Waymo的EMMA给多模态端到端自驾指引了方向
最近Waymo发的论文EMMA端到端确实在自动驾驶届引发了很大的关注,核心的原因是它采用的端到端模型是基于Gemini Nano的语言模型,目前看现在做端到端方案的,就它和特斯拉是语言模型为底座来实现多模态视觉输入的。
EMMA:End-to-End Multimodal Model for Autonomous Driving
端到端多模态自动驾驶的意思,不是艾玛电动车

论文地址:2410.23262
先看看他是怎么做的
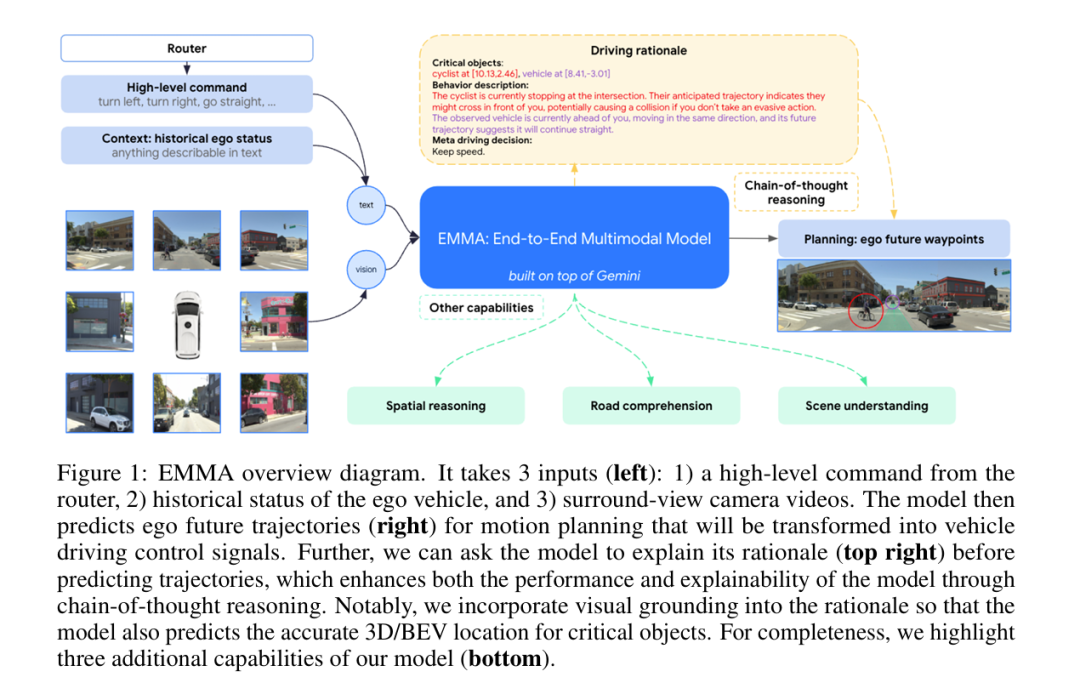
第一:感知层面,它纯视觉,没有雷达之类的输入
第二:输入层面是多维度的信息,包括高维指令,来自于比如google地图的导航指令,例如向左,向右之类的,具象化可以被认为是:“前方请在第二个匝道右转出匝道这种指令”
第三:任何关于此车也就是ego car的既往历史路线和其他的数据
然后就没什么了
把上面这三种东西,我们叫做T和V,T是text信息,V就是vision信息,也就是视频图像一类,最终拆帧也都是以图片形式来embedding的
紧接着,我们要设计一个网络G。这个网络EMMA里用的是Gemini的Nano,选Gemini Nono有它显示的意义,核心原因是这东西不开源,所以堆料比较猛,没有太多的顾及,可以很深度的做蒸馏。试想如果GPT4o出一个Nano是什么概念就可以了。
既然要不是day1就自己训练的,那么底模肯定是要选一个泛化能力高的,推理能力尽可能强的模型
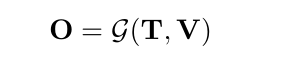
O自然就是把T和V输入给G以后生成的输出了
因为是语言模型,所以O其实是一个序列
![]()
输出的概率分布就可以写成下面这样
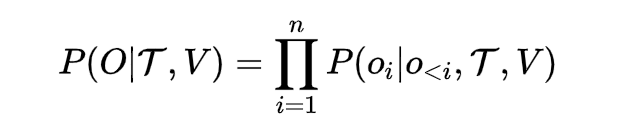
我们进一步细化一下,这几个参数和输出
V就是所有视觉的东西了吧,一般我们回塞给它一个BEV的视角,因为要感知周边的所有环境

T要分几个维度:
第一个就是T_intent,也就是高维指令,什么左转,右转啥的
第二个就是T_ego,历史自车状态
-
-
这些状态表示为BEV空间中的一组路径点坐标 (x_t, y_t),用于 -T_h到 T_h ,这一段时间的时间戳。这些坐标表示为纯文本,无需特殊的标记。
-
这一历史状态也可以扩展其包含更高阶的自车状态,如速度和加速度。
-
![]()
未来轨迹就可以被表达成以上的式子
那么好,现在我把我的公式再拿出来
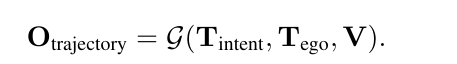
我的摩西那个可以与出来一个O'_trajectory对吧,而基于训练数据,它一定有个真实的未来轨迹O_trajectory,两者求个Lost,这不就损失函数也有了吗?
