头歌实践教学平台 数据采集与处理技术 实训答案(二)
第三阶段 数据采集
练习1:urllib 爬虫
第1关:urllib基础
任务描述
本关任务:掌握 urlopen 函数的使用,完成一个简易的爬取程序。
相关知识
为了完成本关任务,你需要掌握:urlopen 函数。
urlopen函数
urlopen 函数是 urllib 模块下的一个方法,用于实现对目标 url 的访问。函数原型如下:
import urllib # 导入urllib包
urllib.request.urlopen(url, data=None, cafile=None, capath=None,
cadefault=False, context=None)
参数说明:
url 参数:统一资源定位符,目标资源在网络中的位置(如:https://www.xxx.com/);
data 参数:data 用来指明发往服务器请求中的额外信息,data 必须是一个字节数据对象,默认为 None;
cafile、capath、cadefault 参数:用于实现可信任的 CA 证书的 HTTP 请求;
context 参数:实现 SSL 加密传输。
urlopen函数的使用
现在通过访问百度网站,演示如何使用 urlopen 函数。代码如下:
import urllib
response = urllib.request.urlopen(url="http://www.baidu.com") # 打开百度网站
print(type(response)) # 打印数据类型
执行结果如下:

可以看到,得到的数据类型为<class 'http.client.HTTPResponse'>,这种类型的数据是浏览器返回的响应结果,不能够直接使用,需要通过 read 进行内容读取。演示如下:

可以看到,通过 read 方法读取了网页的代码,但是存在一些乱码,是因为编码不对。可以通过指定编码,使乱码正常显示。演示如下:

可以看到,乱码问题得到了解决。
import urllib.request
def request(url):
'''
一个参数
:param url:请求网址
:return:返回一个请求的字符串。编码为utf-8
'''
# *************** Begin *************** #
response = urllib.request.urlopen(url)
html = response.read()
html = html.decode('utf-8')
return html
# *************** End ***************** #第2关:urllib进阶
任务描述
本关任务:利用 Opener 方法,完成一个简易的爬取程序。。
相关知识
为了完成本关任务,你需要掌握:Opener 方法。
Request类
第一关介绍了 urlopen(),它可以实现最基本的请求发起,但构建还不是一个完整的请求,如果请求中需要加入 headers 等信息,需要利用更强大的 Request 类来构建一个请求。
request 是 urllib 库的一个重要模块, 提供了最基本的构造 HTTP 请求的方法,利用它可以模拟浏览器的一个请求发起过程,可以用来发送 request 和获取 request 的结果。
import urllib.request
import http.cookiejar
def request(url,headers):
'''
两个参数
:param url:统一资源定位符,请求网址
:param headers:请求头
:return:html
'''
# ***************** Begin ******************** #
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
request = urllib.request.Request(url,headers=headers)
r = opener.open(request)
# ***************** End ******************** #
html = r.read().decode('utf-8')
return html练习2:requests 爬虫
第1关:requests 基础
任务描述
本关任务:编写一个 requests 请求网页的程序。
相关知识
为了完成本关任务,你需要掌握:requests 的安装和 requests 的常用方法。
requests 的安装
我们之前介绍了 urllib 库的使用,它是作为爬虫入门工具来介绍的,对新手理解 Python 爬虫的整个流程很有帮助。在掌握了爬虫基本思想流程后,就需要引入更高级的工具来提高我们的开发效率,这里就开始给大家介绍 requests 库的使用。
如果本地 Python 环境没有安装 requests,可以在命令提示符窗口输入命令pip install requests,安装 requests 模块,如下图所示。

import requests
def get_html(url):
'''
两个参数
:param url:统一资源定位符,请求网址
:param headers:请求头
:return:html
'''
# ***************** Begin ******************** #
# 补充请求头
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/" "537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
