PAI 大语言模型评测平台现已支持裁判员模型评测
在大模型时代,随着模型效果的显著提升,模型评测的重要性日益凸显。为了有效评价大语言模型(LLM),业界提供了多种基准测试,例如 MMLU、CMMLU,GSM8K 等。但是,这些基准测试更多是针对确定性问题及确定性表述,评测 LLM 在开放场景下的能力(例如聊天助手)仍然是个挑战性问题。
为此,业界提出使用能力更强的 LLM 作为裁判来评估其他 LLM 在开放性问题上的表现,用来弥补各种基准测试以及基于规则的测试的不足,同时也可作为一种接近人类偏好的评价指标。阿里云 PAI 模型评测平台也提供了裁判员模型评测的能力,该能力由审明师(Themis)裁判员提供。Themis 基于 Qwen 系列模型并结合大规模评测数据集微调训练得到,在开源的 Alighbench 等数据集上表现与 GPT-4 持平,部分场景优于 GPT-4 的评测效果。本文将为您介绍如何在 PAI 大语言模型评测平台,基于裁判员模型,评价开源模型或者微调后模型的性能。该功能限时免费,欢迎使用。
PAI 大语言模型评测平台简介
科学、高效的模型评测,不仅能帮助开发者有效地衡量和对比不同模型的性能,更能指导他们进行精准地模型选择和优化,加速 AI 创新和应用落地。为此,PAI 上线了大语言模型评测平台,建立一套平台化的大模型评测最佳实践。
