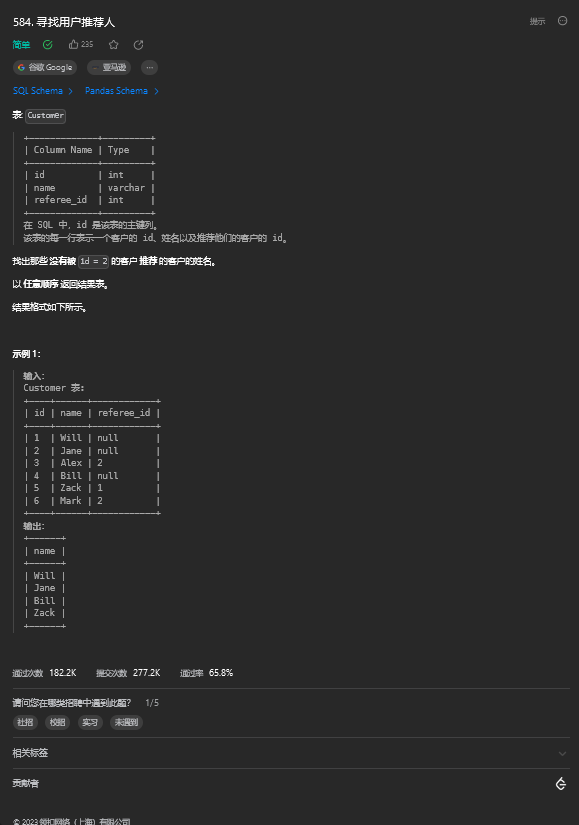
2.2. 解题思路
SELECT name FROM customer WHERE referee_id != 2 OR referee_id IS NULL;3. 大的国家(简单)
3.1. 题目描述
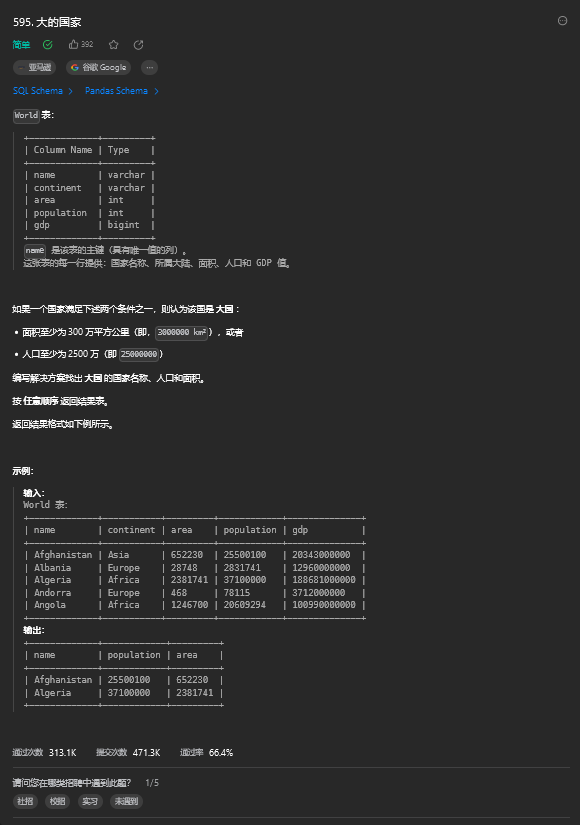
3.2. 解题思路
SELECT
name, population, area
FROM
world
WHERE
area >= 3000000
UNION
SELECT
name, population, area
FROM
world
WHERE
population >= 25000000
;4. 文章浏览 I(简单)
4.1. 题目描述
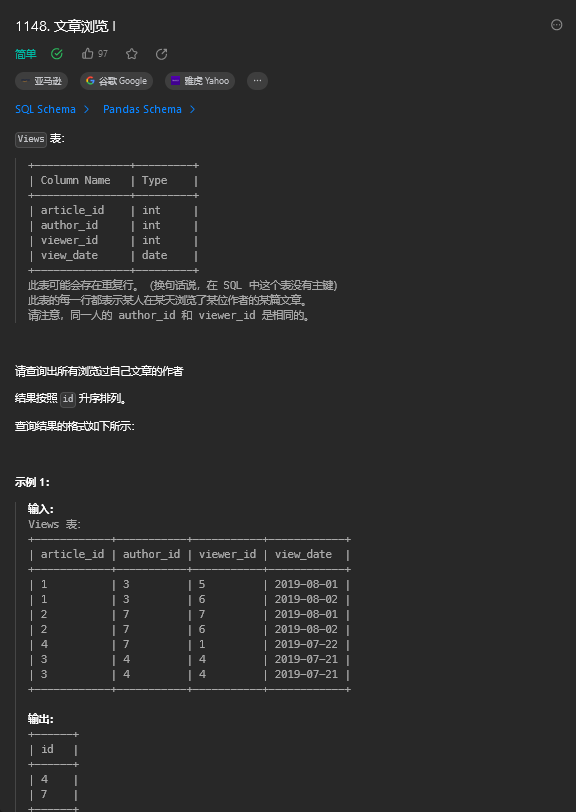
4.2. 解题思路
-- 请编写一条 SQL 查询以找出所有浏览过自己文章的作者,结果按照 id 升序排列。
select distinct author_id as id
from Views
where author_id=viewer_id
order by author_id;5. 无效的推文(简单)
5.1. 题目描述
5.2. 解题思路
SELECT
tweet_id
FROM
tweets
WHERE
CHAR_LENGTH(content) > 156. 寻找今年具有正收入的客户(简单)
6.1. 题目描述
6.2. 解题思路
方法一
SELECT customer_id
FROM customers
WHERE year = 2021 AND revenue > 0;方法二
SELECT
customer_id
FROM
customers
WHERE
year = 2021
GROUP BY
customer_id
HAVING sum(revenue)>0方法三
select a.customer_id from Customers a
where a.year='2021'
AND a.revenue>07. 从不订购的客户(简单)
7.1. 题目描述
7.2. 解题思路
方法一
select customers.name as 'Customers'
from customers
where customers.id not in
(
select customerid from orders
);方法二
SELECT name AS 'Customers'
FROM Customers
LEFT JOIN Orders ON Customers.Id = Orders.CustomerId
WHERE Orders.CustomerId IS NULL8. 计算特殊奖金(简单)
8.1. 题目描述

8.2. 解题思路
SELECT
employee_id,
IF(employee_id % 2 = 1 AND name NOT REGEXP '^M', salary, 0) AS bonus
FROM
employees
ORDER BY
employee_id9. 购买了产品 A 和产品 B 却没有购买产品 C 的顾客(中等)
9.1. 题目描述
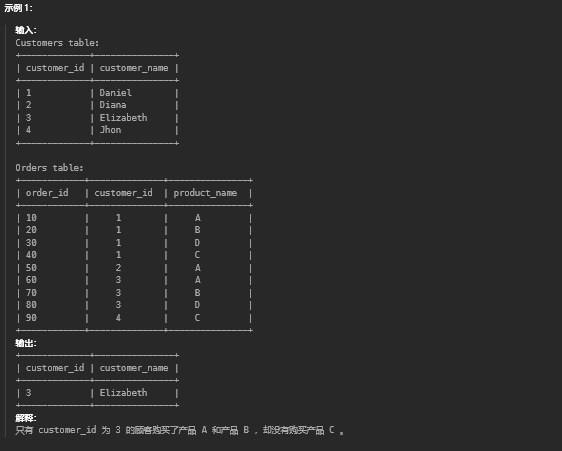
9.2. 解题思路
方法一:子查询
SELECT
customer_id,
customer_name
FROM
Customers
WHERE
customer_id IN(
SELECT
DISTINCT customer_id
FROM
Orders
WHERE
product_name = 'A')
AND customer_id IN(
SELECT
DISTINCT customer_id
FROM
Orders
WHERE
product_name = 'B')
AND customer_id NOT IN(
SELECT
DISTINCT customer_id
FROM
Orders
WHERE
product_name = 'C'
)
ORDER BY customer_id;10. 每位学生的最高成绩(中等)
10.1. 题目描述

10.2. 解题思路
#先找到最大的元素 然后分组即可,不用管某些字段(grade)是不是聚合字段
SELECT
e1.student_id,min(e1.course_id) course_id,e1.grade
FROM
Enrollments e1
INNER JOIN
(
SELECT student_id,max(grade) mGrade
FROM Enrollments
GROUP BY student_id
)e2
ON
e1.student_id=e2.student_id AND e1.grade=e2.mGrade
GROUP BY
e1.student_id
ORDER BY
e1.student_id二、连接查询
1. 使用唯一标识码替换员工ID(简单)
1.1. 题目描述
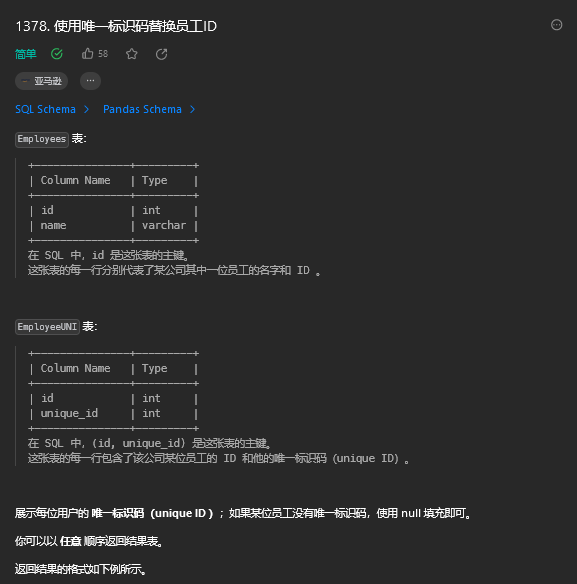
1.2. 解题思路
select e2.unique_id,e1.name
from employees e1 left join employeeUNI e2
on e1.id = e2.id 2. 产品销售分析 I(简单)
2.1. 题目描述
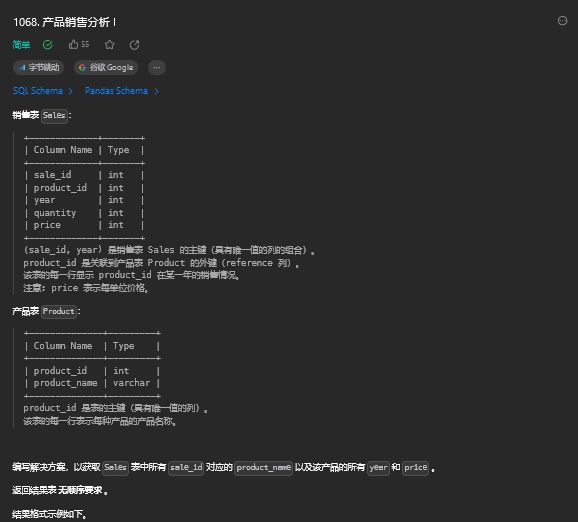

2.2. 解题思路
select
p.product_name,s.year,s.price
from
sales s
join
product p
on
s.product_id=p.product_id;3. 进店却未进行过交易的顾客(简单)
3.1. 题目描述