# get请求网页
re = requests.get(url,headers = header)
# 获取网页信息文本
re.encoding = "utf-8"
html = re.text
# ***************** End ******************** #
return html第2关:requests 进阶
任务描述
本关任务:使用 session 编写爬取网页的小程序。
相关知识
为了完成本关任务,你需要掌握:cookie 与 session 的使用。
cookie的使用
当你浏览某网站时,Web 服务器会修改修改你电脑上的 Cookies 文件,它是一个非常小的文本文件,可以记录你的用户 ID 、密码、浏览过的网页、停留的时间等信息。 当你再次来到该网站时,网站通过读取 Cookies 文件,得知你的相关信息,从而做出相应的动作,如在页面显示欢迎你的标语,或者让你不用输入 ID、密码就直接登录等等。
import requests
def get_html(url):
'''
两个参数
:param url:统一资源定位符,请求网址
:param headers:请求头
:return html 网页的源码
:return sess 创建的会话
'''
# ***************** Begin ******************** #
# 补充请求头
headers={ 'User-Agent': 'Mozilla/5.0 (Linux; Android 8.0.0; Pixel 2 XL Build/OPD1.170816.004) AppleWebKit/'
'537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36',
"Cookie": "BAIDUID=53B7CC4BFCDC39D2EF625C13D285429D:FG=1; BIDUPSID=53B7CC4BFCDC39D2EF625C13D285429D; "
"PSTM=1591665716; BD_UPN=12314753; BDUSS=2N2ajRYZnI2cVlZN1FRemlWNU9FV1lSZFM3SnZBS0dvRW44WFRCUTRWck1mUVpmR"
"VFBQUFBJCQAAAAAAAAAAAEAAAAoKJzNMTIyMzM4ODQ1uNW41QAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"
"AAAAAAAAAAAAMzw3l7M8N5eS; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; sug=3; sugstore=1; ORIGIN=0; bdime=0; "
"H_PS_PSSID=1456_31672_32139_31253_32046_32230_31708_32295_26350_22160; delPer=0; BD_CK_SAM=1; PSINO=6; "
"H_PS_645EC=3b86vFCd303Aw0wmqvkcAGpfxU4oXfwYcs6jRd1RnxihTsvhfqaVB%2BIoeBs; BDSVRTM=0" }
# 创建Session, 并使用Session的get请求网页
sess = requests.session()
response = sess.get(url,headers = headers)
# 获取网页信息文本
response.conding = "utf-8"
html = response.text
# ****************** End ********************* #
return html, sess练习3:网页数据解析
第1关:XPath解析网页
任务描述
本关任务:在 XPath 基础实训中,介绍了 XPath 的基础知识,本关需要使用 XPath 技术来编写解析网页的程序。
相关知识
为了完成本关任务,你需要掌握 XPath 的使用。
XPath概念
XPath ,全称 XML Path Language ,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的搜索。所以在做爬虫时,完全可以使用 XPath 做相应的信息抽取。
XPath 的选择功能十分强大,它提供了非常简洁明了的路径选择表达式。另外,它还提供了超过 100 个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有想要定位的节点都可以用 XPath 来选择。
import urllib.request
from lxml import etree
def get_data(url):
'''
:param url: 请求地址
:return: None
'''
response=urllib.request.urlopen(url=url)
html=response.read().decode("utf-8")
# *************** Begin *************** #
parse = etree.HTML(html)
item_list = parse.xpath("//div[@class='left']/ul/li/span/a/text()")
# *************** End *****************
print(item_list)
第2关:BeautifulSoup解析网页
任务描述
本关任务:使用 BeautifulSoup 解析网页爬取古诗词的内容部分。
相关知识