PAI 模型评测功能支持从两个维度对大语言模型进行评测:基于自定义数据集和公开数据集评测。
基于自定义数据集的评测包括:
- 基于规则的评测,用 ROUGE 和 BLEU 系列指标计算模型预测结果和真实结果之间的差距;
- 基于裁判员模型的评测,基于 PAI 提供的裁判员模型,对问答对【问题-模型输出】逐条打分,并统计得分情况,用于评价模型性能;
基于公开数据集的评测是通过在多种公开数据集上加载并执行模型预测,根据每个数据集特定的评价框架,为您提供行业标准的评估参考。
Themis 模型简介

Themis 是一款专为提升大语言模型评估效率和准确性而设计的智能大模型解决方案,主要针对主观性问答对进行评测。用户调用服务后,首先将用户输入的问题进行场景划分,通过模型生成该问题的场景、场景描述和场景维度,例如:(场景)回答开放性问题。然后根据用户输入的问答和对应的场景通过 Prompt Engineering 生成完整的评估描述,然后请求裁判员模型获得对问答的评测结果。
在真实的较大规模数据集上,Themis 与直接使用 ChatGPT-4 做裁判员模型进行对比:从不同的场景上分析,在回答开放性问题、阅读理解与信息提取、创意文体写作、信息与专业写作、角色扮演上,效果和 ChatGPT-4 持平;在翻译、代码生成修改与分析、回答确定性问题、文本改写、回答数学类问题的效果评测上,Themis 仍有改进的空间。