Linux 命令 | 每日一学,文本处理三剑客之grep命令实践

[ 知识是人生的灯塔,只有不断学习,才能照亮前行的道路 ]
0x00 前言简述
上一篇,我们学习了Shell脚本编程中的正则表达式【Linux 运维 | 6.从零开始,Shell编程中正则表达式 RegExp 速成指南】, 不知道各位初学的童鞋是否已经初步掌握了呢,接下来我们学习Linux中的文本处理三剑客之一grep命令,grep 命令是Linux系统中常用的文本搜索工具,它可以根据指定的字符串模式或者正则表达式对文件内容每行进行搜索、匹配等操作。

不管是那一门编程语言,字符串类型都是及其重要的,所以在学习各种编程语言后会发现近40%左右都与字符串有关,特别是在php、java编程,当然在Linux中的shell脚本开发也同样存在, 所以这也是我们必须要学习并掌握 grep 命令的原因。
此 Linux 命令 | 系列 文章将作为《#运维从业必学》专栏辅助学习知识,这是也是每位Linux运维工程师必须掌握的基础知识,作者耗费心力、时间进行总结,希望对大家有所帮助,所以若有帮助还请多多关注作者,并鼓励作者创造更多实践文章吧。
废话不多说,实践为王!
0x01 grep 命令 & egrep 命令
grep(Global search Rgular Expression and Print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用基础正则表达式(Base Regular Expression)搜索文本,根据用户指定的模式对目标稳步进行逐行匹配,并把匹配的行打印出来。
egrep(Extended Global search Rgular Expression and Print out the line)是 grep 命令的扩展版本,它支持扩展正则表达式(Extended Regular Expression)语法,等同于 grep -E 命令。
温馨提示:这里作者将 grep 命令 与 egrep 命令放在一起进行讲解,由于 egrep 其使用的语法及参数同于 grep 命令所以不分开进行讲解了,若有不同的地方后续作者也会标注出来!
语法参数
用法: grep [选项]... 模式 [文件]...
# 模式选择与解释:
-E, --extended-regexp <模式> 是扩展正则表达式 [常用]
-F, --fixed-strings <模式> 是字符串
-G, --basic-regexp <模式> 是基本正则表达式 [常用]
-P, --perl-regexp <模式> 是 Perl 正则表达式 [常用]
-e, --regexp=<模式> 用指定的<模式>字符串来进行匹配操作 [常用]
-f, --file=<文件> 从给定<文件>中取得<模式>
-i, --ignore-case 在模式和数据中忽略大小写 [常用]
--no-ignore-case 不要忽略大小写(默认)
-w, --word-regexp 强制<模式>仅完全匹配字词 [常用]
-x, --line-regexp 强制<模式>仅完全匹配整行
-z, --null-data 数据行以一个 0 字节结束,而非换行符
# 杂项:
-s, --no-messages 不显示错误信息
-v, --invert-match 选中不匹配的行,即反向匹配 [常用]
-V, --version 显示版本信息并退出
# 输出控制:
-m, --max-count=<次数> 得到给定<次数>次匹配后停止
-b, --byte-offset 输出的同时打印字节偏移
-n, --line-number 输出的同时打印行号 [常用]
--line-buffered 每行输出后刷新输出缓冲区
-H, --with-filename 为输出行打印文件名 [常用]
-h, --no-filename 输出时不显示文件名前缀
--label=<标签> 将给定<标签>作为标准输入文件名前缀
-o, --only-matching 只显示行中非空匹配部分 [常用]
-q, --quiet, --silent 不显示所有常规输出 [常用]
--binary-files=TYPE 设定二进制文件的 TYPE(类型);TYPE 可以是 'binary'、'text' 或 'without-match'
-a, --text 等同于 --binary-files=text
-I 等同于 --binary-files=without-match
-d, --directories=ACTION how to handle directories; ACTION is 'read', 'recurse', or 'skip'
-D, --devices=ACTION 如何处理设备、FIFO和socket;操作为“读取”或“跳过”
-r, --recursive like --directories=recurse [常用]
-R, --dereference-recursive 递归搜索目录,但不搜索符号链接
--include=GLOB 只查找匹配 GLOB 的文件 [常用]
--exclude=GLOB 跳过匹配 GLOB 的文件 [常用]
--exclude-from=FILE 跳过所有匹配给定文件内容中任意模式的文件 [常用]
--exclude-dir=GLOB 跳过所有匹配 GLOB 的目录 [常用]
-L, --files-without-match 仅打印没有选定行的文件名
-l, --files-with-matches 仅打印选定行的文件名
-c, --count 打印出匹配的行总分数 [常用]
-T, --initial-tab make tabs line up (if needed)
-Z, --null 在FILE名称后打印0字节
文件控制:
-B, --before-context=NUM 打印文本及其前面 NUM 行 [常用]
-A, --after-context=NUM 打印文本及其后面 NUM 行 [常用]
-C, --context=NUM 打印文本匹配的前后 NUM 行 [常用]
-NUM same as --context=NUM
--group-separator=SEP use SEP as a group separator
--no-group-separator use empty string as a group separator
--color[=WHEN],
--colour[=WHEN] 使用标记突出显示匹配的字符串参数 'always', 'never', or 'auto'
-U, --binary EOL时不删除CR字符(MSDOS/Windows)基础示例
# 示例文本
tee learn_grep.txt <<'EOF'