为了完成本关任务,你需要掌握:BeautifulSoup 的使用。
BeautifulSoup 库的安装
BeautifulSoup 和 lxml 一样,BeautifulSoup 也是一个 HTML/XML 的解析器,主要的功能也是解析和提取 HTML/XML 数据。
如果本地 Python 环境没有安装 BeautifulSoup,可以在命令提示符窗口输入命令pip install bs4,安装 BeautifulSoup 模块,如下图所示。

import requests
from bs4 import BeautifulSoup
def get_data(url, headers):
'''
两个参数
:param url:统一资源定位符,请求网址
:param headers:请求头
:return data:list类型的所有古诗内容
'''
# ***************** Begin ******************** #
sess = requests.session()
response = sess.get(url, headers = headers)
# 获取网页信息文本
response.conding = "utf-8"
html = response.text
soup = BeautifulSoup(html,'lxml')
# ****************** end ********************* #
data1 = list()
for i in range(11):
data = soup.find_all('p')[i].get_text()
data1.append(str(data))
return data1
练习4:JSON数据解析
第1关:JSON解析
任务描述
本关任务:编写一个能用 JSON 解析爬虫数据的小程序。
相关知识
为了完成本关任务,你需要掌握:JSON 的使用方法。
json 库的使用
这里回顾一下 json 库的使用。在 Python 中,可以使用 json 库对 JSON 数据进行编解码。
import urllib.request
from lxml import etree
import http.cookiejar
import json
def request_sess(url,headers):
cj=http.cookiejar.CookieJar()
opener=urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
request = urllib.request.Request(url=url, headers=headers)
r=opener.open(fullurl=request)
html = r.read().decode('utf-8')
return html
def save_data(path):
'''
:param path: 文件保存路径
:return: 无
'''
url='http://127.0.0.1:8080/index'
headers={
'User-Agent':'Mozilla/5.0 (Linux; Android 8.0.0; Pixel 2 XL Build/OPD1.170816.004) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36'
}
# ********** Begin ************** #
# 输出 JSON 数据中的 key 值为 code 对应的数据
data = request_sess(url,headers)
json_str = json.loads(data)
print(json_str['code'])
# 将爬取下来的 JSON 数据保存到本地
with open(path,'w') as f:
json.dump(json_str,f)
# ********** End ************** #练习5:网页抓取及信息提取
第1关:利用URL获取超文本文件并保存至本地
任务描述
当我们想要在浏览器中打开一个网页时,需要在浏览器的地址栏中输入该网页的url,例如在地址栏中输入百度搜索网站的首页url:https://www.baidu.com/ ,点击确认后,浏览器将向服务器发出一个对该网的请求;服务器端收到请求后,会返回该网页的超文本文件,浏览器收到服务器端发来的网页超文本文件后,对其进行解析,然后在窗口中显示该超文本文件对应的网页。如下图所示。

网页对应的超文本文件如下图所示。

本关我们将使用Python程序,实现通过网页的url,获得服务器返回的超文本文件,并打印出来的功能。
# -*- coding: utf-8 -*-
import urllib.request as req
import os
import hashlib
# 国防科技大学本科招生信息网中录取分数网页URL:
url = 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/index.html' # 录取分数网页URL
def step1():
# 请按下面的注释提示添加代码,完成相应功能
#********** Begin *********#
# 1.将网页内容保存到data
age = req.urlopen(url)
data = age.read()
# 2.将data以二进制写模式写入以学号命名的 “nudt.txt” 文件:
f = open('nudt.txt','wb')
f.write(data)
f.close()