其实关于基本训练这块,就是这么的简单
牛B的是,这个训练是自监督的,你可以认为和语言模型的pretrain差不多,两者都是没什么人类输入的干扰,比如做语言模型,你的next-token的predicate就是这句话的下一个字对吧?那你玩这个EMMA,next-token就是输入给你目前的信息,你给我预测后面车的位置(x_t, y_t),然后多个位置就有一个trajectory,就完了。
这样的好处是和预训练LLM的道理是一样的,尽量让模型寻找隐空间里不易被人类捕捉到的规则,从这个角度上来讲EMMA的论文有这一个点就很有价值。
当然也不是啥任务都适合拿自监督来训练,例如3D物体检测、道路图估计和场景理解。这些任务需要使用人工标注的数据进行训练,这些就跟一般supervior的tunning也没啥区别了
人们都反映大模型是黑盒,尤其在自动驾驶领域这块,需要强烈的决策可解释性,EMMA用了prompt让LLM输出它的COT决策机制,这点我觉得是另一个创新点(这块学到了,我拿O1来做自驾的规划输出这块,最近也准备加入reasonning输出这部分
COT是啥就不解释了,看我频道的读者都知道,确实可以一定成都上增强推理能力并提高可解释性的强大工具(O1都玩TOT了,而且是原生,更牛B)。在 EMMA 中,作者将链式思维推理引入到端到端规划器轨迹生成中,通过要求模型表述其决策依据 O_rationale ,同时预测最终的未来轨迹路径点 O_trajectory 。
我们按照层次结构组织驾驶依据,从4种类型的粗到细的信息开展:
R1 - 场景描述 (Scene description):
-
广泛描述驾驶场景,包括天气、时间、交通状况和道路条件。
-
例如:天气晴朗,并且是白天。道路是一条没有分隔的四车道街道,中间有一个人行横道。街道两边停有汽车。
R2 - 关键物体 (Critical objects):
-
是那些在道路上并可能影响自车驾驶行为的代理物体。
-
我们要求模型识别它们的精准3D/鸟瞰视图(BEV)坐标。
-
例如:行人位置在 [9.01, 3.22],车辆位置在 [11.58, 0.35]。
R3 - 关键物体的行为描述 (Behavior description of critical objects):
-
描述关键物体的当前状态和意图。
-
一个具体的例子如下:行人目前站在人行道上,望向道路,可能准备过马路。该车辆目前在我前方,向同一方向移动,其未来轨迹表明它将继续直行。
R4 - 高层驾驶决策 (Meta driving decision):
-
包含12种高层次驾驶决策,基于先前观察总结驾驶计划。
-
一个例子是:我应该保持当前低速。
我们强调,驾驶依据说明使用自动化工具生成,无需任何额外的人类标签,确保数据生成流程的可扩展性。具体来说,我们利用现成的感知和预测专家模型来识别关键代理物体,然后使用 Gemini 模型结合精心设计的视觉和文本提示生成全面的场景和代理行为描述。高层驾驶决策通过一个启发式算法计算,该算法分析自车的地面真值轨迹。
在训练和推理过程中,模型预测所有驾驶依据的四个组件,然后再预测未来路径点,所以损失函数的公式求解被进一步演变成了
![]()
