DAPT: Distribution-Aware Prompt Tuning for Vision-Language Models

文章汇总
动机
该论文的动机很像下面这篇文章:
Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere
https://proceedings.mlr.press/v119/wang20k/wang20k.pdf
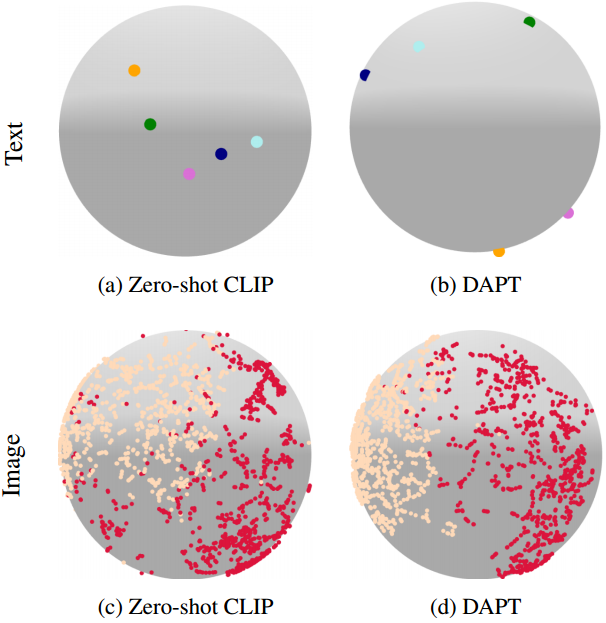
如(a)和(b)所示,zero-shot CLIP类标签的文本嵌入之间距离较小,并且图像特征聚类效果不佳。但是,使用DAPT进行提示调优可以在同一类中获得更均匀间隔的文本嵌入和更好的图像嵌入聚类。
解决办法
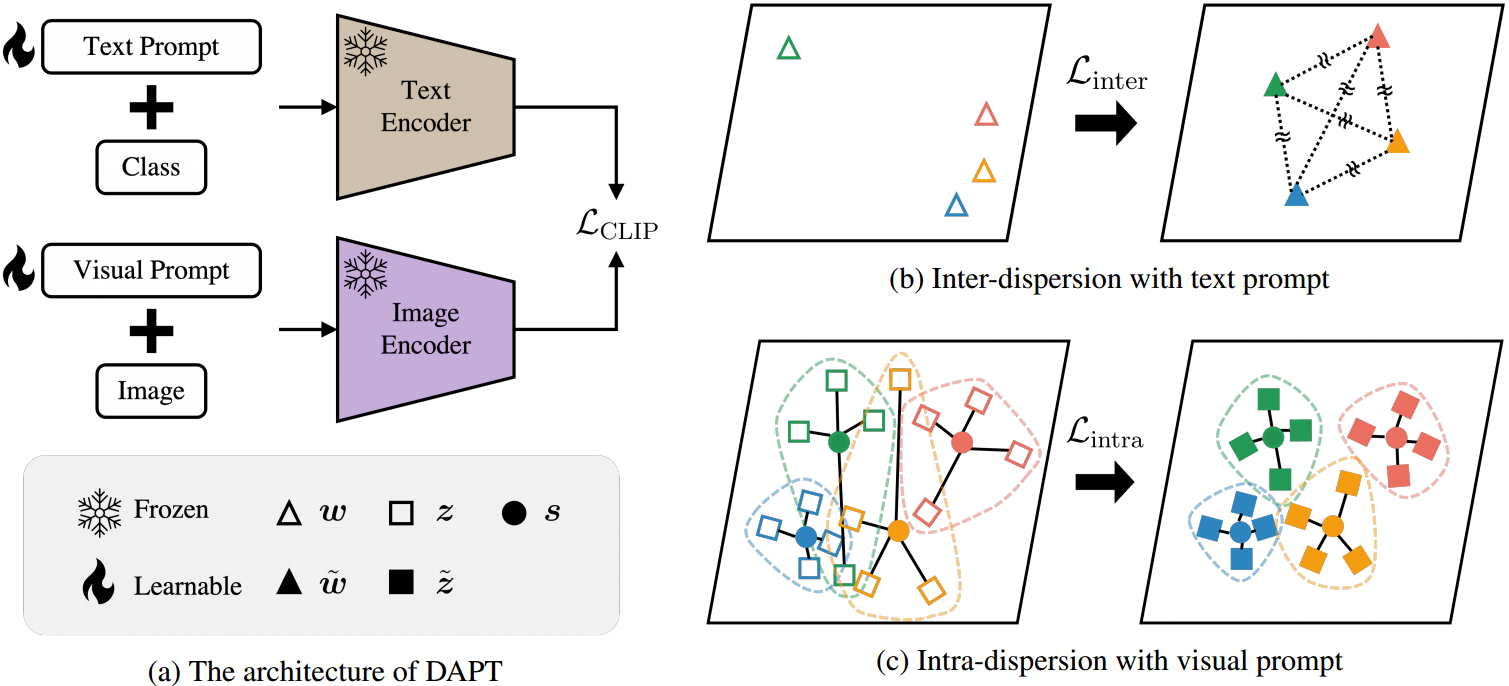
如动机那样,对应文本提示,我们能够更均匀地分布在一个空间中;对于视觉提示,我们通过每个类的质心使其同一个类别的图像特征更加聚拢在一起。
文本提示更均匀分布在同一个空间
均匀性是指特征嵌入在超球内的分布大致均匀。这样可以最大限度地减少嵌入之间的重叠,并实现更好的对齐。对于规范化文本嵌入 w ~ \tilde{w} w~,我们定义高斯势核 G G G如下:
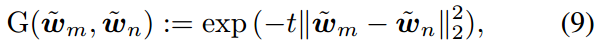
其中, m , n ∈ C , m ≠ n m,n\in C,m\ne n m,n∈C,m=n。
最小化上面的高斯势核 G G G增加了提示 p m p_m pm和 p n p_n pn在超球上的文本嵌入之间的距离。为了优化文本嵌入的均匀分布,我们将分散间损失定义如下:
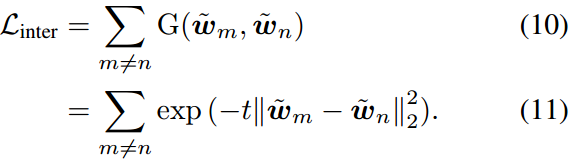
注意,本文中所有实验均设置超参数 t = 2 t = 2 t=2。
同一个类别的图像特征更加聚拢在一起
为了更好地对齐给定类 t c t_c tc的文本和图像嵌入,同一类的图像嵌入应该彼此接近。为了减少图像嵌入 z ~ i \tilde{z}_i z~i和 z ~ j \tilde{z}_j z~j的类内距离,我们用训练样本 D N = { ( x i , y i ) } i = 1 N \mathcal{D}_N=\{(x_i,y_i)\}^N_{i=1} DN={(xi,yi)}i=1N定义了由PROTONET[34]驱动的原型 s s s