#********** End **********#第2关:提取子链接
任务描述
上一关我们学习了如何访问给定的网页并保存信息到本地,本关我们要从上一关访问的网页中提取出嵌套的url地址,即实现子链接的提取。
# -*- coding: utf-8 -*-
import urllib.request as req
# 国防科技大学本科招生信息网中录取分数网页URL:
url = 'https://www.nudt.edu.cn/bkzs/xxgk/lqfs/index.htm' # 录取分数网页URL
webpage = req.urlopen(url) # 按照类文件的方式打开网页
data = webpage.read() # 一次性读取网页的所有数据
data = data.decode('utf-8') # 将byte类型的data解码为字符串(否则后面查找就要另外处理了)
def step2():
# 建立空列表urls,来保存子网页的url
urls = []
# 请按下面的注释提示添加代码,完成相应功能
#********** Begin *********#
# 从data中提取2016到2012每一年分数线子网站地址添加到urls列表中
years = [2021,2020,2019,2018,2017,2016, 2015, 2014]
for year in years:
index = data.find("%s年录取分数统计(生长军官学员)" %year)
href= data[index-134:index-97]# 根据单个特征串提取url子串
website = 'https://www.nudt.edu.cn/bkzs/xxgk/lqfs/'
urls.append(website+href)
#********** End **********#
return urls第3关:网页数据分析
任务描述
下图是2016年国防科技大学分数线的网页,在浏览器中我们可以看到,各省的最高分、最低分、平均分都整齐地排列自在表格中。一个网页的源代码时常有成百上千行,其中很多代码都是为了布局页面样式服务的,而我们时常关心的是网页上的数据,而并不关心样式代码。所以如何从冗长的网页源代码中提取我们关心的数据,是这一关我们将要一起学习和体验的内容。

# -*- coding: utf-8 -*-
import urllib.request as req
import re
# 国防科技大学本科招生信息网中2016年录取分数网页URL:
url = 'https://www.nudt.edu.cn/bkzs/xxgk/lqfs/6a4ee15ca795454083ed233f502b262b.htm'
webpage = req.urlopen(url) # 根据超链访问链接的网页
data = webpage.read() # 读取超链网页数据
data = data.decode('utf-8') # byte类型解码为字符串
# 获取网页中的第一个表格中所有内容:
table = re.findall(r'<table(.*?)</table>', data, re.S)
firsttable = table[0] # 取网页中的第一个表格
# 数据清洗,将表中的 ,\u3000,和空格号去掉
firsttable = firsttable.replace(' ', '')
firsttable = firsttable.replace('\u3000', '')
firsttable = firsttable.replace(' ', '')
def step3():
score = []
# 请按下面的注释提示添加代码,完成相应功能,若要查看详细html代码,可在浏览器中打开url,查看页面源代码。
#********** Begin *********#
# 1.按tr标签对获取表格中所有行,保存在列表rows中:
rows = re.findall(r'<tr(.*?)</tr>', firsttable, re.S)
# 2.迭代rows中的所有元素,获取每一行的td标签内的数据,并把数据组成item列表,将每一个item添加到scorelist列表:
scorelist = []
for row in rows:
items = []
tds = re.findall(r'<td.*?>(.*?)</td>', row, re.S)
for td in tds:
# 提取<td>标签中的文本内容
clean_text = re.sub(r'<.*?>', '', td)
items.append(clean_text.strip())
scorelist.append(items)
# 3.将由省份,分数组成的8元列表(分数不存在的用/代替)作为元素保存到新列表score中,不要保存多余信息
for record in scorelist[1:]: # 跳过表头
if len(record) >= 8:
cleaned_record = record[:8]
score.append(cleaned_record)
#********** End **********#
return score爬虫实战——求是网周刊文章爬取
第1关:获取新闻url
任务描述
本关任务:编写一个爬虫,并使用正则表达式获取求是周刊2019年第一期的所有文章的url。详情请查看《求是》2019年第1期 。
相关知识
获取每个新闻的url有以下几个步骤:
首先获取2019年第1期页面的源码,需要解决部分反爬机制;
找到目标url所在位置,观察其特征;
编写正则表达式,获取目标数据。
import requests
import re
def geturls():