其中 O_rationale 表示驾驶依据组件 R1, R2, R3, R4 的有序文本输出。这种链式思维推理方法通过为决策过程添加解释性步骤,提升了自动驾驶系统的整体性能和安全性。它不仅提高了系统的决策能力,还增强了其解释性,使得自动驾驶过程更加透明和可信。
另外还有路线图规划,空间3D检测这些任务,和标准的supervisor instruction tunning区别不大,这些都是要有人类标注数据作为label的。
3D空间检测
T的输入是利用把3D 边界框给公式化即
![]()
其中 (x, y, z) 是车辆框架中的中心位置坐标, l, w, h 分别是框的长度、宽度和高度,θ 是指向角度,cls 是文本中的类别标签。将这个玩意儿转换为文本,通过写入带有两位小数点的浮点数,并用空格分隔每个维度。使用一个固定提示 T_detect_3D,例如“检测场景中的所有3D物体”,如下:
![]()
路径图估计(Road graph estimation)
主要关注于识别安全驾驶所需的关键道路元素,包括语义元素(例如车道标记、标志)和物理属性(例如车道曲率)。这些道路元素的集合形成了一幅道路图。例如,车道段可以通过(节点表示,当车道在交叉口、合并、分裂时,以及这些节点之间沿着交通方向排列的边表示。完整的道路图包含了许多这样的多段线段。
在EMMA里的任务建模为以下
![]()
路径图估计的详细内容
目标:
路径图估计的目的是识别道路上具有重要意义的元素,包括语义元素(如车道标记、标志)和物理属性(如车道曲率)。
识别和表示这些元素对于实现安全驾驶至关重要。
构建方法:
-
道路图由许多连接段组成,这些连接段由节点和边表示。
-
节点(nodes):例如,车道在交叉口、合并、分裂处的节点。
-
边(edges):连接这些节点,按照交通方向排列。
多段线的顺序:
每个多段线内部的边是有方向的,但不同多段线之间的相对顺序不一定唯一。类似于物体检测中的边界框,每个框由有序属性(例如左上、右下)定义,但框之间的顺序不一定有
具体步骤:
将车道转换成有序路径点集,并将这些路径点集转换为文本。使用样本有序路径点来表示交通方向和曲率是有益的。
编码示例:
"(x1,y1 and ... and xn,yn); ..."其中 "x,y" 是精确到小数点两位的浮点路径点,";" 分隔不同径实例。
通过将车道信息转换为有序路径点集并编码为文本,模型可以更精确地捕捉道路的方向和曲率。这一过程不仅提升了路径图估计的质量,还使得模型能够更好地理解和解释复杂的道路结构,为安全驾驶提供支持。
场景理解(Scene understanding)
场景理解任务测试模型对整个场景上下文的理解,特别是与驾驶相关的部分。举例来说,道路可能由于施工、紧急情况或其他事件而临时阻塞。及时检测这些阻塞并安全地绕行对于确保自动驾驶车辆的平稳和安全运行至关重要。然而,需要场景中的多种线索来确定是否存在阻塞。我们主要关注模型在临时阻塞检测任务中的表现,使用以下公式:
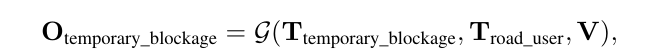
其中,O_temporary_blockage 是模型输出,指示潜在的阻塞情况;V 表示周围的图像;T_road_users表示所有在道路前方的物体;T_temporary_blockage是文本提示:“前方道路是否临时阻塞?”