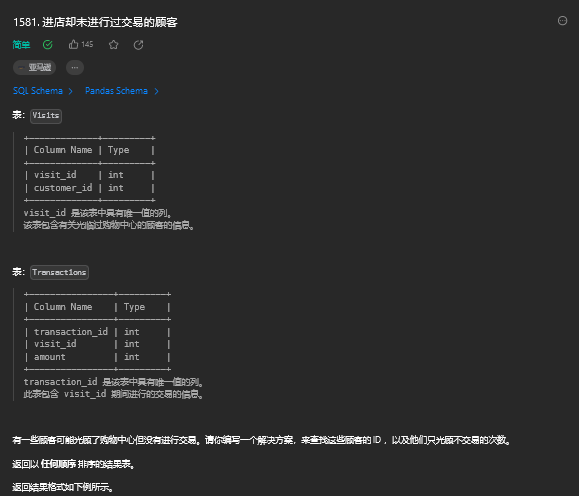
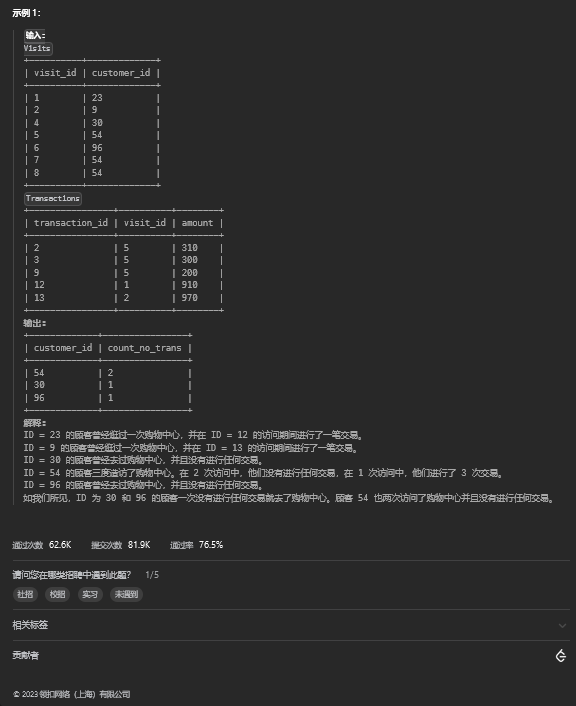
3.2. 解题思路
SELECT Visits.customer_id, count(Visits.visit_id) as count_no_trans
FROM Visits
LEFT JOIN Transactions
ON Visits.visit_id = Transactions.visit_id
WHERE Transactions.amount is NULL
GROUP BY Visits.customer_id4. 上升的温度(简单)
4.1. 题目描述
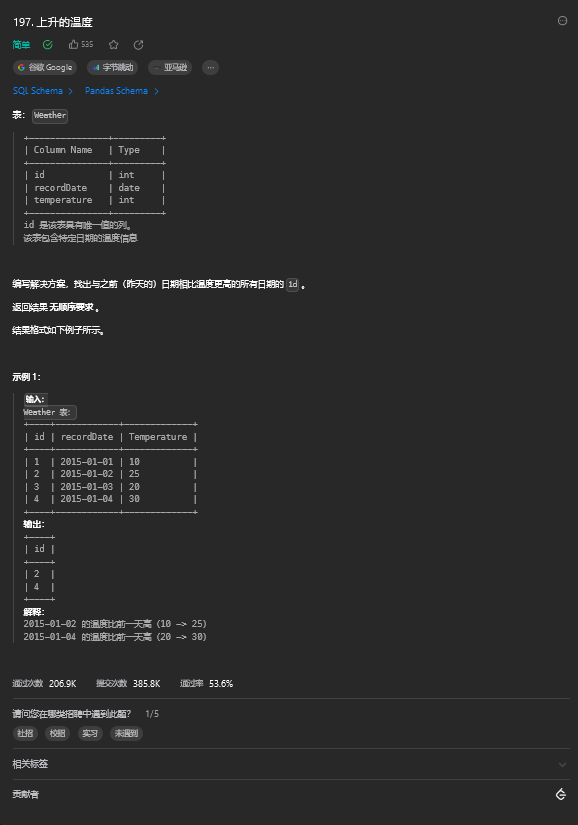
4.2. 解题思路
select w1.id
from weather as w1
join
weather as w2
on datediff(w1.recordDate, w2.recordDate) = 1 and w1.Temperature > w2.Temperature;5. 每台机器的进程平均运行时间(简单)
5.1. 题目描述
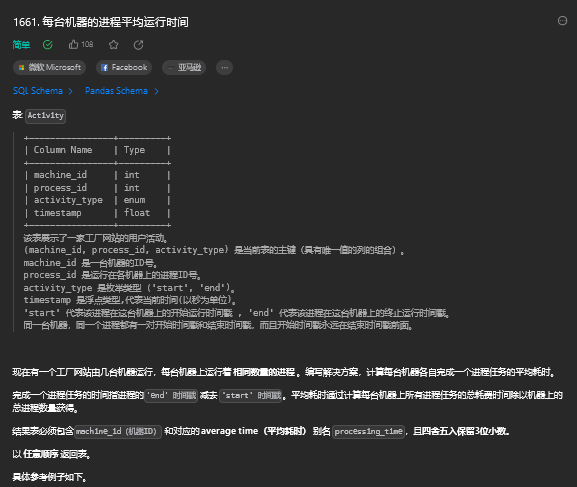
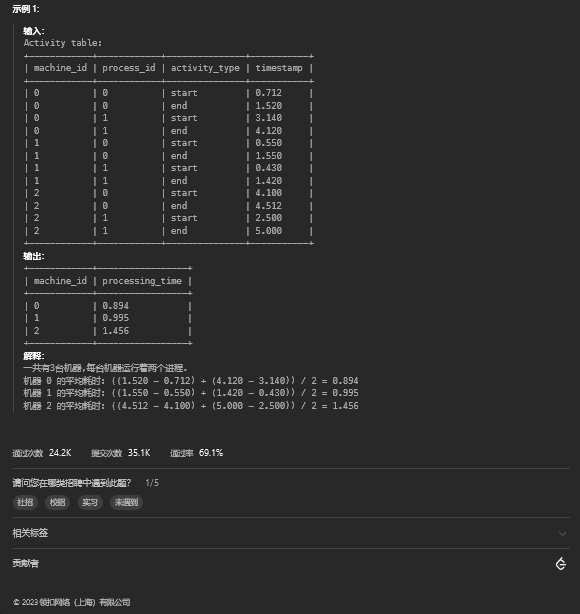
5.2. 解题思路
方法1
SELECT A1.machine_id, round(avg(A2.timestamp - A1.timestamp),3) as processing_time FROM Activity A1 JOIN Activity A2
ON A1.machine_id = A2.machine_id
AND A1.process_id = A2.process_id
AND A1.activity_type = 'start'
AND A2.activity_type = 'end'
GROUP BY machine_idround(value,n)
用法:对某个数据(value)保留指定n个小数位数
例如:
#保留2301.15476的两位小数。
select round(2301.15476,2)
#结果为=》2301.15方法2
# Write your MySQL query statement below
select t1.machine_id, round(tot/num,3) processing_time
from
(
select machine_id, sum(if(activity_type='start', -timestamp, timestamp)) tot
from Activity a
group by machine_id
) t1 left join
(
select b.machine_id, count(distinct b.process_id) num
from Activity b group by machine_id
) t2
on(t1.machine_id=t2.machine_id)6. 员工奖金(简单)
6.1. 题目描述
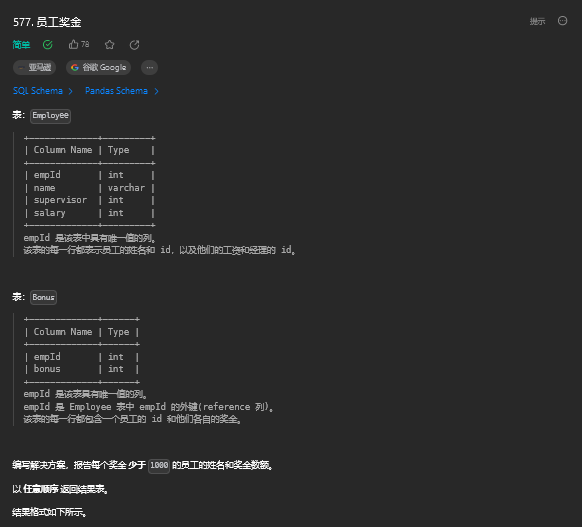
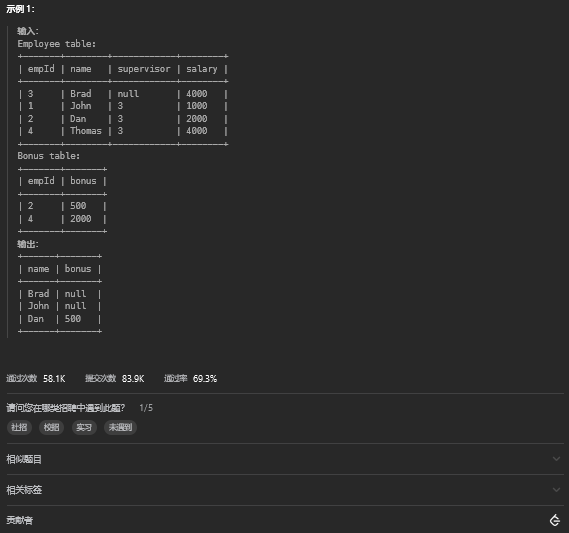
6.2. 解题思路
select
a.name,
b.bonus
from Employee a
left join Bonus b
on a.empId = b.empId
where coalesce(b.bonus,0) < 1000;在MySQL中,COALESCE函数用于返回一组表达式中的第一个非NULL值。
COALESCE函数接受多个参数,并按照参数顺序进行求值,返回第一个非NULL参数。
如果所有参数都为NULL,则返回NULL。
以下是COALESCE函数的语法:
COALESCE(expression1, expression2, ..., expressionN)7. 学生们参加各科测试的次数(简单)
7.1. 题目描述
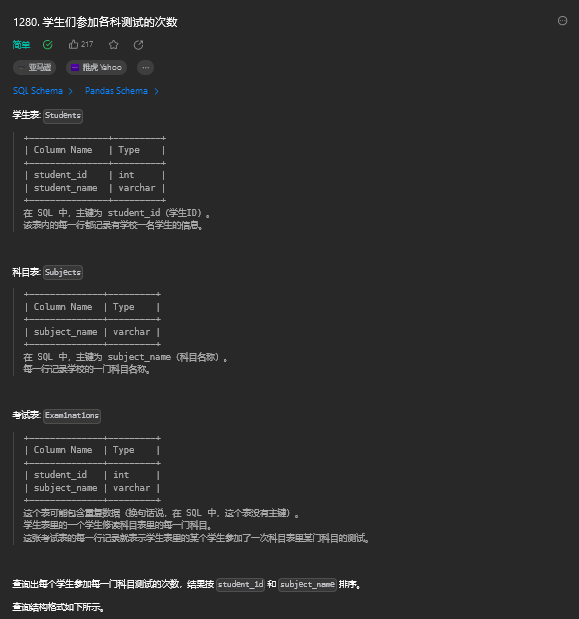
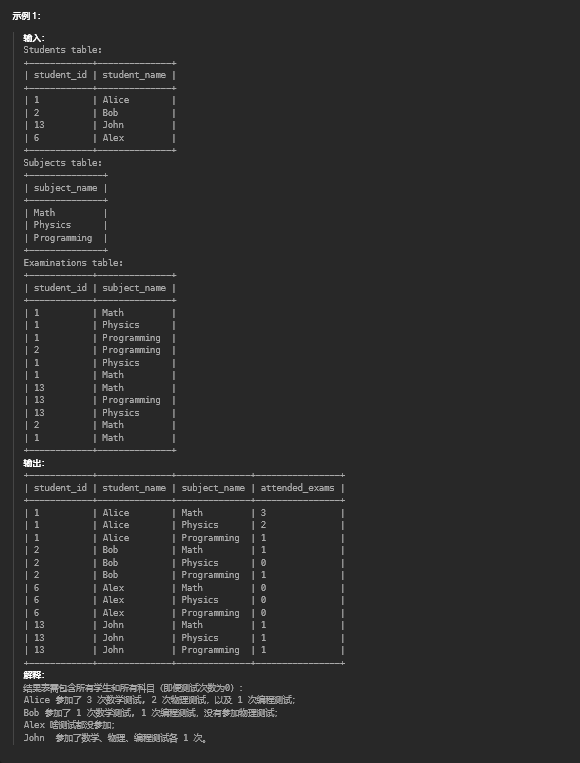
7.2. 解题思路
select
ss.student_id as student_id,
ss.student_name as student_name,
ss.subject_name as subject_name,
ifnull(e1.attended_exams, 0) as attended_exams
from
(
select
*
from Students as s1
cross join Subjects as s2
) as ss
left join
(
select
student_id,
subject_name,
count(student_id) as attended_exams
from Examinations
group by student_id,subject_name
) as e1
on ss.student_id = e1.student_id
and ss.subject_name = e1.subject_name
order by ss.student_id, ss.subject_nameCROSS JOIN是一种关系型数据库中的表连接操作,它用于获取两个或多个表的笛卡
尔积。
简单来说,CROSS JOIN会返回两个表中的所有可能组合。
CROSS JOIN没有任何条件约束,它会将左侧表的每一行与右侧表的每一行进行组
合。
结果集的行数等于左表的行数乘以右表的行数。
以下是CROSS JOIN的语法:
SELECT column1, column2, ...