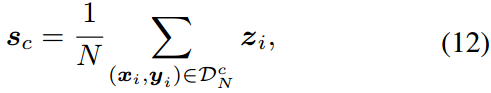
其中 z i = f ( x i ) z_i = f(x_i) zi=f(xi)注意 D N c = { ( x i , y i ) ∈ D N ∣ y i = c } \mathcal{D}^c_N=\{(x_i,y_i)\in \mathcal{D}_N|y_i=c\} DNc={(xi,yi)∈DN∣yi=c}, N N N为训练样本的个数。为了用相同的类聚类图像嵌入,我们假设每个嵌入都应该接近它的原型。因此,减小图像嵌入到原型 s s s之间距离的弥散内损失 L intra \mathcal{L}_{\text{intra}} Lintra定义为:
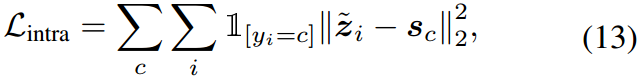
其中 c c c为输入图像 x i x_i xi对应的类索引。
总损失
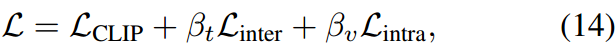
其中 β t \beta_t βt和 β v \beta_v βv是每个色散损失的超参数。
摘要
通过利用从大数据中学习到的知识,预训练的视觉语言模型(VLMs)在各种下游任务中表现出令人印象深刻的性能。通常,通过提示调优,可以进一步提高VLM在目标任务上的性能,这可以为输入图像或文本添加上下文。通过利用目标任务的数据,文献中研究了各种提示调优方法。提示调整的关键是通过固定模型参数的可学习向量在两个模态之间进行特征空间对齐。我们观察到,当每个模态的嵌入在潜在空间中“排列良好”时,对齐变得更加有效。受这一观察结果的启发,我们提出了用于视觉语言模型的分布感知提示调优(DAPT),该方法简单而有效。具体来说,提示是通过最大化内部分散,类之间的距离,以及最小化由同一类嵌入之间的距离测量的内部分散来学习的。我们在11个基准数据集上的大量实验表明,我们的方法显着提高了泛化性。代码可在https://github.com/mlvlab/DAPT上获得。
1. 介绍