# ********** Begin ********** #
url = 'http://www.qstheory.cn/dukan/qs/2014/2019-01/01/c_1123924172.htm'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36",
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8'
}
# ********** End ********** #
response = requests.get(url,headers=headers)
result = response.content.decode("utf8")
urls = re.findall('<a\shref="(.+?)"\starget="_[a-z]+?"><strong>',result)
return urls
if __name__ == "__main__":
urls = geturls()
for x in urls:
print(x)第2关:获取文章内容
任务描述
本关任务:编写一个爬虫,请求上一关获取的每个url,获取每篇文章的标题、作者、正文以及文章中全部图片的完整url。
相关知识
为了完成本关任务,你需要掌握xpath的基本使用。
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36"
}
def parsepage(urls):
mainbody = [] # 保存新闻内容
# ********** Begin ********** #
for url in urls:
response = requests.get(url,headers=headers)
result = response.content.decode("utf8")
html = etree.HTML(result)
img = html.xpath('//div[@class="highlight"]//p//img//@scr')
# 获取图片的url
imgurl = []
split_url = url.split("/")
split_url.pop(-1)
if len(img) >= 1:
for x in img:
imgurl.append("/".join(split_url)+"/"+x)
else:
imgurl=""
# 获取标题并去除首尾空格
title = "".join(html.xpath('//div[@class="row"]//div[@class="inner"]//h1/text()')).strip()
# 获取作者并去除首尾空格
author = (html.xpath('//div[@class="row"]//span[@class="appellation"]//text()')[-1].split(":")[-1]).strip()
# 获取正文并去除首尾空格
cont = html.xpath('//div[@class="content"]//div[@class="highlight"]/p//*[not(@color="navy")]/text()|//div[@class="highlight"]/p/text()')
content = "".join(cont).strip()
mainbody.append({"title":title,"author":author,"content":content,"imgurl":imgurl})
# ********** End ********** #
return mainbody
第四阶段 数据清洗
Pandas数值运算与缺失值处理
第1关:Pandas数值运算方法
任务描述
本关任务:获取鸢尾花数据集前30行并转换成DataFrame,然后让每一行都减去第一行的值,输出运算后的结果。
相关知识
Pandas在数值运算方面继承了NumPy的通用函数等功能,实现了一些高效技巧。
import pandas as pd
from sklearn import datasets
def demo1():
iris = datasets.load_iris().data # 鸢尾花数据集,返回的是array
#********** Begin **********#
df = pd.DataFrame(iris[:30],columns=['a','b','c','d'])
print(df - df.iloc[0])
#********** End **********#第2关:Pandas缺失值类型
任务描述
本关任务:根据所学知识完成右侧选择题。
相关知识
本关卡主要介绍Pandas自带的几个处理缺失值的工具的用法,该系列Pandas实训的缺失值主要有三种形式:null、NaN或NA。
选择处理缺失值的方法
一般情况下可以分为两种:一种方法是通过一个覆盖全局的掩码表示缺失值,另一种方法是用一个**标签值(sentinel value)**表示缺失值。
掩码方法中掩码可能是一个与原数组维度相同的完整布尔类型数组,也可能是用一个比特(0或1)表示有缺失值的局部状态;
标签方法中,标签值可能是具体的数据(例如用-9999表示缺失的整数),也可能是些极少出现的形式。
实训答案:1、D;2、E
第3关:缺失值处理
任务描述
本关任务:按照编程要求完成任务并输出目标DataFrame。
import numpy as np
import pandas as pd
from sklearn import datasets
def demo3():