FROM table1
CROSS JOIN table2;- column1, column2, ...:要选择的列。
- table1, table2:要联接的表。
8. 至少有5名直接下属的经理(中等)
8.1. 题目描述
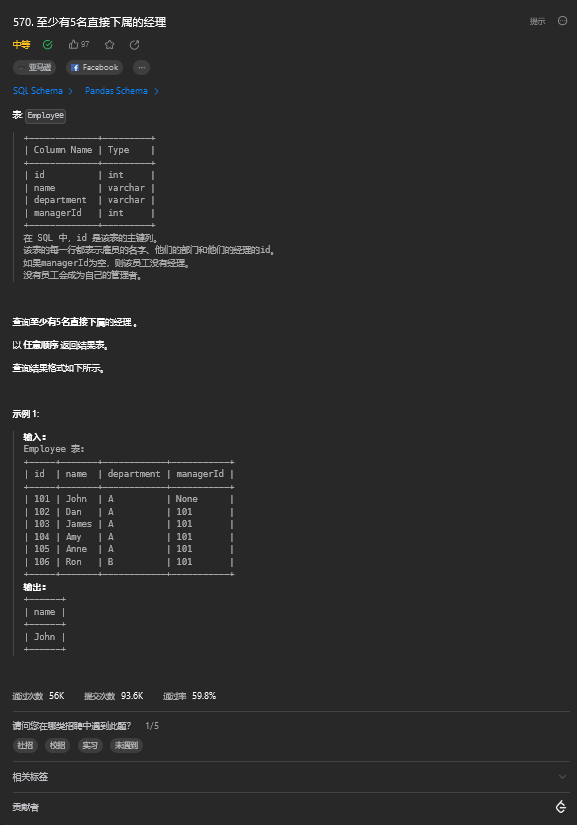
8.2. 解题思路
select
e2.name
from
Employee as e1 left join Employee as e2
on
e1.managerId = e2.id
group by
e2.name
having e2.name is not null and count(1)>=59. 确认率(中等)
9.1. 题目描述
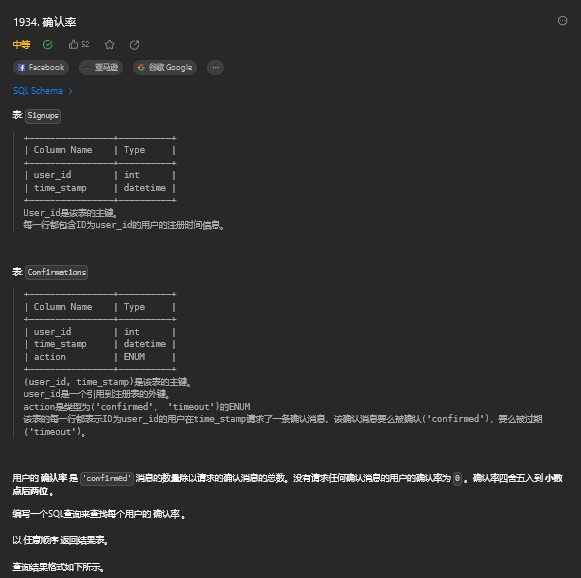
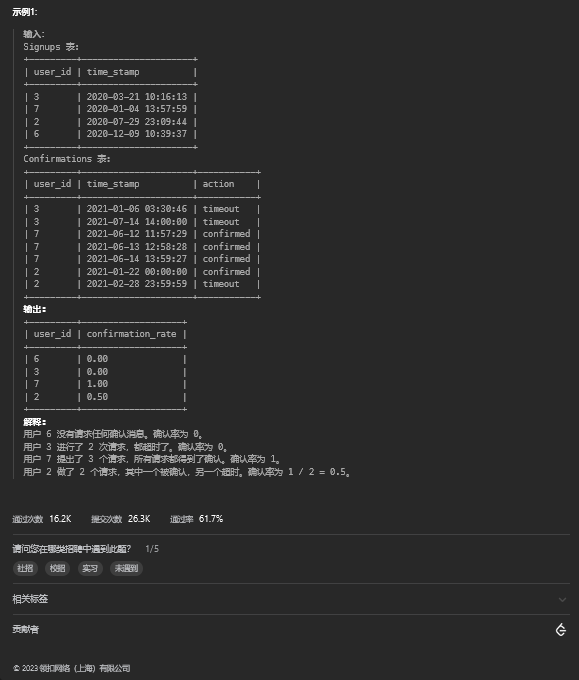
9.2. 解题思路
select signups.user_id,
ifnull(round(sum(action='confirmed')/count(Confirmations.action),2),0.00) AS confirmation_rate
from signups left join confirmations on signups.user_id=Confirmations.user_id
Group by signups.user_id在MySQL中,ROUND函数用于对一个数进行四舍五入取整操作。
ROUND函数有两个常用的语法形式:
- ROUND(x, d)
-
- x是要进行四舍五入的数值表达式。
- d是可选参数,表示保留的小数位数,默认为0(即取整)。
- ROUND(x)
-
- x是要进行四舍五入的数值表达式。
- 不指定d参数时,ROUND函数默认将x四舍五入到最接近的整数。
以下是一些示例说明ROUND函数的使用:
SELECT ROUND(3.14159); -- 结果为3,将3.14159四舍五入为最接近的整数
SELECT ROUND(3.14159, 2); -- 结果为3.14,将3.14159保留两位小数并四舍五入
SELECT ROUND(3.14159, 4); -- 结果为3.1416,将3.14159保留四位小数并四舍五入10. 组合两个表(简单)
10.1. 题目描述
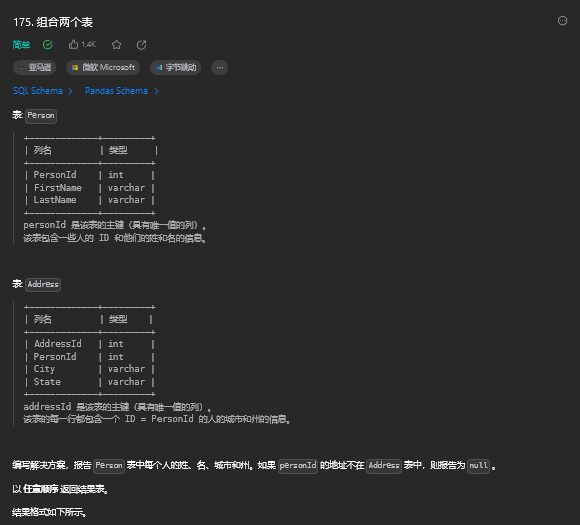
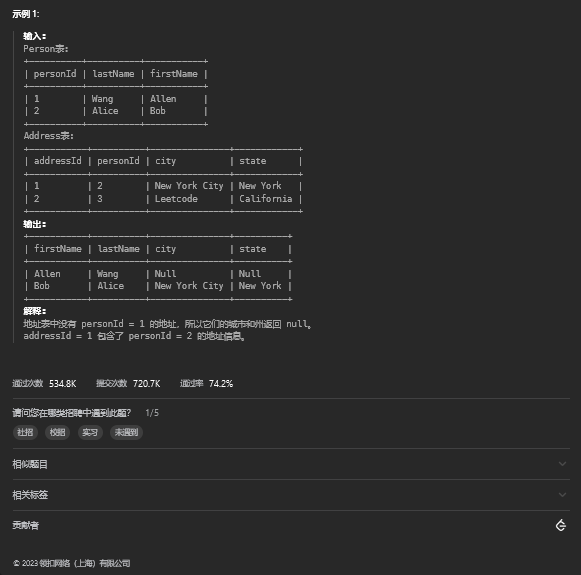
10.2. 解题思路
select p.FirstName, p.LastName, a.City, a.State
from Person p
left join Address a
on p.PersonId = a.PersonId;11. 没有卖出的卖家
11.1. 题目描述
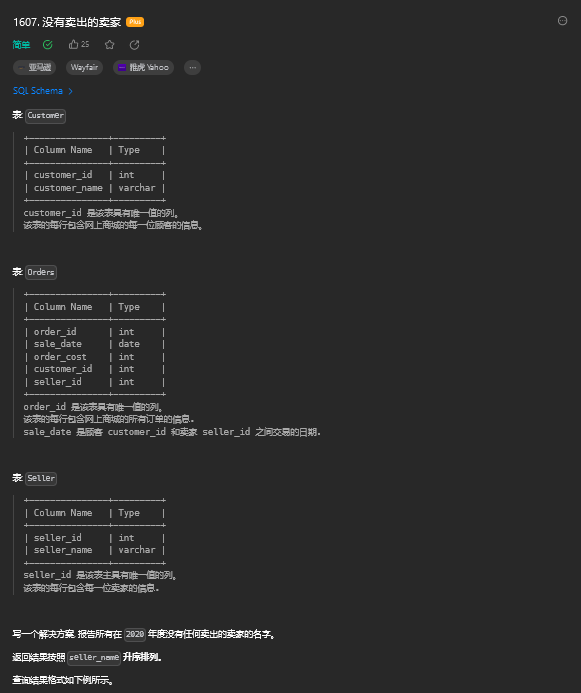
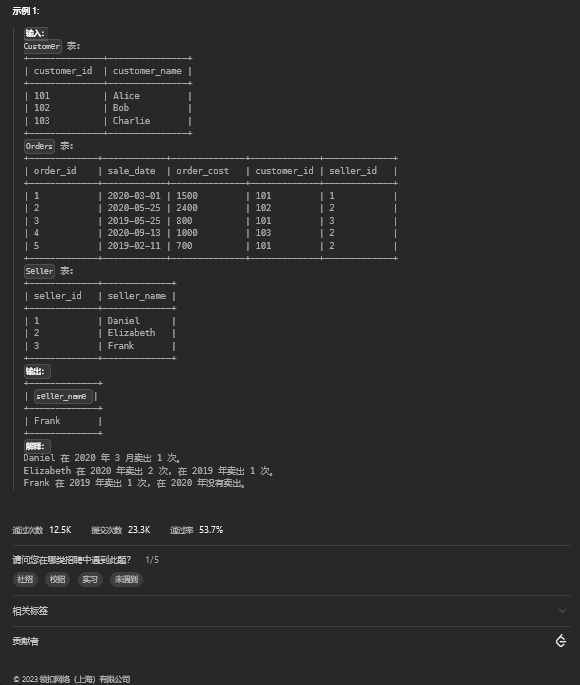
11.2. 解题思路
select s.seller_name
from Seller as s
left join Orders as o
on s.seller_id=o.seller_id and year(o.sale_date)='2020'
group by s.seller_name
having count(o.order_id)=0
order by s.seller_name;12. 排名靠前的旅行者
12.1. 题目描述
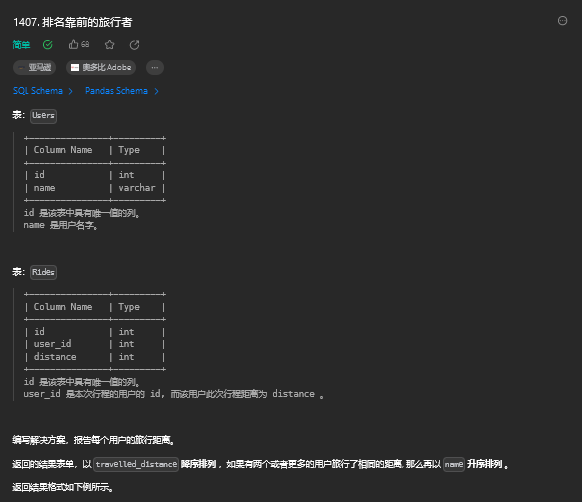
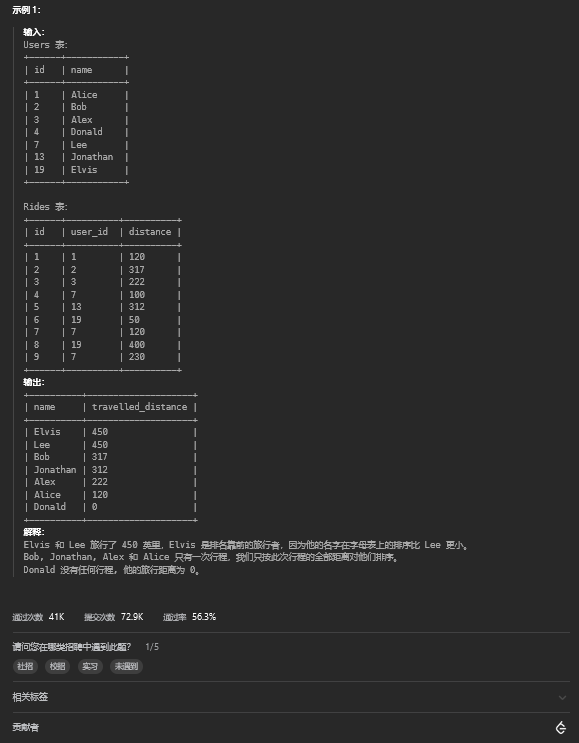
12.2. 解题思路
select a.name,ifnull(sum(b.distance),0) as travelled_distance
from users as a left join Rides as b on b.user_id=a.id
group by b.user_id
order by travelled_distance desc, name13. 销售员
13.1. 题目描述
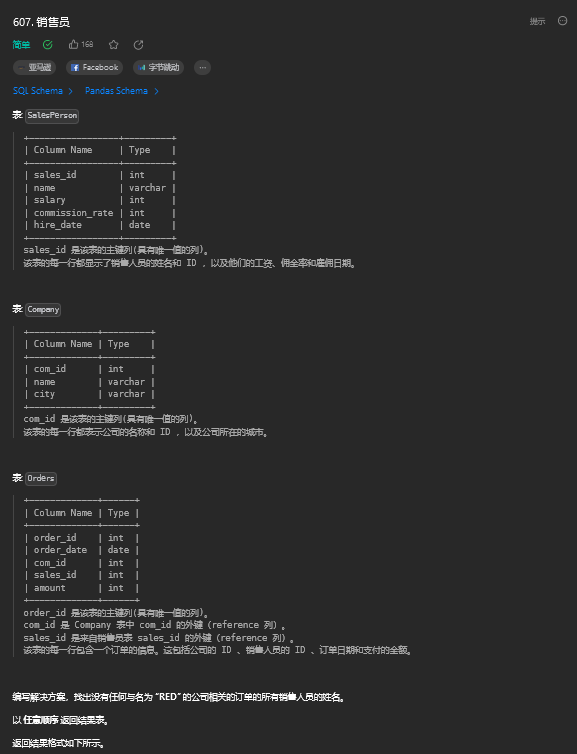
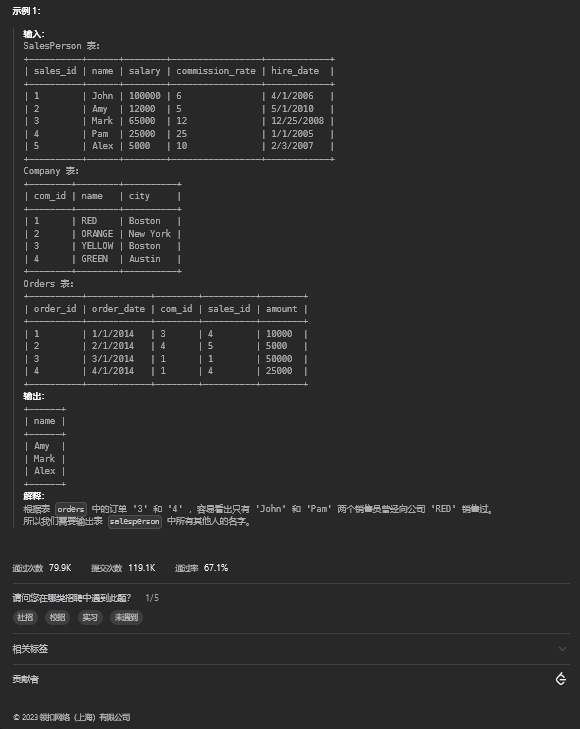
13.2. 解题思路
select name
from salesperson
where sales_id not in(select sales_id
from orders
where com_id=(select com_id from company where name='RED'))14. 计算布尔表达式的值
14.1. 题目描述
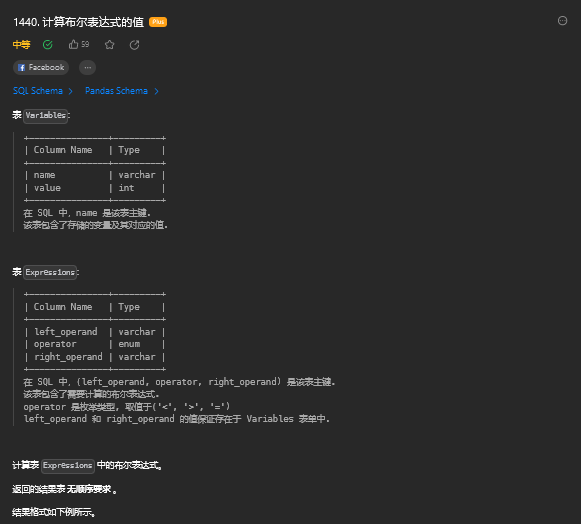
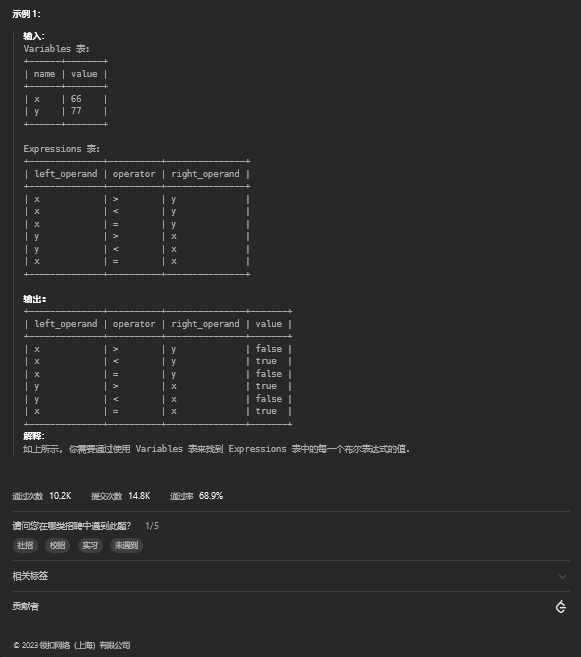
14.2. 解题思路
select
a.left_operand,
a.operator,
a.right_operand,
case when a.operator = '>' and b.value > c.value then 'true'
when a.operator = '=' and b.value = c.value then 'true'
when a.operator = '<' and b.value < c.value then 'true'
else 'false'
end value
from Expressions a
inner join Variables b
on a.left_operand = b.name
inner join Variables c
on a.right_operand = c.name;15. 查询球队积分
15.1. 题目描述
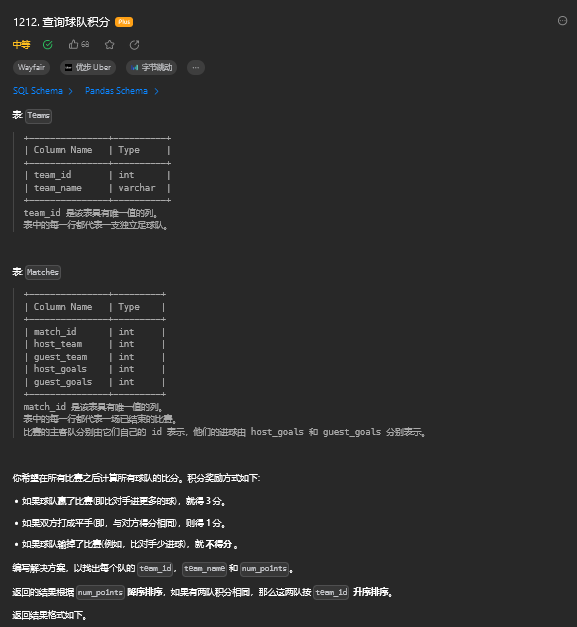
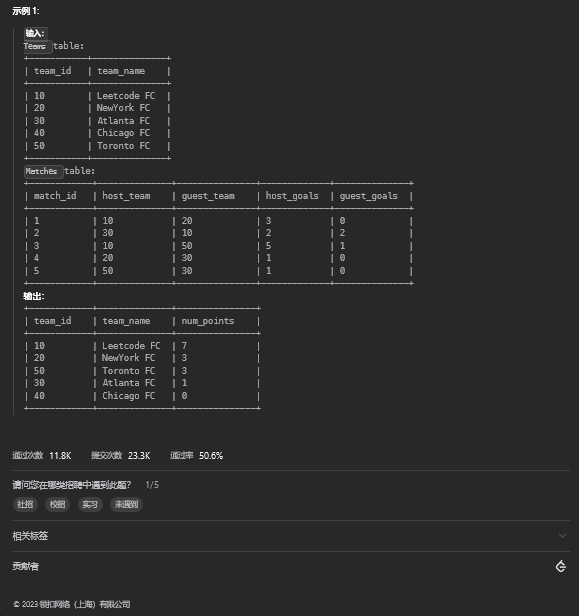
15.2. 解题思路
UNION ALL
select team_id,team_name,
sum(case when host_goals>guest_goals then 3
when host_goals=guest_goals then 1