这部分场景在引入参考答案后,裁判员模型的评估精度也显著提升。
开发实战
数据准备
- 裁判员模型评测需要提供 JSONL 格式的评测集文件。
- 文件格式:每行是一个列表字典,使用 question 标识问题列,answer 标识参考答案列,也可以在评测页面选择指定列。answer 列选填。
[{"question": "在守望先锋中,碰到外挂该怎么办?", "answer": "如果在游戏中遇到使用作弊工具或外挂的玩家,你可以使用内置的举报系统来报告可疑行为。这一般通过在游戏结束后的玩家列表中点击嫌疑人的名字,然后选择适当的举报选项来完成"}]
[{"question": "你觉得幸福是什么?", "answer": "幸福是一种主观的感觉,它通常与快乐、满足和生活中的意义感相关。对不同的人来说,幸福可能意味着不同的事情。对有些人来说,幸福可能与物质财富、社会地位和成就感息息相关,而对其他人来说,幸福可能更多地与人际关系的密切程度、心灵的平和与健康或个人的精神满足感有关>"}]- 【可选】上传符合格式的评测集文件至 OSS,并创建评测数据集,详情请参见:上传文件到 oss 和创建数据集。
- 也可直接在评测任务页面上传评测集文件并使用。

提交裁判员模型评测任务
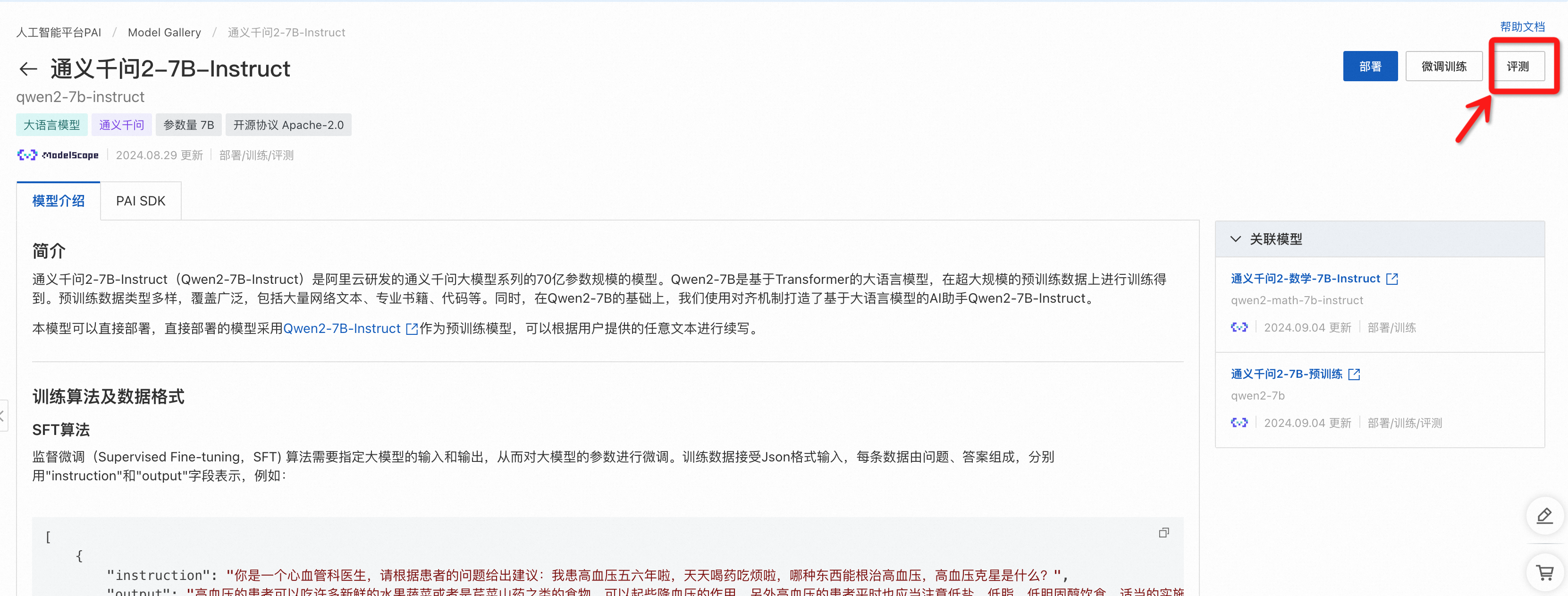
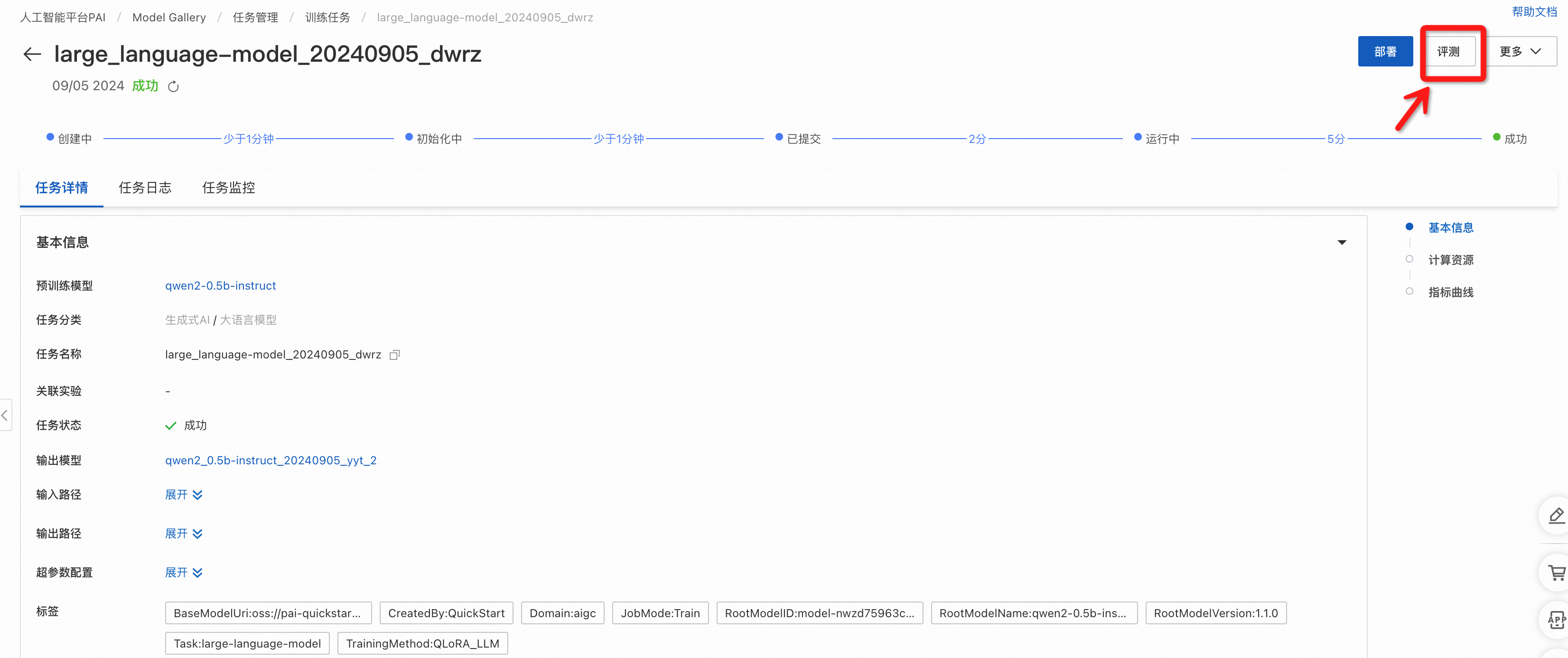
开发者可通过两个入口进入模型评测页面:
1. PAI 控制台的 Model Gallary->LLM 模型卡片->评测按钮
2. 微调任务详情页->评测按钮
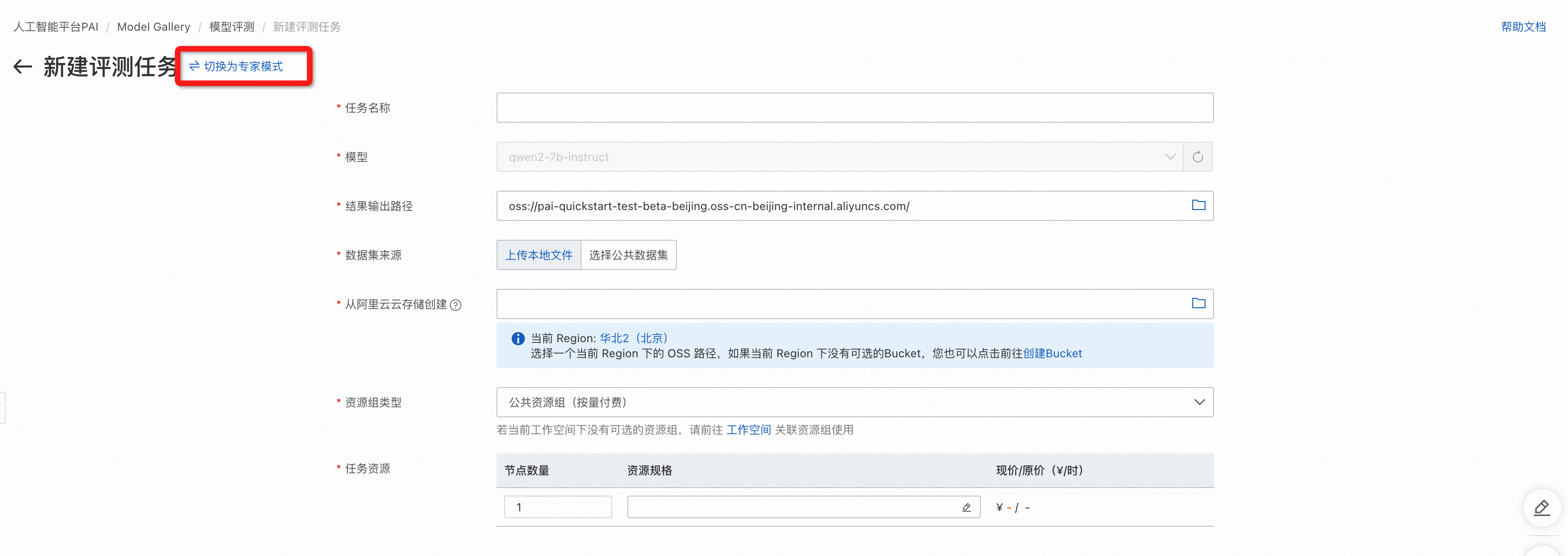
进入模型评测页面后,左上角切换到专家模式:
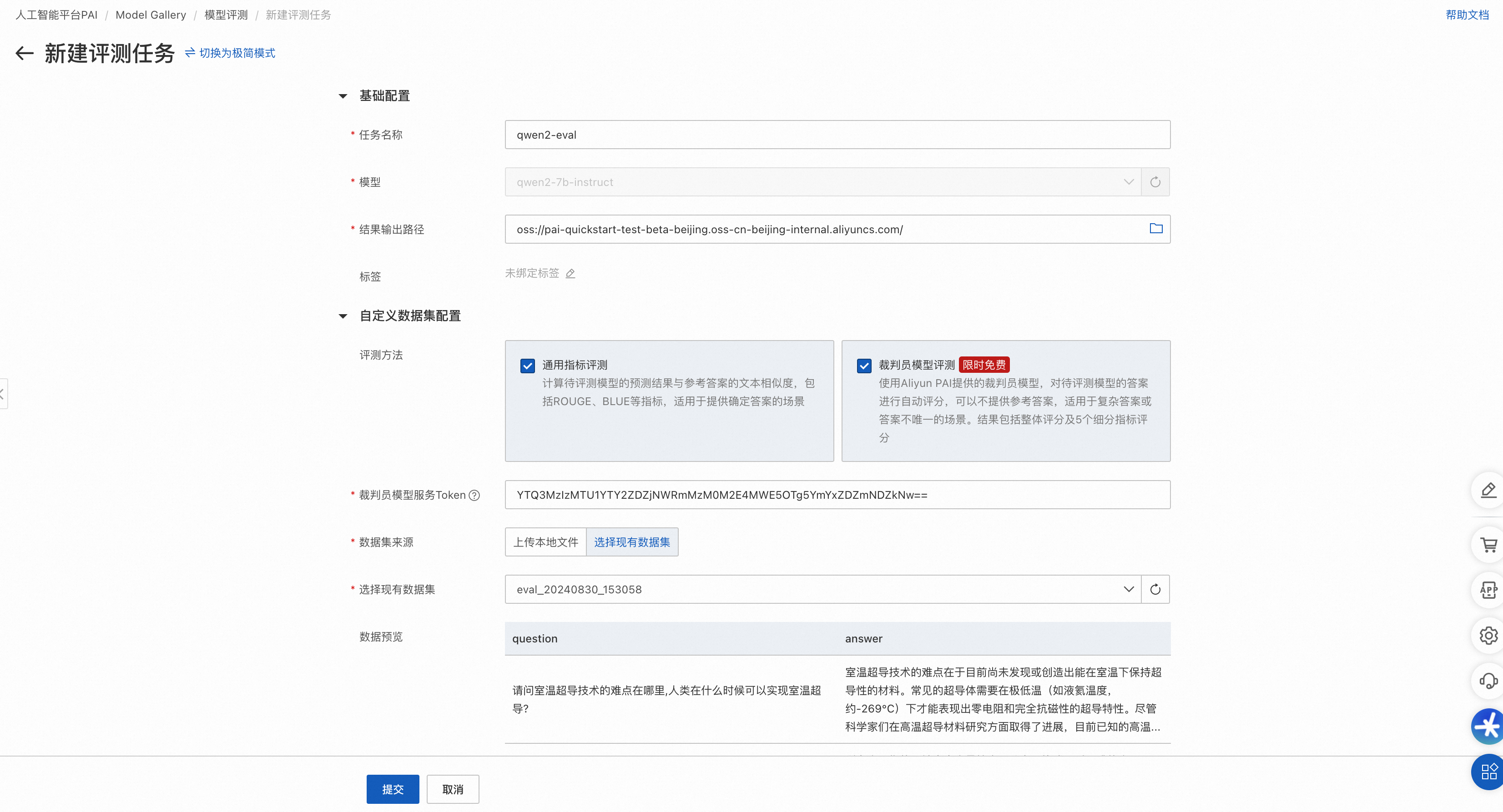
按照页面介绍填写任务信息后提交任务:
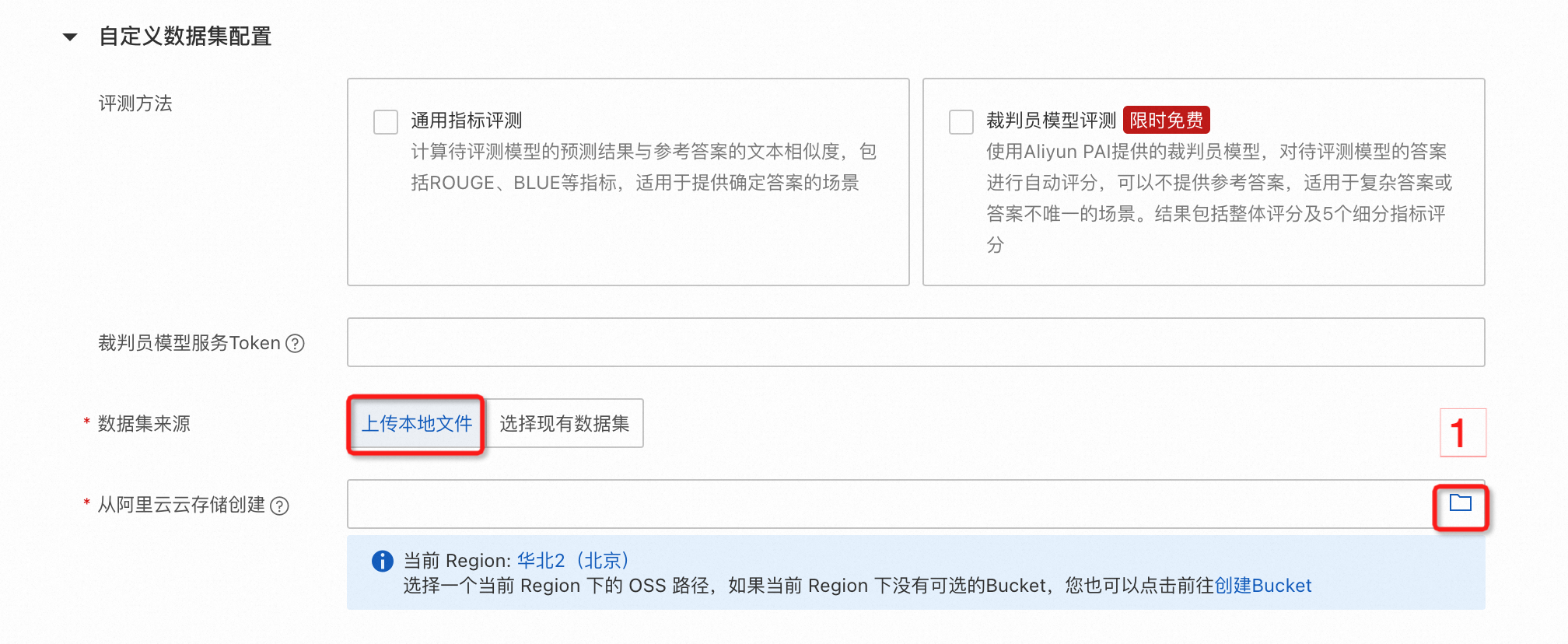
1. 填写任务基本配置;
2. 自定义数据集配置选项中选中裁判员模型评测选项,并同意开通裁判员模型服务【限时免费】,此时会自动获取对应的裁判员模型服务 token;

3. 选择或上传自定义数据集;
4. 选择任务资源,如果资源组类型为公共资源组时,默认会根据您的模型规格推荐相应资源;
5. 配置推理超参数;
评测结果分析
单任务结果查看