iris = datasets.load_iris().data
#********** Begin **********#
df = pd.DataFrame(iris[:30],columns = ['a','b','c','d'])
subdf = df.sub(df.iloc[0])
subdf[subdf < 0] = np.nan
subdf1 = subdf.dropna(axis = 'rows',thresh = 2)
print(subdf1.fillna(method = 'ffill'))
#********** End **********#第五阶段 数据集成
Pandas合并数据集
第1关:Concat与Append操作
任务描述
本关任务:使用read_csv()读取两个csv文件中的数据,将两个数据集合并,将索引设为Ladder列,并将缺失值填充为0。
相关知识
在Numpy中,我们介绍过可以用np.concatenate、np.stack、np.vstack和np.hstack实现合并功能。Pandas中有一个pd.concat()函数与concatenate语法类似,但是配置参数更多,功能也更强大,主要参数如下。
| 参数名 | 说明 |
|---|---|
| objs | 参与连接的对象,必要参数 |
| axis | 指定轴,默认为0 |
| join | inner或者outer,默认为outer,指明其他轴的索引按哪种方式进行合并,inner表示取交集,outer表示取并集 |
| join_axes | 指明用于其他n-1条轴的索引,不执行并集/交集运算 |
| keys | 与连接对象有关的值,用于形成连接轴向上的层次化索引。可以是任意值的列表或数组 |
| levels | 指定用作层次化索引各级别上的索引 |
| names | 用于创建分层级别的名称,如果设置了keys和levels |
| verify_integrity | 检查结果对象新轴上的重复情况,如果发现则引发异常。默认False允许重复 |
| ignore_index | 不保留连接轴上的索引,产生一组新索引 |
pd.concat()可以简单地合并一维的Series或DataFrame对象。
import pandas as pd
def task1():
#********** Begin **********#
df = pd.read_csv("step1/data.csv")
df1 = pd.read_csv("step1/data1.csv")
data = pd.concat([df,df1],axis=1)
data=data.T.drop_duplicates().T #通过两次装置删除重复列
data.index.name = "Ladder"
result=data.fillna(0)
#********** End **********#
return result第2关:合并与连接
任务描述
本关任务:使用pandas中的merge()函数按照编程要求合并三份数据。
相关知识
merge()可根据一个或者多个键将不同的DataFrame连接在一起,类似于SQL数据库中的合并操作。
| 参数名 | 说明 |
|---|---|
| left | 拼接左侧DataFrame对象 |
| right | 拼接右侧DataFrame对象 |
| on | 列(名称)连接,必须在左和右DataFrame对象中存在(找到)。 |
| left_on | 左侧DataFrame中的列或索引级别用作键,可以是列名、索引级名,也可以是长度等于DataFrame长度的数组。 |
| right_on | 右侧DataFrame中的列或索引级别用作键。可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。 |
| left_index | 如果为True,则使用左侧DataFrame中的索引(行标签)作为其连接键。 |
| right_index | 与left_index相似 |
| how | 它可以等于’left’, ‘right’, ‘outer’, ‘inner’. 默认inner。inner是取交集,outer取并集。 |
| sort | sort - 按照字典顺序通过连接键对结果DataFrame进行排序。 |
| suffixes | 用于追加到重叠列名的末尾。例如,左右两个DataFrame都有‘data’列,则结果中就会出现‘data_x’和‘data_y’. |
| copy | 默认总是复制 |
import pandas as pd
def task2(dataset1, dataset2, dataset3):
# ********** Begin **********#
d1, d2, d3 = pd.DataFrame(dataset1), pd.DataFrame(dataset2), pd.DataFrame(dataset3)
result = pd.merge(d3, pd.merge(d1, d2, on='user_id', how='outer'), left_on='id', right_on='user_id', how='outer')
result['user_id'] = result['user_id'].fillna(result['id'])
result['page_click_count_y'] = result['page_click_count_y'].fillna(result['page_click_count_x'])