2024 Years, "Open Source" is a good mechanism to develop programs.
Welcome to learn Global search Rgular Expression and Print out the line!
Authors: Weiyigeek
Wechat:Weiyigeeker
Email:master@weiyigeek.top
博客:blog.weiyigeek.top
公众号: 全栈工程师修炼指南
Hello World, Grep & Egrep!
7b
100
EOF
# 1.字符串过滤匹配,返回指定文件中的匹配字符串的行
grep "weiyigeek" learn_grep.txt
# Email:master@weiyigeek.top
# 博客:blog.weiyigeek.top
# 2.忽略大小写查找内容,返回匹配的行
grep -i "weiyigeek" learn_grep.txt
# Authors: Weiyigeek
# Wechat:Weiyigeeker
# Email:master@weiyigeek.top
# 博客:blog.weiyigeek.top
# 3.返回不包含txt字符串的文件
ls | grep -v "txt"
# 4.静默输出不会输出任何信息,如果命令运行成功返回0,失败则返回非0值。一般用于条件测试。
grep -q "weiyigeek" learn_grep.txt
echo $? # 输出上次程序返回值
# 0 # 匹配成功返回 0
grep -q "not found" learn_grep.txt
echo $?
# 1 # 未匹配返回 1
# 5.统计文件或者文本中包含匹配字符串的行数,比使用`wc -l`命令更简洁
grep -c "weiyigeek" learn_grep.txt
# 2
# 6.输出包含匹配字符串的行数,及其匹配行内容。
grep -n "全栈工程师修炼指南" learn_grep.txt
# 7:公众号: 全栈工程师修炼指南
# 7.根据多个条件模式进行匹配, 并返回匹配行
grep -e "Authors" -e "公众号" learn_grep.txt
# Authors: Weiyigeek
# 公众号: 全栈工程师修炼指南
# 8.将匹配条件输出到文件中,匹配时根据文件中的内容进行匹配
grep -f match.txt learn_grep.txt
# Authors: Weiyigeek
# 公众号: 全栈工程师修炼指南
# 9.多文件中,或递归查询搜索匹配字符串
grep "match_pattern" file_1 file_2 file_3
grep "text" -n file_1 file_2
# 10.输出那个文件中成功匹配指定的字符串
grep -l "root" /etc/passwd /etc/shadow
# /etc/passwd
# /etc/shadow
# 11.递归查询匹配的字符串,及其文件名称。
grep -r "weiyigeek" /home/weiyigeek/
# ./learn_grep.txt:Email:master@weiyigeek.top
# ./learn_grep.txt:博客:blog.weiyigeek.top
# ./learn_regex.txt:Email:master@weiyigeek.top
# ./learn_regex.txt:博客:blog.weiyigeek.top
# 递归匹配,但不包含链接文件,其中.表示当前目录。
grep "string" -R -n .
