DeepNet :Scaling Transformers to 1000 Layer
DeepNet :Scaling Transformers to 1000 Layer
- Introduction
- TL;DR for Practitioners
- Experiment
Introduction
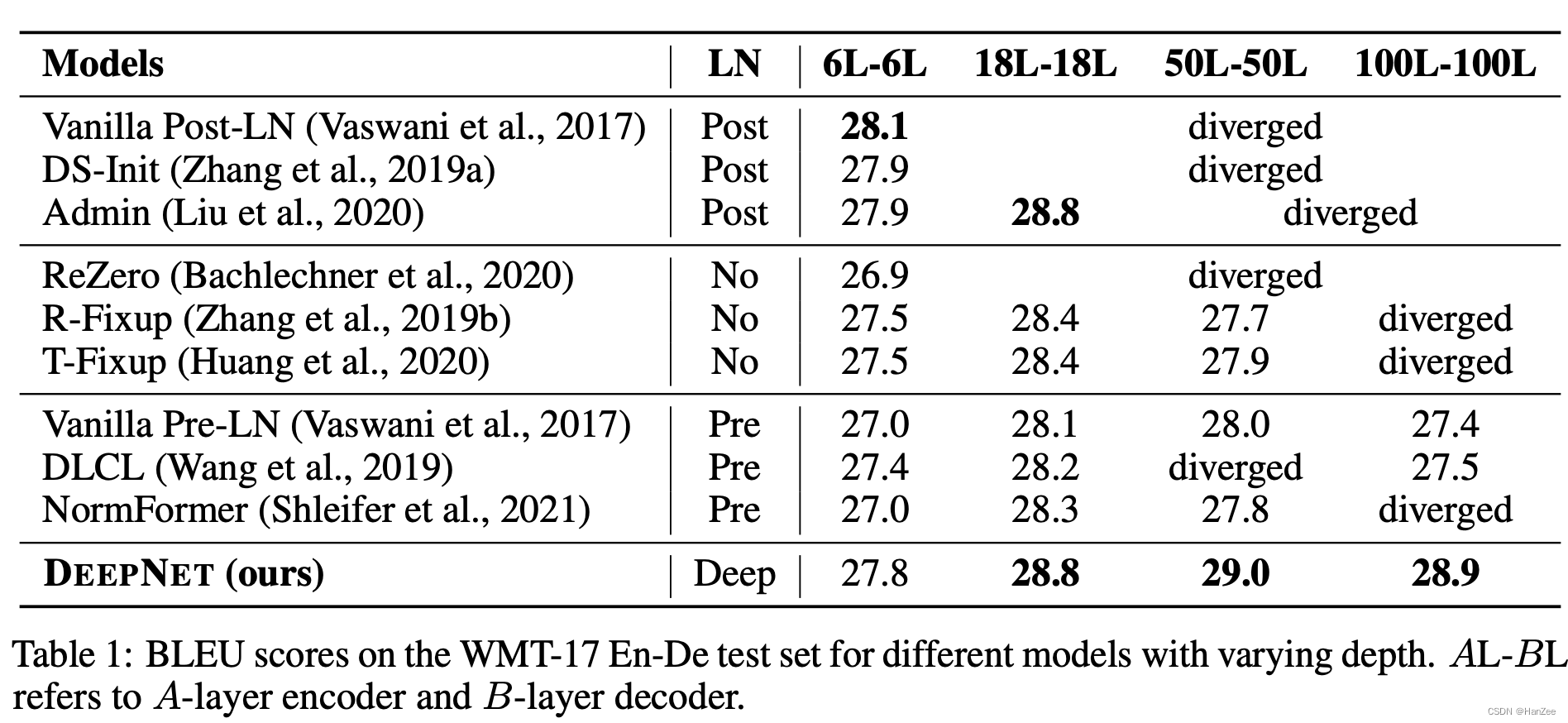
作者提出了一种简单且高效的方法稳定的提升了Transformer 的深度,这种方法是一种新的残差连接的方式(DeepNorm),它结合了以前的Post-LN的高表现与Pre-LN的稳定性的优点。通过这种方法作者把Transformer的层数提升了一个数量级。
作者还提到 200 层 3.2B的参数要outperform 48层12B的参数的模型 5个点。
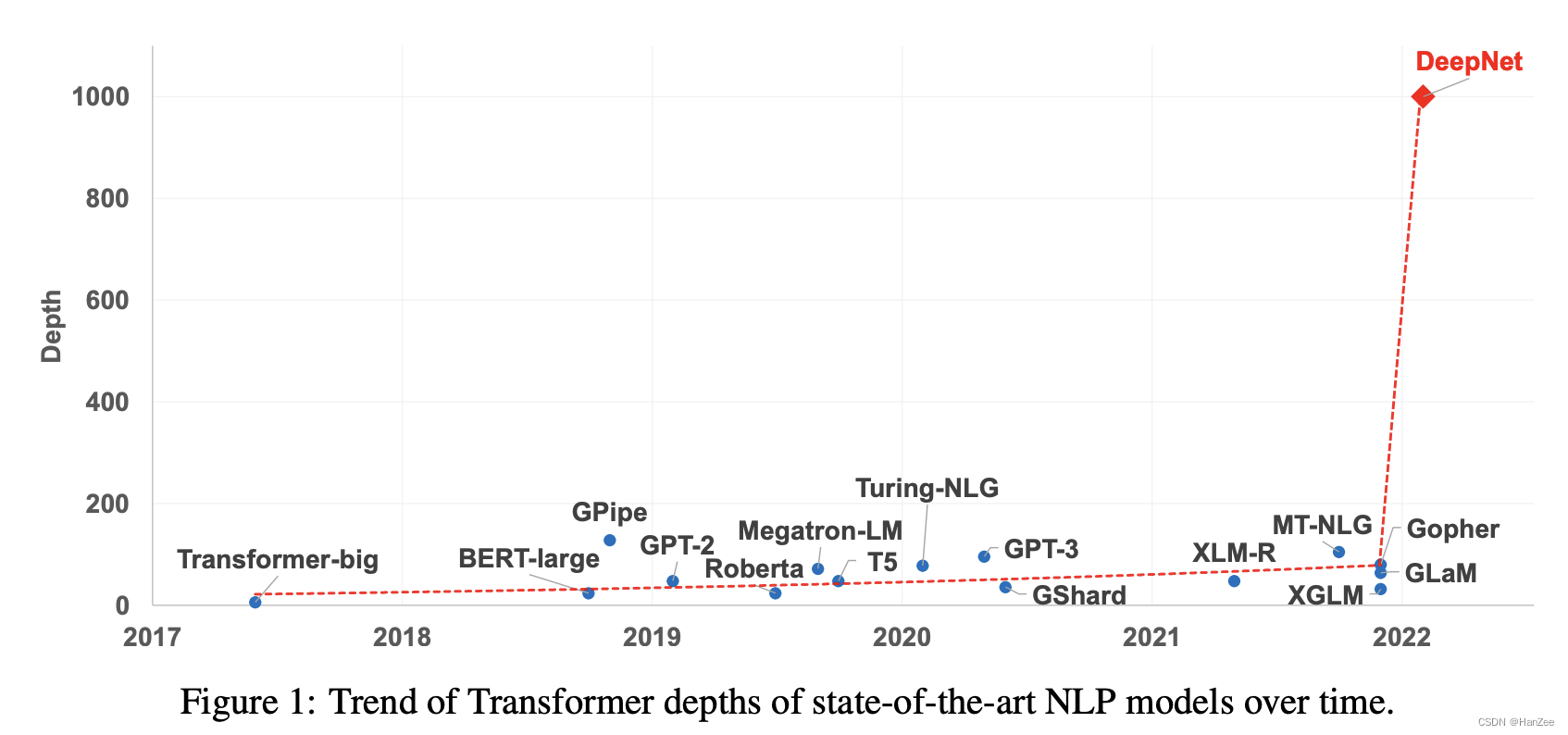
近年来大模型是一个趋势,参数量从million 到 billion 再到 trillions。尽管有着巨大的参数,但是他们的深度都被模型性训练不稳定所制约。
作者还提到大模型训练更深层次的网络不稳定的原因可能是exploding model update,本人理解为 大量的更新参数 可能会陷入局部最优。
TL;DR for Practitioners

上述图片为deepnorm的伪代码,其中以Post-LN为基础,给 x 加一个alpha权重,然后对ffn,v_projection, out_projection 与 q_projection 和k_projection分别采用不同的初始化方法,区别是gain参数,其中gain参数为一个可选的比例因子。
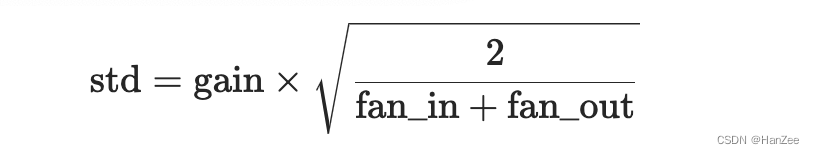
alpha 与beta的选择参考如下:
N-layer encoder, M-layer decoder

Experiment