AAMAS 24 | 基于深度强化学习的多智能体和自适应框架用于动态组合风险管理
AAMAS 24 | 基于深度强化学习的多智能体和自适应框架用于动态组合风险管理
原创 QuantML QuantML 2024年09月09日 18:23 上海
J.P.Morgan的python教程
Content

本文提出了一个名为MASA的多智能体和自适应框架,利用深度强化学习技术,通过两个合作的智能体(一个基于TD3算法的RL智能体和一个基于约束求解器的智能体)以及一个市场观察者智能体,动态平衡投资组合的总体回报和潜在风险。实证结果表明,MASA框架在处理过去10年CSI 300、道琼斯工业平均指数和标普500指数数据集时,相较于其他已知的RL方法,展现出了显著的优势。
1. 引言
计算金融(CF)是一个活跃的研究领域,它涉及使用计算方法来解决金融中的各种挑战性问题。近年来,研究人员开始探索机器学习方法,包括支持向量机、深度学习和强化学习在金融领域的应用,特别是在投资组合管理方面。由于金融市场的不可预测性和多变性,传统的投资策略可能无法有效应对市场变化,因此需要新的计算方法来设计能够快速适应市场变化的投资策略。本文开发一个多智能体和自适应框架(MASA),以解决动态投资组合风险管理问题MASA框架的核心是利用深度强化学习来协调多个智能体的行为,以实现在不断变化的市场环境中优化投资组合的回报和风险平衡。
2. 预备知识
2.1 强化学习
强化学习是智能体在环境中通过试错来学习最优行为策略的过程。在金融领域,强化学习特别适用于需要实时决策的场景,如动态调整交易策略。本节定义了强化学习中的关键概念,包括状态、动作、奖励和策略。状态是对环境的描述,动作是智能体在特定状态下可以采取的行为,奖励是智能体在执行动作后从环境中获得的反馈,策略则是智能体根据当前状态选择动作的规则。
部分可观察马尔可夫决策过程(POMDP)是描述强化学习问题的一个数学框架。在POMDP中,智能体只能观察到环境的部分信息,这增加了决策的复杂性。强化学习算法,如TD3算法,通过迭代学习过程来优化策略,以最大化长期累积奖励。TD3算法适用于具有连续动作空间的动态环境,使其成为解决金融市场中投资组合优化问题的理想选择。
2.2 多智能体系统
多智能体系统(MAS)涉及多个智能体的协调和合作。在金融领域,MAS可以用来模拟市场中的多个参与者,如投资者、交易员和监管机构。这些智能体可能有着不同的目标和策略,他们的互动会影响市场的整体动态。
MAS在金融模拟中的应用包括市场动态的模拟、策略评估和风险管理。通过模拟不同的市场情景,研究人员可以更好地理解市场行为,预测市场变化,并设计出更有效的投资策略。此外,MAS也为研究市场异常现象提供了一个有力的工具。