else 0
end) num_points
from teams t
left join
(select host_team,guest_team,host_goals,guest_goals
from matches
union all
select guest_team host_team,
host_team guest_team,
guest_goals host_goals,
host_goals guest_goals
from matches) tmp
on t.team_id = tmp.host_team
group by team_id
order by num_points desc,team_idCASE WHEN罗列大法
select team_id,team_name,
ifnull(sum(
case when host_goals>guest_goals and team_id=host_team then 3
when host_goals=guest_goals and team_id=host_team then 1
when host_goals<guest_goals and team_id=host_team then 0
when host_goals<guest_goals and team_id=guest_team then 3
when host_goals=guest_goals and team_id=guest_team then 1
when host_goals>guest_goals and team_id=guest_team then 0
end),0) as num_points
from teams,matches
group by team_id
order by num_points desc,team_idCASE WHEN中嵌套IF语句
select team_id,team_name,
sum(case when host_goals>guest_goals then if(team_id = host_team,3,0)
when host_goals<guest_goals then if(team_id = guest_team,3,0)
else if(team_id in (host_team,guest_team),1,0)
end) as num_points
from teams ,matches
group by team_id
order by num_points desc,team_id三、子查询
1. 上级经理已离职的公司员工
1.1. 题目描述
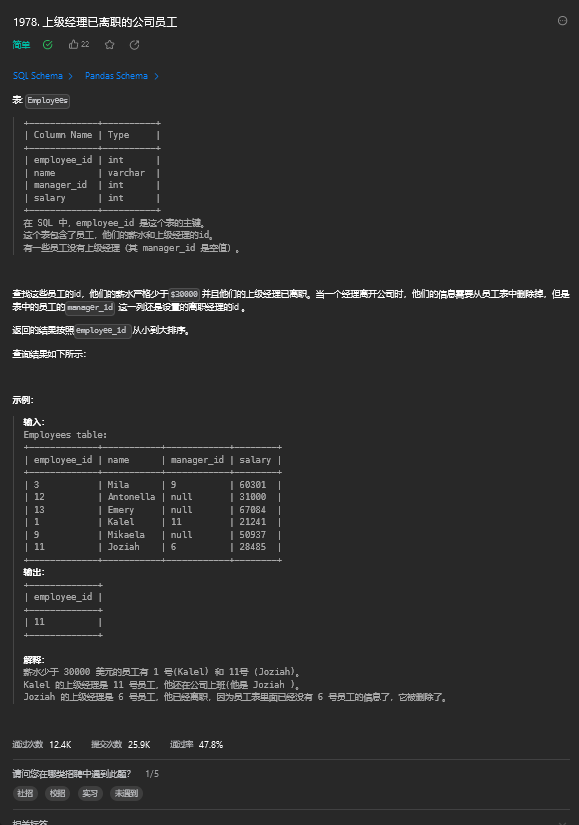
1.2. 解题思路
select e1.employee_id
from
Employees e1
left join Employees e2
on e1.manager_id=e2.employee_id
where e1.salary<30000
and
e1.manager_id is not null
and
e2.employee_id is null
order by employee_id
2. 换座位
2.1. 题目描述
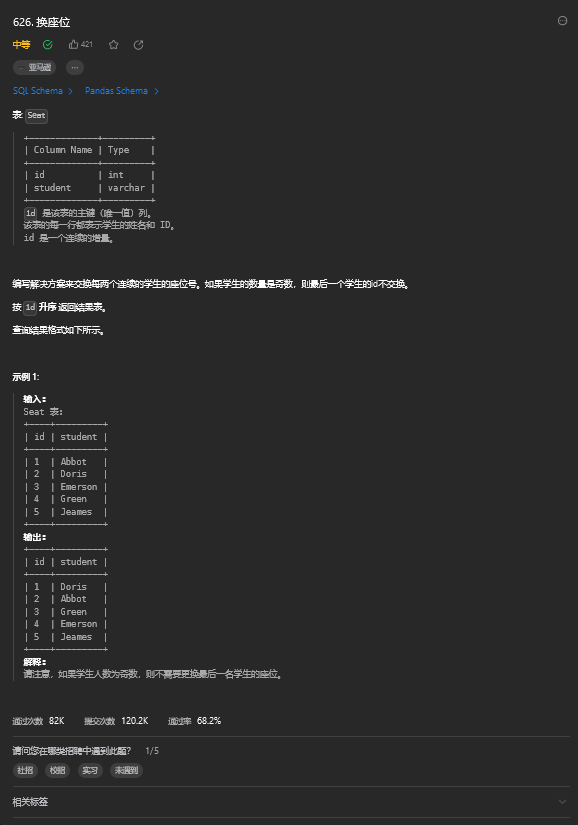
2.2. 解题思路
select
if (id%2=0, id-1,
if(id=mxid, id, id+1)
) as id, student
from seat, (select max(id) as mxid from seat) as init # 最大数为奇数
order by id;3. 电影评分
3.1. 题目描述
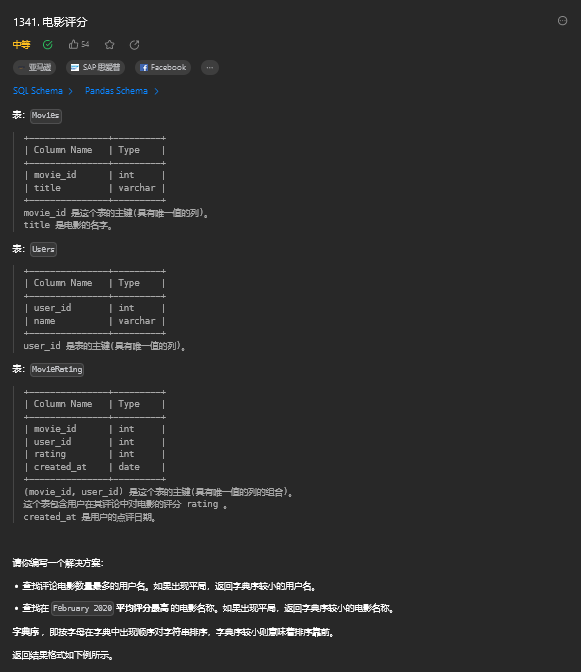
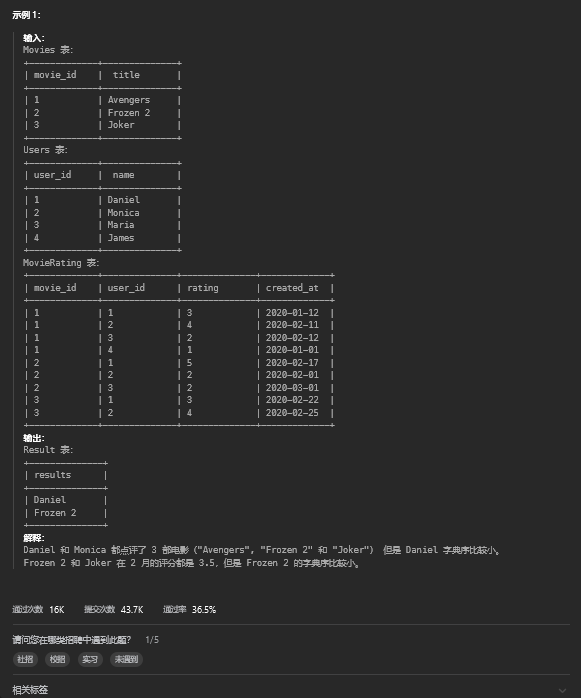
3.2. 解题思路
(
select u.name as results
from MovieRating r join Users u
on r.user_id=u.user_id
group by r.user_id
order by count(r.movie_id) desc, u.name
limit 0,1
)
union all
(
select m.title as results
from MovieRating r join Movies m
on r.movie_id=m.movie_id
where r.created_at between '2020-02-01' and '2020-02-29'
group by r.movie_id
order by avg(r.rating) desc, m.title
limit 0,1
);4. 餐馆营业额变化增长
4.1. 题目描述
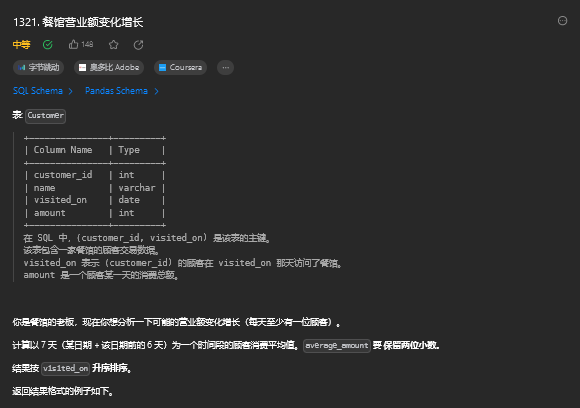
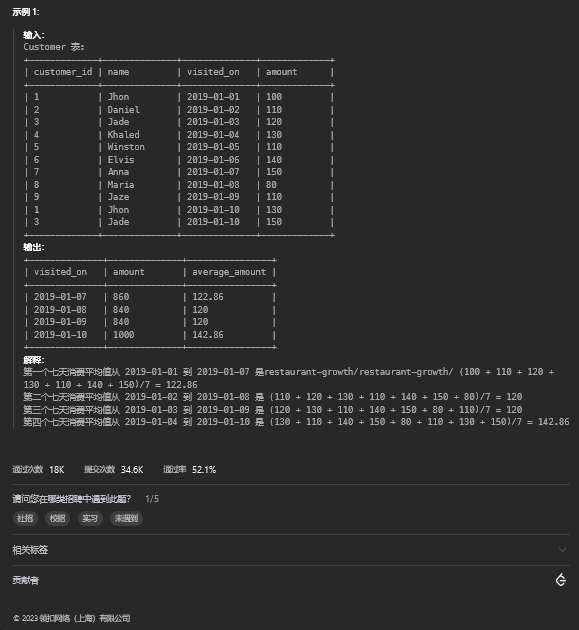
4.2. 解题思路
SELECT DISTINCT visited_on,sum_amount as amount, round(average_amount,2) as average_amount
FROM (
SELECT visited_on,
sum(amount) over(order by visited_on rows 6 preceding) as sum_amount,
avg(amount) over(order by visited_on rows 6 preceding) as average_amount
FROM(
SELECT visited_on,sum(amount) as amount
FROM Customer
group by visited_on
) t1
)t2
WHERE datediff(visited_on,(SELECT MIN(visited_on) FROM Customer))>=65. 好友申请 II :谁有最多的好友
5.1. 题目描述
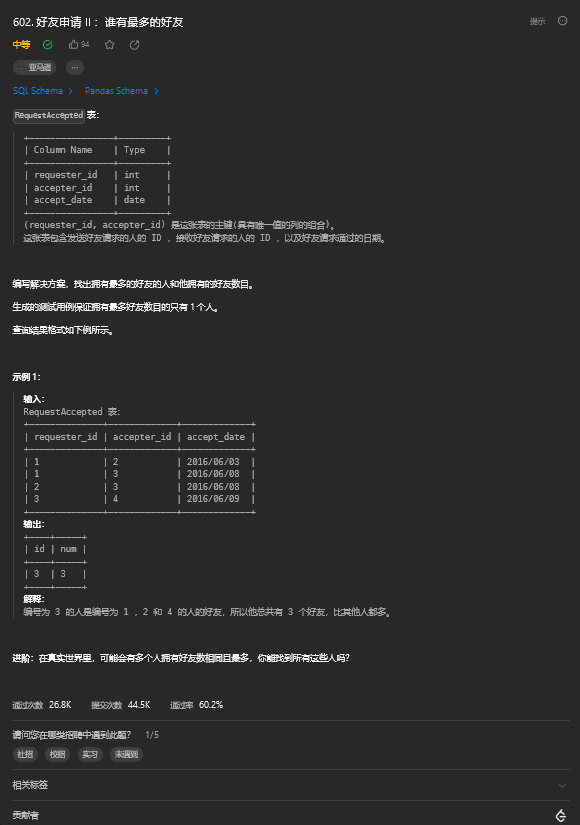
5.2. 解题思路