# 12.匹配字符串的前后的N行和M行
grep -n -B 1 "公众号" learn_grep.txt # 前一行
# 6-博客:blog.weiyigeek.top
# 7:公众号: 全栈工程师修炼指南
grep -n -A 1 "公众号" learn_grep.txt # 后一行
# 7:公众号: 全栈工程师修炼指南
# 8-Hello World, Grep & Egrep!
grep -n -C 1 "公众号" learn_grep.txt # 前后各一行
# 6-博客:blog.weiyigeek.top
# 7:公众号: 全栈工程师修炼指南
# 8-Hello World, Grep & Egrep!
# 13.匹配一次后停止匹配,并返回匹配的行
grep -m 1 "weiyigeek" learn_grep.txt
# Email:master@weiyigeek.top
# 14.使用正则表达式匹配字符串,使用扩展正则表达式需要加-E参数
# 基本正则表达式
grep "[1-9]\+" learn_grep.txt
# 扩展正则表达式
grep -E "[1-9]+" learn_grep.txt
# 2024 Years, "Open Source" is a good mechanism to develop programs.
# 7b
# 100
# 15.打印样式匹配所位于的字符或字节偏移
echo "gun is not unix" | grep -b -o "not"
7:not
# 16.匹配出两个文件相同的内容的行
seq 1 6 > six.txt # 1 2 3 4 5 6
seq 5 8 > eight.txt # 5 6 7 8
grep -f eight.txt six.txt # 只有 5 和 6 重叠
5
6
# 或者
cat eight.txt six.txt | sort | uniq -d
5
6
实践示例
# 1.静默验证当前系统是否为Ubuntu、CentOS或Rocky Linux系统
grep -Eqi -e "Ubuntu|CentOS|Rocky" /etc/system-release
echo $?
# 静默验证当前bash是否为sh,不显示错误信息
ps -p $$ | grep -siq sh
echo $?
# 2.使用正则表达式匹配不带注释以及空白的行,不过为了兼容性建议都加上 -E 参数
grep -v "^#" /etc/ssh/sshd_config | grep -v "^$"
# 或者使用 -Ev 选项
grep -Ev "^$|#" /etc/ssh/sshd_config
grep -Ev "^($|#)" /etc/ssh/sshd_config
Include /etc/ssh/sshd_config.d/*.conf
Port 22
PermitRootLogin yes
AuthorizedKeysFile .ssh/authorized_keys
PrintLastLog no
Subsystem sftp /usr/libexec/openssh/sftp-server
# 3.使用递归搜索的方式,按照文件类型搜索,或者按照文件里的文件名进程排除匹配
# 只在目录中所有的.php和.html文件中递归搜索字符"main()"
grep "main()" . -r --include *.{php,html}
# 在搜索结果中排除所有README文件
grep "main()" . -r --exclude "README"
# 在搜索结果中排除filelist文件列表里的文件
grep "main()" . -r --exclude-from filelist.txt
# 4.使用0值字节后缀,并批量删除匹配到的文件
# 测试文件:
echo "aaa" > f1.txt
echo "bbb" > f2.txt
echo "aaa" > f3.txt # f1 和 f3 内容相同
grep "aaa" f* -Z
# file1aaa
# file3aaa
grep -lZ "aaa" f*
# f1.txtf3.txt
# 命令解释:执行后会删除f1和f3,grep 输出用-Z选项来指定以0值字节作为终结符文件名(\0),xargs -0 读取输入并用0值字节终结符分隔文件名,然后删除匹配文件,-Z通常和-l结合使用。
grep -lZ "aaa" f* | xargs -0 rm
# 5.打印出匹配文本之前或者之后的行,使用 seq 命令生成10个数字。
# 使用 -A 显示匹配某个结果之后的行,
seq 10 | grep "5" -A 3 -n