在多智能体环境中,智能体需要具备学习和适应的能力,以便在不断变化的市场条件下做出最优决策。这要求智能体能够处理复杂的信息,如价格波动、交易量和其他市场指标,并能够根据这些信息调整自己的行为。
2.3 计算金融中的投资组合优化
投资组合优化是计算金融中的一个关键问题,它涉及到如何在不同的资产之间分配资金,以最大化回报并最小化风险。本节首先介绍了投资组合优化的基本概念,包括投资组合价值、资产权重和预期回报。
投资组合风险的度量包括短期和长期风险。短期风险通常与市场波动性相关,而长期风险则与资产价格的长期趋势有关。为了量化这些风险,本节介绍了一些常用的风险度量方法,如方差、标准差和夏普比率。
夏普比率是一个特别重要的指标,它衡量了投资组合每承担一单位总风险所产生的超额回报。一个高夏普比率的投资组合意味着在相同风险水平下可以获得更高的回报,或者在相同回报水平下承担更低的风险。
投资组合优化中的挑战包括市场不确定性、资产相关性和交易成本。这些因素都增加了投资组合优化问题的复杂性,使得传统的优化方法可能无法提供满意的解决方案。因此,需要采用更先进的方法,如机器学习和强化学习,来解决这些问题。
3. 提出的多智能体和自适应框架
作者提出了一个名为MASA的多智能体和自适应框架,旨在解决动态投资组合风险管理中的挑战。该框架通过两个合作的智能体——基于强化学习的RL智能体和基于求解器的智能体——来实现一个新的多智能体强化学习方案。RL智能体负责优化当前投资组合的整体回报,而求解器智能体则负责进一步调整投资组合以最小化潜在风险。此外,MASA框架还集成了一个灵活的市场观察者智能体,它提供对市场趋势的估计,作为对多智能体强化学习方法的有价值的反馈,以便快速适应不断变化的市场条件。
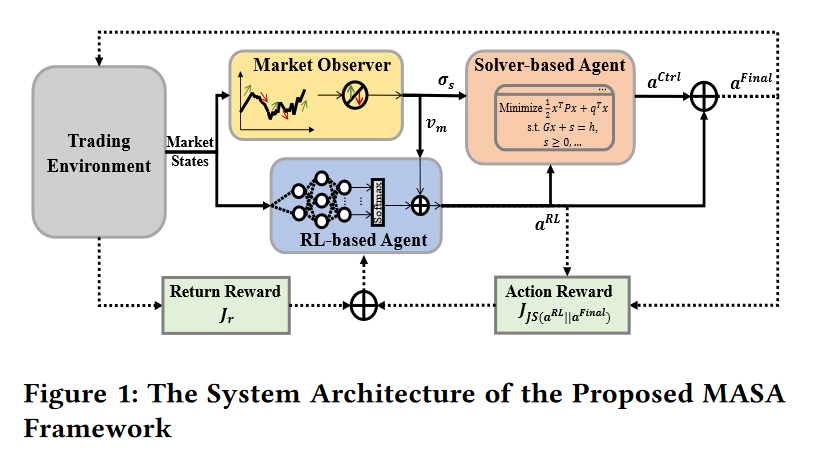
MASA框架采用了松耦合和流水线计算模型,使得即使某个智能体失败,整体框架仍能继续工作,从而提高了系统的鲁棒性和可靠性。市场观察者智能体作为深度神经网络,如多层感知器(MLP)模型,可以扩展MASA框架,使其成为动态投资组合管理的多智能体深度强化学习方法。
MASA框架的训练过程包括初始化RL策略、市场观察者智能体和记忆元组,然后通过迭代训练过程,收集当前市场状态信息,计算先前执行动作的回报,并根据市场观察者智能体提供的市场条件信息更新RL和求解器智能体。通过这种自适应的奖励机制和智能引导策略,MASA框架能够在面对高度动荡的金融市场环境时,动态平衡投资组合的整体回报和潜在风险。