select aa.accepter_id as id, acount as num from( select accepter_id, count(accepter_id) as acount from( select accepter_id from requestaccepted union all select requester_id as accepter_id from requestaccepted )a group by accepter_id )aa order by acount desc limit 1;6. 2016年的投资
6.1. 题目描述
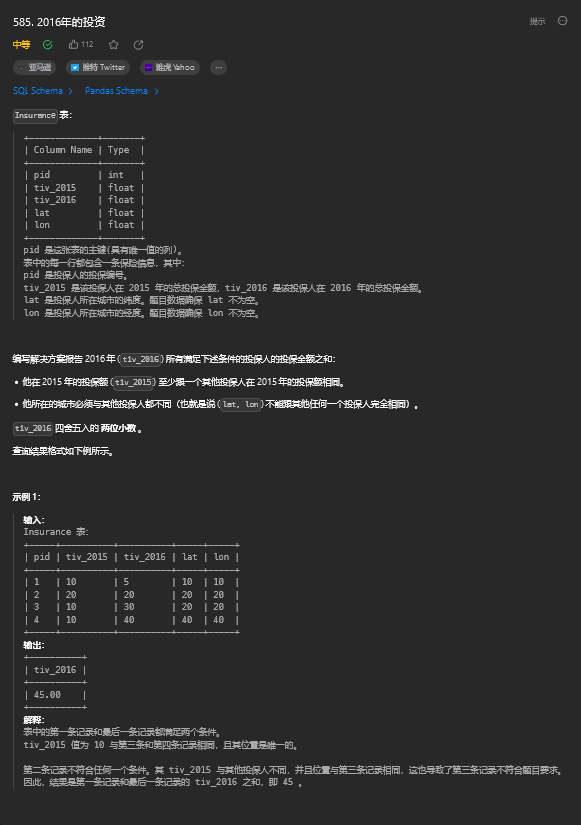
6.2. 解题思路
select round(sum(tiv_2016),2) tiv_2016 from
(select *,count(*) over(partition by tiv_2015) a1,count(*) over(partition by lat,lon) a2 from insurance)
as a
where a1>1 and a2=17. 部门工资前三高的所有员工
7.1. 题目描述
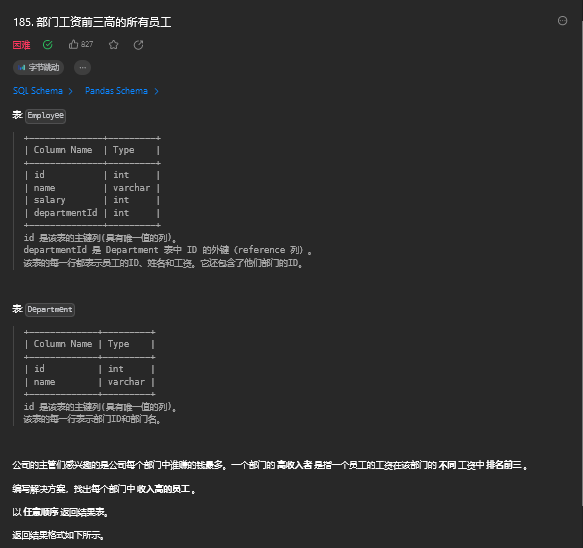
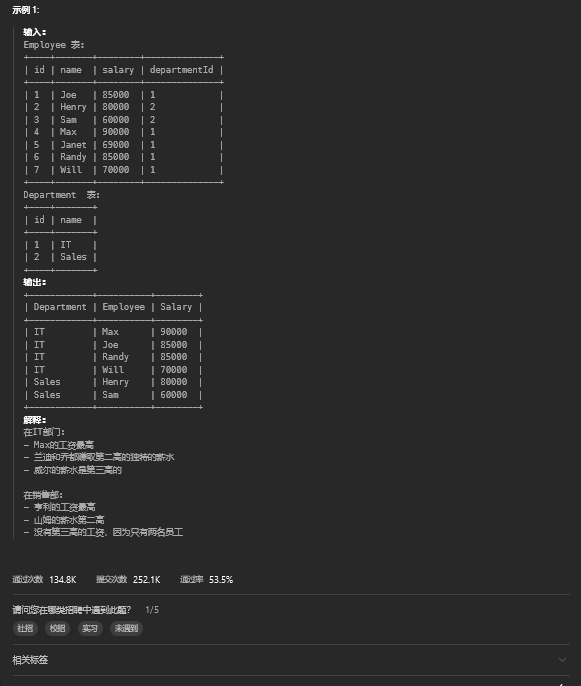
7.2. 解题思路
解法一
select
Department
, Employee
, Salary
from (
select
t2.name as department
, t1.name as employee
, t1.salary
, dense_rank() over (partition by departmentid order by salary desc) as rk
from employee as t1
inner join department as t2 on t1.departmentid = t2.id
) as t3
where rk <= 3;思路:
使用dense_rank函数,找到每个部门最高,然后取dense_rank<=3的结果即可。
代码-版本1:
大数据量时,要尽量避免通过salary这种数字进行表间联结,性能会很不可测。
解法二
可以先dense_rank,再join维度表(hive或spark里必要时进行map join),在分布式计算中,性能会高一些。
select
t2.name AS Department
, t1.Employee
, t1.Salary
from (
select
DepartmentId,
name as employee,
salary,
dense_rank() over (partition by departmentid order by salary desc) as rnk
from employee
) t1
inner join department as t2 on t1.departmentid = t2.id
where t1.rnk <= 3;8. 院系无效的学生
8.1. 题目描述

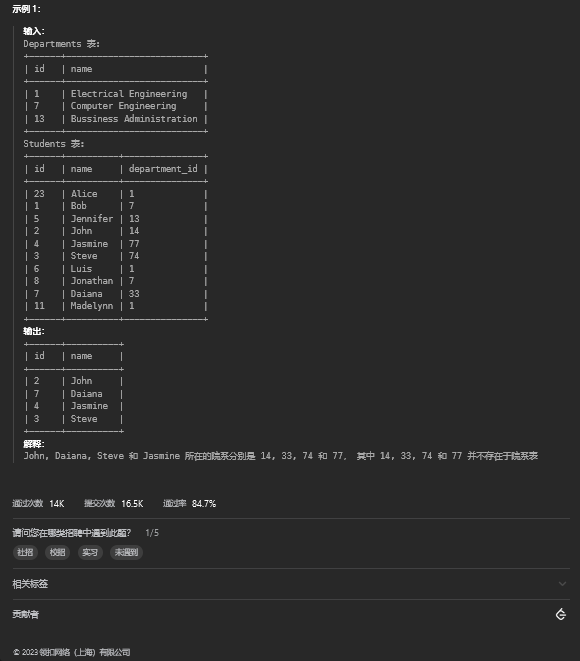
8.2. 解题思路
SELECT id, name
FROM Students
WHERE department_id NOT IN (SELECT id FROM Departments);9. 求团队人数
9.1. 题目描述
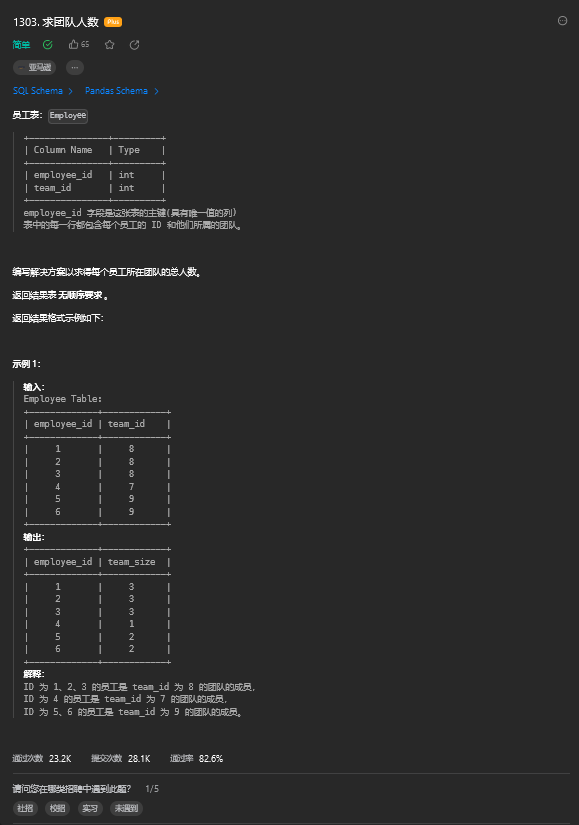
9.2. 解题思路
方法一:窗口函数
select
employee_id,
count(team_id) over(partition by team_id) as team_size
from Employee;方法二:左联结+子查询
select a.employee_id,b.team_size
from Employee as a
left join(
select
team_id,count(*) as team_size
from Employee
group by team_id
)as b
on a.team_id=b.team_id;10. 游戏玩法分析 II
10.1. 题目描述
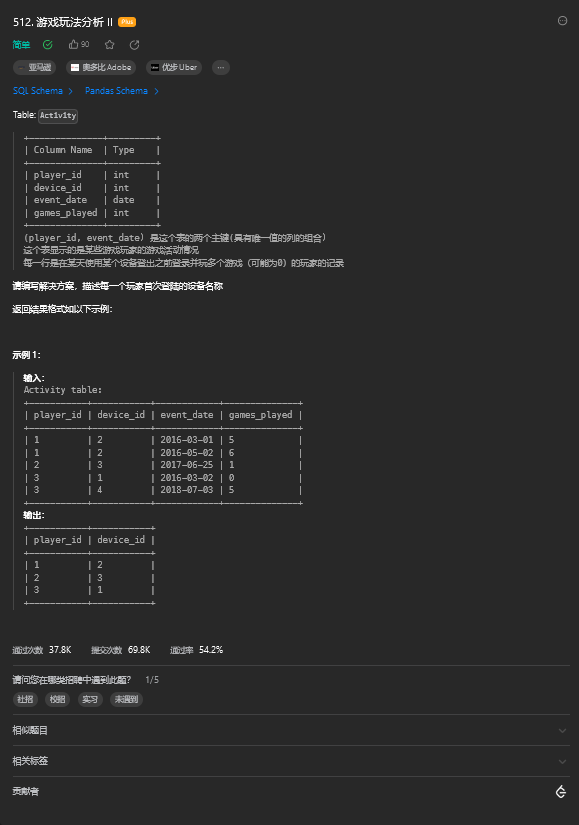
10.2. 解题思路
select a.player_id, a.device_id
from activity a
where (a.player_id,a.event_date) in(select player_id,min(event_date) from activity group by player_id);11. 部门工资最高的员工
11.1. 题目描述
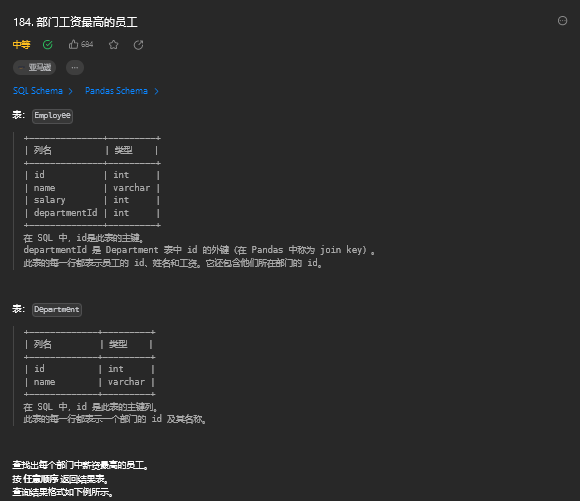
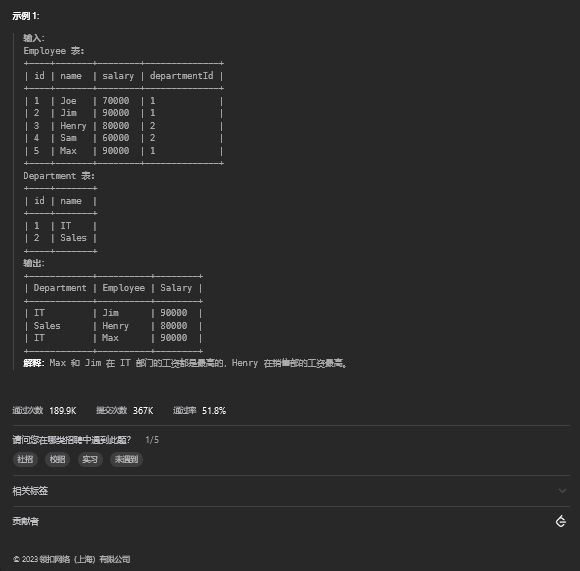
11.2. 解题思路
SELECT
Department,
Employee,
Salary
FROM(
SELECT
Department.name as Department,
Employee.name as Employee,
salary as Salary,
rank() over(partition by Employee.departmentId ORDER BY salary DESC) as RANKING
FROM
Employee
LEFT JOIN
Department
ON
departmentId = Department.id) t
WHERE RANKING = 112. 每件商品的最新订单
12.1. 题目描述
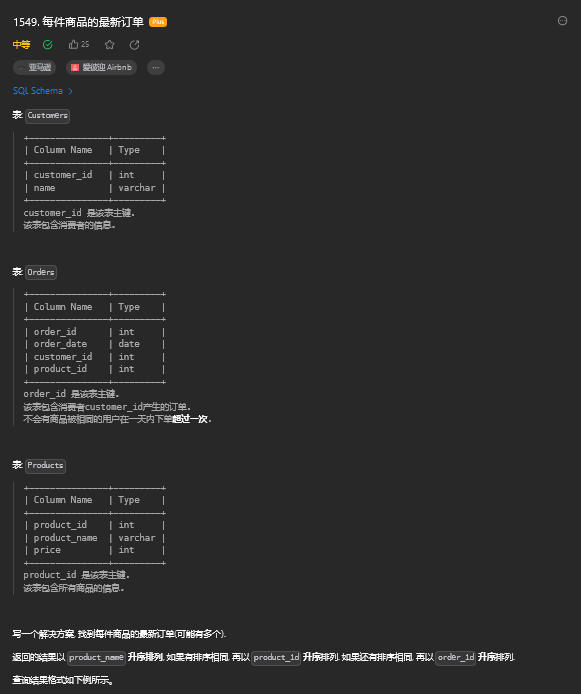
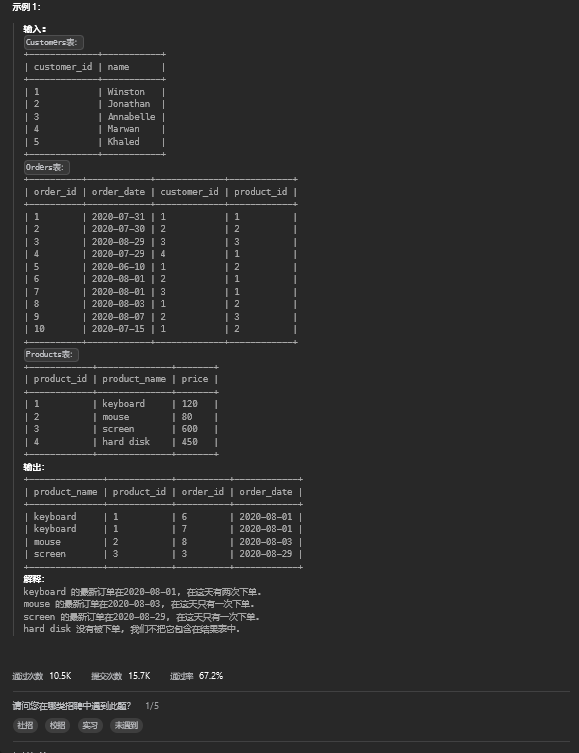
12.2. 解题思路
select
c.product_name,
b.product_id,
b.order_id,
b.order_date
from (
select
a.product_id,
a.order_id,
a.order_date,
rank() over(partition by a.product_id order by order_date desc) rk
from Orders a
)b
left join Products c
on b.product_id = c.product_id