# 5:5
# 6-6
# 7-7
# 8-8
# #显示匹配某个结果之前的2行,使用 -B 选项:
seq 10 | grep "5" -B 2 -n
# 3-3
# 4-4
# 5:5
# 显示匹配某个结果的前1行和后1行,使用 -C 选项:
seq 10 | grep "5" -C 1 -n
# 4-4
# 5:5
# 6-6
# 显示 以 Cached 打头所在行的下三行
grep -E -A 3 "^Cached" /proc/meminfo
# Cached: 396196 kB
# SwapCached: 0 kB
# Active: 218416 kB
# Inactive: 447312 kB
grep -E -A 3 "^Cached" meminfo #显示后三行
# SwapCached: 0 kB
# Active: 163624 kB
# Inactive: 319796 kB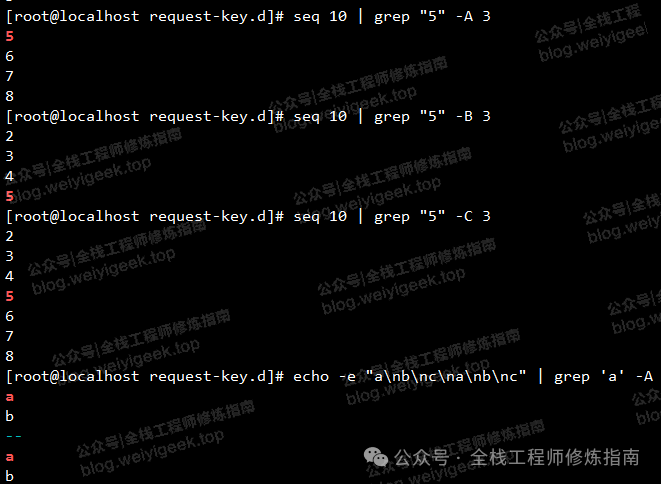
正则表达式匹配示例
# 示例1.grep采用perl正则表达式元字符(环视功能)需指定参数-P
# 当后接字符串可以匹配出则显示,否则不显示
echo "WeiyiWeiyiGeek Whoami" | grep -oP "Weiyi(?=WeiyiGeek)"
# 当前置字符串可以匹配出则显示,否则不显示
echo "WeiyiGeek Whoami" | grep -oP "(?=WeiyiGeek)Weiyi"
# Weiyi
# 示例2.只输出匹配的perl正则元字符字符串
grep -Po '(?<=^ID=")\w+' /etc/os-release
rocky # ID="rocky"
# 示例3.查询某一时刻前一分钟其后的100行
grep -A 100 "$(date -d '-1 minute' '+%Y-%m-%d %H:%M')" studentcenter.log
# 示例4.统计那些人已经看了网页
cd /app/logs/StudentCenter && grep -E "21500140770323|21500113771228" info.2021-04-18.0.log | grep "yxmc=" | grep -oE "ksh=\d{14}" | sort | uniq -c
# 示例5.使用正则表达式递归匹配目录各文件中的url
grep -ohr -E "https?://[a-zA-Z0-9\.\/_&=@$%?~#-]*" ./folder
# 示例6.使用正则表达式匹配文件中的url,排除.docx, .pdf, .jpg, .gif文件
grep -oE '(https|http|ftp)?://[a-zA-Z0-9\.\/_&=@$%?~#-]*' demo.txt | grep -vE ".docx$|.pdf$|.jpg$|.gif$" | sort | uniq
# 示例7.递归查询某一目录下不存在指定字符串的文件
grep -R -L "pageid:" . | grep -E "md$"
# 示例8.匹配一个或者多个中文汉字匹配,参数-P支持perl正则匹配字符
grep -o -P '[\p{Han}]{0,}' weiyigeek.top.log
# 示例9.只显示指定条件匹配到的字符串,参数-P支持perl正则匹配字符
grep -o -P 'ksh=[0-9]{14}, xm=[\p{Han}]{0,3}, sfzh=[0-9xX]{18}' /tmp/weiyigeek.logs
# ksh=23500111132484, xm=张某, sfzh=500106300602113826
# 示例10.对象Java项目Spring中日志打印出字符串进行匹配,并
grep -w -oP "^\[2023-01-[0-9]{0,2} [0-9]{0,2}:[0-9]{0,2}:[0-9]{0,2}.[0-9]{0,3}\]|ksh=[0-9]{14}, xm=[\p{Han}]{0,}, sfzh=[0-9xX]{18}" /tmp/weiyigeek.logs | sed ':a;N;$!ba;s/]\n/] /g'
# [2023-01-29 21:43:56.485] ksh=23500111132484, xm=张某, sfzh=500102200402103222
# 示例11.按照指定字符串进行排序后显示
grep "cj=" result.txt | grep -o -P '^\[2023-03-[0-9]{0,2} [0-9]{0,2}:[0-9]{0,2}:[0-9]{0,2}.[0-9]{0,3}\]|ksh=[0-9]{14}, xm=[\p{Han}]{0,3}' | sed ':a;N;$!ba;s/]\n/] /g' | sort -t "]" -k 2