近年来,预训练的视觉语言模型(VLMs)在计算机视觉的广泛应用中取得了巨大的成功,如图像分类[29,33]、目标检测[7,11,44]、字幕[21,24,42]和视觉问答(VQA)[9]。值得注意的是,VLM在各种下游任务中显示出了良好的泛化能力和可转移性。例如,CLIP[29]和ALIGN[15]等VLM在零样本和少样本学习方面表现出色。这些模型为零样本图像分类和零样本目标检测打开了大门。为了进一步提高预训练模型的零样本泛化能力,提示已被提出。例如,在图像分类中,CLIP[29]建议在类标签[class]前使用上下文文本“a photo of a”来获取目标类的文本嵌入。提示是一个新兴的研究课题,因为它比微调有几个优势,微调是利用预训练深度学习模型的传统方法。对于预训练的VLM,由于大量的模型参数,微调通常具有实际挑战性。由于目标域数据量少,对整个VLM进行微调往往会导致过拟合。Zhou等人[47]已经证明存在更强大的上下文字符串(硬提示)。然而,手动寻找更好的硬提示(提示工程)既耗时又不理想。因此,在此之后,一系列工作提出了优化软提示,可学习向量的提示调优[16,20,47]。在固定预训练的VLM模型参数的情况下,将可学习向量与其他输入连接并通过反向传播进行数值优化。
图1:(a)和(b)中的点表示来自OxfordPets的文本特征的标准化t-SNE嵌入[26]。此外,©和(d)上的点表示来自EuroSAT的图像特征的t-SNE嵌入[12]。如(a)和(b)所示,zero-shot CLIP类标签的文本嵌入之间距离较小,但其图像嵌入聚类效果不佳。但是,使用DAPT进行提示调优可以在同一类中获得更均匀间隔的文本嵌入和更好的图像嵌入聚类。
提示调整可以看作是文本和图像两个潜在空间之间的对齐。从图1可以看出,CLIP的每个潜在空间都不适合进行特征对齐。图1a中从原始CLIP中获得的目标类的文本嵌入聚集在附近,这可能导致对接近类的错误分类。此外,图1c中原始CLIP的视觉嵌入分布广泛,部分区域重叠。为了解决这个问题,我们提出了一种提示调优方法DAPT,它优化了每个模态的嵌入分布,以更好地实现特征对齐。
DAPT学习向量(即软提示)的文本和图像编码器与额外的损失项-间色散损失和内色散损失。具体来说,我们将互散损失应用于文本提示来传播文本嵌入。另一方面,将内部色散损失应用于视觉提示,以最大限度地减少同类图像嵌入的可变性。