where b.rk = 1
order by c.product_name,b.product_id,b.order_id;13. 最近的三笔订单
13.1. 题目描述
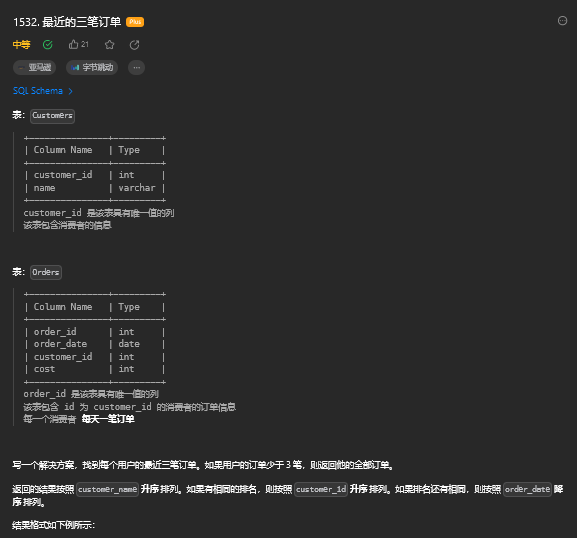
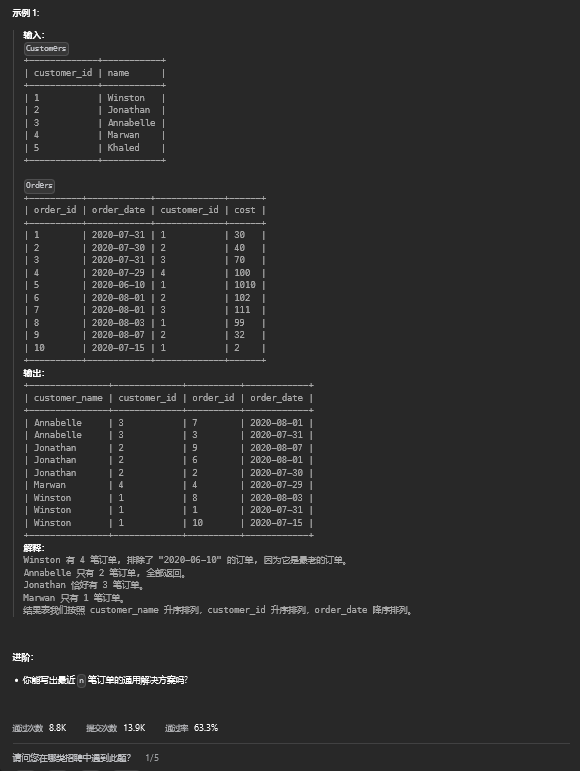
13.2. 解题思路
select t2.name as customer_name
, t1.customer_id as customer_id
, t1.order_id as order_id
, t1.order_date as order_date
from (
select
customer_id
, order_id
, order_date
, rank() over(partition by customer_id order by order_date desc) as rn
from orders
) t1
join Customers t2 on t1.customer_id = t2.customer_id
where rn <= 3
order by t2.name asc, t1.customer_id asc, t1.order_date desc;14. 每天的最大交易
14.1. 题目描述
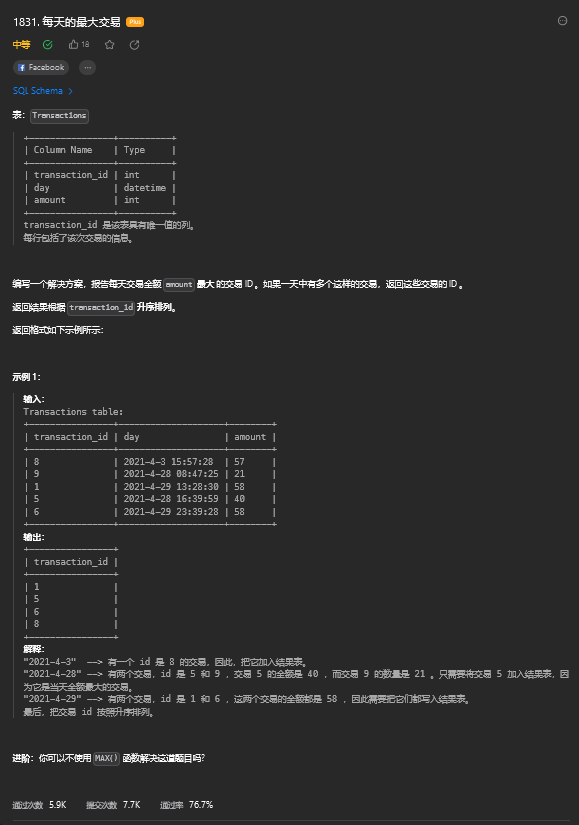
14.2. 解题思路
select
transaction_id
from
(
select
transaction_id, dense_rank() over(partition by date_format(day,'%Y-%m-%d') order by amount desc) dr
from
Transactions
) s1
where dr = 1
order by transaction_id四、高级查询和连接
1. 每位经理的下属员工数量
1.1. 题目描述

1.2. 解题思路
select
a.reports_to as employee_id ,
b.name,
count(a.reports_to) as reports_count,
round(avg(a.age),0) as average_age
from Employees as a
left join Employees as b
on a.reports_to=b.employee_id
where a.reports_to is not null
group by a.reports_to
order by employee_id;2. 员工的直属部门
2.1. 题目描述
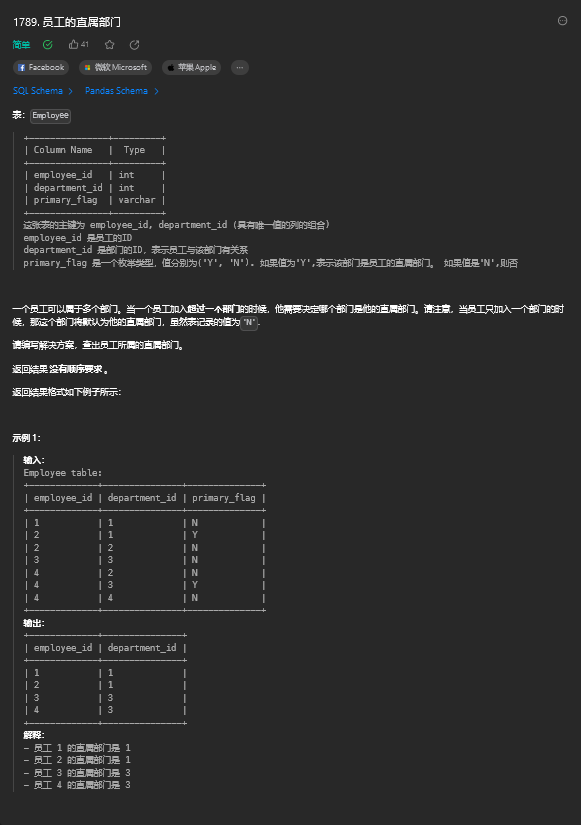
2.2. 解题思路
select b.employee_id,b.department_id
from (
select employee_id,max(primary_flag) as primary_flag
from Employee
group by employee_id
)as a inner join Employee as b on a.employee_id=b.employee_id and a.primary_flag=b.primary_flag;
3. 判断三角形
3.1. 题目描述
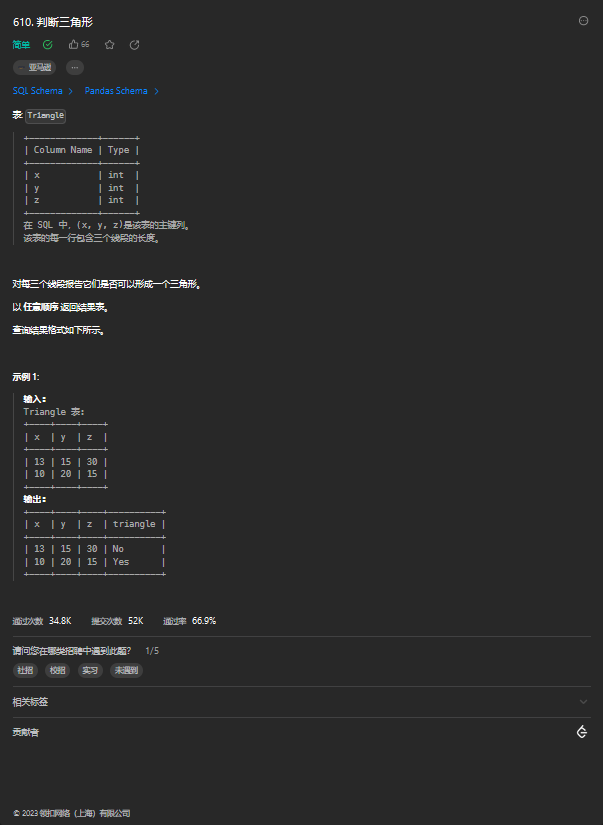
3.2. 解题思路
select x, y, z,
(case when x+y>z and x+z>y and y+z>x then 'Yes' else 'No' end) as triangle
from Triangle4. 连续出现的数字
4.1. 题目描述
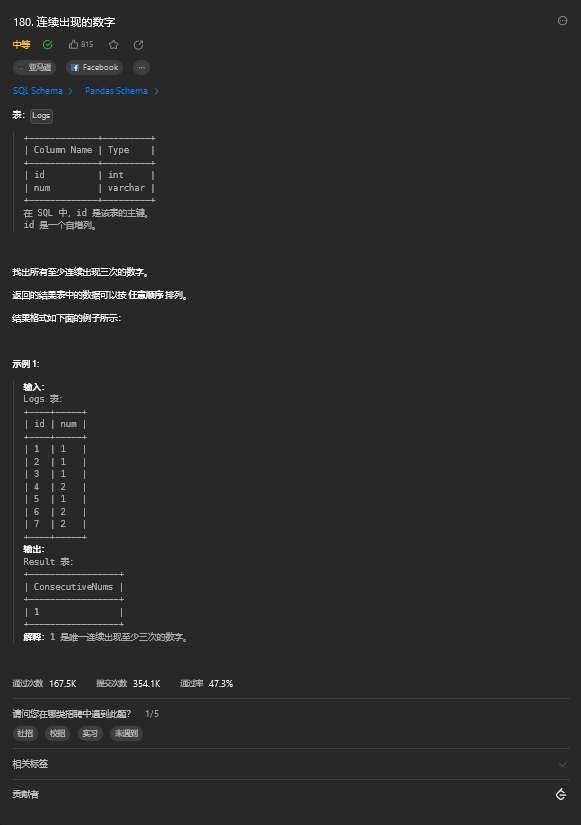
4.2. 解题思路
解法一:自关联使用三张表
这种做法虽然简单,理解也容易,且通用性好,可以在其他数据库中正确运行;
但是性能不是特别好,涉及三张表连接查询。
SELECT distinct(l1.Num) AS ConsecutiveNums
FROM Logs l1
LEFT JOIN Logs l2 ON l1.Id = l2.Id - 1
LEFT JOIN logs l3 ON l1.Id = l3.Id - 2
WHERE l1.Num = l2.Num AND l1.Num = l3.Num;解法二:利用变量
利用用户变量实现对连续出现的值进行计数。 两个变量,一个用于判断,一个用于计数;
可扩展性好,可以很对数字进行修改;通用性不强,在MySQL中可以运行,PostgreSQL中不能。
select distinct Num as ConsecutiveNums
from (
select Num,
case
when @prev = Num then @count := @count + 1
when (@prev := Num) is not null then @count := 1
end as CNT
from Logs, (select @prev := null,@count := null) as t
) as temp
where temp.CNT >= 3变量在MySQL是一个极为优秀的功能。
解法三: 存在量词
exists 关键字
select distinct num as ConsecutiveNums
from Logs l1 where
exists( select 1 from logs l2 where l1.num = l2.num and l1.id = l2.id-1)
and exists( select 1 from logs l2 where l1.num = l2.num and l1.id = l2.id-2)5. 指定日期的产品价格
5.1. 题目描述
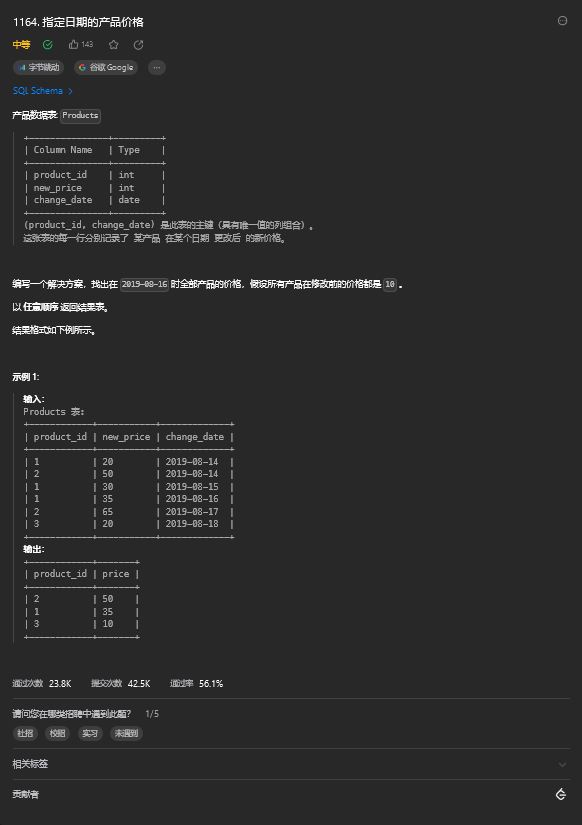
5.2. 解题思路
select p1.product_id, ifnull(p2.new_price,10) as price from
(
select distinct product_id from Products
) p1
left join
(
select product_id, new_price from Products
where (product_id,change_date) in (