解释
场景理解任务:
-
目标:测试模型对整个驾驶场景的理解,这些理解对于驾驶决策具有重要意义。
-
举例:道路临时阻塞(例如施工、紧急情况)需要及时检测和处理,以确保车辆能够安全平稳地操作。
临时阻塞检测任务:
-
重要性:快速检测到临时阻塞并安全绕行对于自动驾驶系统的平稳运行至关重要。
-
挑战:需要场景中的多条信息(如图像和物体检测等)来准确判断是否存在阻塞。
训练:
统一的视觉语言公式使得能够使用单个模型同时训练多个任务,在推理时,通过简单变化任务提示 T_task 实现任务特定的预测。训练过程既简单又灵活。
对于每个任务,构建一个包含 D_task 训练样本的数据集 |D_task|。每次训练迭代期间,我们从可用数据集中随机抽取一个批次,选择特定数据集样本的概率与数据集大小成比例:即 |D_task|/ ε_t |D_t|。为了训练 e ephco,我们将训练迭代的总次数设置为 e*ε_t |D_t|,确保训练在任务之间的比例由相对数据集大小控制。(通俗点解释就跟你训练GPT3似的,小数据集为了防止被大数据集给冲了,每种datasets再训练的时候有合适的ephco和数据集比例的乘积,理解到这个层面就可以了)
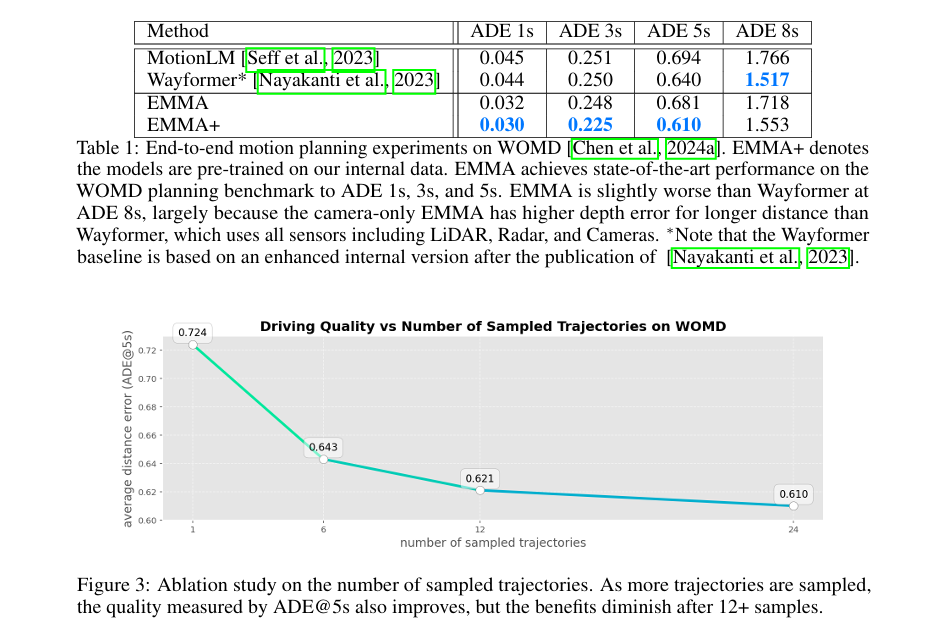
上图Table1中的实验结果 (WOMD 数据集):
WOMD datasets可以理解为包含 103,000 个真实世界的城市和郊区驾驶场景,每个场景持续 20 秒。这些场景进一步细分为 1,100,000 个示例,每个示例代表 9 秒的窗口:1秒用于作为输入上下文,其余 8 秒作为预测目标。数据集包括详细的地图特征,如交通信号状态和车道特性,连同自车状态如位置、速度、加速度和边界框。
在推理过程中,从多个候选轨迹中采样最终轨迹在最终性能中起到关键作用。MotionLM 和 Wayformer 生成 192 个候选轨迹,随后使用 k-means 聚类聚合为 6 个代表性轨迹,并从这 6 个代表性轨迹中根据其相关概率选择最终轨迹。为公平起见,使用一种 Top-K 解码策略,多次采样轨迹,最多达到 K=24。然后计算所有轨迹之间的成对 L2 距离(就是MSE均方误差,或者欧式距离,其实多余解释,但是为了让更多的人理解),并选择其中平均 L2 距离最小的轨迹作为最终预测轨迹,这可以看作所有预测中的“中值”轨迹。在 ADE 计算中,将该中值轨迹视为所有预测中概率最高的轨迹。(看不懂的话,就可以理解为采样均值化,保证output的输出稳定,无太大的数据噪音)
-
评估指标:
-
平均距离误差 (ADE) 在不同时间窗口(1秒、3秒、5秒、8秒)内的表现。
-
-
模型表现:
-
EMMA 与其他模型(如 MotionLM 和 Wayformer)相比,当仅在 WOMD 数据集上训练时,模型表现与 MotionLM 基线相似,采用 Gemini 预训练权重。当用另外内部数据集预训练时(称为 EMMA+)模型在未来 ADE 5s 中超越了 MotionLM 和 Wayformer,特别在短时间窗口(1s, 3s, 5s)上性能优越(短窗口敏感这是对自驾非常重要的,对比长周期规划)