为了验证DAPT的有效性,我们在不同的基准数据集上进行了少量学习和领域泛化任务的实验。对于每类一个样本(1-shot)到16个样本(16-shot)的少样本学习,本文提出的方法在11个基准数据集上进行了评估。在领域泛化方面,在ImageNet上进行少样本学习后,使用4个基准数据集[5]。总的来说,我们在最近的少样本学习和领域泛化的基线上取得了显著的进步。
综上所述,我们提出了DAPT,一种能够感知数据分布的提示调优方法,以提高VLM在少样本学习设置中的性能。与传统的提示调优方法不同,DAPT优化了文本和视觉提示,以便在每种模式中找到合适的分布。在第3节中,我们将讨论DAPT的细节,并在第4节中展示各种实验。
2. 相关工作
预训练的视觉语言模型。预训练的视觉语言模型(VLMs)[15,29,40,43]通过大规模噪声图像-文本配对数据集共同学习文本和图像嵌入。其中,CLIP[29]和ALIGN[15]通过对比学习优化正对之间的跨模态表示,并在各种下游任务中表现出令人印象深刻的性能[7,11,21,24,42,45]。此外,在后续的研究中也出现了通过调整潜在空间来提高VLMs能力的方法。例如,Wang等人[38]认为对齐和均匀性是需要优化的两个关键属性。通过扩展这些属性,Goel等人[10]提出了CyCLIP来缓解CLIP中的不一致预测,固定CLIP嵌入几何。
提示调优。提示在自然语言处理(NLP)中得到了广泛的研究。提出了Petroni等[28]、Shin等[32]、Jiang等[17]等提示调优方法来构建合适的提示模板。在自然语言处理的影响下,基于视觉语言模型的快速调优方法在计算机视觉领域得到了积极的研究。与CLIP[29]中提出的硬提示不同,一些研究通过优化文本或视觉形式的可学习向量来研究软提示。CoOp[47]通过文本编码器将提示连接与标签嵌入和可学习向量组合在一起。CoOp[46]是CoOp的高级版本,提高了不可见类的通用性。此外,VPT[16]和VP[1]建议对视觉形态进行及时调整。VPT在Vision Transformer中使用可学习向量进行提示调整[6]。与以往的工作不同,VP建议在CLIP图像编码器中进行图像像素级提示调整。这些快速调优方法在参数较少的情况下,具有显著的可移植性和通用性。最近,ProDA[22]和PLOT[3]使用多个提示符,表现出比单个文本提示符更好的性能。基于最近提示调优的成功,VLM中出现了多模态提示调优方法。UPT[41]联合优化具有额外层的模态不可知提示。MVLPT[31]侧重于多任务提示。MaPLe[18]通过多模态提示提高了VLM的泛化能力。