# 示例12.统计 18:05~18:10 时间段里面指定字符串的行数输出匹配的字符串(进行了过滤)
cd /app/logs/StudentCenter && egrep "18:(05|06|07|08|09|10)" info.2021-03-12.0.log | grep "cjxmc=总分" | egrep -o "sfzh=[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]" | sort -u | wc -l
# 合计: 2815+2736+2585+2639+2640+2574
# 示例13.egrep 命令扩展表达式使用示例
$ egrep -n 'goo*d' regular_express.txt #{0,N}
$ egrep -n 'go+d' regular_express.txt #{1,N}
$ egrep -n 'go?d' regular_express.txt #{0,1}
$ egrep -n 'g(la|oo)d' regular_express.txt # 搜寻(glad)或 good 这两个字符串
$ echo'AxyzxyzxyzxyzC'|egrep 'A(xyz)+C'
$ echo'AxyzxyzxyzxyzC'|egrep 'A(xz)+C'
# 示例14.egrep 命令忽略大小写匹配
egrep -i '^(From|Subject|Date): ' email.txt
# 示例15.egrep 命令扩展表达式与管道符结合,计算文本中所有数字的和
cat number.txt
c=1024
b=256
c=128
egrep -o '[0-9]+' number.txt | paste -s -d + | bc
1408
# 示例16.egrep 命令扩展表达式与指定正则匹配的文件联用,匹配主机中的所有IP地址
tee match_ip_regex.txt <<EOF
([0-9]{1,3}\.){3}[0-9]{1,3}
EOF
ifconfig | egrep -of match_ip_regex.txt
# 192.168.228.128
# 255.255.255.0
# 192.168.228.255
# 127.0.0.1
# 255.0.0.0
# 示例17.统计当前主机中IP地址TCP连接数
ss -nt | egrep "^ESTAB" | tr -s ' ' : | cut -d ':' -f6 | sort | uniq -c | sort -nr
4 192.168.228.1
1 10.100.100.5
# 示例18.统计当前主机中各链接状态,使用 -v 排除标题行。
ss -nta | egrep -v '^State' | cut -d " " -f1 | sort | uniq -c
1 FIN_WAIT2
4 ESTABLISHED
3 CLOSE_WAIT
# 示例19.输出系统中磁盘使用率最高的最高值
df | grep '^/dev/' | grep -oE '[0-9]{,3}%' | grep -oE '[0-9]+' | sort -nr
27
4
2
1
df | grep '^/dev/' | grep -oE '[0-9]{,3}%' | grep -oE '[0-9]+' | sort -nr | head -n1
27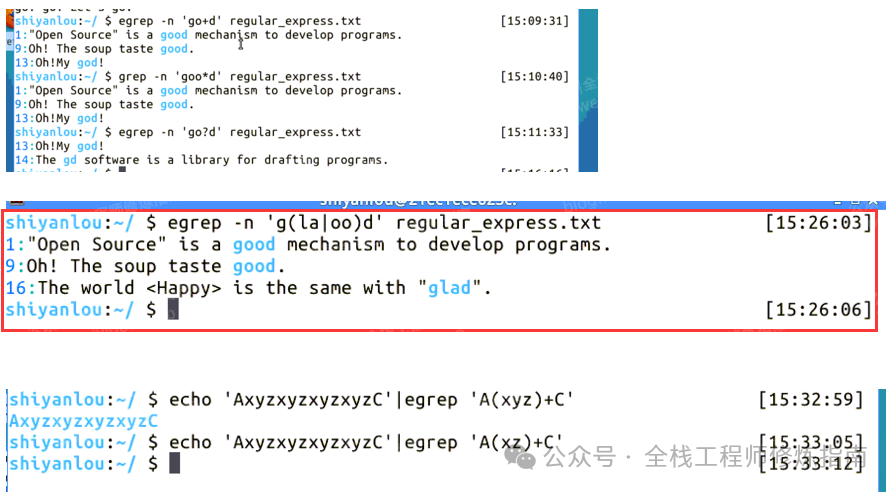
问题.find命令与grep命令的区别
find 在系统中搜索的条件的文件名, 如需要匹配,使用
通配符匹配是完全匹配。grep 在文件中搜索符号的字符串, 如需匹配,则使用
正则表达式是包含匹配。
若文章写得不错,不要吝惜手中转发,点赞、在看,若有疑问的小伙伴,可在评论区留言你想法哟💬!
温馨提示:作者最近10年的工作学习笔记(涉及网络、安全、运维、开发),需要学习实践笔记的看友,可添加作者账号[WeiyiGeeker],当前价格¥199,除了获得从业笔记的同时还可进行问题答疑以及每月远程技术支持,希望大家多多支持,收获定大于付出!
如果此篇文章对你有帮助,请你将它转发给更多的人!
学习推荐 往期文章
🔥【最新】Linux 运维 | 6.从零开始,Shell编程中正则表达式 RegExp 速成指南
🔥【最新】Github 星标 62K: 微软出品,面向初学者的生成式 AI 学习课程!
💡【相关】Linux 运维 | 5.从零开始,编辑器之神 vi/vim 速成指南
💡【相关】Linux 命令 | 每日一学,文本处理之内容统计比较实践