result['city_x'] = result['city_x'].fillna(result['city_y'])
result = result.drop(['id', 'page_click_count_x', 'city_y'], axis=1)
result.rename(columns={'city_x': 'city', 'page_click_count_y': 'page_click_count'}, inplace=True)
result = result.sort_values(by="user_id")
result['user_id'] = result['user_id'].values.astype(int)
# 调整列顺序
result = result[['user_id', 'page_click_count', 'city']]
# ********** End **********#
return result第3关:案例:美国各州的统计数据
任务描述
本关为练习关卡,请按照编程要求完成任务,获取美国各州2010年的人口密度排名。
编程要求
- 使用
read_csv()函数读取step3文件夹中的state-population.csv(pop)、state-areas.csv(areas)、state-abbrevs.csv(abbrevs)文件;
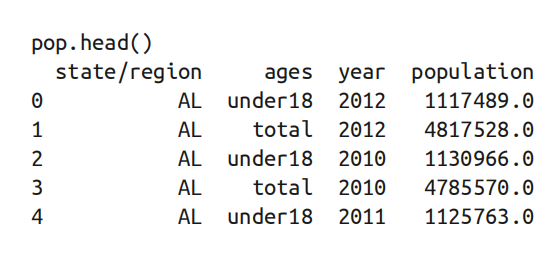


-
合并
pop和abbrevs。我们需要将pop的state/region列与abbrevs的abbreviation列进行合并,还需要通过how='outer'确保数据没有丢失,得到合并后的结果,发现有一个重复列需要删除,所以,删除abbreviation列;
-
来全面检查一下数据是否有缺失,对每个字段逐行检查是否有缺失值,通过结果可知只有
population和state列有缺失值;
-
查看
population这一列为缺失值的特征。通过结果可以得到好像所有的人口缺失值都出现在2000年之前的波多黎各,此前并没有统计过波多黎各的人口;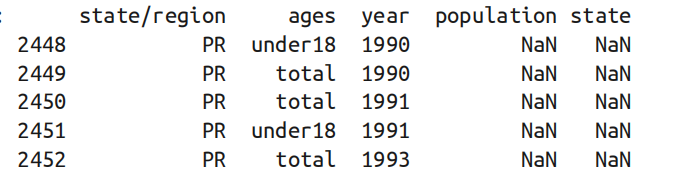
-
从上面的结果可以发现
state这一列也有缺失值,通过下列代码可以查看是哪些州有缺失值;merged.loc[merged['state'].isnull(),'state/region'].unique()

-
我们可以快速解决这个问题:人口数据中包含波多黎各
(PR)和全国总数(USA),但这两项没有出现在州名称缩写表中。我们可以用以下代码来填充对应的全称;merged.loc[merged['state/region'] == 'PR', 'state'] = 'Puerto Rico'merged.loc[merged['state/region'] == 'USA', 'state'] = 'United States'
-
然后我们用类似的规则将面积数据和处理完后的
merged合并起来。数据合并的键为state,连接方式为左连接;
-
检查缺失值,从结果中可以发现,
area列中还有缺失值; -
查看是哪个地区面积缺失。结果如下:

- 从上面的结果可以得出缺少的是全美国的面积数据,但是我们的目标数据并不需要全美国的面积数据,所以我们需要删掉这些缺失值;
- 取
year为2010年的数据,并将索引设为state列; - 计算人口密度,将
2010年的人口population除以面积area (sq. mi); - 由于人口密度中分为成年人的人口密度和未成年人的人口密度,所以我们需要对两个值进行求合得到最终的人口密度;
- 对值进行排序,取人口密度结果的前
5名与倒数5名; - 具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
import pandas as pd
import numpy as np
def task3():
#********** Begin **********#
#读取三个csv文件
pop = pd.read_csv('./step3/state-population.csv')
areas = pd.read_csv('./step3/state-areas.csv')
abbrevs = pd.read_csv('./step3/state-abbrevs.csv')
# 合并pop和abbrevs并删除重复列
result = pd.merge(pop,abbrevs,how="outer",left_on="state/region",right_on="abbreviation")
result = result.drop("abbreviation",1)
# 填充对应的全称
result.loc[result['state/region'] == 'PR', 'state'] = 'Puerto Rico'
result.loc[result['state/region'] == 'USA', 'state'] = 'United States'
# 合并面积数据
final = pd.merge(result,areas,on="state",how="left")
# 删掉这些缺失值
final.dropna(inplace=True)
# 计算未成年人与成年人的人口数量
data2010_1= final.query("year == 2010 & ages == 'total'")
data2010_2=final.query("year == 2010 & ages == 'under18'")