-
在较长时间窗口(8s)表现稍逊于 Wayformer,这是因为 EMMA 只使用相机作为传感器,而 Wayformer 结合了激光雷达和雷达,提高了深度感知能力。
-
作者注意到 MotionLM和 EMMA 输入上的差异:MotionLM 接受来自代理位置历史、代理交互、道路图和交通信号状态的输入。这些代理框由专门的外部感知模型生成,这些模型同时看重过去和未来的观测,并经过大量精心制作的人类标签训练。相比之下,EMMA 仅使用相机图像和自车历史作为输入,无需任何标签或额外模型(除了利用 Gemini 预训练权重,可见VLM天生的泛化优势体现的淋漓尽致)。
Figure3中的消融研究结果:
消融研究:对采样轨迹数量的影响进行研究。
-
随着采样轨迹数量的增加,驾驶质量(通过 ADE@5s 测量)也提高,但12个以上样本后的收益减弱。
关键点:
-
多任务训练的比例:
-
由数据集相对大小控制。(公式中的比例计算确保了训练任务之间的均匀分布)
-
受任务复杂性、任务间的相关性和任务迁移性影响。
-
-
实验结果:
-
证明使用统一的通用模型训练多个任务,始终优于单任务训练的专门模型。(端到端的最大优势,少了不同模型调用损失,少由于垃圾policy堆砌的影响)
-
优势:增强知识迁移、改善泛化能力和增加效率。
-
在nuScenes dataset上的测试
nuScenes 数据集 提供了一个综合的自动驾驶传感器套件用于评估。它包含1,000个场景,每个场景持续20秒,包含来自6个摄像头、5个雷达和1个激光雷达的信息,共同提供360度的视野覆盖。数据集完全标注了23类和8个属性的3D边界框。我们的实验遵循规划评估的标准协议:基于2秒的历史数据预测未来3秒的驾驶动作。我们在1秒、2秒和3秒的时间段上测量L2误差,与已建立的基准方法对齐。
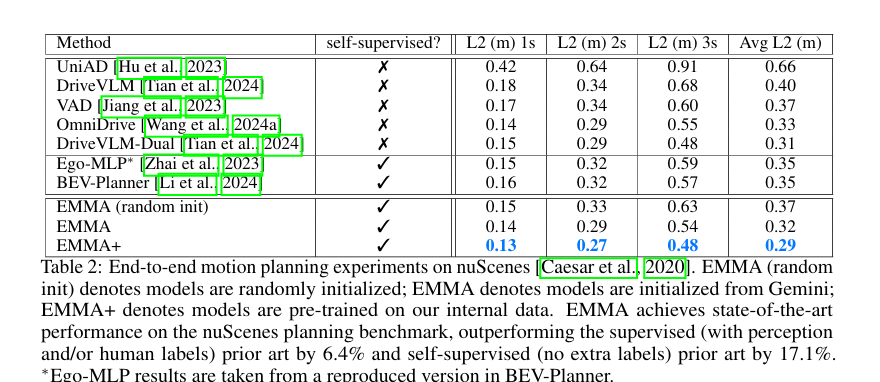
如上表所示
自监督的EMMA在nuScenes上的规划取得了最先进的结果,超越了所有之前的监督(带中间感知标签和/或人类标签)和自监督(无额外标签)方法。在相同的自监督设置下,EMMA的平均L2误差比之前的BEV-Planner 提高了17.1%;即使与使用大量中间感知和人类标签的DriveVLM-Dual 相比,自监督EMMA仍然将平均L2误差降低了6.4%。这是相当牛B的改善。
刚才的两组对比呢,都是基于以下这个公式来做的实验
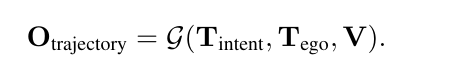
也就是我刚才讲的基础款,那么现在我们请出来plus版本,把COT给接进来
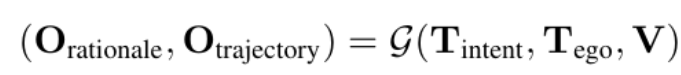