select product_id, max(change_date) from Products
where change_date <= "2019-08-16"
group by product_id
)
) p2
on p1.product_id = p2.product_id6. 最后一个能进入电梯的人
6.1. 题目描述

6.2. 解题思路
方法一:自连接
SELECT a.person_name
FROM Queue a, Queue b
WHERE a.turn >= b.turn
GROUP BY a.person_id HAVING SUM(b.weight) <= 1000
ORDER BY a.turn DESC
LIMIT 1方法二:自定义变量
根据上面的思路,我们还可以使用自定义变量。
将每一条记录的 weight 按照 turn 的顺序和自定义变量相加并生成新的记录。生成临时表并处理。
SELECT a.person_name
FROM (
SELECT person_name, @pre := @pre + weight AS weight
FROM Queue, (SELECT @pre := 0) tmp
ORDER BY turn
) a
WHERE a.weight <= 1000
ORDER BY a.weight DESC
LIMIT 17. 按分类统计薪水
7.1. 题目描述

7.2. 解题思路
SELECT
'Low Salary' AS category,
sum( income < 20000 ) AS accounts_count
FROM accounts
UNION ALL
SELECT
'Average Salary' AS category,
sum( income >= 20000 AND income <= 50000 ) AS accounts_count
FROM accounts
UNION ALL
SELECT
'High Salary' AS category,
sum( income > 50000 ) AS accounts_count
FROM accounts
8. 连续空余座位
8.1. 题目描述

8.2. 解题思路
join
select
distinct c1.seat_id
from cinema c1 join cinema c2
on abs(c1.seat_id - c2.seat_id) = 1 and c1.free = 1 and c2.free = 1
order by c1.seat_id;row_number() over()
with temp as (
select
seat_id,
seat_id - row_number() over() as k
from cinema where free = 1
)
select seat_id from temp where k in (
select k from temp group by k having count(*) >= 2
);变量
with temp as (
select
seat_id,
case
when @pre_free = free and free = 1 then @pre_seat_id
when @pre_free:=free then @pre_seat_id:=seat_id
end as k
from cinema, (select @pre_free:=null, @pre_seat_id:=null) init
)
select seat_id from temp where k in (
select k from temp group by k having count(*) >= 2
);9. 每个产品在不同商店的价格
9.1 题目描述
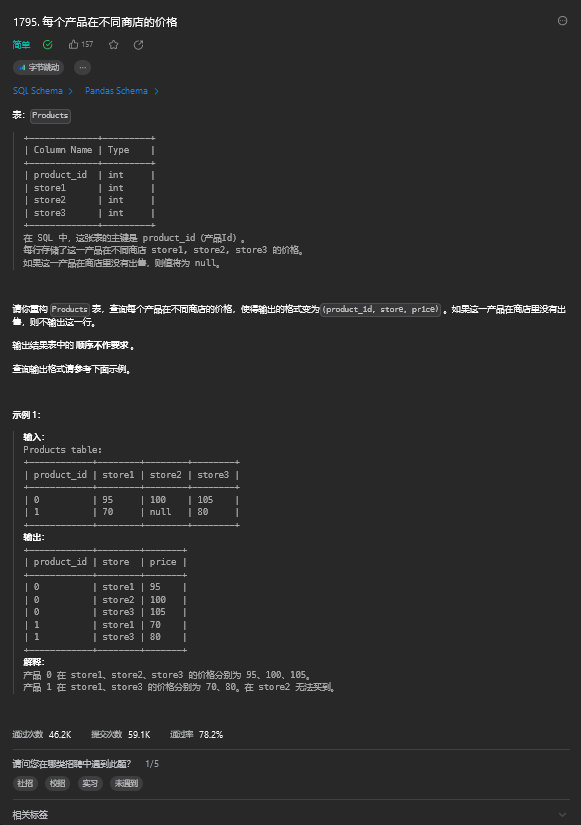
9.2 解题思路
select product_id, 'store1' as store, store1 as price from Products where store1 is not null
union
select product_id, 'store2' as store, store2 as price from Products where store2 is not null
union
select product_id, 'store3' as store, store3 as price from Products where store3 is not null;10. 直线上的最近距离
10.1 题目描述
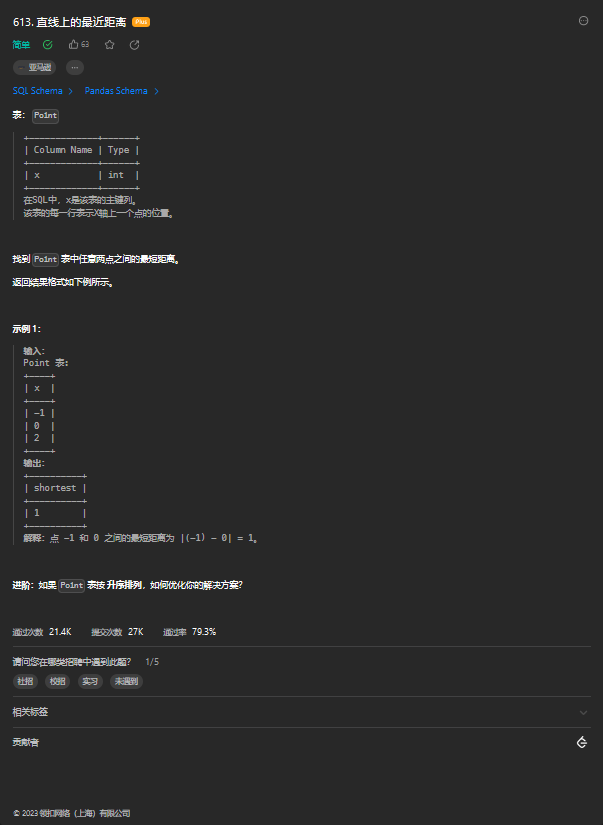
10.2 解题思路
select abs(a.x - b.x) as shortest from point a, point b
where a.x != b.x
order by shortest
limit 0,111. 丢失信息的雇员
11.1 题目描述
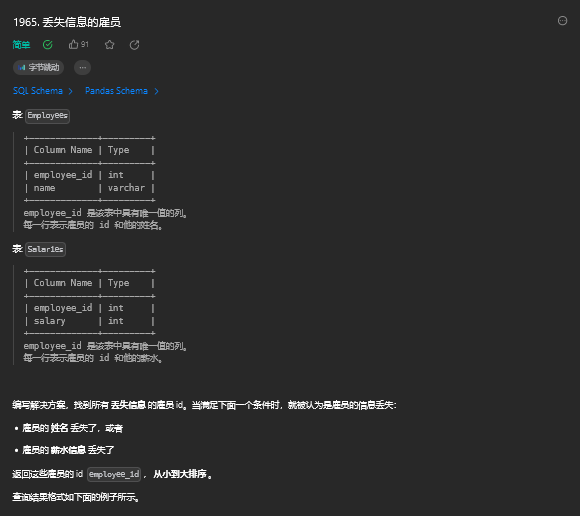
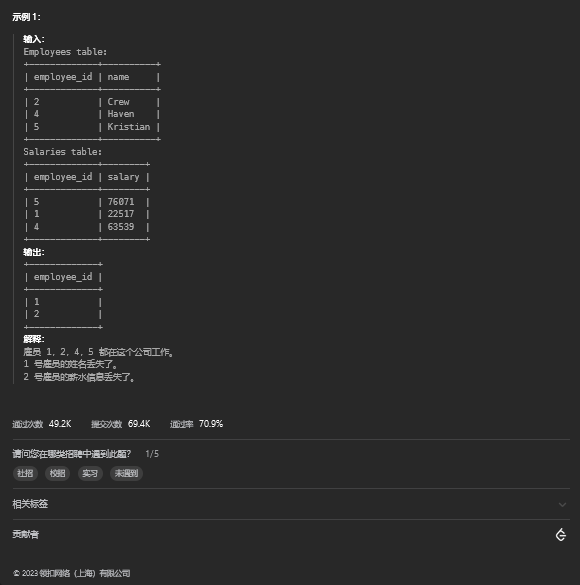
11.2 解题思路
select e.employee_id
from Employees e
left outer join Salaries s
on e.employee_id = s.employee_id
where s.employee_id is null
union
select s.employee_id
from Employees e
right outer join Salaries s
on e.employee_id = s.employee_id
where e.employee_id is null
order by employee_id;12. 页面推荐
12.1 题目描述
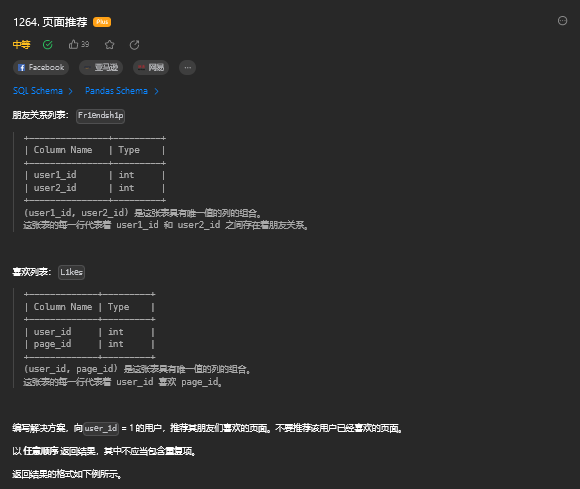
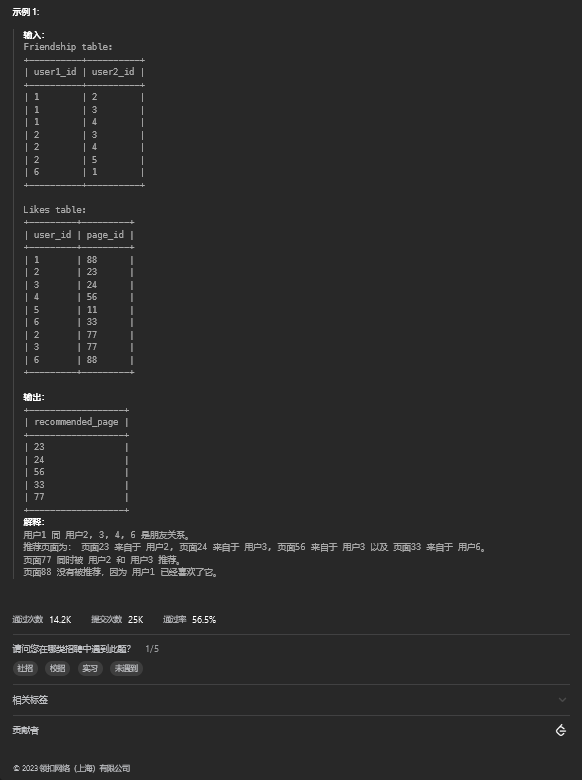
12.2 解题思路
方法一
SELECT DISTINCT page_id AS recommended_page
FROM Likes
WHERE user_id IN (SELECT user1_id AS friend