# 计算人口密度
p=np.array(data2010_1.loc[:,'population'])+np.array(data2010_2.loc[:,'population'])
data2010=data2010_1.copy()
data2010.loc[:,'population']=p
# 对密度求和
data2010.set_index('state', inplace=True)
density = data2010["population"] / data2010["area (sq. mi)"]
# 对值进行排序
density.sort_values(ascending=False, inplace=True)
# 输出人口密度前5名和倒数5名
print('前5名:')
print(density[:5])
print('后5名:')
print(density[-5:])
#********** End **********#Pandas分组聚合与透视表的创建
第1关:Pandas分组聚合
任务描述
本关任务:使用Pandas加载drinks.csv文件中的数据,根据数据信息求每个大洲红酒消耗量的最大值与最小值的差以及啤酒消耗量的和。
相关知识
分组聚合的流程主要有三步:
-
分割步骤:将
DataFrame按照指定的键分割成若干组; -
应用步骤:对每个组应用函数,通常是累计、转换或过滤函数;
-
组合步骤:将每一组的结果合并成一个输出数组。

import pandas as pd
import numpy as np
'''
返回最大值与最小值的和
'''
def sub(df):
######## Begin #######
return df.max() - df.min()
######## End #######
def main():
######## Begin #######
data = pd.read_csv("step1/drinks.csv")
df = pd.DataFrame(data)
mapping = {"wine_servings":sub,"beer_servings":np.sum}
return(df.groupby("continent").agg(mapping))
######## End #######
if __name__ == '__main__':
print(main)第2关:Pandas创建透视表和交叉表
任务描述
本关任务:使用Pandas加载tip.csv文件中的数据集,分别用透视表和交叉表统计顾客在每种用餐时间、每个星期下的小费总体情况。
相关知识
透视表
透视表是各种电子表格程序和其他数据分析软件中一种常见的数据汇总工具。它根据一个或多个键对数据进行聚合,并根据行和列上的分组将数据分配到各个矩形区域中。
在pandas中,可以通过pivot_table函数创建透视表。
pivot_table函数的参数:
DataFrame.pivot_table(self, values=None, index=None, columns=None,ggfunc='mean', fill_value=None, .margins=False,dropna=True, margins_name='All')
| 参数名 | 说明 |
|---|---|
values | 待聚合的列的名称。默认聚合所有数值列 |
index | 用于分组的列名或其他分组键,出现在结果透视表的行 |
columns | 用于分组的列名或其他分组键,出现在结果透视表的列 |
aggfunc | 聚合函数或函数列表,默认为mean,可以是任何对groupby有效的函数 |
fill_value | 用于替换结果表中的缺失值 |
dropna | boolean值,默认为 True,是否删除空值 |
margins | boolean值,当需要计算每一组的总数时可以设为 True |
margins_name | string,默认为‘ALL’,当参数margins为 True时,ALL行和列的名字 |
#-*- coding: utf-8 -*-
import pandas as pd
#创建透视表
def create_pivottalbe(data):
########## Begin ##########
return data.pivot_table(index=["day"], columns=["time"], values=["tip"], aggfunc=sum, margins=True)
########## End ##########
#创建交叉表
def create_crosstab(data):
########## Begin ##########
return pd.crosstab(index=data["day"], columns=data["time"], values=data["tip"], aggfunc=sum, margins=True)
########## End ##########
def main():
#读取csv文件数据并赋值给data
########## Begin ##########
data = pd.read_csv("step2/tip.csv")
########## End ##########
piv_result = create_pivottalbe(data)
cro_result = create_crosstab(data)
print("透视表:\n{}".format(piv_result))
print("交叉表:\n{}".format(cro_result))
if __name__ == '__main__':
main()