任务完成后查看评测结果。评测指标如下图所示:
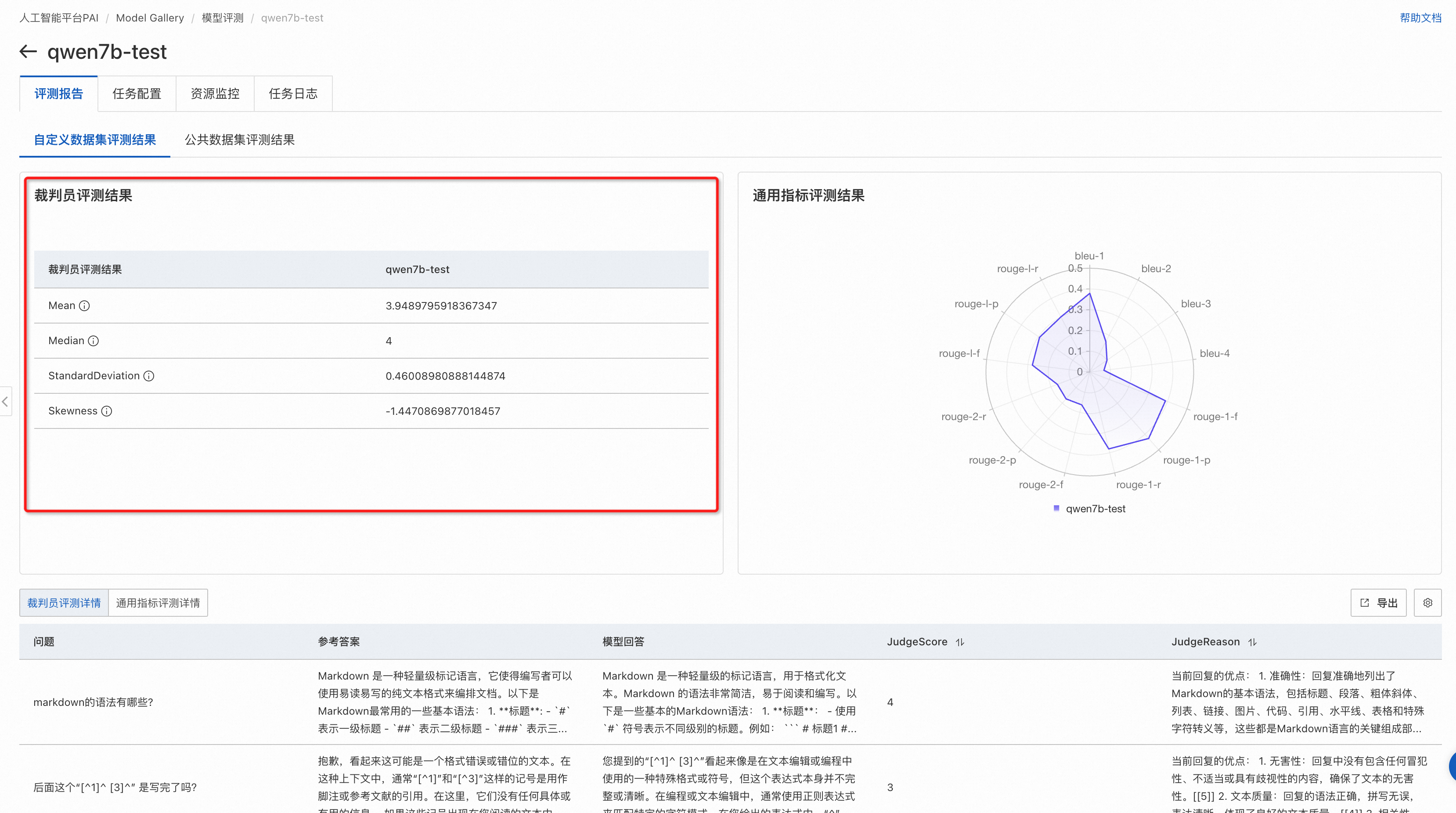
- Mean,表示裁判员大模型对模型生成结果打分的平均值(不含无效打分),最低值1,最大值5,越大表示模型回答越好。
- Median,表示裁判员大模型对模型生成结果打分的中位数(不含无效打分),最低值1,最大值5,越大表示模型回答越好。
- StandardDeviation,表示裁判员大模型对模型生成结果打分的标准差(不含无效打分),在均值和中位数相同情况下,标准差越小,模型越好。
- Skewness,表示裁判员大模型打分结果的分布偏度(不含无效打分),正偏度表示分布右侧(高分段)有较长尾部;负偏度则表示左侧(低分段)有较长尾部。
此外还会在页面底部展示评测文件每条数据的评测详情,包含了完整的评分理由。
多任务对比
在 Model Gallary -> 任务管理 -> 模型评测页面中选中要对比的模型评测任务,右上角单击对比,可以查看对比结果:

模型评测平台支持面向企业开发者的自定义数据集评测和面向算法研究人员的公开数据集评测。完整介绍详见:模型评测产品文档。
Themis 模型 API 调用
可通过魔搭在线体验 Themis:https://modelscope.cn/studios/PAI/PAI-Themis