FROM Friendship
WHERE user2_id = 1
UNION
SELECT user2_id AS friend
FROM Friendship
WHERE user1_id = 1)
AND page_id NOT IN (SELECT page_id
FROM Likes
WHERE user_id = 1);方法二
with
tmp as (
select
distinct
case when user1_id = 1 then user2_id else user1_id end user_id
from Friendship
where user1_id = 1
or user2_id = 1
)
select
distinct
a.page_id recommended_page
from Likes a
inner join tmp b
on a.user_id = b.user_id
where not exists (
select 1 from Likes c
where c.user_id = 1
and a.page_id = c.page_id);13. 树节点
13.1 题目描述
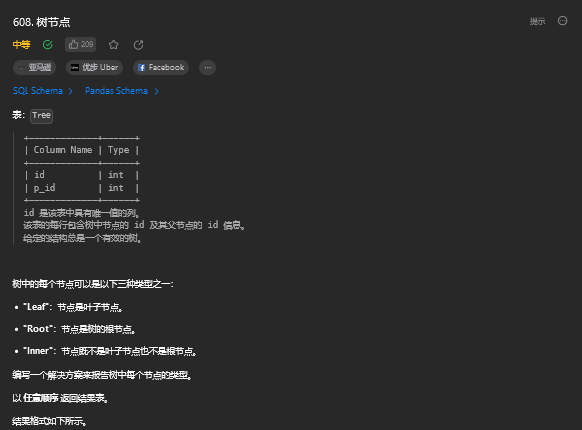
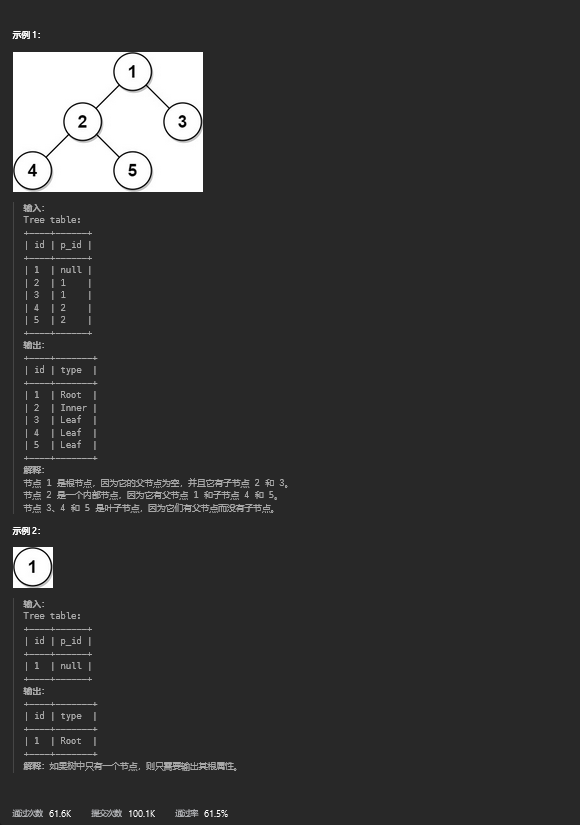
13.2 解题思路
select
id,
case
when p_id is null then 'Root'
when id in (select distinct p_id from tree) then 'Inner' # 当not in() 里面包含null值,查询不会返回任何值
else 'Leaf'
end as type
from
tree
order by id14. 游戏玩法分析 III
14.1 题目描述
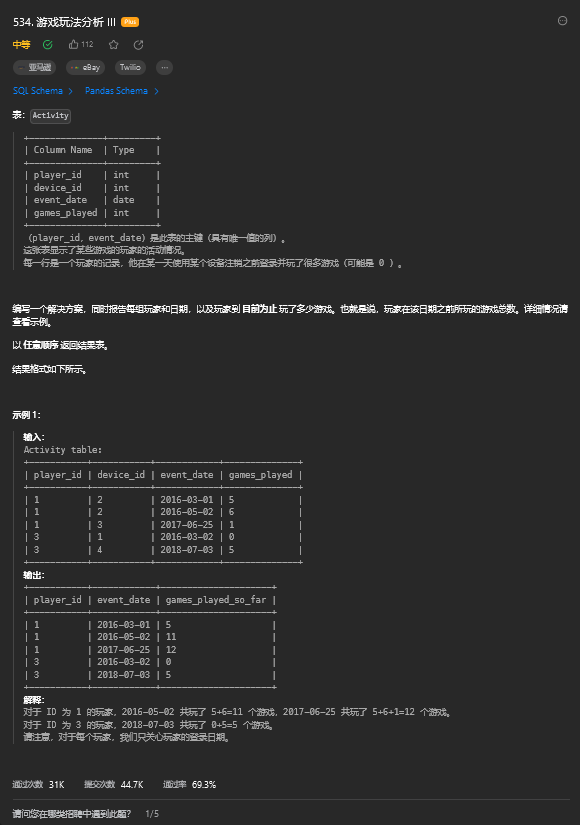
14.2 解题思路
sum() over()
select
player_id
, event_date
, sum(games_played) over(partition by player_id order by event_date) as games_played_so_far
from activity;join
select
t1.player_id
, t1.event_date
, sum(t2.games_played) games_played_so_far
from Activity t1,Activity t2
where t1.player_id=t2.player_id and t1.event_date>=t2.event_date
group by t1.player_id,t1.event_date;变量
select player_id, event_date,
sum(
case
when @pre_player_id = player_id then @n:=@n+games_played
when @pre_player_id:= player_id then @n:=games_played
end
) as games_played_so_far
from (
select * from activity order by player_id, event_date
) temp, (select @pre_player_id:=null, @n:=0) init
group by player_id, event_date;15. 大满贯数量
15.1 题目描述
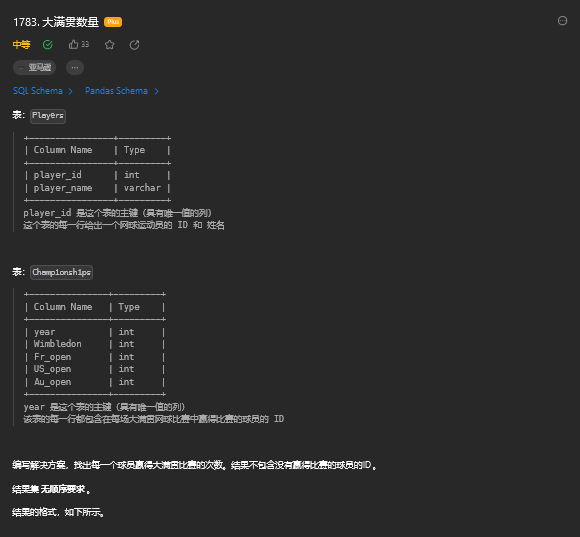
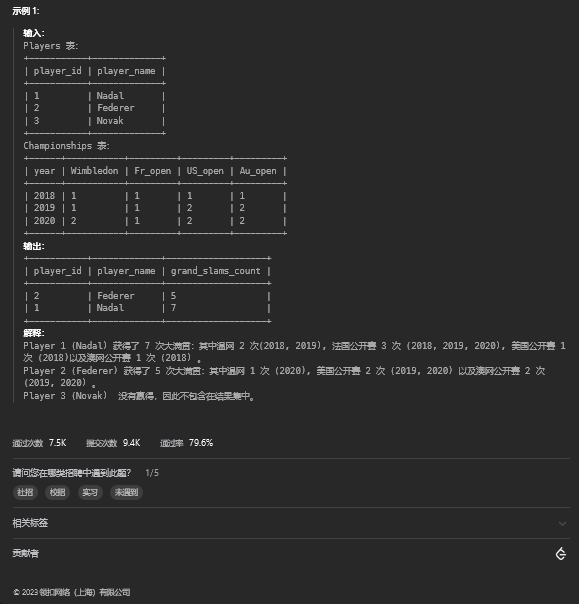
15.2 解题思路
1. 方法一
SELECT
p.player_id,
p.player_name,
sum( player_id = wimbledon )+ sum( player_id = fr_open )+ sum( player_id = us_open )+ sum( player_id = au_open ) AS grand_slams_count
FROM
players p
JOIN championships c
GROUP BY
p.player_id,
p.player_name
HAVING
grand_slams_count > 02. 方法二
select player_id,player_name, count(*) grand_slams_count from
players join
(select wimbledon from championships
union all
select fr_open from championships
union all
select us_open from championships
union all
select au_open from championships)t
on player_id=wimbledon
group by player_id,player_name16. 应该被禁止的 Leetflex 账户
16.1 题目描述
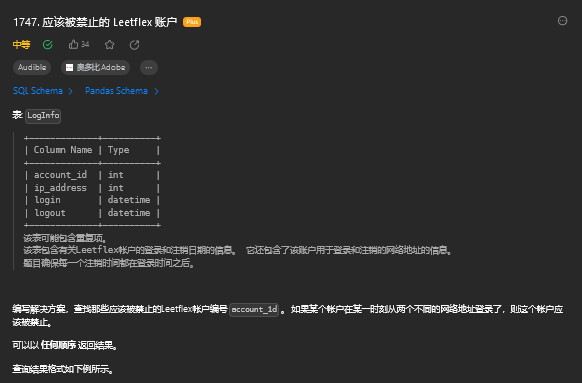
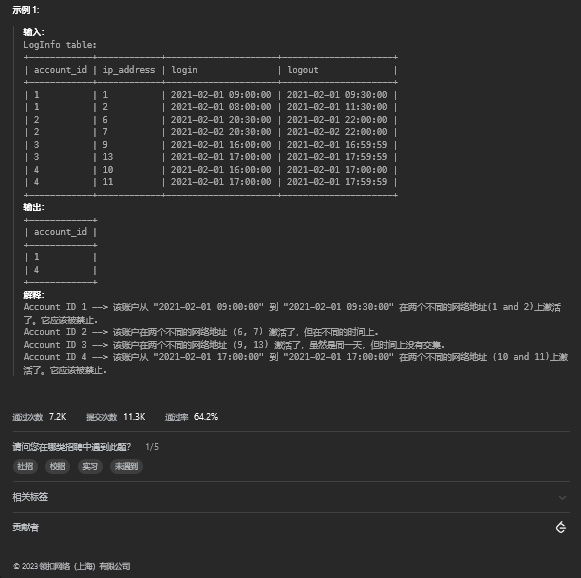
16.2 解题思路
1. 方法一
select distinct a.account_id
from loginfo a join loginfo b on a.account_id = b.account_id
where a.ip_address != b.ip_address and !(a.logout < b.login || b.logout < a.login)2. 方法二
SELECT DISTINCT l1.account_id
FROM LogInfo l1 JOIN LogInfo l2 ON l1.account_id = l2.account_id AND l1.ip_address <> l2.ip_address
AND (l1.login BETWEEN l2.login AND l2.logout OR l1.logout BETWEEN l2.login AND l2.logout)