3. 方法
在本节中,我们将简要回顾3.1节中的CLIP[29]和几种提示调优方法[16,47]。然后,我们将在第3.2节中详细介绍一个分布感知的提示调优,DAPT。
3.1. Preliminaries
CLIP[29]是一种视觉语言模型,它通过对大量图像-文本对的对比学习进行训练。CLIP一般由图像编码器 f f f和文本编码器 g g g组成。给定图像 x x x和文本标签 t t t,则可以得到图像嵌入 z z z和文本嵌入 w w w:

注意,图像嵌入 z z z和文本嵌入 w w w是标准化的。给定 C C C个图像类,使用softmax计算预测概率,图像嵌入与对应文本嵌入的余弦相似度表示图像类为:
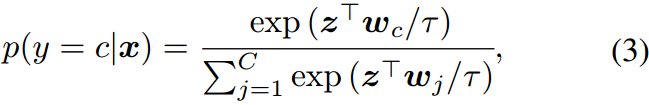
式中 τ \tau τ为温度参数, w c w_c wc表示类标签 t c t_c tc的文本嵌入。结合交叉熵,我们定义CLIP损耗 L CLIP \mathcal{L}_{\text{CLIP}} LCLIP如下:
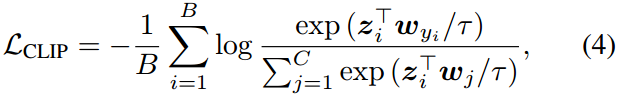
式中, y i y_i yi为第 i i i张图像 x x x的类, B B B为图像-文本对的批。
文本提示。CoOp[47]是第一个在CLIP的文本编码器中应用提示调优的方法。在CoOp中,文本提示符 p p p被表示为可学习向量 v v v与类的组合。那么,文本编码器的输入为:
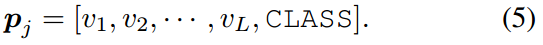
带有软提示的文本编码器的输出表示为:

注意, w ~ \tilde{w} w~是归一化的。CoOp根据数据集使用不同的长度 L L L和位置配置。它们可以被视为用于提示调优的超参数。在我们的方法中,我们固定了所有设置的超参数。文本提示符的可学习向量放置在CLASS前面,长度为 L = 16 L = 16 L=16。