实验设置:
Table 3 实验结果:
-
数据集背景:
-
使用内部数据集进行实验,这个数据集包含数百万的场景,相较于任何公开可用的自动驾驶数据集,规模更大。
-
模型使用两秒历史数据来预测五秒后的驾驶动作。
-
-
链式思维推理的优势:
-
使用链式思维推理使模型能够通过详细解释每一步决策,提升其推理能力和可解释性。
-
性能改进:
采用链式思维推理公式相比标准端到端规划公式实现了6.7%的性能改进。
消融研究:
-
驾驶元决策和关键物体识别分别提升了3.0%和1.5%的性能。
-
综合所有部分可以实现更显著的性能提升,尤其是元决策和关键物体识别的组合效果最佳。
-
场景描述对性能影响较小,但显著增强了模型的可解释性。
-
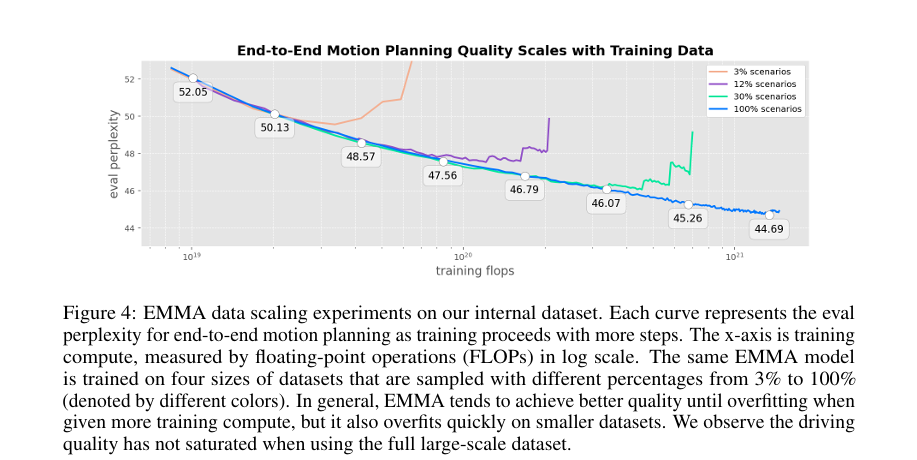
数据扩展实验Figure4:
验证困惑度:
随着训练数据集的扩大,验证困惑度在过拟合前逐步降低,表明模型具有更好的泛化能力。
数据集比例:
实验中使用了不同比例的数据集(3%, 12%, 30% 和 100%),观察其对模型性能的影响。
在较大数据集上(100%)训练时,虽然过拟合问题减轻,但驾驶质量尚未达到饱和状态。(scaling law 呗)
刚才讲规划这块,反过来我们在说感知任务。
先说3D检测
实验设置
数据集:
Waymo Open Dataset (WOD):这是一个包含大量交通场景及其3D标注的大型数据集,被广泛用于自动驾驶研究。
LET匹配方法:指的是纵向误差容忍匹配方法,用于检测评价。
模型版本:
EMMA:基本模型版本。
EMMA+:在内部数据集上预训练了3D检测任务的增强版本。
性能比较:
EMMA+ 在基准测试上表现出色。
评价标准:
精度/召回率:由于模型输出的检测框没有单独的置信分数,直接比较精度和召回率。
F1 分数:比较了常规的 F1 分数和 F1-max 分数。F1 分数基于单个精度/召回计算,而F1-max是选择曲线上的最大值。
性能提升的方面:
车辆检测:
EMMA+ 相较于最先进的方法(如 BEVFormer)在相同精度下的召回率提高5.5%,总检测精度提升16.3%。(牛逼)
行人检测:
EMMA+ 在行人检测上的表现与 MV-FCOS3D++ 相当。
不同距离范围内的性能:
在近距离范围内(例如交通繁忙的都市区域),EMMA+ 的表现尤为出色。(这点更重要了)
关键点
-
EMMA+ 展示了多模态方法在丰富数据和大型模型下的强大性能,甚至超越了专门的专家模型。
-
EMMA+ 的出色表现证明了多模态方法的潜力。通过适当的预训练和丰富的数据资源,这种方法可以广泛应用于各种复杂的自动驾驶场景,提升系统的整体检测质量。
道路图估计(Road Graph Estimation)
如何设计更好的RGE(Road Graph Estimation)是一个复杂课题,这个论文也给出了比较好的对比消融实验和哪些指标能更好的提升模型的能力。