4. 实证评估
评估过程中,MASA框架的原型使用Python实现,并在配备AMD Ryzen 9 3900X 12-Core处理器和两块Nvidia RTX 3090 GPU的GPU服务器上进行测试。测试使用了2013年9月至2023年8月期间的CSI 300、道琼斯工业平均指数(DJIA)和标准普尔500指数(S&P 500)的数据集,其中前五年的数据用于模型训练,随后两年的数据用于模型验证,最后三年的数据用于评估验证后的模型性能。
在性能评估中,MASA框架与其他十种基于算法或强化学习的方法进行了比较。这些方法包括恒定再平衡投资组合(CRP)、指数梯度(EG)、在线移动平均回归(OLMAR)、被动攻击性均值回归(PAMR)、鲁棒中位数回归(RMR)、基于相关性的非参数学习策略(CORN)以及四种最新的基于强化学习的组合优化方法。评估使用了年化回报(AR)、最大回撤(MDD)、夏普比率(SR)和短期投资组合风险(Risk)等四个常用的性能指标。
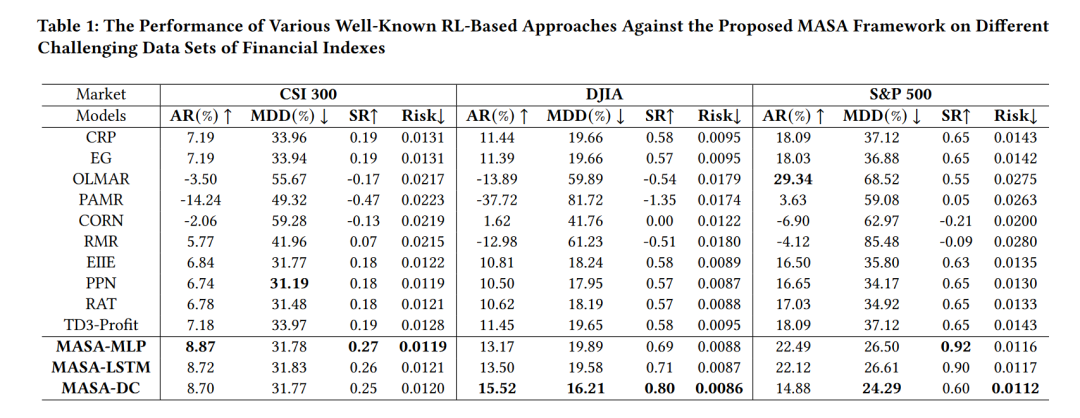
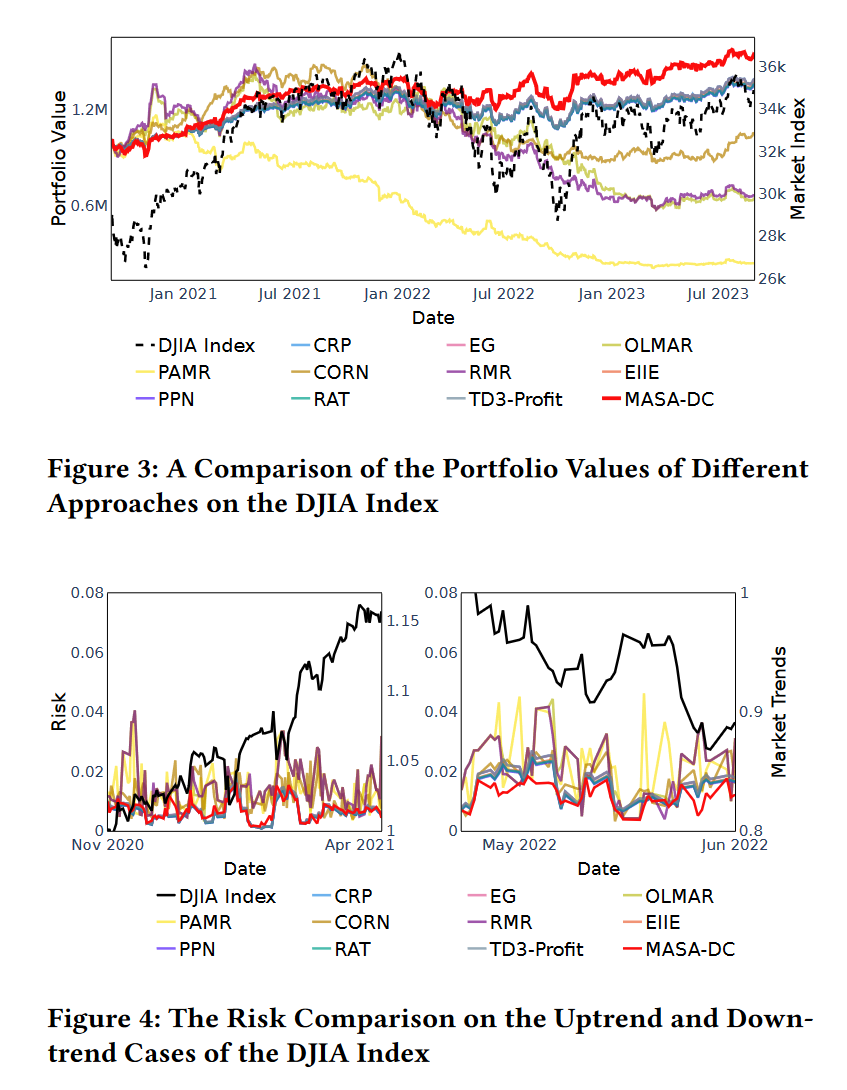
评估结果显示,MASA框架在CSI 300、DJIA和S&P 500指数的数据集上均优于其他方法。具体来说,MASA框架在CSI 300数据集上实现了至少比其他方法高1.5%的年化回报,同时保持了相对较低的投资组合风险。在DJIA指数上,使用基于方向变化的市场观察者代理的MASA-DC方法在所有指标上均优于其他基线模型。在S&P 500数据集上,MASA框架同样在平衡回报和潜在风险方面表现最佳,实现了约0.9的夏普比率和26%的最大回撤。
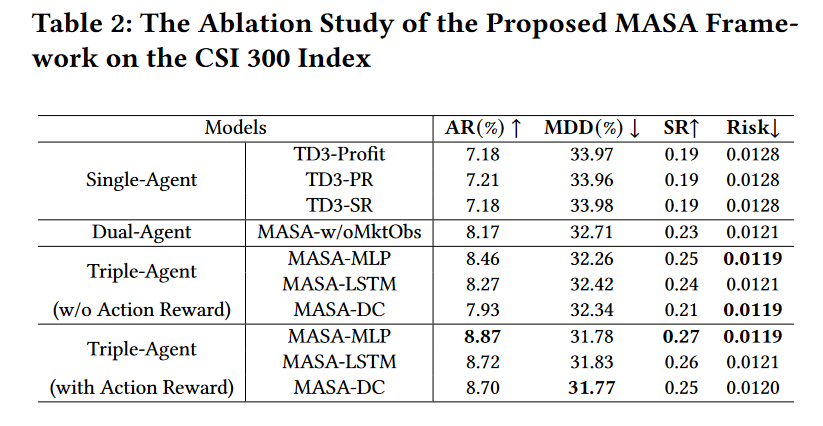
此外,为了进一步验证MASA框架的有效性,还进行了消融研究。消融研究比较了基于TD3的不同模型变体与MASA框架的三个变体。结果显示,MASA框架在没有市场观察者智能体提供额外市场信息的情况下,仍然能够有效地减少投资风险。当考虑到市场观察者智能体提供的市场信息后,MASA框架能够更好地估计潜在风险,同时追求更高的回报,从而在风险和回报之间实现了更好的平衡。
5. 结论
本文总结了MASA框架在处理高度动荡金融市场环境中的投资组合管理问题方面的显著性能,并指出了未来研究的可能方向,包括探索不同的基于元启发式的优化器作为求解器智能体、尝试各种智能方法作为市场观察者智能体,以及将MASA模型应用于资源分配、规划或灾难恢复等风险管理至关重要的领域。