视觉提示。在计算机视觉领域,VPT[16]提出了一种视觉变压器(vision transformer, ViT)的视觉提示调谐方法[6]。与CoOp类似,VPT在图像编码器的类令牌CLS和图像补丁嵌入 E E E之间插入可学习向量 u u u。由于CLIP[29]使用ViT骨干作为图像编码器,我们将CLIP中的视觉提示定义如下:
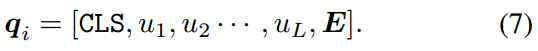
我们将视觉提示的可学习向量长度设为 L = 16 L = 16 L=16,与式(5)中的文本提示相同。由式(7)可得到视觉提示符 q i q_i qi为的输出图像嵌入 a ~ \tilde{a} a~:

注意 z ~ \tilde{z} z~是归一化的。
提示调优。当使用提示对CLIP进行微调时,图像编码器和文本编码器通常会冻结所有层的权重。因此,只优化了提示符。对于大规模的预训练模型,提示调谐通常比传统的微调方法(如线性探测和所有层的全微调)更有效和高效。
3.2. 分布感知提示调优
我们提出了DAPT,通过优化嵌入的分布,通过分散间和分散内损失来改善文本和视觉模式之间的特征对齐。所提出的方法的整体流程如图2所示,分散间和分散内损失如何优化文本和视觉潜在空间分别如图2b和2c所示。
图2:DAPT的总体架构。(a) DAPT由CLIP[29]体系结构与CoOp[47]和VPT[16]相结合组成。符号表示文本和视觉输出嵌入(即 w w w和 z z z),文本和视觉输出结合提示(即 w ~ \tilde{w} w~和 w ~ \tilde{w} w~),原型 s s s。按照提示调整方式,在训练过程中,文本和图像编码器被冻结,只更新提示。(b)将高斯势核 G G G定义的弥散间损失Linter应用于文本提示,扩大每个文本嵌入之间的距离 w ~ \tilde{w} w~,避免嵌入崩溃。©为了聚合同一类内的图像嵌入,我们通过计算zero-shot CLIP图像嵌入 z z z的平均值来定义每个类的具有代表性的图像嵌入的原型 s s s,然后将intra-dispersion loss Lintra应用于视觉提示,收集原型 s s s周围的图像嵌入。
文本提示的分散损耗。文本(标签)嵌入之间的小距离可能导致错误分类,并使视觉特征难以对齐。为了解决这个问题,我们在Wang等人[38]启发的均匀性基础上引入了文本嵌入中的分散损失。均匀性是指特征嵌入在超球内的分布大致均匀。这样可以最大限度地减少嵌入之间的重叠,并实现更好的对齐。对于规范化文本嵌入 w ~ \tilde{w} w~,我们定义高斯势核 G G G如下:
其中, m , n ∈ C , m ≠ n m,n\in C,m\ne n m,n∈C,m=n。
最小化上面的高斯势核 G G G增加了提示 p m p_m pm和 p n p_n pn在超球上的文本嵌入之间的距离。为了优化文本嵌入的均匀分布,我们将分散间损失定义如下:
注意,本文中所有实验均设置超参数 t = 2 t = 2 t=2。
视觉提示的内分散损失。给定一个类,与唯一定义的文本(标签)嵌入不同,潜在空间中存在多个视觉嵌入。具体来说,由于数据集中每个类有多个图像,因此从图像编码器获得各种图像嵌入。
为了更好地对齐给定类 t c t_c tc的文本和图像嵌入,同一类的图像嵌入应该彼此接近。为了减少图像嵌入 z ~ i \tilde{z}_i z~i和 z ~ j \tilde{z}_j z~j的类内距离,我们用训练样本 D N = { ( x i , y i ) } i = 1 N \mathcal{D}_N=\{(x_i,y_i)\}^N_{i=1} DN={(xi,yi)}i=1N定义了由PROTONET[34]驱动的原型 s s s
其中 z i = f ( x i ) z_i = f(x_i) zi=f(xi)注意 D N c = { ( x i , y i ) ∈ D N ∣ y i = c } \mathcal{D}^c_N=\{(x_i,y_i)\in \mathcal{D}_N|y_i=c\} DNc={(xi,yi)∈DN∣yi=c}, N N N为训练样本的个数。为了用相同的类聚类图像嵌入,我们假设每个嵌入都应该接近它的原型。因此,减小图像嵌入到原型s之间距离的弥散内损失 L intra \mathcal{L}_{\text{intra}} Lintra定义为:
其中 c c c为输入图像 x i x_i xi对应的类索引。
优化。结合(4)中的CLIP损失,(11)和(13)中的离散损失,DAPT通过最小化以下总损失来优化(5)中的文本提示 p p p和(7)中的视觉提示 q q q:
其中 β t \beta_t βt和 β v \beta_v βv是每个色散损失的超参数。