道路图估计是一项复杂任务,需预测一组无序的多段线,每个段线表示为一系列路径点。用两个指标来衡量道路图预测的质量:(1) 车道级别的精度和召回率,定义为当且仅当预测的车道段线与真实车道段线的平均距离在1米以内时,认为这是一个真正匹配;以及 (2) 像素级别的精度和召回率,多段线被栅格化成1米分辨率的鸟瞰视图(BEV)网格,然后将BEV网格看作图像,并基于逐像素匹配计算精度和召回率。这个任务涉及多种设计选择。其中一个选择是道路图多段线(polylines)的表示方式,定义每个车道的起点和终点,以及需要的中间点以准确捕获道路的曲率。另一个关键设计选择是用模型训练目标标签序列的构造。借鉴Pix2Seq 在物体检测中的做法,一个有效的设计选择是将目标打散并随机打乱。这种技术有助于模型处理无序输出,并防止训练期间的过早终止。
实验设置
复杂任务:
目标:预测无序的多段线,每个多段线表示为一系列路径点。
质量衡量:
-
车道级别精度和召回率:通过路径点之间的平均距离计算匹配。
-
像素级别精度和召回率:将路径点栅格化成鸟瞰视图网格,并基于逐像素匹配计算。
设计选择
路径线表示方法:
动态采样 vs. 固定采样:
-
更好的方法是根据曲率和长度动态调整路径点数。
-
带来的提升效果显著,特别是更能准确捕捉曲率较大的车道细节。
目标序列构造:
随机排序 vs. 任意排序:
-
使用终点距离自车最近顺序,并动态打乱顺序构造目标序列。
-
这样能提升模型的健壮性和覆盖范围。
填充 vs. 不填充:
-
使用填充值以防止序列的过早终止,结合“无效”标记以明确表示路径点结束。
-
显示出显著的效果提升。
标点符号和语义冗余标记:
-
使用语言样式的结构和标点符号提升了目标的有效分组。
-
明确标记“有效”或“无效”标记点,可以显著提升精度。
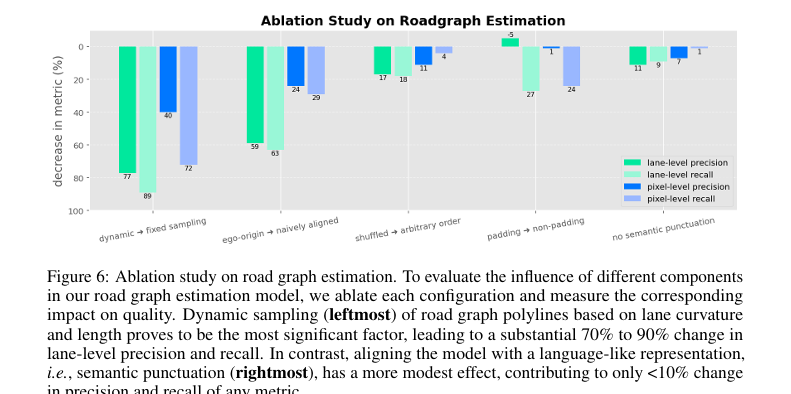
Figure6的消融研究结果:
-
动态采样:多段线表示为每条车道的一组稀疏控制点,例如,每端点两个,外加抓取曲率所需的固定数量的中间点。然而,我们发现一个更好的方法是根据曲率和长度动态调整每个车道的点数量。保持一致的路径点密度而不是一致的路径点数量,可以更准确捕获车道的结构细节,带来约 40% 到 90% 的性能提升。
-
路径点间隔调整:防止直接转换点带来的偏差,能提升 25% 到 60% 的预测质量。
-
随机排序:使用终点距离自车最近的顺序,将车道目标划分为多个区域,动态打乱提高模型在不同车道配置下的健壮性和覆盖范围。。
-
填充操作:额外使用“无效”标记以明确表示多段线未填充结束点提高了模型的预测可靠性。
-
标点符号和冗余标记:使用语言样式的结构和标点符号提高分组目标的效果显著。此外,明确标记“有效”或“无效”标记点可以提升车道级别指标约 10%。
场景理解(Scene Understanding)
这个就是偏向于长周期规划的了。