Themis 模型也支持直接通过 HTTP 调用,调用示例如下:
$ curl -X POST http://ai-service.ce8cc13b6421545749e7b4605f3d02607.cn-hangzhou.alicontainer.com/v1/chat/completions \
-H "Authorization: Bearer ${THEMIS_TOKEN}" -H "Content-Type: application/json" \
-d '{"model":"themis-turbo","messages":[{"role":"user","content":[{"mode":"single","type":"json","json":{"question":"9.9和9.11哪个大?","answer":"首先,我们需要比较两个数字9.9和9.11。9.9的整数部分是9。9.11的整数部分也是9。由于整数部分相同,我们需要比较小数部分。9.9的小数部分是0.9。9.11的小数部分是0.11。比较小数部分,0.9大于0.11。因此,9.11比9.9大。"}}]}],"temperature":0.2}'返回结果:
我认为该回复的综合评分为[[1]],理由如下。
当前回复的优点:
1. 文本连贯性:回复在结构上是连贯的,逐步比较了两个数字的整数部分和小数部分,使得解释过程易于理解。[[3]]
当前回复的不足:
1. 准确性:回复的结论是错误的。正确的比较应该是9.9比9.11大,这是因为9.9和9.11的整数部分都相同,小数部分9.9的0.9大于9.11的0.11。这是一个重大的准确性问题。[[1]]
2. 相关性:虽然回复试图通过比较数字的整数部分和小数部分来解决问题,但由于结论错误,这导致回复的相关性受到影响。[[1]]
3. 指令遵守度:回复没有正确遵循指令要求,给出了错误的比较结果。[[1]]
4. 用户体验:由于回复的错误,可能会导致用户混淆或误解,影响用户体验。[[1]]
5. 上下文理解:回复显示出对数字比较的基本理解,但由于结论错误,表明对复杂上下文的理解不足。[[1]]
6. 简洁性:尽管回复在表达上相对简洁,但由于结论错误,这一点无法弥补其他缺陷。[[2]]
7. 创造性:此项不完全适用于当前任务,因为任务主要关注于比较两个数字的大小,而不是创造性输出。[[N/A]]
综上所述,虽然回复在文本连贯性方面做得还可以,但由于准确性问题非常严重,导致其他方面的评价也受到了影响。因此,综合评分为1。