算法1总结了DAPT如何通过最小化(14)中提出的损失来优化关于每种模态在潜在空间中的分布的文本和视觉提示。综上所述,在训练过程中,文本提示符 w ~ \tilde{w} w~和视觉提示符 z ~ \tilde{z} z~通过分散间损失、分散内损失和CLIP损失组成的组合损失进行优化。
4. 实验
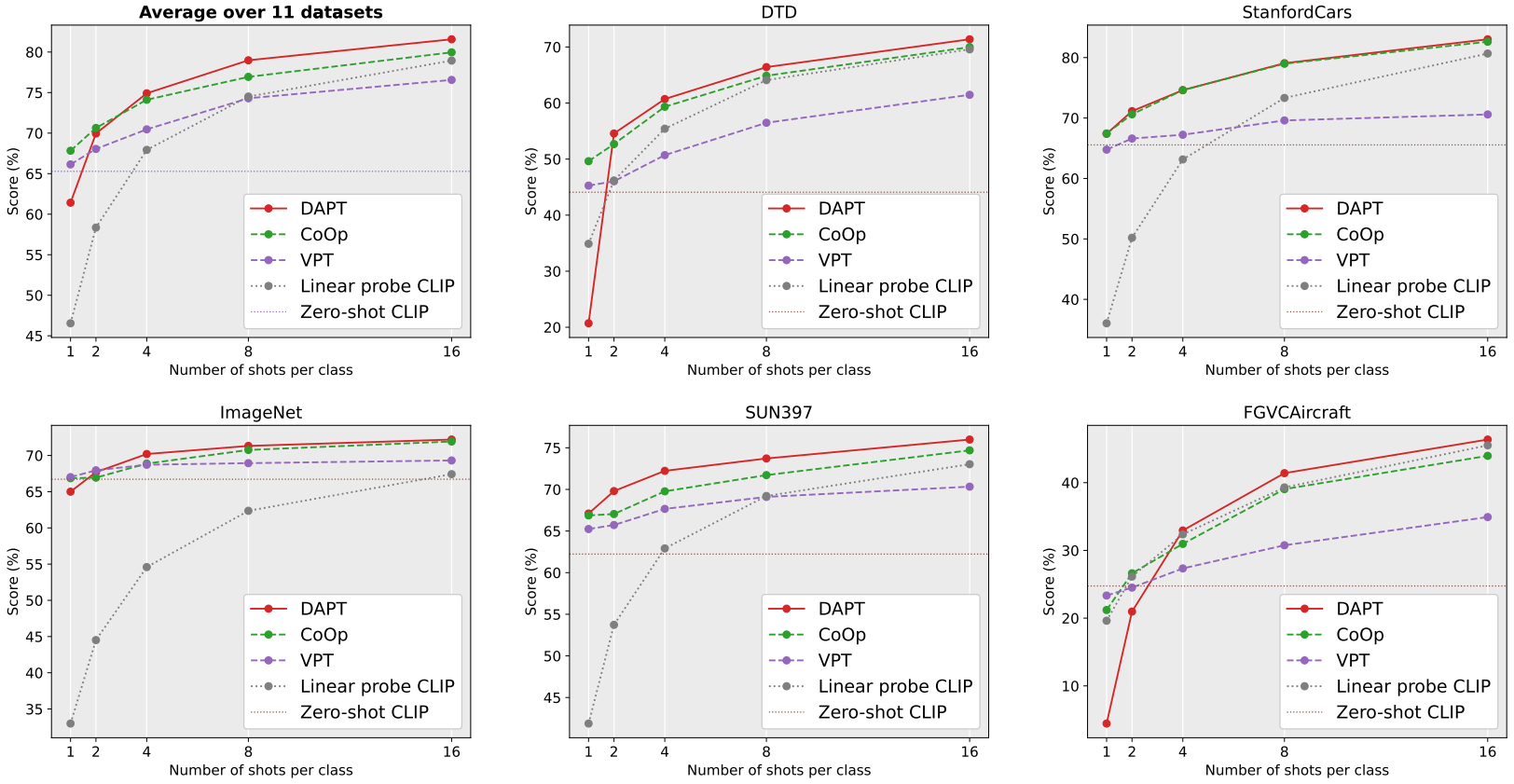
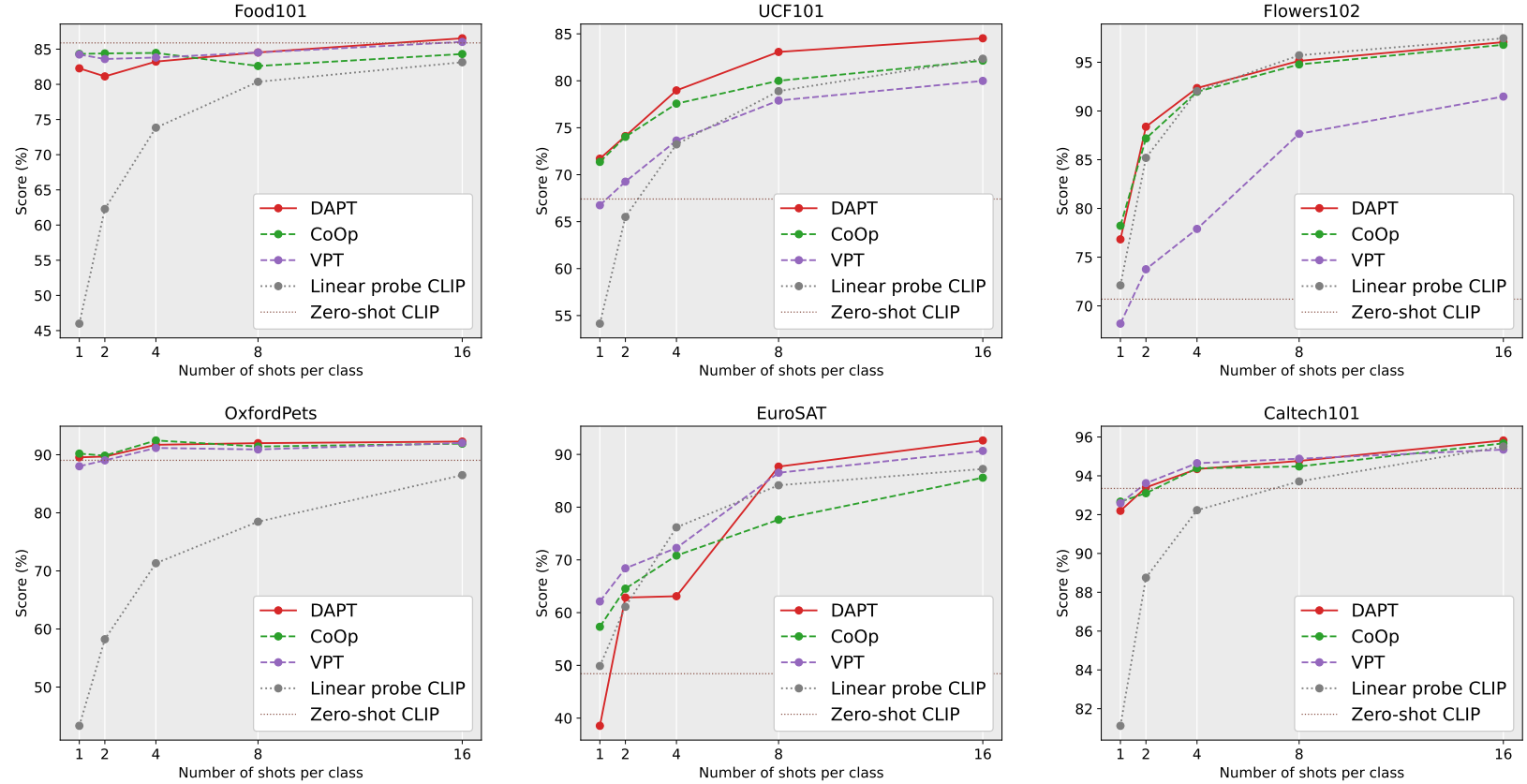
图4:11个数据集上图像分类的少样本学习。
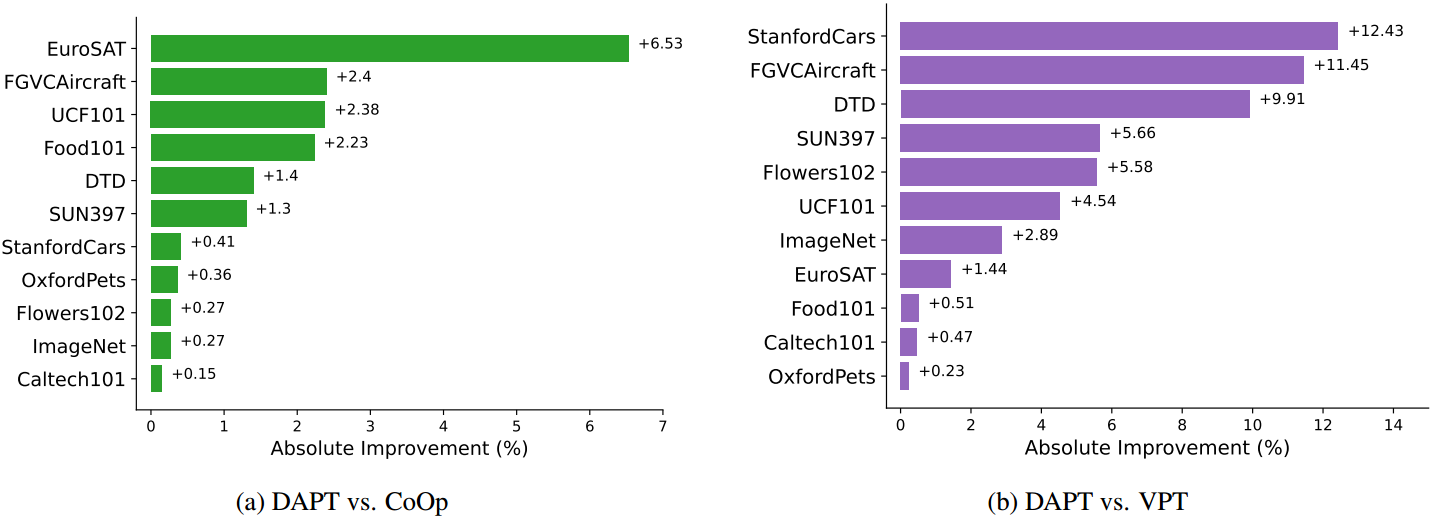
图5:与CoOp和VPT的比较。我们展示了每个数据集使用16个训练数据样本的图像分类结果。与CoOp[47]和VPT[16]相比,我们的方法有全面的改进。
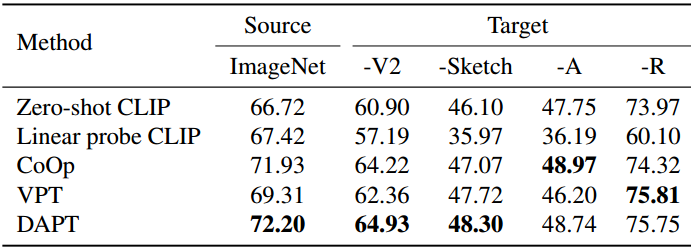
表3:域概化比较。
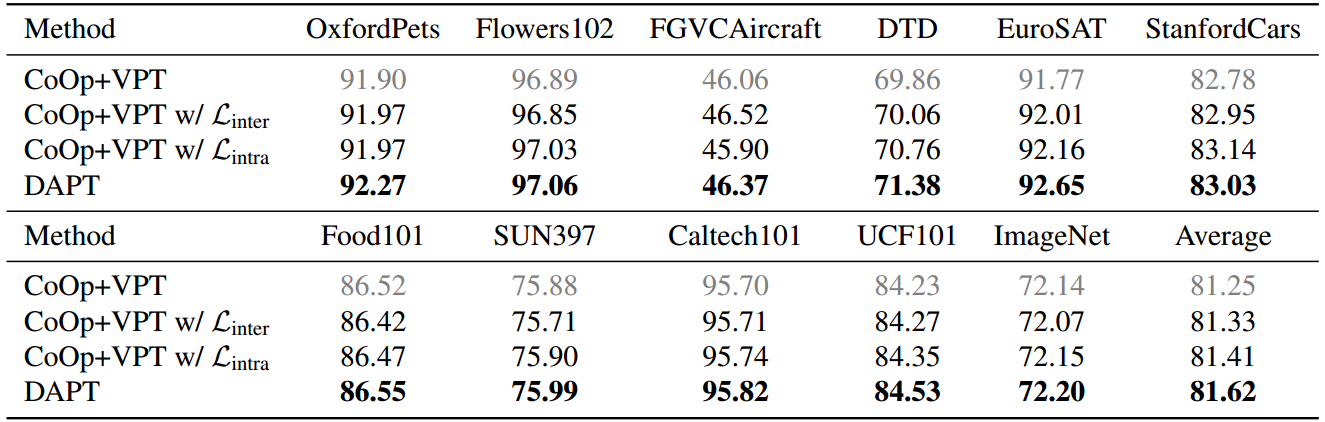
表5:消融研究。我们将DAPT与基线(即CoOp [47]+VPT[16])在11个基准数据集上进行比较。我们通过一个接一个地添加损失来观察大多数数据集的性能提高。

图6:图像嵌入的可视化。我们通过tSNE可视化Flowers102和UCF101的图像嵌入。与zero-shot CLIP相比,我们的DAPT更紧凑地对每个类的图像嵌入进行聚类。
5. 局限性与结论
针对预训练的视觉语言模型(VLM),提出了一种分布感知的提示调优方法DAPT。通过考虑嵌入的分布来进行提示调谐,该方法显著提高了性能,这在文献中尚未得到充分的研究同时保持现有提示调优方法的优点。在本文中,我们提出了适当优化VLM的文本和视觉潜在空间的弥散间损失和弥散内损失,使我们能够在下游任务中仅使用提示而无需额外层实现更高的性能。尽管所提出的方法显著提高了整体性能,但在极端少样本设置(如1-shot和2-shot)下优化提示仍然具有挑战性。最后,将其应用于图像分类以外的各种下游应用将是一个有趣的未来方向。
参考资料
论文下载(ICCV 2023)
https://arxiv.org/abs/2309.03406

代码地址
https://github.com/mlvlab/DAPT