在临时阻塞检测任务上进行的场景理解研究。研究基于内部数据集,这些数据集专门为这些场景精心策划。对于这个研究,通过向人类展示图片,并要求他们判断车道是否暂时被阻塞,来建立基准评价。回答可以是“是”、“否”或“不确定”。将所有“不确定”答案视为不正确的基线,并使用这些答案进行过滤比较。
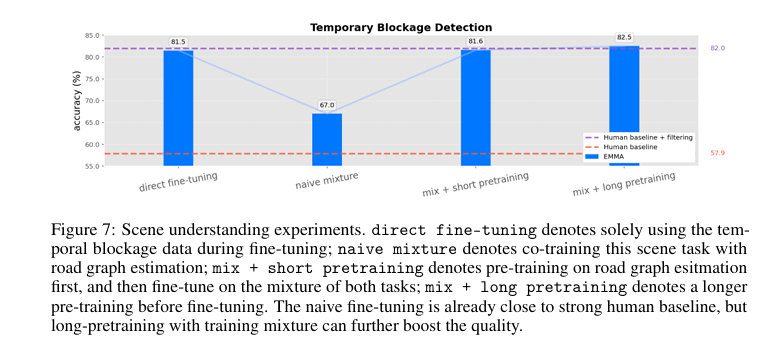
与之相对,模型经过微调后能够对所有问题回答“是”或“否”。如图所示,仅使用临时堵塞数据直接对模型进行微调,虽然性能略低于基线比较,但在屏蔽过滤后的表现不足。为了提高模型性能,第一个尝试是将此任务与道路图估计任务联合训练,但“朴素混合”方法并未改善性能。第二个尝试是先在道路估计任务上进行预训练,然后在这两个任务上进行微调。结果表明,当进行长时间预训练后,质量显著提高,表明模型能够更好地整合多任务以增强表现。
-
直接微调(direct fine-tuning):
-
仅使用临时堵塞数据进行微调,精度为61.5%。
-
-
朴素混合(naive mixture):
-
将该任务与道路图估计任务联合训练,精度为67.0%。
-
-
短期预训练的混合方法(mix + short pretraining):
-
先在道路估计任务上预训练,然后在该任务和临时堵塞检测任务上进行微调,精度为81.6%。
-
-
长期预训练的混合方法(mix + long pretraining):
-
更长时间预训练后再进行微调,精度为82.5%。
-
不过这块我觉得其实没什么可解释,你训练语言模型也是一样,微调没有原始数据分布,质量不好,很正常,这块和自动驾驶也没关系了,这是模型ft的基本概念。

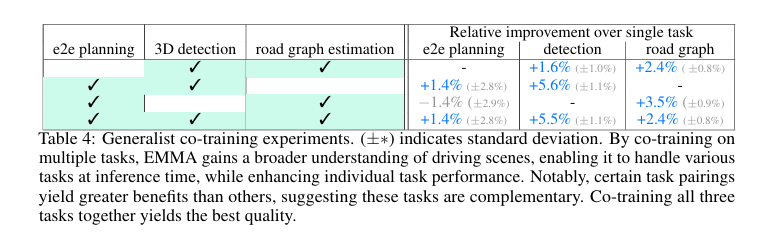
Table4总结了在联合训练多任务中的通用训练实验,展示了与单任务相比的相对改进:
-
e2e运动规划(end-to-end motion planning):
-
通过联合训练e2e运动规划、3D检测和道路图估计任务,整体性能提高。
-
-
检测(detection):
-
通过与道路图估计任务联合训练,3D检测任务性能提升显著,达到5.6%。
-
-
道路图(road graph estimation):
-
与e2e运动规划和3D检测任务联合训练后,道路图估计任务性能也得到了提升,高达3.5%。
-
论文的剩余部分就是一些展示了

我就不意义点评了,值得说的是这张图的c,有一只松鼠,车辆对它进行回避,作者说在预训练数据集(它的增量预训练数据集)里是没松树的,这个demo让作者们对于EMMA的泛化能力特别surprise。
我这里是这么看的,有几种情况
第一:松鼠不在增量预训练的数据集里,可能在本身Gemini Nano原始模型的理解里,这个可能性比较大
第二:被当成为识别的object采取的避障行为。
不管是以上哪一种,VLM都证明了要比传统基于supervisor train的模型要有更大的能力和想象空间。
